 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak-shot Semantic Segmentation by Transferring Semantic Affinity and Boundary
Oct 04, 2021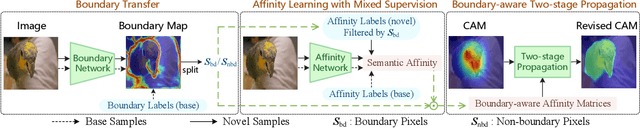
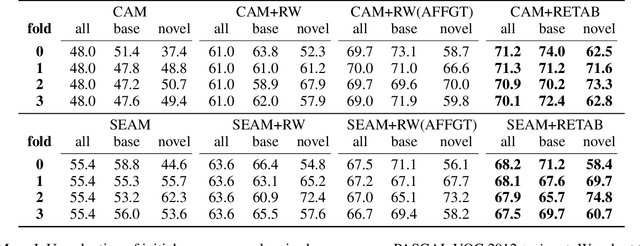


Weakly-supervised semantic segmentation (WSSS) with image-level labels has been widely studied to relieve the annotation burden of the traditional segmentation task. In this paper, we show that existing fully-annotated base categories can help segment objects of novel categories with only image-level labels, even if base and novel categories have no overlap. We refer to this task as weak-shot semantic segmentation, which could also be treated as WSSS with auxiliary fully-annotated categories. Recent advanced WSSS methods usually obtain class activation maps (CAMs) and refine them by affinity propagation. Based on the observation that semantic affinity and boundary are class-agnostic, we propose a method under the WSSS framework to transfer semantic affinity and boundary from base categories to novel ones. As a result, we find that pixel-level annotation of base categories can facilitate affinity learning and propagation, leading to higher-quality CAMs of novel categories. Extensive experiments on PASCAL VOC 2012 dataset demonstrate that our method significantly outperforms WSSS baselines on novel categories.
HYouTube: Video Harmonization Dataset
Sep 18, 2021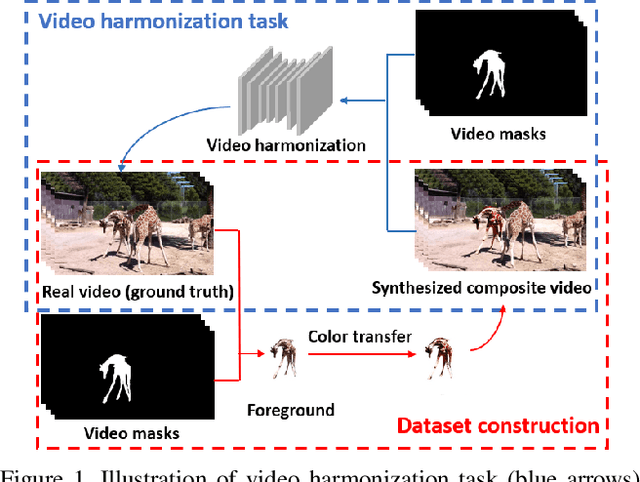
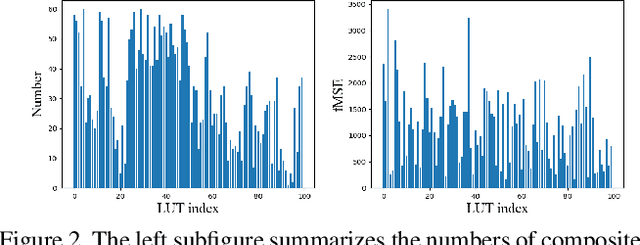

Video composition aims to generate a composite video by combining the foreground of one video with the background of another video, but the inserted foreground may be incompatible with the background in terms of color and illumination. Video harmonization aims to adjust the foreground of a composite video to make it compatible with the background. So far, video harmonization has only received limited attention and there is no public dataset for video harmonization. In this work, we construct a new video harmonization dataset HYouTube by adjusting the foreground of real videos to create synthetic composite videos. Considering the domain gap between real composite videos and synthetic composite videos, we additionally create 100 real composite videos via copy-and-paste. Datasets are available at https://github.com/bcmi/Video-Harmonization-Dataset-HYouTube.
High-Resolution Image Harmonization via Collaborative Dual Transformations
Sep 14, 2021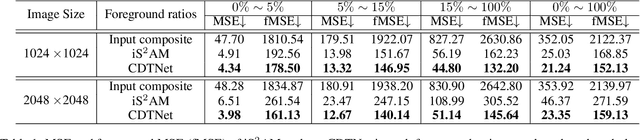

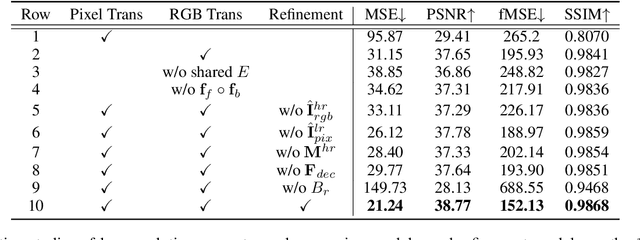
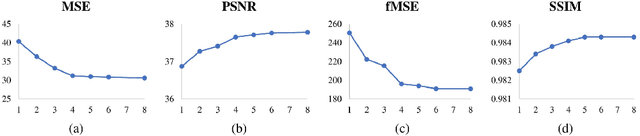
Given a composite image, image harmonization aims to adjust the foreground to make it compatible with the background. High-resolution image harmonization is in high demand, but still remains unexplored. Conventional image harmonization methods learn global RGB-to-RGB transformation which could effortlessly scale to high resolution, but ignore diverse local context. Recent deep learning methods learn the dense pixel-to-pixel transformation which could generate harmonious outputs, but are highly constrained in low resolution. In this work, we propose a high-resolution image harmonization network with Collaborative Dual Transformation (CDTNet) to combine pixel-to-pixel transformation and RGB-to-RGB transformation coherently in an end-to-end framework. Our CDTNet consists of a low-resolution generator for pixel-to-pixel transformation, a color mapping module for RGB-to-RGB transformation, and a refinement module to take advantage of both. Extensive experiments on high-resolution image harmonization dataset demonstrate that our CDTNet strikes a good balance between efficiency and effectiveness.
Visible Watermark Removal via Self-calibrated Localization and Background Refinement
Aug 08, 2021
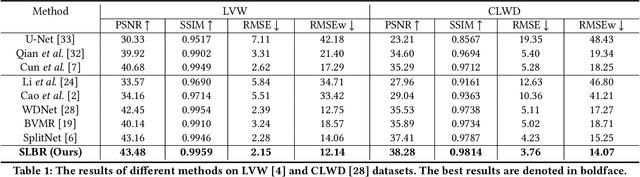
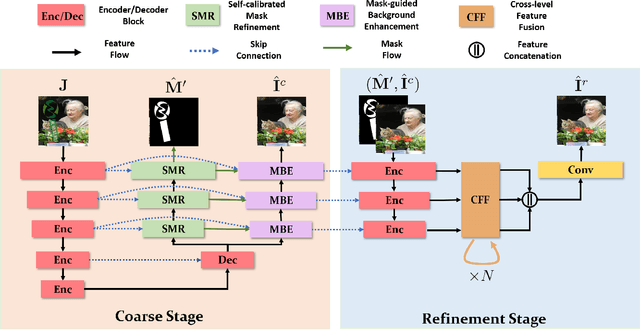
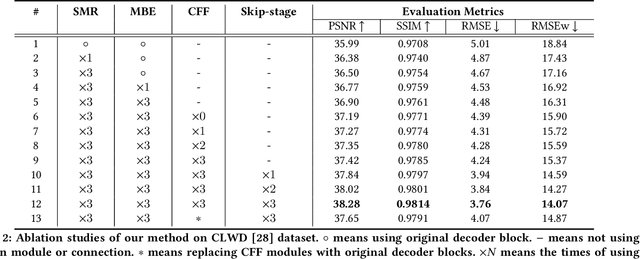
Superimposing visible watermarks on images provides a powerful weapon to cope with the copyright issue. Watermark removal techniques, which can strengthen the robustness of visible watermarks in an adversarial way, have attracted increasing research interest. Modern watermark removal methods perform watermark localization and background restoration simultaneously, which could be viewed as a multi-task learning problem. However, existing approaches suffer from incomplete detected watermark and degraded texture quality of restored background. Therefore, we design a two-stage multi-task network to address the above issues. The coarse stage consists of a watermark branch and a background branch, in which the watermark branch self-calibrates the roughly estimated mask and passes the calibrated mask to background branch to reconstruct the watermarked area. In the refinement stage, we integrate multi-level features to improve the texture quality of watermarked area. Extensive experiments on two datasets demonstrate the effectiveness of our proposed method.
OPA: Object Placement Assessment Dataset
Jul 05, 2021Image composition aims to generate realistic composite image by inserting an object from one image into another background image, where the placement (e.g., location, size, occlusion) of inserted object may be unreasonable, which would significantly degrade the quality of the composite image. Although some works attempted to learn object placement to create realistic composite images, they did not focus on assessing the plausibility of object placement. In this paper, we focus on object placement assessment task, which verifies whether a composite image is plausible in terms of the object placement. To accomplish this task, we construct the first Object Placement Assessment (OPA) dataset consisting of composite images and their rationality labels. Dataset is available at https://github.com/bcmi/Object-Placement-Assessment-Dataset-OPA.
Making Images Real Again: A Comprehensive Survey on Deep Image Composition
Jun 28, 2021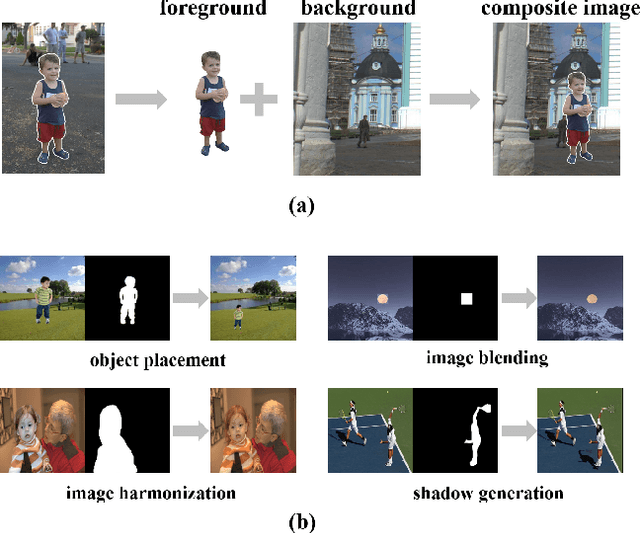



As a common image editing operation, image composition aims to cut the foreground from one image and paste it on another image, resulting in a composite image. However, there are many issues that could make the composite images unrealistic. These issues can be summarized as the inconsistency between foreground and background, which include appearance inconsistency (e.g., incompatible color and illumination) and geometry inconsistency (e.g., unreasonable size and location). Previous works on image composition target at one or more issues. Since each individual issue is a complicated problem, there are some research directions (e.g., image harmonization, object placement) which focus on only one issue. By putting all the efforts together, we can acquire realistic composite images. Sometimes, we expect the composite images to be not only realistic but also aesthetic, in which case aesthetic evaluation needs to be considered. In this survey, we summarize the datasets and methods for the above research directions. We also discuss the limitations and potential directions to facilitate the future research for image composition. Finally, as a double-edged sword, image composition may also have negative effect on our lives (e.g., fake news) and thus it is imperative to develop algorithms to fight against composite images. Datasets and codes for image composition are summarized at https://github.com/bcmi/Awesome-Image-Composition.
End-to-End Video Object Detection with Spatial-Temporal Transformers
May 23, 2021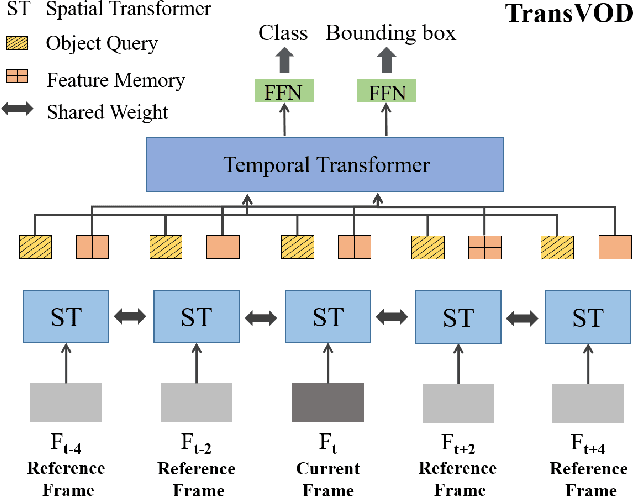
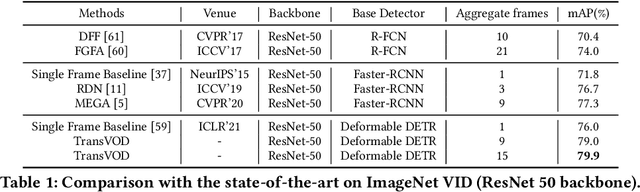
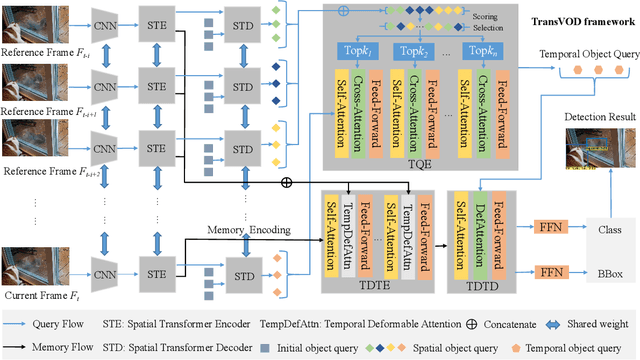
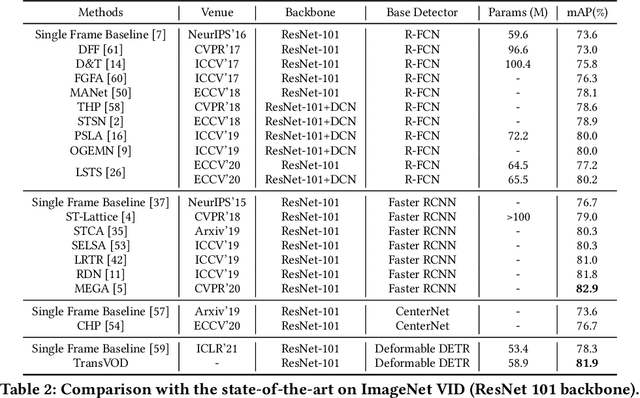
Recently, DETR and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, an end-to-end video object detection model based on a spatial-temporal Transformer architecture. The goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow, recurrent neural networks, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS or Tubelet rescoring, which keeps the pipeline simple and clean. In particular, we present temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal Transformer consists of three components: Temporal Deformable Transformer Encoder (TDTE) to encode the multiple frame spatial details, Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. TransVOD yields comparable results performance on the benchmark of ImageNet VID. We hope our TransVOD can provide a new perspective for video object detection. Code will be made publicly available at https://github.com/SJTU-LuHe/TransVOD.
Shadow Generation for Composite Image in Real-world Scenes
Apr 21, 2021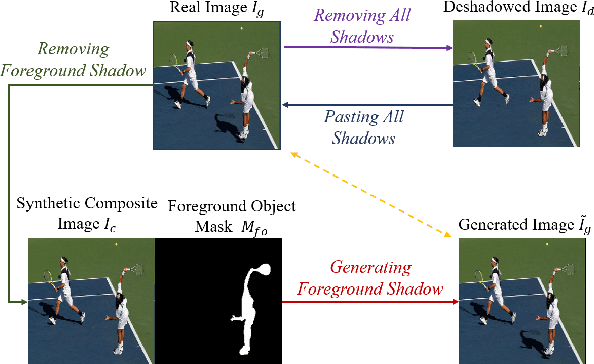
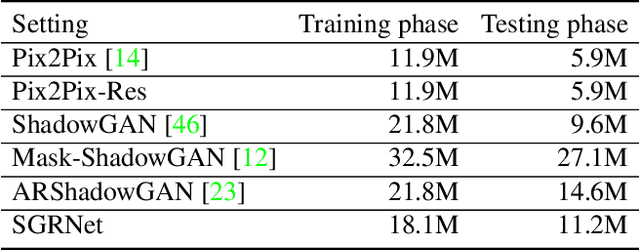

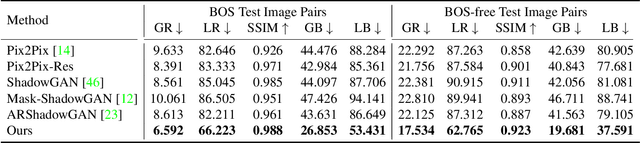
Image composition targets at inserting a foreground object on a background image. Most previous image composition methods focus on adjusting the foreground to make it compatible with background while ignoring the shadow effect of foreground on the background. In this work, we focus on generating plausible shadow for the foreground object in the composite image. First, we contribute a real-world shadow generation dataset DESOBA by generating synthetic composite images based on paired real images and deshadowed images. Then, we propose a novel shadow generation network SGRNet, which consists of a shadow mask prediction stage and a shadow filling stage. In the shadow mask prediction stage, foreground and background information are thoroughly interacted to generate foreground shadow mask. In the shadow filling stage, shadow parameters are predicted to fill the shadow area. Extensive experiments on our DESOBA dataset and real composite images demonstrate the effectiveness of our proposed method.
Inharmonious Region Localization
Apr 19, 2021
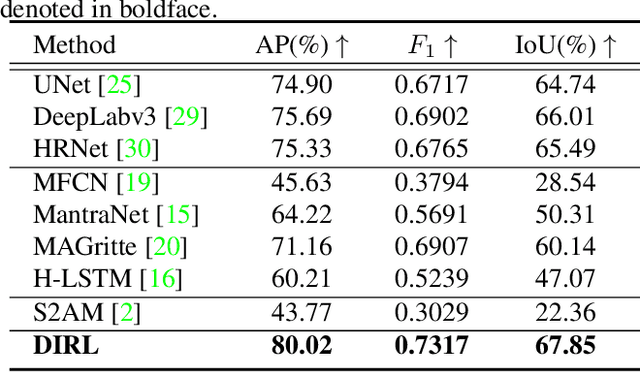
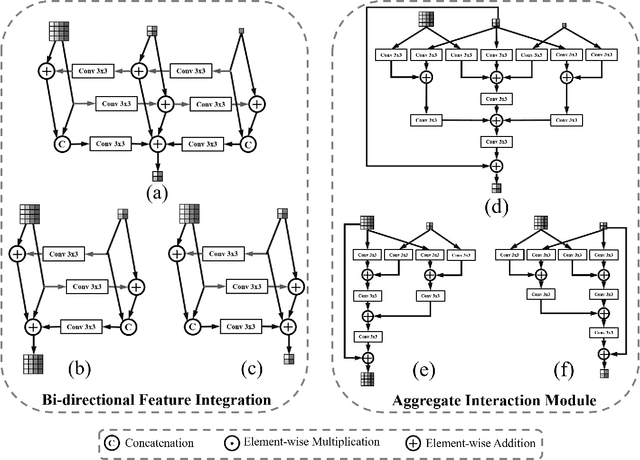
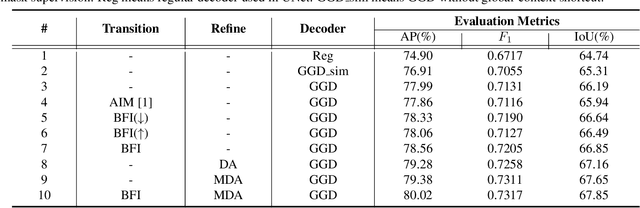
The advance of image editing techniques allows users to create artistic works, but the manipulated regions may be incompatible with the background. Localizing the inharmonious region is an appealing yet challenging task. Realizing that this task requires effective aggregation of multi-scale contextual information and suppression of redundant information, we design novel Bi-directional Feature Integration (BFI) block and Global-context Guided Decoder (GGD) block to fuse multi-scale features in the encoder and decoder respectively. We also employ Mask-guided Dual Attention (MDA) block between the encoder and decoder to suppress the redundant information. Experiments on the image harmonization dataset demonstrate that our method achieves competitive performance for inharmonious region localization. The source code is available at https://github.com/bcmi/DIRL.
Image Composition Assessment with Saliency-augmented Multi-pattern Pooling
Apr 07, 2021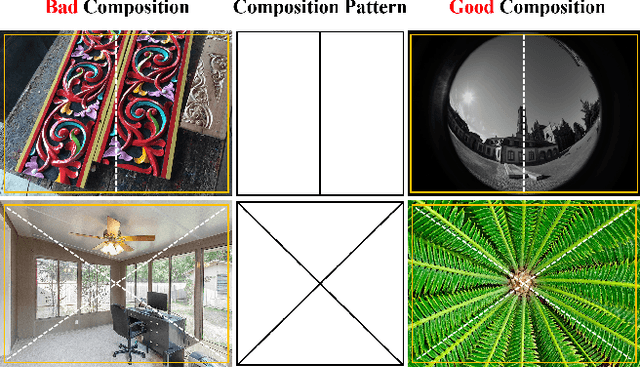
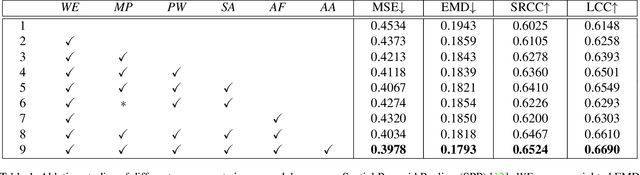
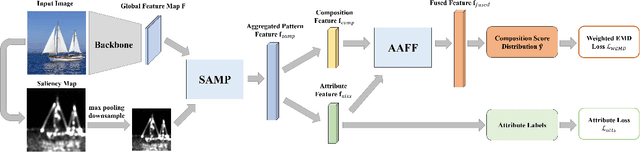
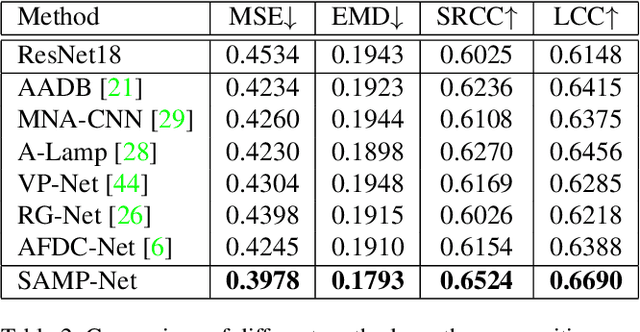
Image composition assessment is crucial in aesthetic assessment, which aims to assess the overall composition quality of a given image. However, to the best of our knowledge, there is neither dataset nor method specifically proposed for this task. In this paper, we contribute the first composition assessment dataset CADB with composition scores for each image provided by multiple professional raters. Besides, we propose a composition assessment network SAMP-Net with a novel Saliency-Augmented Multi-pattern Pooling (SAMP) module, which analyses visual layout from the perspectives of multiple composition patterns. We also leverage composition-relevant attributes to further boost the performance, and extend Earth Mover's Distance (EMD) loss to weighted EMD loss to eliminate the content bias. The experimental results show that our SAMP-Net can perform more favorably than previous aesthetic assessment approaches and offer constructive composition suggestions.