 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrated Task and Motion Planning
Oct 02, 2020
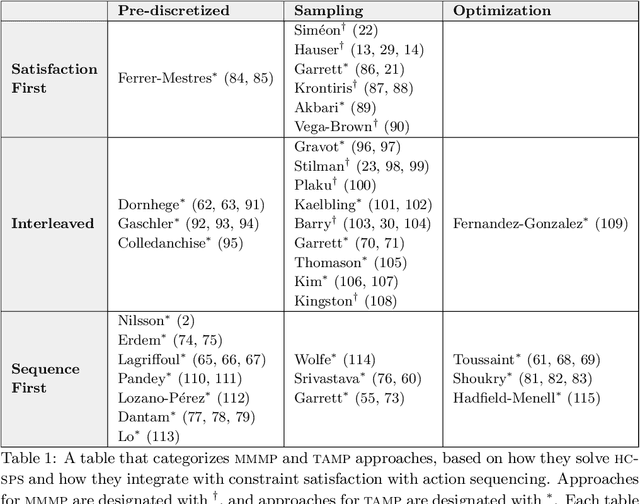
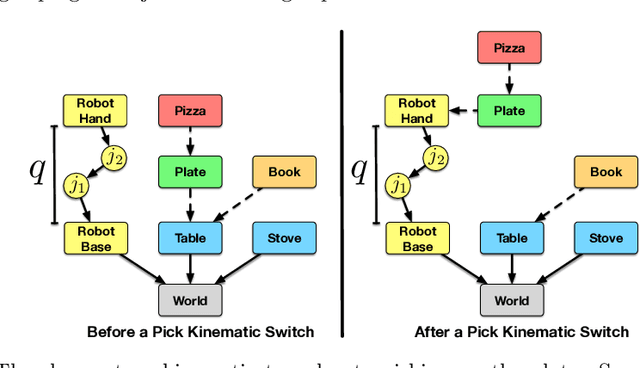
The problem of planning for a robot that operates in environments containing a large number of objects, taking actions to move itself through the world as well as to change the state of the objects, is known as task and motion planning (TAMP). TAMP problems contain elements of discrete task planning, discrete-continuous mathematical programming, and continuous motion planning, and thus cannot be effectively addressed by any of these fields directly. In this paper, we define a class of TAMP problems and survey algorithms for solving them, characterizing the solution methods in terms of their strategies for solving the continuous-space subproblems and their techniques for integrating the discrete and continuous components of the search.
Planning with Learned Object Importance in Large Problem Instances using Graph Neural Networks
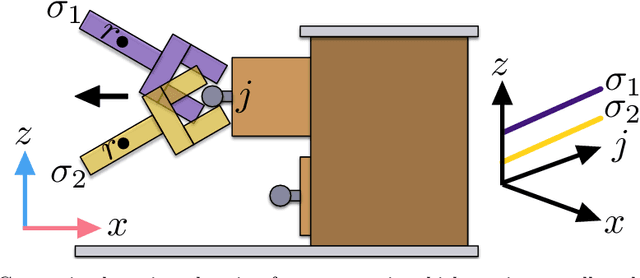
Sep 11, 2020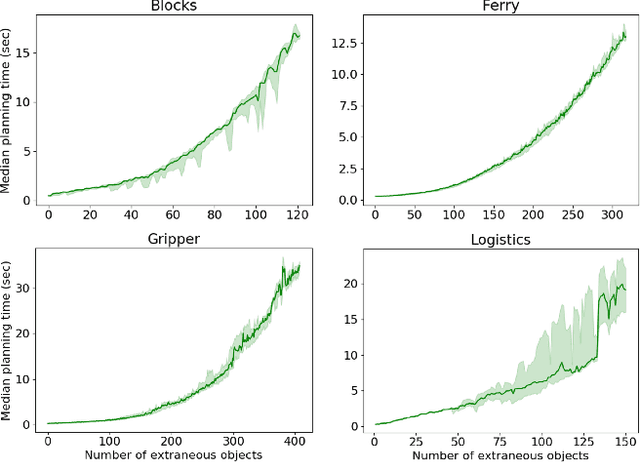
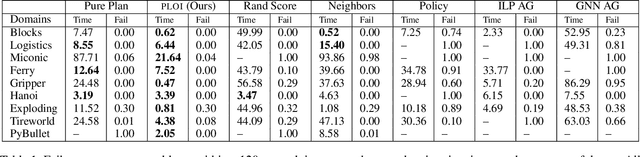
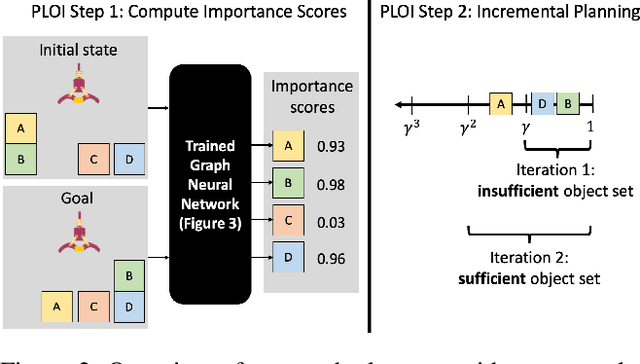

Real-world planning problems often involve hundreds or even thousands of objects, straining the limits of modern planners. In this work, we address this challenge by learning to predict a small set of objects that, taken together, would be sufficient for finding a plan. We propose a graph neural network architecture for predicting object importance in a single pass, thereby incurring little overhead while substantially reducing the number of objects that must be considered by the planner. Our approach treats the planner and transition model as black boxes, and can be used with any off-the-shelf planner. Empirically, across classical planning, probabilistic planning, and robotic task and motion planning, we find that our method results in planning that is significantly faster than several baselines, including other partial grounding strategies and lifted planners. We conclude that learning to predict a sufficient set of objects for a planning problem is a simple, powerful, and general mechanism for planning in large instances. Video: https://youtu.be/FWsVJc2fvCE
CAMPs: Learning Context-Specific Abstractions for Efficient Planning in Factored MDPs
Jul 26, 2020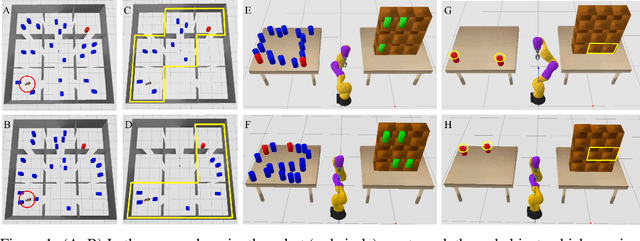
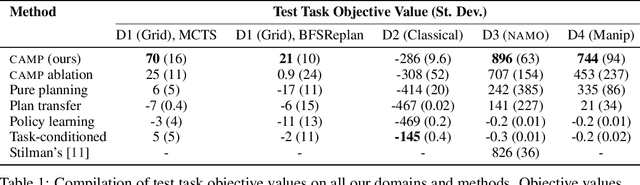
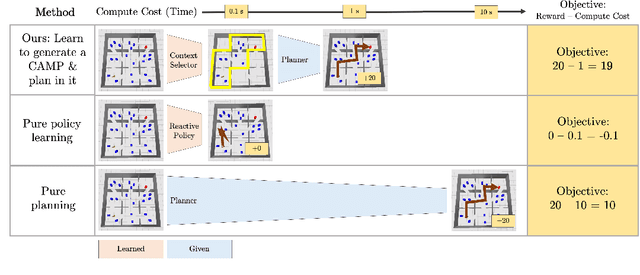
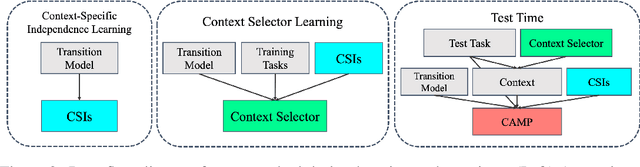
Meta-planning, or learning to guide planning from experience, is a promising approach to improving the computational cost of planning. A general meta-planning strategy is to learn to impose constraints on the states considered and actions taken by the agent. We observe that (1) imposing a constraint can induce context-specific independences that render some aspects of the domain irrelevant, and (2) an agent can take advantage of this fact by imposing constraints on its own behavior. These observations lead us to propose the context-specific abstract Markov decision process (CAMP), an abstraction of a factored MDP that affords efficient planning. We then describe how to learn constraints to impose so the CAMP optimizes a trade-off between rewards and computational cost. Our experiments consider five planners across four domains, including robotic navigation among movable obstacles (NAMO), robotic task and motion planning for sequential manipulation, and classical planning. We find planning with learned CAMPs to consistently outperform baselines, including Stilman's NAMO-specific algorithm. Video: https://youtu.be/wTXt6djcAd4
Learning compositional models of robot skills for task and motion planning
Jun 08, 2020
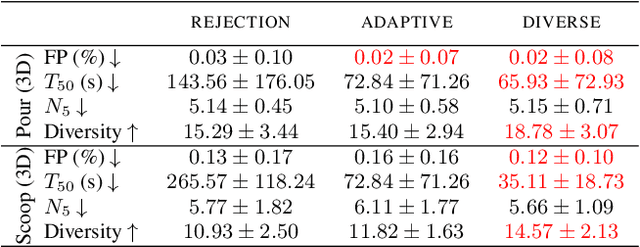

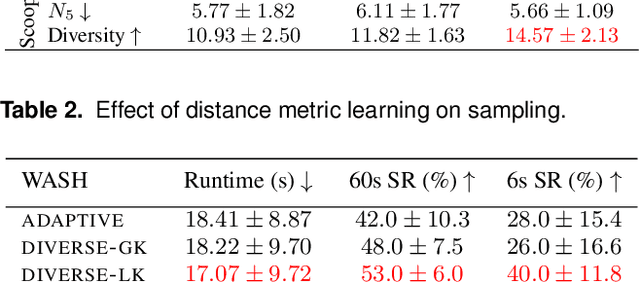
The objective of this work is to augment the basic abilities of a robot by learning to use new sensorimotor primitives to solve complex long-horizon manipulation problems. This requires flexible generative planning that can combine primitive abilities in novel combinations and thus generalize across a wide variety of problems. In order to plan with primitive actions, we must have models of the preconditions and effects of those actions: under what circumstances will executing this primitive successfully achieve some particular effect in the world? We use, and develop novel improvements on, state-of-the-art methods for active learning and sampling. We use Gaussian process methods for learning the conditions of operator effectiveness from small numbers of expensive training examples. We develop adaptive sampling methods for generating a comprehensive and diverse sequence of continuous parameter values (such as pouring waypoints for a cup) configurations and during planning for solving a new task, so that a complete robot plan can be found as efficiently as possible. We demonstrate our approach in an integrated system, combining traditional robotics primitives with our newly learned models using an efficient robot task and motion planner. We evaluate our approach both in simulation and in the real world through measuring the quality of the selected pours and scoops. Finally, we apply our integrated system to a variety of long-horizon simulated and real-world manipulation problems.
Visual Prediction of Priors for Articulated Object Interaction
Jun 06, 2020

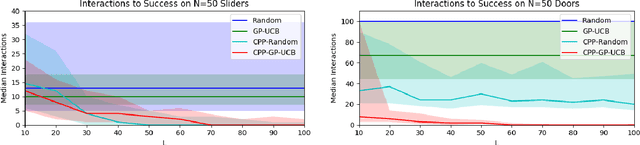
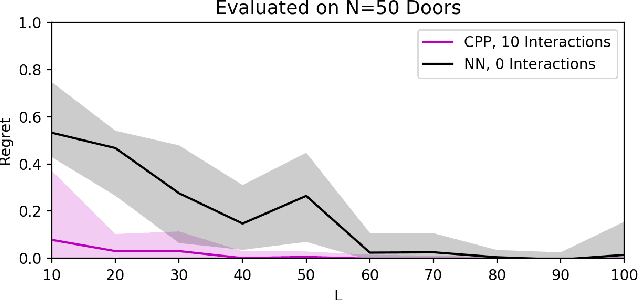
Exploration in novel settings can be challenging without prior experience in similar domains. However, humans are able to build on prior experience quickly and efficiently. Children exhibit this behavior when playing with toys. For example, given a toy with a yellow and blue door, a child will explore with no clear objective, but once they have discovered how to open the yellow door, they will most likely be able to open the blue door much faster. Adults also exhibit this behavior when entering new spaces such as kitchens. We develop a method, Contextual Prior Prediction, which provides a means of transferring knowledge between interactions in similar domains through vision. We develop agents that exhibit exploratory behavior with increasing efficiency, by learning visual features that are shared across environments, and how they correlate to actions. Our problem is formulated as a Contextual Multi-Armed Bandit where the contexts are images, and the robot has access to a parameterized action space. Given a novel object, the objective is to maximize reward with few interactions. A domain which strongly exhibits correlations between visual features and motion is kinemetically constrained mechanisms. We evaluate our method on simulated prismatic and revolute joints.
Meta-learning curiosity algorithms
Mar 11, 2020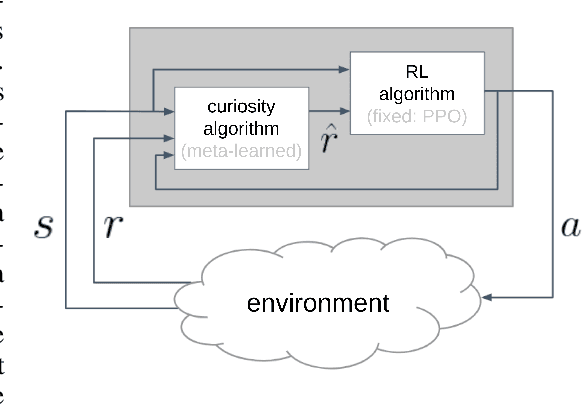
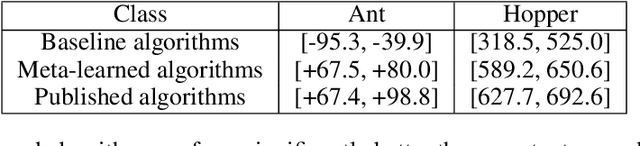
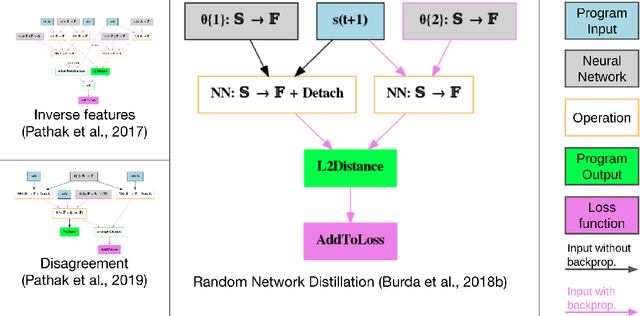
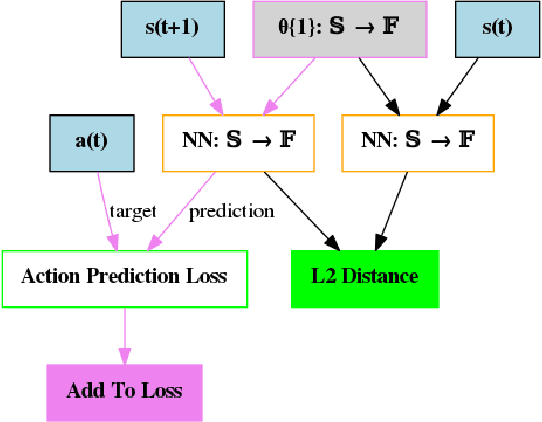
We hypothesize that curiosity is a mechanism found by evolution that encourages meaningful exploration early in an agent's life in order to expose it to experiences that enable it to obtain high rewards over the course of its lifetime. We formulate the problem of generating curious behavior as one of meta-learning: an outer loop will search over a space of curiosity mechanisms that dynamically adapt the agent's reward signal, and an inner loop will perform standard reinforcement learning using the adapted reward signal. However, current meta-RL methods based on transferring neural network weights have only generalized between very similar tasks. To broaden the generalization, we instead propose to meta-learn algorithms: pieces of code similar to those designed by humans in ML papers. Our rich language of programs combines neural networks with other building blocks such as buffers, nearest-neighbor modules and custom loss functions. We demonstrate the effectiveness of the approach empirically, finding two novel curiosity algorithms that perform on par or better than human-designed published curiosity algorithms in domains as disparate as grid navigation with image inputs, acrobot, lunar lander, ant and hopper.
GLIB: Exploration via Goal-Literal Babbling for Lifted Operator Learning
Jan 22, 2020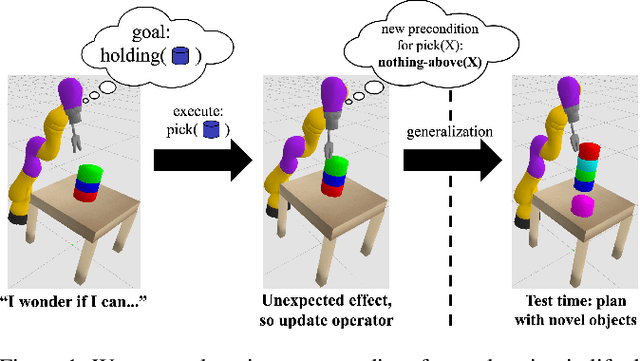
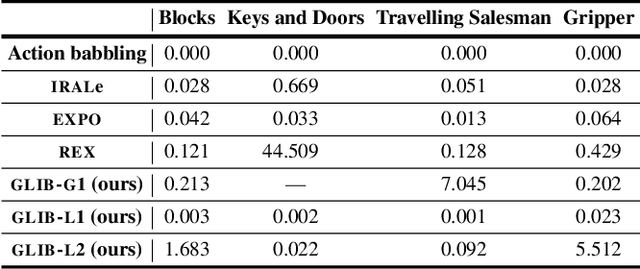
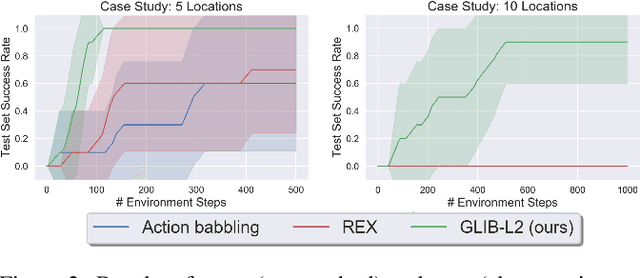
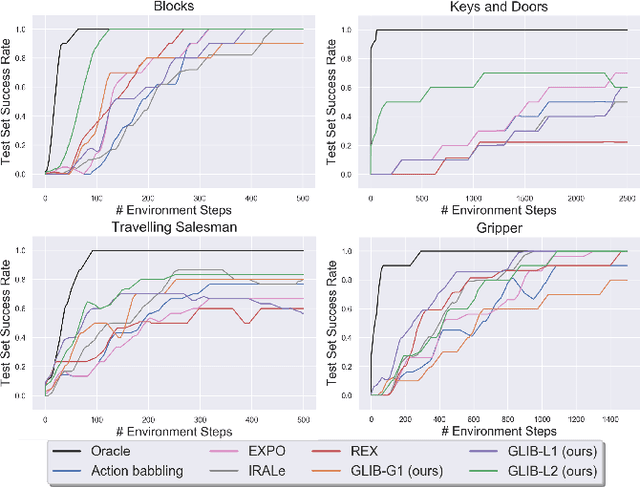
We address the problem of efficient exploration for learning lifted operators in sequential decision-making problems without extrinsic goals or rewards. Inspired by human curiosity, we propose goal-literal babbling (GLIB), a simple and general method for exploration in such problems. GLIB samples goals that are conjunctions of literals, which can be understood as specific, targeted effects that the agent would like to achieve in the world, and plans to achieve these goals using the operators being learned. We conduct a case study to elucidate two key benefits of GLIB: robustness to overly general preconditions and efficient exploration in domains with effects at long horizons. We also provide theoretical guarantees and further empirical results, finding GLIB to be effective on a range of benchmark planning tasks.
Online Replanning in Belief Space for Partially Observable Task and Motion Problems
Nov 11, 2019
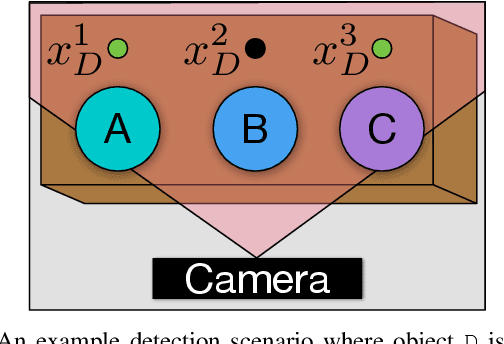

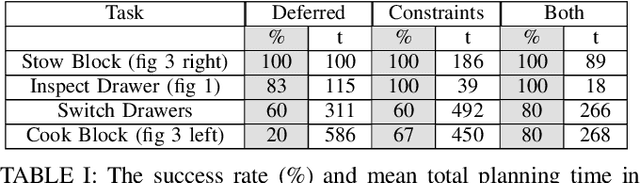
To solve multi-step manipulation tasks in the real world, an autonomous robot must take actions to observe its environment and react to unexpected observations. This may require opening a drawer to observe its contents or moving an object out of the way to examine the space behind it. If the robot fails to detect an important object, it must update its belief about the world and compute a new plan of action. Additionally, a robot that acts noisily will never exactly arrive at a desired state. Still, it is important that the robot adjusts accordingly in order to keep making progress towards achieving the goal. In this work, we present an online planning and execution system for robots faced with these kinds of challenges. Our approach is able to efficiently solve partially observable problems both in simulation and in a real-world kitchen.
Differentiable Algorithm Networks for Composable Robot Learning
May 28, 2019

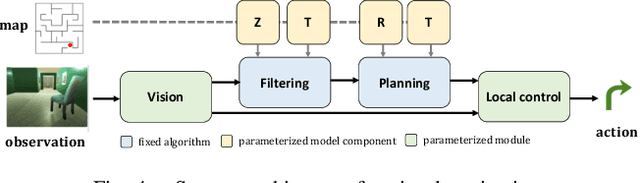
This paper introduces the Differentiable Algorithm Network (DAN), a composable architecture for robot learning systems. A DAN is composed of neural network modules, each encoding a differentiable robot algorithm and an associated model; and it is trained end-to-end from data. DAN combines the strengths of model-driven modular system design and data-driven end-to-end learning. The algorithms and models act as structural assumptions to reduce the data requirements for learning; end-to-end learning allows the modules to adapt to one another and compensate for imperfect models and algorithms, in order to achieve the best overall system performance. We illustrate the DAN methodology through a case study on a simulated robot system, which learns to navigate in complex 3-D environments with only local visual observations and an image of a partially correct 2-D floor map.
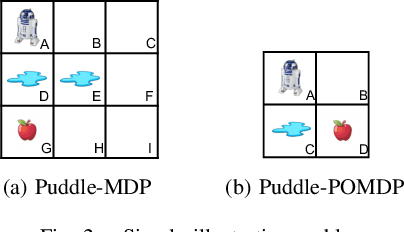
Graph Element Networks: adaptive, structured computation and memory
May 13, 2019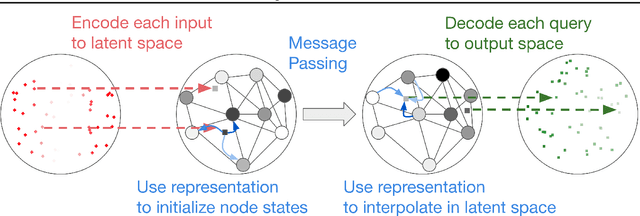
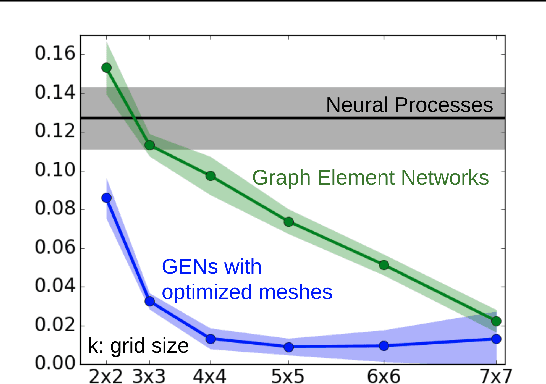
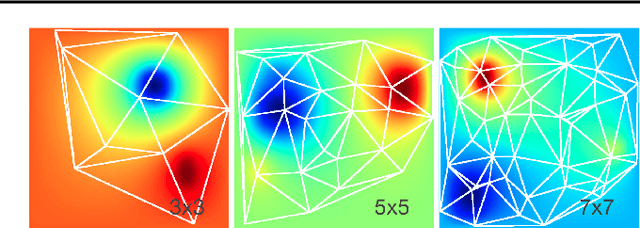
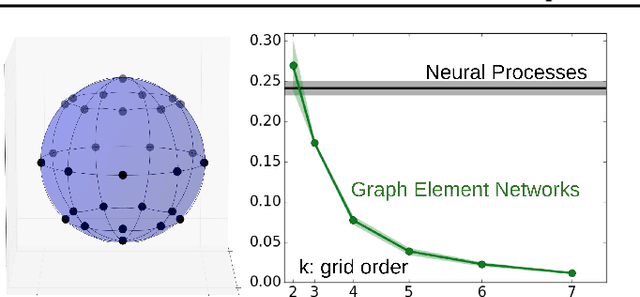
We explore the use of graph neural networks (GNNs) to model spatial processes in which there is no a priori graphical structure. Similar to finite element analysis, we assign nodes of a GNN to spatial locations and use a computational process defined on the graph to model the relationship between an initial function defined over a space and a resulting function in the same space. We use GNNs as a computational substrate, and show that the locations of the nodes in space as well as their connectivity can be optimized to focus on the most complex parts of the space. Moreover, this representational strategy allows the learned input-output relationship to generalize over the size of the underlying space and run the same model at different levels of precision, trading computation for accuracy. We demonstrate this method on a traditional PDE problem, a physical prediction problem from robotics, and learning to predict scene images from novel viewpoints.