 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Lightweight Multi-Scale Attention Framework for Real-Time Spinal Endoscopic Instance Segmentation
Dec 26, 2025Real-time instance segmentation for spinal endoscopy is important for identifying and protecting critical anatomy during surgery, but it is difficult because of the narrow field of view, specular highlights, smoke/bleeding, unclear boundaries, and large scale changes. Deployment is also constrained by limited surgical hardware, so the model must balance accuracy and speed and remain stable under small-batch (even batch-1) training. We propose LMSF-A, a lightweight multi-scale attention framework co-designed across backbone, neck, and head. The backbone uses a C2f-Pro module that combines RepViT-style re-parameterized convolution (RVB) with efficient multi-scale attention (EMA), enabling multi-branch training while collapsing into a single fast path for inference. The neck improves cross-scale consistency and boundary detail using Scale-Sequence Feature Fusion (SSFF) and Triple Feature Encoding (TFE), which strengthens high-resolution features. The head adopts a Lightweight Multi-task Shared Head (LMSH) with shared convolutions and GroupNorm to reduce parameters and support batch-1 stability. We also release the clinically reviewed PELD dataset (61 patients, 610 images) with instance masks for adipose tissue, bone, ligamentum flavum, and nerve. Experiments show that LMSF-A is highly competitive (or even better than) in all evaluation metrics and much lighter than most instance segmentation methods requiring only 1.8M parameters and 8.8 GFLOPs, and it generalizes well to a public teeth benchmark. Code and dataset: https://github.com/hhwmortal/PELD-Instance-segmentation.
LibContinual: A Comprehensive Library towards Realistic Continual Learning
Dec 26, 2025A fundamental challenge in Continual Learning (CL) is catastrophic forgetting, where adapting to new tasks degrades the performance on previous ones. While the field has evolved with diverse methods, this rapid surge in diverse methodologies has culminated in a fragmented research landscape. The lack of a unified framework, including inconsistent implementations, conflicting dependencies, and varying evaluation protocols, makes fair comparison and reproducible research increasingly difficult. To address this challenge, we propose LibContinual, a comprehensive and reproducible library designed to serve as a foundational platform for realistic CL. Built upon a high-cohesion, low-coupling modular architecture, LibContinual integrates 19 representative algorithms across five major methodological categories, providing a standardized execution environment. Meanwhile, leveraging this unified framework, we systematically identify and investigate three implicit assumptions prevalent in mainstream evaluation: (1) offline data accessibility, (2) unregulated memory resources, and (3) intra-task semantic homogeneity. We argue that these assumptions often overestimate the real-world applicability of CL methods. Through our comprehensive analysis using strict online CL settings, a novel unified memory budget protocol, and a proposed category-randomized setting, we reveal significant performance drops in many representative CL methods when subjected to these real-world constraints. Our study underscores the necessity of resource-aware and semantically robust CL strategies, and offers LibContinual as a foundational toolkit for future research in realistic continual learning. The source code is available from \href{https://github.com/RL-VIG/LibContinual}{https://github.com/RL-VIG/LibContinual}.
RAPTOR: Real-Time High-Resolution UAV Video Prediction with Efficient Video Attention
Dec 25, 2025



Video prediction is plagued by a fundamental trilemma: achieving high-resolution and perceptual quality typically comes at the cost of real-time speed, hindering its use in latency-critical applications. This challenge is most acute for autonomous UAVs in dense urban environments, where foreseeing events from high-resolution imagery is non-negotiable for safety. Existing methods, reliant on iterative generation (diffusion, autoregressive models) or quadratic-complexity attention, fail to meet these stringent demands on edge hardware. To break this long-standing trade-off, we introduce RAPTOR, a video prediction architecture that achieves real-time, high-resolution performance. RAPTOR's single-pass design avoids the error accumulation and latency of iterative approaches. Its core innovation is Efficient Video Attention (EVA), a novel translator module that factorizes spatiotemporal modeling. Instead of processing flattened spacetime tokens with $O((ST)^2)$ or $O(ST)$ complexity, EVA alternates operations along the spatial (S) and temporal (T) axes. This factorization reduces the time complexity to $O(S + T)$ and memory complexity to $O(max(S, T))$, enabling global context modeling at $512^2$ resolution and beyond, operating directly on dense feature maps with a patch-free design. Complementing this architecture is a 3-stage training curriculum that progressively refines predictions from coarse structure to sharp, temporally coherent details. Experiments show RAPTOR is the first predictor to exceed 30 FPS on a Jetson AGX Orin for $512^2$ video, setting a new state-of-the-art on UAVid, KTH, and a custom high-resolution dataset in PSNR, SSIM, and LPIPS. Critically, RAPTOR boosts the mission success rate in a real-world UAV navigation task by 18/%, paving the way for safer and more anticipatory embodied agents.
A Community-Enhanced Graph Representation Model for Link Prediction
Dec 24, 2025Although Graph Neural Networks (GNNs) have become the dominant approach for graph representation learning, their performance on link prediction tasks does not always surpass that of traditional heuristic methods such as Common Neighbors and Jaccard Coefficient. This is mainly because existing GNNs tend to focus on learning local node representations, making it difficult to effectively capture structural relationships between node pairs. Furthermore, excessive reliance on local neighborhood information can lead to over-smoothing. Prior studies have shown that introducing global structural encoding can partially alleviate this issue. To address these limitations, we propose a Community-Enhanced Link Prediction (CELP) framework that incorporates community structure to jointly model local and global graph topology. Specifically, CELP enhances the graph via community-aware, confidence-guided edge completion and pruning, while integrating multi-scale structural features to achieve more accurate link prediction. Experimental results across multiple benchmark datasets demonstrate that CELP achieves superior performance, validating the crucial role of community structure in improving link prediction accuracy.
Multi-Agent Intelligence for Multidisciplinary Decision-Making in Gastrointestinal Oncology
Dec 23, 2025Multimodal clinical reasoning in the field of gastrointestinal (GI) oncology necessitates the integrated interpretation of endoscopic imagery, radiological data, and biochemical markers. Despite the evident potential exhibited by Multimodal Large Language Models (MLLMs), they frequently encounter challenges such as context dilution and hallucination when confronted with intricate, heterogeneous medical histories. In order to address these limitations, a hierarchical Multi-Agent Framework is proposed, which emulates the collaborative workflow of a human Multidisciplinary Team (MDT). The system attained a composite expert evaluation score of 4.60/5.00, thereby demonstrating a substantial improvement over the monolithic baseline. It is noteworthy that the agent-based architecture yielded the most substantial enhancements in reasoning logic and medical accuracy. The findings indicate that mimetic, agent-based collaboration provides a scalable, interpretable, and clinically robust paradigm for automated decision support in oncology.
CrystalFormer-CSP: Thinking Fast and Slow for Crystal Structure Prediction
Dec 20, 2025Crystal structure prediction is a fundamental problem in materials science. We present CrystalFormer-CSP, an efficient framework that unifies data-driven heuristic and physics-driven optimization approaches to predict stable crystal structures for given chemical compositions. The approach combines pretrained generative models for space-group-informed structure generation and a universal machine learning force field for energy minimization. Reinforcement fine-tuning can be employed to further boost the accuracy of the framework. We demonstrate the effectiveness of CrystalFormer-CSP on benchmark problems and showcase its usage via web interface and language model integration.
Revisiting the Broken Symmetry Phase of Solid Hydrogen: A Neural Network Variational Monte Carlo Study
Dec 19, 2025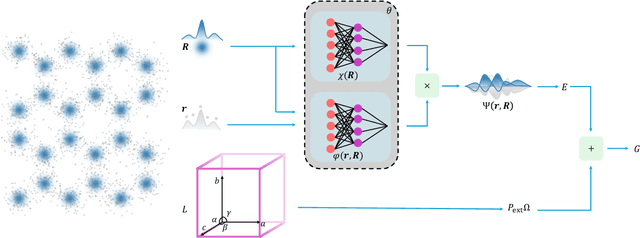
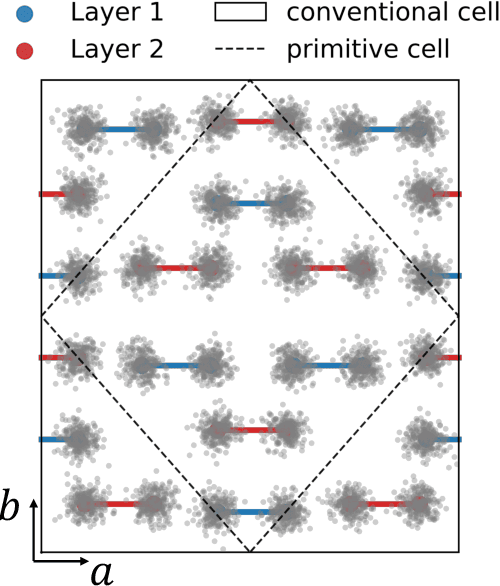
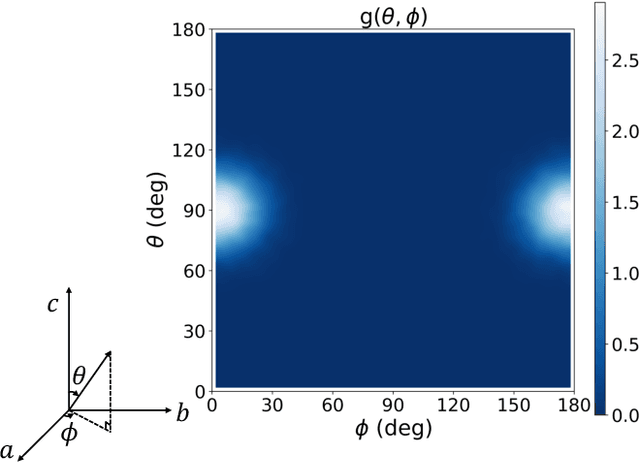
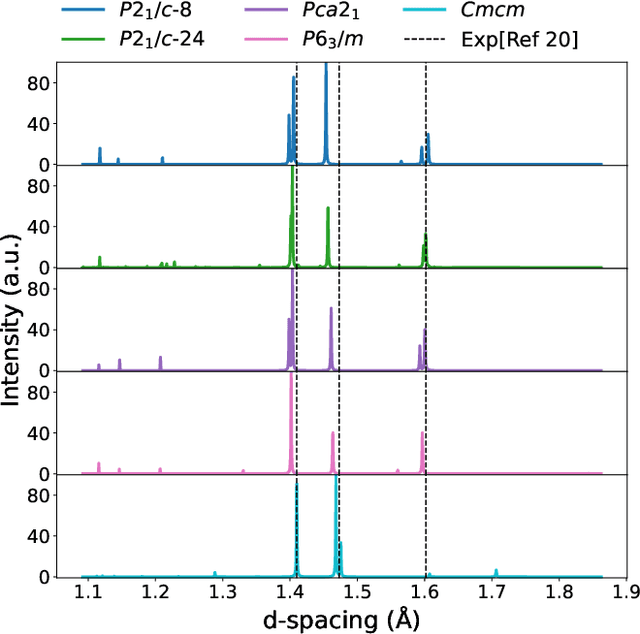
The crystal structure of high-pressure solid hydrogen remains a fundamental open problem. Although the research frontier has mostly shifted toward ultra-high pressure phases above 400 GPa, we show that even the broken symmetry phase observed around 130~GPa requires revisiting due to its intricate coupling of electronic and nuclear degrees of freedom. Here, we develop a first principle quantum Monte Carlo framework based on a deep neural network wave function that treats both electrons and nuclei quantum mechanically within the constant pressure ensemble. Our calculations reveal an unreported ground-state structure candidate for the broken symmetry phase with $Cmcm$ space group symmetry, and we test its stability up to 96 atoms. The predicted structure quantitatively matches the experimental equation of state and X-ray diffraction patterns. Furthermore, our group-theoretical analysis shows that the $Cmcm$ structure is compatible with existing Raman and infrared spectroscopic data. Crucially, static density functional theory calculation reveals the $Cmcm$ structure as a dynamically unstable saddle point on the Born-Oppenheimer potential energy surface, demonstrating that a full quantum many-body treatment of the problem is necessary. These results shed new light on the phase diagram of high-pressure hydrogen and call for further experimental verifications.
KOSS: Kalman-Optimal Selective State Spaces for Long-Term Sequence Modeling
Dec 18, 2025Recent selective state space models (SSMs), such as Mamba and Mamba-2, have demonstrated strong performance in sequence modeling owing to input-dependent selection mechanisms. However, these mechanisms lack theoretical grounding and cannot support context-aware selection from latent state dynamics. To address these limitations, we propose KOSS, a Kalman-optimal Selective State Space model that formulates selection as latent state uncertainty minimization. Derived from estimation theory, KOSS adopts a continuous-time latent update driven by a Kalman gain that dynamically modulates information propagation based on content and context, enabling a closed-loop, context-aware selectivity mechanism. To ensure stable computation and near-linear scalability, KOSS employs global spectral differentiation for frequency-domain derivative estimation, along with a segment-wise scan for hardware-efficient processing. On a selective copying task with distractors, KOSS achieves over 79\% accuracy while baselines drop below 20\%, demonstrating robust context-aware selection. Furthermore, across nine long-term forecasting benchmarks, KOSS reduces MSE by 2.92--36.23\% and consistently outperforms state-of-the-art models in both accuracy and stability. To assess real-world applicability, a case study on secondary surveillance radar (SSR) tracking confirms KOSS's robustness under irregular intervals and noisy conditions and demonstrates its effectiveness in real-world applications. Finally, supplementary experiments verify Kalman gain convergence and the frequency response of spectral differentiation, providing theoretical support for the proposed closed-loop design.
MCP-SafetyBench: A Benchmark for Safety Evaluation of Large Language Models with Real-World MCP Servers
Dec 17, 2025Large language models (LLMs) are evolving into agentic systems that reason, plan, and operate external tools. The Model Context Protocol (MCP) is a key enabler of this transition, offering a standardized interface for connecting LLMs with heterogeneous tools and services. Yet MCP's openness and multi-server workflows introduce new safety risks that existing benchmarks fail to capture, as they focus on isolated attacks or lack real-world coverage. We present MCP-SafetyBench, a comprehensive benchmark built on real MCP servers that supports realistic multi-turn evaluation across five domains: browser automation, financial analysis, location navigation, repository management, and web search. It incorporates a unified taxonomy of 20 MCP attack types spanning server, host, and user sides, and includes tasks requiring multi-step reasoning and cross-server coordination under uncertainty. Using MCP-SafetyBench, we systematically evaluate leading open- and closed-source LLMs, revealing large disparities in safety performance and escalating vulnerabilities as task horizons and server interactions grow. Our results highlight the urgent need for stronger defenses and establish MCP-SafetyBench as a foundation for diagnosing and mitigating safety risks in real-world MCP deployments.
CCSD: Cross-Modal Compositional Self-Distillation for Robust Brain Tumor Segmentation with Missing Modalities
Nov 18, 2025



The accurate segmentation of brain tumors from multi-modal MRI is critical for clinical diagnosis and treatment planning. While integrating complementary information from various MRI sequences is a common practice, the frequent absence of one or more modalities in real-world clinical settings poses a significant challenge, severely compromising the performance and generalizability of deep learning-based segmentation models. To address this challenge, we propose a novel Cross-Modal Compositional Self-Distillation (CCSD) framework that can flexibly handle arbitrary combinations of input modalities. CCSD adopts a shared-specific encoder-decoder architecture and incorporates two self-distillation strategies: (i) a hierarchical modality self-distillation mechanism that transfers knowledge across modality hierarchies to reduce semantic discrepancies, and (ii) a progressive modality combination distillation approach that enhances robustness to missing modalities by simulating gradual modality dropout during training. Extensive experiments on public brain tumor segmentation benchmarks demonstrate that CCSD achieves state-of-the-art performance across various missing-modality scenarios, with strong generalization and stability.