 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning and Best-Response Dynamics
Jun 25, 2014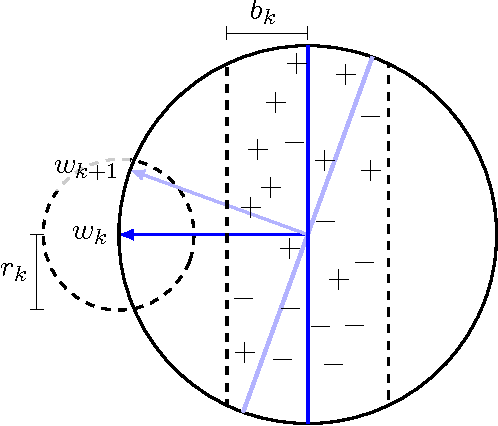
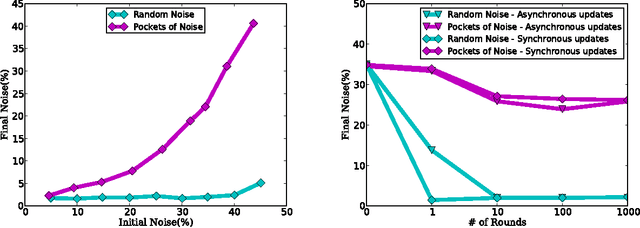
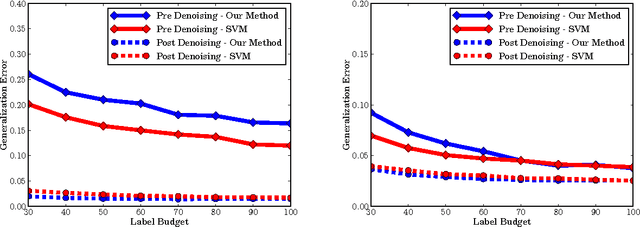
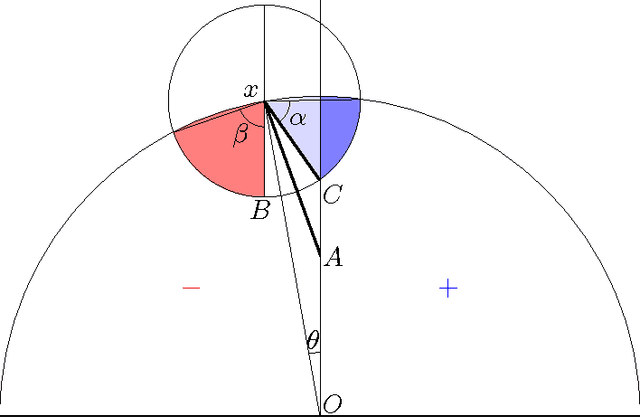
We examine an important setting for engineered systems in which low-power distributed sensors are each making highly noisy measurements of some unknown target function. A center wants to accurately learn this function by querying a small number of sensors, which ordinarily would be impossible due to the high noise rate. The question we address is whether local communication among sensors, together with natural best-response dynamics in an appropriately-defined game, can denoise the system without destroying the true signal and allow the center to succeed from only a small number of active queries. By using techniques from game theory and empirical processes, we prove positive (and negative) results on the denoising power of several natural dynamics. We then show experimentally that when combined with recent agnostic active learning algorithms, this process can achieve low error from very few queries, performing substantially better than active or passive learning without these denoising dynamics as well as passive learning with denoising.
Estimating Diffusion Network Structures: Recovery Conditions, Sample Complexity & Soft-thresholding Algorithm
May 12, 2014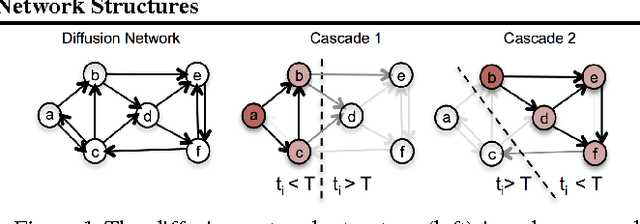

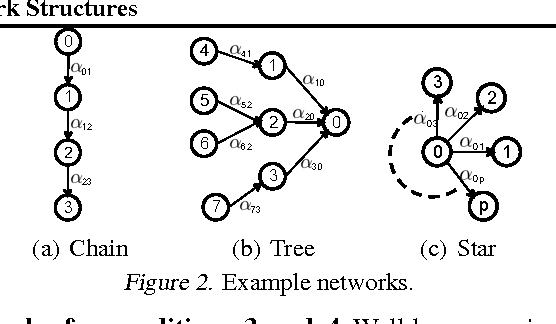
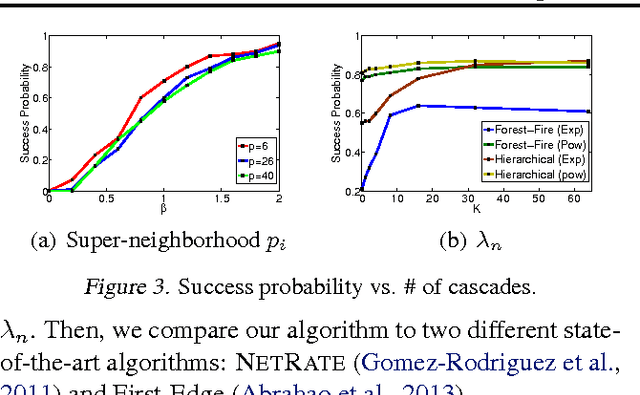
Information spreads across social and technological networks, but often the network structures are hidden from us and we only observe the traces left by the diffusion processes, called cascades. Can we recover the hidden network structures from these observed cascades? What kind of cascades and how many cascades do we need? Are there some network structures which are more difficult than others to recover? Can we design efficient inference algorithms with provable guarantees? Despite the increasing availability of cascade data and methods for inferring networks from these data, a thorough theoretical understanding of the above questions remains largely unexplored in the literature. In this paper, we investigate the network structure inference problem for a general family of continuous-time diffusion models using an $l_1$-regularized likelihood maximization framework. We show that, as long as the cascade sampling process satisfies a natural incoherence condition, our framework can recover the correct network structure with high probability if we observe $O(d^3 \log N)$ cascades, where $d$ is the maximum number of parents of a node and $N$ is the total number of nodes. Moreover, we develop a simple and efficient soft-thresholding inference algorithm, which we use to illustrate the consequences of our theoretical results, and show that our framework outperforms other alternatives in practice.
Budgeted Influence Maximization for Multiple Products
Apr 16, 2014
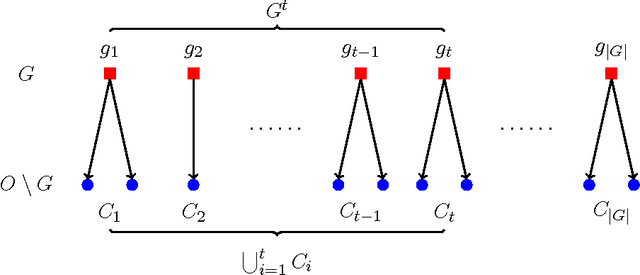
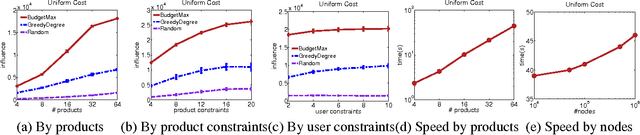
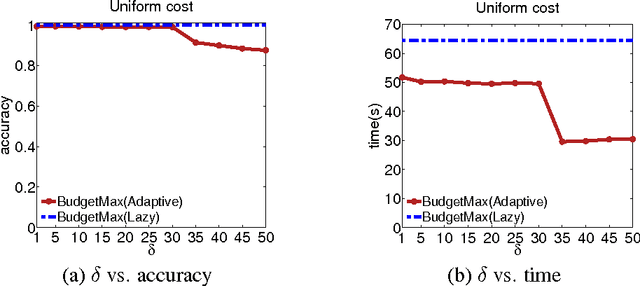
The typical algorithmic problem in viral marketing aims to identify a set of influential users in a social network, who, when convinced to adopt a product, shall influence other users in the network and trigger a large cascade of adoptions. However, the host (the owner of an online social platform) often faces more constraints than a single product, endless user attentions, unlimited budget and unbounded time; in reality, multiple products need to be advertised, each user can tolerate only a small number of recommendations, influencing user has a cost and advertisers have only limited budgets, and the adoptions need to be maximized within a short time window. Given theses myriads of user, monetary, and timing constraints, it is extremely challenging for the host to design principled and efficient viral market algorithms with provable guarantees. In this paper, we provide a novel solution by formulating the problem as a submodular maximization in a continuous-time diffusion model under an intersection of a matroid and multiple knapsack constraints. We also propose an adaptive threshold greedy algorithm which can be faster than the traditional greedy algorithm with lazy evaluation, and scalable to networks with million of nodes. Furthermore, our mathematical formulation allows us to prove that the algorithm can achieve an approximation factor of $k_a/(2+2 k)$ when $k_a$ out of the $k$ knapsack constraints are active, which also improves over previous guarantees from combinatorial optimization literature. In the case when influencing each user has uniform cost, the approximation becomes even better to a factor of $1/3$. Extensive synthetic and real world experiments demonstrate that our budgeted influence maximization algorithm achieves the-state-of-the-art in terms of both effectiveness and scalability, often beating the next best by significant margins.
Nonparametric Latent Tree Graphical Models: Inference, Estimation, and Structure Learning
Jan 16, 2014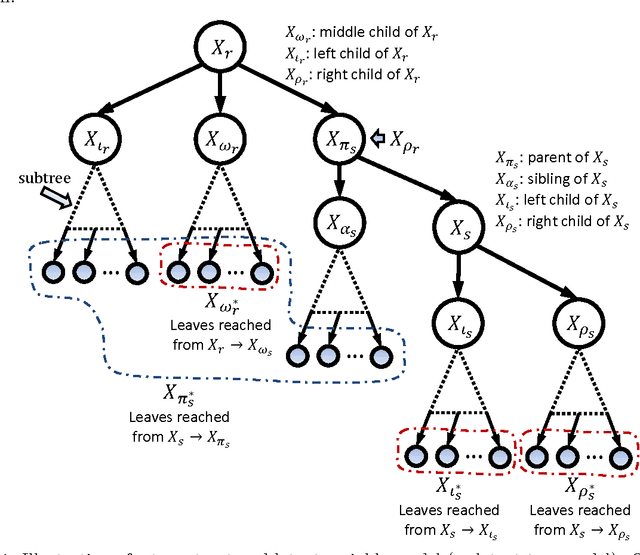
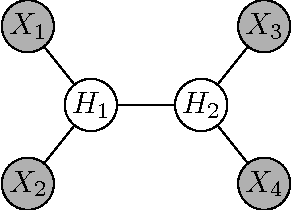
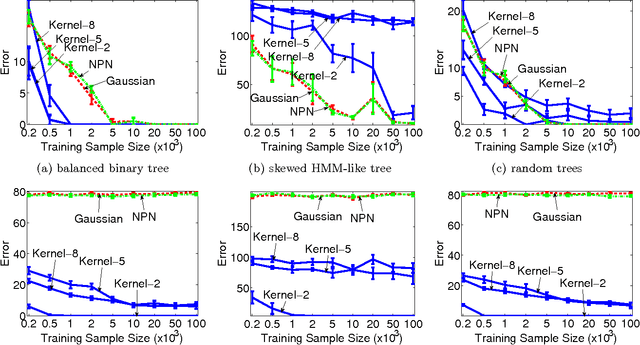
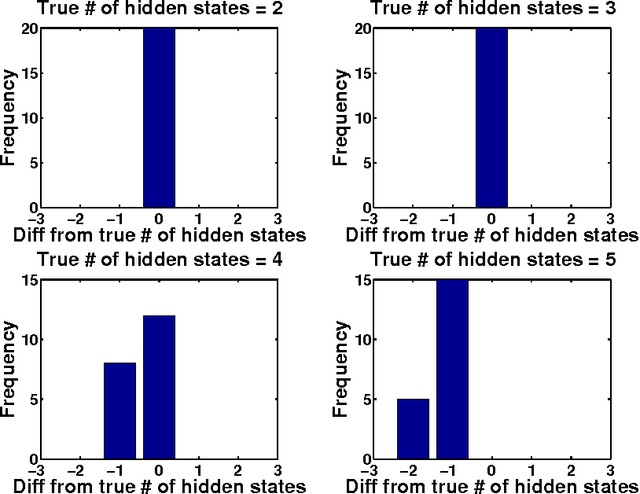
Tree structured graphical models are powerful at expressing long range or hierarchical dependency among many variables, and have been widely applied in different areas of computer science and statistics. However, existing methods for parameter estimation, inference, and structure learning mainly rely on the Gaussian or discrete assumptions, which are restrictive under many applications. In this paper, we propose new nonparametric methods based on reproducing kernel Hilbert space embeddings of distributions that can recover the latent tree structures, estimate the parameters, and perform inference for high dimensional continuous and non-Gaussian variables. The usefulness of the proposed methods are illustrated by thorough numerical results.
Nonparametric Estimation of Multi-View Latent Variable Models
Dec 08, 2013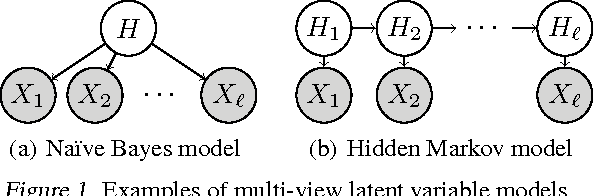
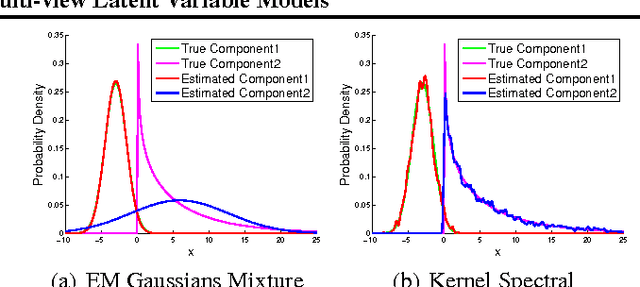
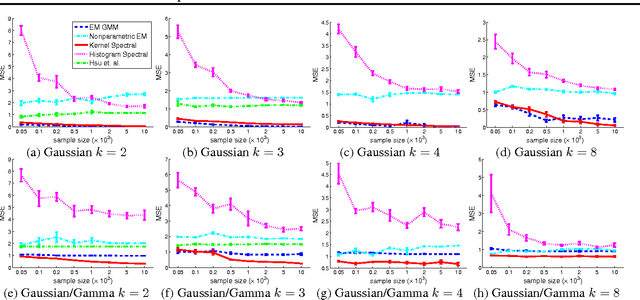
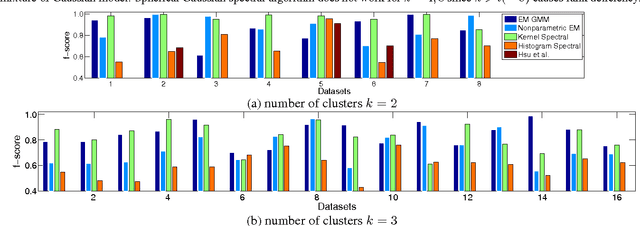
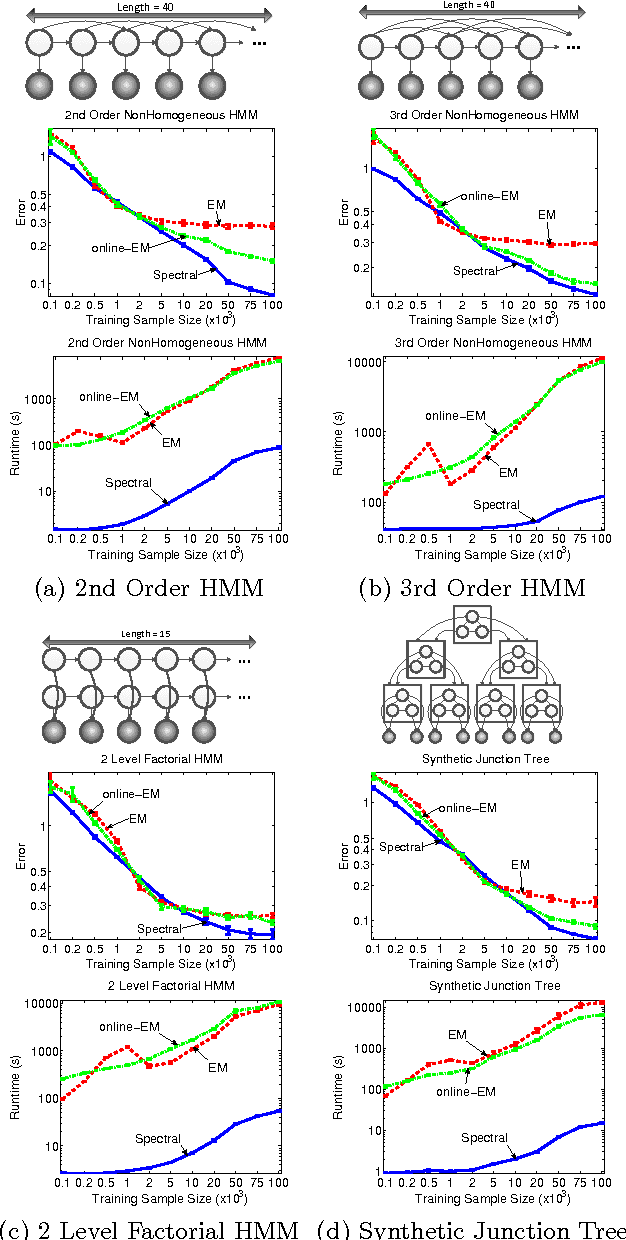
Spectral methods have greatly advanced the estimation of latent variable models, generating a sequence of novel and efficient algorithms with strong theoretical guarantees. However, current spectral algorithms are largely restricted to mixtures of discrete or Gaussian distributions. In this paper, we propose a kernel method for learning multi-view latent variable models, allowing each mixture component to be nonparametric. The key idea of the method is to embed the joint distribution of a multi-view latent variable into a reproducing kernel Hilbert space, and then the latent parameters are recovered using a robust tensor power method. We establish that the sample complexity for the proposed method is quadratic in the number of latent components and is a low order polynomial in the other relevant parameters. Thus, our non-parametric tensor approach to learning latent variable models enjoys good sample and computational efficiencies. Moreover, the non-parametric tensor power method compares favorably to EM algorithm and other existing spectral algorithms in our experiments.
Scalable Influence Estimation in Continuous-Time Diffusion Networks
Nov 14, 2013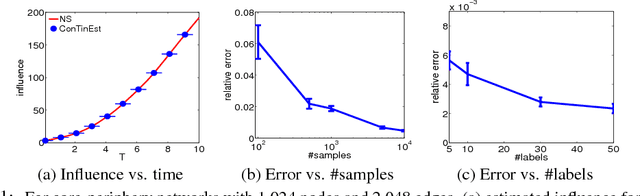
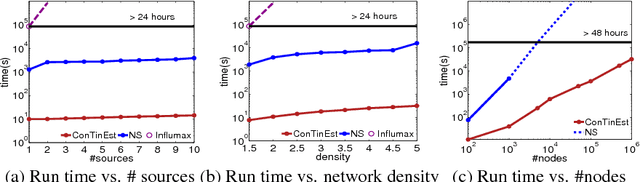
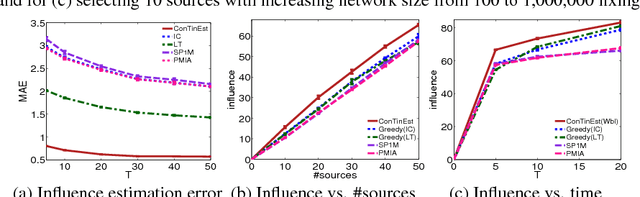
If a piece of information is released from a media site, can it spread, in 1 month, to a million web pages? This influence estimation problem is very challenging since both the time-sensitive nature of the problem and the issue of scalability need to be addressed simultaneously. In this paper, we propose a randomized algorithm for influence estimation in continuous-time diffusion networks. Our algorithm can estimate the influence of every node in a network with |V| nodes and |E| edges to an accuracy of $\varepsilon$ using $n=O(1/\varepsilon^2)$ randomizations and up to logarithmic factors O(n|E|+n|V|) computations. When used as a subroutine in a greedy influence maximization algorithm, our proposed method is guaranteed to find a set of nodes with an influence of at least (1-1/e)OPT-2$\varepsilon$, where OPT is the optimal value. Experiments on both synthetic and real-world data show that the proposed method can easily scale up to networks of millions of nodes while significantly improves over previous state-of-the-arts in terms of the accuracy of the estimated influence and the quality of the selected nodes in maximizing the influence.
Least Squares Revisited: Scalable Approaches for Multi-class Prediction
Oct 21, 2013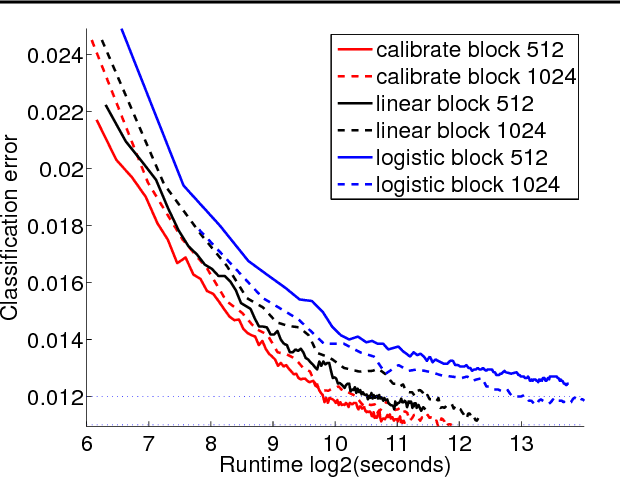

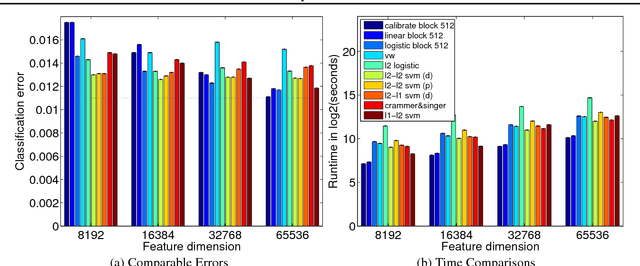
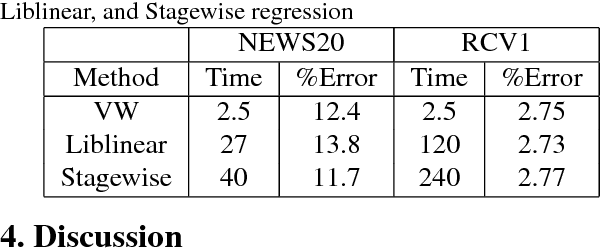
This work provides simple algorithms for multi-class (and multi-label) prediction in settings where both the number of examples n and the data dimension d are relatively large. These robust and parameter free algorithms are essentially iterative least-squares updates and very versatile both in theory and in practice. On the theoretical front, we present several variants with convergence guarantees. Owing to their effective use of second-order structure, these algorithms are substantially better than first-order methods in many practical scenarios. On the empirical side, we present a scalable stagewise variant of our approach, which achieves dramatic computational speedups over popular optimization packages such as Liblinear and Vowpal Wabbit on standard datasets (MNIST and CIFAR-10), while attaining state-of-the-art accuracies.
A Spectral Algorithm for Latent Junction Trees
Oct 16, 2012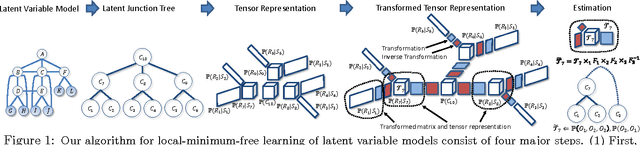
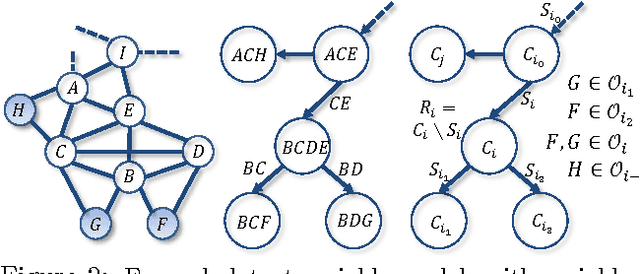
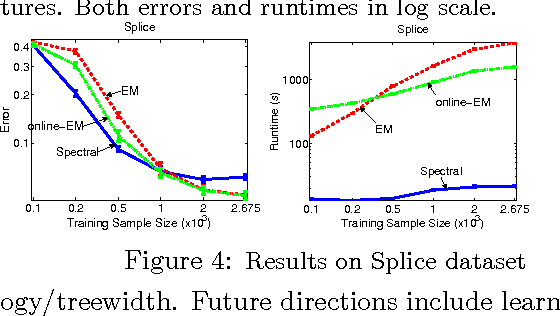
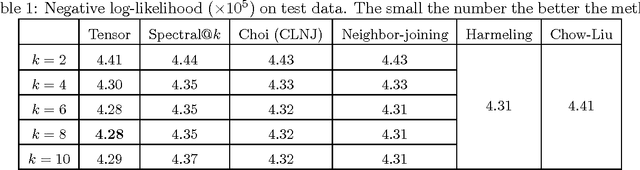
Latent variable models are an elegant framework for capturing rich probabilistic dependencies in many applications. However, current approaches typically parametrize these models using conditional probability tables, and learning relies predominantly on local search heuristics such as Expectation Maximization. Using tensor algebra, we propose an alternative parameterization of latent variable models (where the model structures are junction trees) that still allows for computation of marginals among observed variables. While this novel representation leads to a moderate increase in the number of parameters for junction trees of low treewidth, it lets us design a local-minimum-free algorithm for learning this parameterization. The main computation of the algorithm involves only tensor operations and SVDs which can be orders of magnitude faster than EM algorithms for large datasets. To our knowledge, this is the first provably consistent parameter learning technique for a large class of low-treewidth latent graphical models beyond trees. We demonstrate the advantages of our method on synthetic and real datasets.
Unfolding Latent Tree Structures using 4th Order Tensors
Oct 03, 2012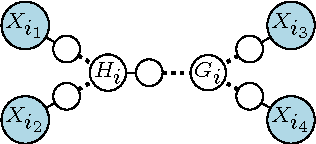
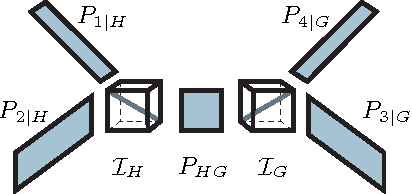
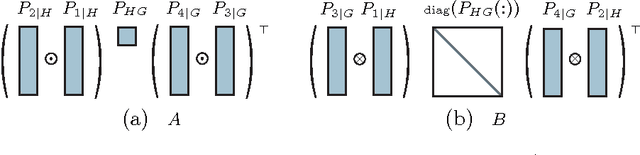
Discovering the latent structure from many observed variables is an important yet challenging learning task. Existing approaches for discovering latent structures often require the unknown number of hidden states as an input. In this paper, we propose a quartet based approach which is \emph{agnostic} to this number. The key contribution is a novel rank characterization of the tensor associated with the marginal distribution of a quartet. This characterization allows us to design a \emph{nuclear norm} based test for resolving quartet relations. We then use the quartet test as a subroutine in a divide-and-conquer algorithm for recovering the latent tree structure. Under mild conditions, the algorithm is consistent and its error probability decays exponentially with increasing sample size. We demonstrate that the proposed approach compares favorably to alternatives. In a real world stock dataset, it also discovers meaningful groupings of variables, and produces a model that fits the data better.
Spectral Methods for Learning Multivariate Latent Tree Structure
Nov 08, 2011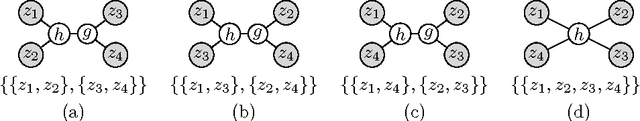
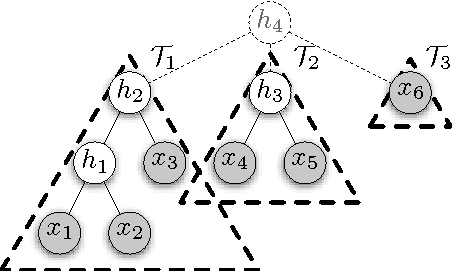
This work considers the problem of learning the structure of multivariate linear tree models, which include a variety of directed tree graphical models with continuous, discrete, and mixed latent variables such as linear-Gaussian models, hidden Markov models, Gaussian mixture models, and Markov evolutionary trees. The setting is one where we only have samples from certain observed variables in the tree, and our goal is to estimate the tree structure (i.e., the graph of how the underlying hidden variables are connected to each other and to the observed variables). We propose the Spectral Recursive Grouping algorithm, an efficient and simple bottom-up procedure for recovering the tree structure from independent samples of the observed variables. Our finite sample size bounds for exact recovery of the tree structure reveal certain natural dependencies on underlying statistical and structural properties of the underlying joint distribution. Furthermore, our sample complexity guarantees have no explicit dependence on the dimensionality of the observed variables, making the algorithm applicable to many high-dimensional settings. At the heart of our algorithm is a spectral quartet test for determining the relative topology of a quartet of variables from second-order statistics.