 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Distillation of Deep Spiking Neural Networks for Full-Range Timestep Deployment
Jan 27, 2025Spiking Neural Networks (SNNs) are emerging as a brain-inspired alternative to traditional Artificial Neural Networks (ANNs), prized for their potential energy efficiency on neuromorphic hardware. Despite this, SNNs often suffer from accuracy degradation compared to ANNs and face deployment challenges due to fixed inference timesteps, which require retraining for adjustments, limiting operational flexibility. To address these issues, our work considers the spatio-temporal property inherent in SNNs, and proposes a novel distillation framework for deep SNNs that optimizes performance across full-range timesteps without specific retraining, enhancing both efficacy and deployment adaptability. We provide both theoretical analysis and empirical validations to illustrate that training guarantees the convergence of all implicit models across full-range timesteps. Experimental results on CIFAR-10, CIFAR-100, CIFAR10-DVS, and ImageNet demonstrate state-of-the-art performance among distillation-based SNNs training methods.
Reliable Imputed-Sample Assisted Vertical Federated Learning
Jan 11, 2025Vertical Federated Learning (VFL) is a well-known FL variant that enables multiple parties to collaboratively train a model without sharing their raw data. Existing VFL approaches focus on overlapping samples among different parties, while their performance is constrained by the limited number of these samples, leaving numerous non-overlapping samples unexplored. Some previous work has explored techniques for imputing missing values in samples, but often without adequate attention to the quality of the imputed samples. To address this issue, we propose a Reliable Imputed-Sample Assisted (RISA) VFL framework to effectively exploit non-overlapping samples by selecting reliable imputed samples for training VFL models. Specifically, after imputing non-overlapping samples, we introduce evidence theory to estimate the uncertainty of imputed samples, and only samples with low uncertainty are selected. In this way, high-quality non-overlapping samples are utilized to improve VFL model. Experiments on two widely used datasets demonstrate the significant performance gains achieved by the RISA, especially with the limited overlapping samples, e.g., a 48% accuracy gain on CIFAR-10 with only 1% overlapping samples.
An Efficient Adaptive Compression Method for Human Perception and Machine Vision Tasks
Jan 08, 2025



While most existing neural image compression (NIC) and neural video compression (NVC) methodologies have achieved remarkable success, their optimization is primarily focused on human visual perception. However, with the rapid development of artificial intelligence, many images and videos will be used for various machine vision tasks. Consequently, such existing compression methodologies cannot achieve competitive performance in machine vision. In this work, we introduce an efficient adaptive compression (EAC) method tailored for both human perception and multiple machine vision tasks. Our method involves two key modules: 1), an adaptive compression mechanism, that adaptively selects several subsets from latent features to balance the optimizations for multiple machine vision tasks (e.g., segmentation, and detection) and human vision. 2), a task-specific adapter, that uses the parameter-efficient delta-tuning strategy to stimulate the comprehensive downstream analytical networks for specific machine vision tasks. By using the above two modules, we can optimize the bit-rate costs and improve machine vision performance. In general, our proposed EAC can seamlessly integrate with existing NIC (i.e., Ball\'e2018, and Cheng2020) and NVC (i.e., DVC, and FVC) methods. Extensive evaluation on various benchmark datasets (i.e., VOC2007, ILSVRC2012, VOC2012, COCO, UCF101, and DAVIS) shows that our method enhances performance for multiple machine vision tasks while maintaining the quality of human vision.
Trusted Mamba Contrastive Network for Multi-View Clustering
Dec 21, 2024



Multi-view clustering can partition data samples into their categories by learning a consensus representation in an unsupervised way and has received more and more attention in recent years. However, there is an untrusted fusion problem. The reasons for this problem are as follows: 1) The current methods ignore the presence of noise or redundant information in the view; 2) The similarity of contrastive learning comes from the same sample rather than the same cluster in deep multi-view clustering. It causes multi-view fusion in the wrong direction. This paper proposes a novel multi-view clustering network to address this problem, termed as Trusted Mamba Contrastive Network (TMCN). Specifically, we present a new Trusted Mamba Fusion Network (TMFN), which achieves a trusted fusion of multi-view data through a selective mechanism. Moreover, we align the fused representation and the view-specific representation using the Average-similarity Contrastive Learning (AsCL) module. AsCL increases the similarity of view presentation from the same cluster, not merely from the same sample. Extensive experiments show that the proposed method achieves state-of-the-art results in deep multi-view clustering tasks.
AnomalyControl: Learning Cross-modal Semantic Features for Controllable Anomaly Synthesis
Dec 10, 2024
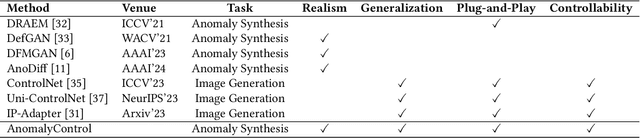
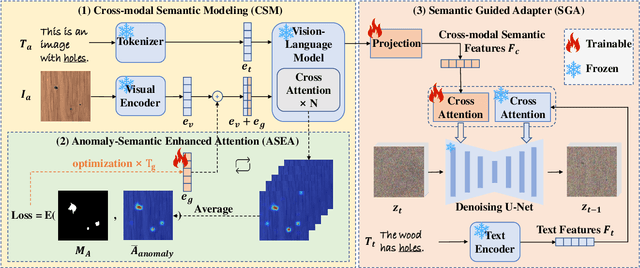
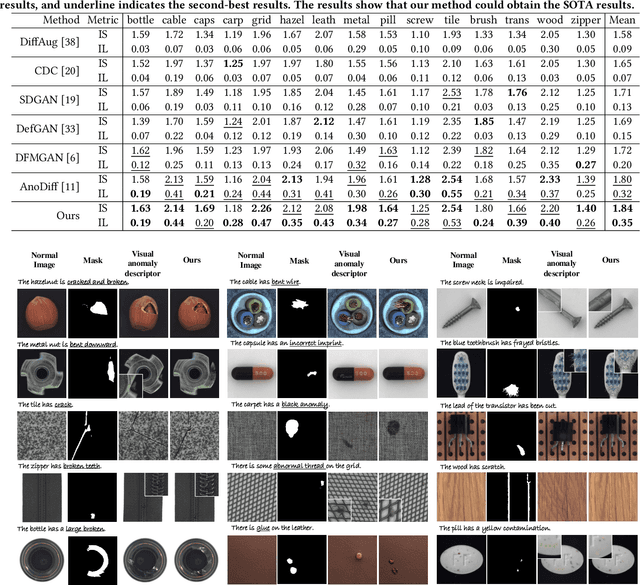
Anomaly synthesis is a crucial approach to augment abnormal data for advancing anomaly inspection. Based on the knowledge from the large-scale pre-training, existing text-to-image anomaly synthesis methods predominantly focus on textual information or coarse-aligned visual features to guide the entire generation process. However, these methods often lack sufficient descriptors to capture the complicated characteristics of realistic anomalies (e.g., the fine-grained visual pattern of anomalies), limiting the realism and generalization of the generation process. To this end, we propose a novel anomaly synthesis framework called AnomalyControl to learn cross-modal semantic features as guidance signals, which could encode the generalized anomaly cues from text-image reference prompts and improve the realism of synthesized abnormal samples. Specifically, AnomalyControl adopts a flexible and non-matching prompt pair (i.e., a text-image reference prompt and a targeted text prompt), where a Cross-modal Semantic Modeling (CSM) module is designed to extract cross-modal semantic features from the textual and visual descriptors. Then, an Anomaly-Semantic Enhanced Attention (ASEA) mechanism is formulated to allow CSM to focus on the specific visual patterns of the anomaly, thus enhancing the realism and contextual relevance of the generated anomaly features. Treating cross-modal semantic features as the prior, a Semantic Guided Adapter (SGA) is designed to encode effective guidance signals for the adequate and controllable synthesis process. Extensive experiments indicate that AnomalyControl can achieve state-of-the-art results in anomaly synthesis compared with existing methods while exhibiting superior performance for downstream tasks.
Medical Multimodal Foundation Models in Clinical Diagnosis and Treatment: Applications, Challenges, and Future Directions
Dec 03, 2024



Recent advancements in deep learning have significantly revolutionized the field of clinical diagnosis and treatment, offering novel approaches to improve diagnostic precision and treatment efficacy across diverse clinical domains, thus driving the pursuit of precision medicine. The growing availability of multi-organ and multimodal datasets has accelerated the development of large-scale Medical Multimodal Foundation Models (MMFMs). These models, known for their strong generalization capabilities and rich representational power, are increasingly being adapted to address a wide range of clinical tasks, from early diagnosis to personalized treatment strategies. This review offers a comprehensive analysis of recent developments in MMFMs, focusing on three key aspects: datasets, model architectures, and clinical applications. We also explore the challenges and opportunities in optimizing multimodal representations and discuss how these advancements are shaping the future of healthcare by enabling improved patient outcomes and more efficient clinical workflows.
HEMGS: A Hybrid Entropy Model for 3D Gaussian Splatting Data Compression
Nov 27, 2024



Fast progress in 3D Gaussian Splatting (3DGS) has made 3D Gaussians popular for 3D modeling and image rendering, but this creates big challenges in data storage and transmission. To obtain a highly compact 3DGS representation, we propose a hybrid entropy model for Gaussian Splatting (HEMGS) data compression, which comprises two primary components, a hyperprior network and an autoregressive network. To effectively reduce structural redundancy across attributes, we apply a progressive coding algorithm to generate hyperprior features, in which we use previously compressed attributes and location as prior information. In particular, to better extract the location features from these compressed attributes, we adopt a domain-aware and instance-aware architecture to respectively capture domain-aware structural relations without additional storage costs and reveal scene-specific features through MLPs. Additionally, to reduce redundancy within each attribute, we leverage relationships between neighboring compressed elements within the attributes through an autoregressive network. Given its unique structure, we propose an adaptive context coding algorithm with flexible receptive fields to effectively capture adjacent compressed elements. Overall, we integrate our HEMGS into an end-to-end optimized 3DGS compression framework and the extensive experimental results on four benchmarks indicate that our method achieves about 40\% average reduction in size while maintaining the rendering quality over our baseline method and achieving state-of-the-art compression results.
Towards Satellite Image Road Graph Extraction: A Global-Scale Dataset and A Novel Method
Nov 23, 2024



Recently, road graph extraction has garnered increasing attention due to its crucial role in autonomous driving, navigation, etc. However, accurately and efficiently extracting road graphs remains a persistent challenge, primarily due to the severe scarcity of labeled data. To address this limitation, we collect a global-scale satellite road graph extraction dataset, i.e. Global-Scale dataset. Specifically, the Global-Scale dataset is $\sim20 \times$ larger than the largest existing public road extraction dataset and spans over 13,800 $km^2$ globally. Additionally, we develop a novel road graph extraction model, i.e. SAM-Road++, which adopts a node-guided resampling method to alleviate the mismatch issue between training and inference in SAM-Road, a pioneering state-of-the-art road graph extraction model. Furthermore, we propose a simple yet effective ``extended-line'' strategy in SAM-Road++ to mitigate the occlusion issue on the road. Extensive experiments demonstrate the validity of the collected Global-Scale dataset and the proposed SAM-Road++ method, particularly highlighting its superior predictive power in unseen regions. The dataset and code are available at \url{https://github.com/earth-insights/samroadplus}.
Scaling up the Evaluation of Collaborative Problem Solving: Promises and Challenges of Coding Chat Data with ChatGPT
Nov 15, 2024



Collaborative problem solving (CPS) is widely recognized as a critical 21st century skill. Efficiently coding communication data is a big challenge in scaling up research on assessing CPS. This paper reports the findings on using ChatGPT to directly code CPS chat data by benchmarking performance across multiple datasets and coding frameworks. We found that ChatGPT-based coding outperformed human coding in tasks where the discussions were characterized by colloquial languages but fell short in tasks where the discussions dealt with specialized scientific terminology and contexts. The findings offer practical guidelines for researchers to develop strategies for efficient and scalable analysis of communication data from CPS tasks.
st-DTPM: Spatial-Temporal Guided Diffusion Transformer Probabilistic Model for Delayed Scan PET Image Prediction
Oct 30, 2024



PET imaging is widely employed for observing biological metabolic activities within the human body. However, numerous benign conditions can cause increased uptake of radiopharmaceuticals, confounding differentiation from malignant tumors. Several studies have indicated that dual-time PET imaging holds promise in distinguishing between malignant and benign tumor processes. Nevertheless, the hour-long distribution period of radiopharmaceuticals post-injection complicates the determination of optimal timing for the second scan, presenting challenges in both practical applications and research. Notably, we have identified that delay time PET imaging can be framed as an image-to-image conversion problem. Motivated by this insight, we propose a novel spatial-temporal guided diffusion transformer probabilistic model (st-DTPM) to solve dual-time PET imaging prediction problem. Specifically, this architecture leverages the U-net framework that integrates patch-wise features of CNN and pixel-wise relevance of Transformer to obtain local and global information. And then employs a conditional DDPM model for image synthesis. Furthermore, on spatial condition, we concatenate early scan PET images and noisy PET images on every denoising step to guide the spatial distribution of denoising sampling. On temporal condition, we convert diffusion time steps and delay time to a universal time vector, then embed it to each layer of model architecture to further improve the accuracy of predictions. Experimental results demonstrated the superiority of our method over alternative approaches in preserving image quality and structural information, thereby affirming its efficacy in predictive task.