 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMalignancy Prediction and Lesion Identification from Clinical Dermatological Images
Apr 02, 2021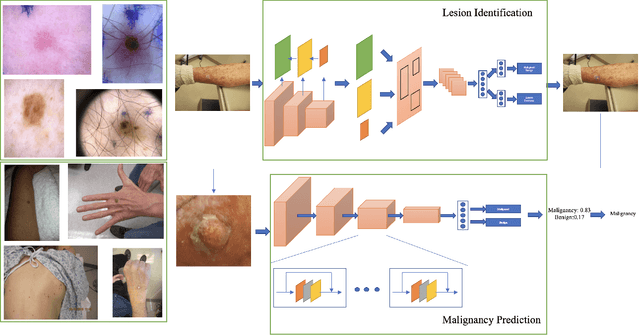
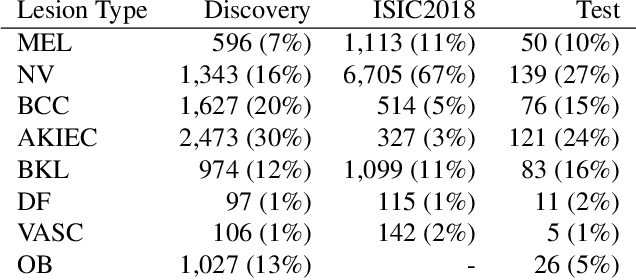
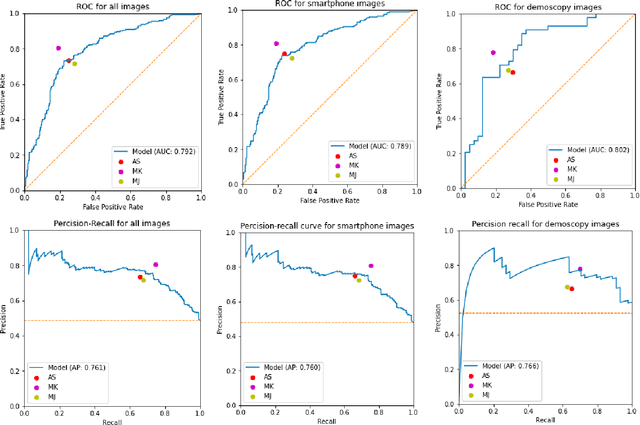
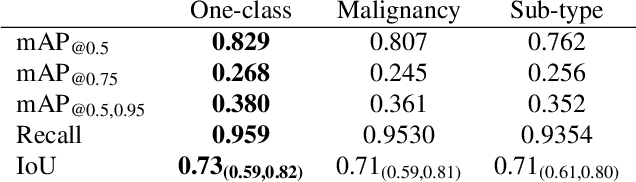
We consider machine-learning-based malignancy prediction and lesion identification from clinical dermatological images, which can be indistinctly acquired via smartphone or dermoscopy capture. Additionally, we do not assume that images contain single lesions, thus the framework supports both focal or wide-field images. Specifically, we propose a two-stage approach in which we first identify all lesions present in the image regardless of sub-type or likelihood of malignancy, then it estimates their likelihood of malignancy, and through aggregation, it also generates an image-level likelihood of malignancy that can be used for high-level screening processes. Further, we consider augmenting the proposed approach with clinical covariates (from electronic health records) and publicly available data (the ISIC dataset). Comprehensive experiments validated on an independent test dataset demonstrate that i) the proposed approach outperforms alternative model architectures; ii) the model based on images outperforms a pure clinical model by a large margin, and the combination of images and clinical data does not significantly improves over the image-only model; and iii) the proposed framework offers comparable performance in terms of malignancy classification relative to three board certified dermatologists with different levels of experience.
Efficient Feature Transformations for Discriminative and Generative Continual Learning
Mar 25, 2021
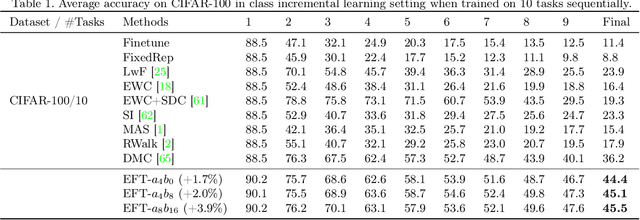
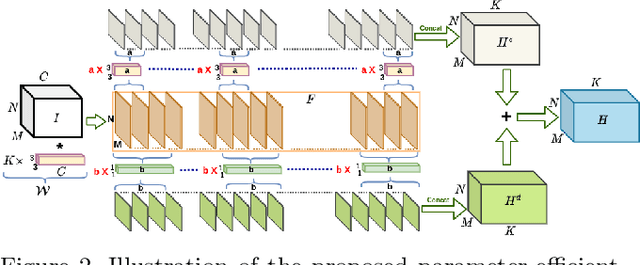
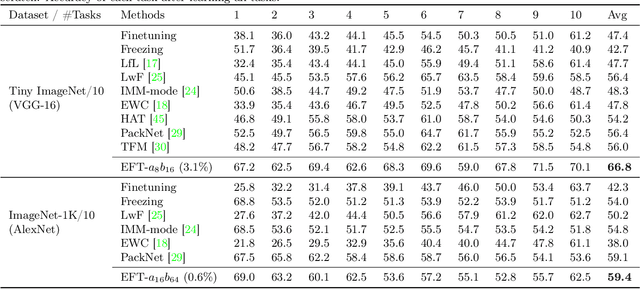
As neural networks are increasingly being applied to real-world applications, mechanisms to address distributional shift and sequential task learning without forgetting are critical. Methods incorporating network expansion have shown promise by naturally adding model capacity for learning new tasks while simultaneously avoiding catastrophic forgetting. However, the growth in the number of additional parameters of many of these types of methods can be computationally expensive at larger scales, at times prohibitively so. Instead, we propose a simple task-specific feature map transformation strategy for continual learning, which we call Efficient Feature Transformations (EFTs). These EFTs provide powerful flexibility for learning new tasks, achieved with minimal parameters added to the base architecture. We further propose a feature distance maximization strategy, which significantly improves task prediction in class incremental settings, without needing expensive generative models. We demonstrate the efficacy and efficiency of our method with an extensive set of experiments in discriminative (CIFAR-100 and ImageNet-1K) and generative (LSUN, CUB-200, Cats) sequences of tasks. Even with low single-digit parameter growth rates, EFTs can outperform many other continual learning methods in a wide range of settings.
Improving Zero-shot Voice Style Transfer via Disentangled Representation Learning
Mar 17, 2021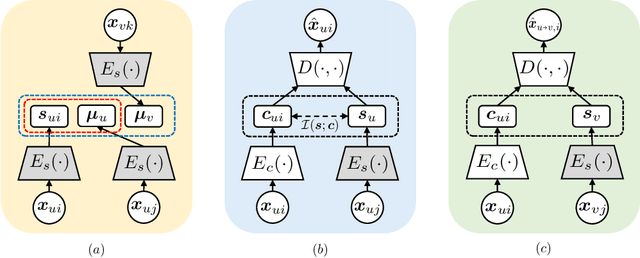


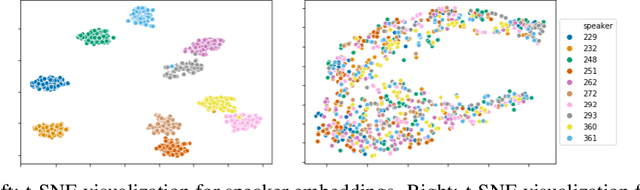
Voice style transfer, also called voice conversion, seeks to modify one speaker's voice to generate speech as if it came from another (target) speaker. Previous works have made progress on voice conversion with parallel training data and pre-known speakers. However, zero-shot voice style transfer, which learns from non-parallel data and generates voices for previously unseen speakers, remains a challenging problem. We propose a novel zero-shot voice transfer method via disentangled representation learning. The proposed method first encodes speaker-related style and voice content of each input voice into separated low-dimensional embedding spaces, and then transfers to a new voice by combining the source content embedding and target style embedding through a decoder. With information-theoretic guidance, the style and content embedding spaces are representative and (ideally) independent of each other. On real-world VCTK datasets, our method outperforms other baselines and obtains state-of-the-art results in terms of transfer accuracy and voice naturalness for voice style transfer experiments under both many-to-many and zero-shot setups.
FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders
Mar 11, 2021
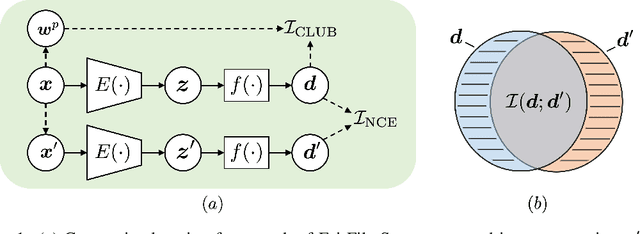
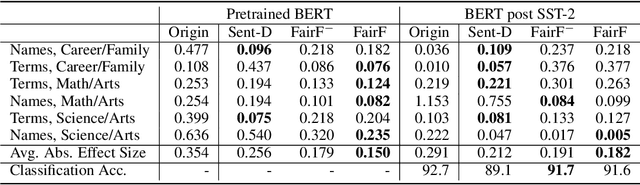
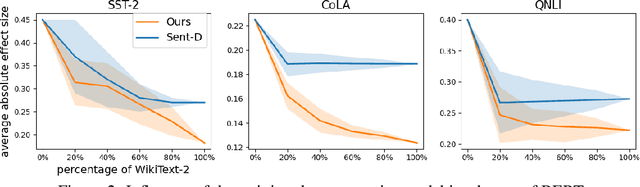
Pretrained text encoders, such as BERT, have been applied increasingly in various natural language processing (NLP) tasks, and have recently demonstrated significant performance gains. However, recent studies have demonstrated the existence of social bias in these pretrained NLP models. Although prior works have made progress on word-level debiasing, improved sentence-level fairness of pretrained encoders still lacks exploration. In this paper, we proposed the first neural debiasing method for a pretrained sentence encoder, which transforms the pretrained encoder outputs into debiased representations via a fair filter (FairFil) network. To learn the FairFil, we introduce a contrastive learning framework that not only minimizes the correlation between filtered embeddings and bias words but also preserves rich semantic information of the original sentences. On real-world datasets, our FairFil effectively reduces the bias degree of pretrained text encoders, while continuously showing desirable performance on downstream tasks. Moreover, our post-hoc method does not require any retraining of the text encoders, further enlarging FairFil's application space.
Efficient Continual Adaptation for Generative Adversarial Networks
Mar 06, 2021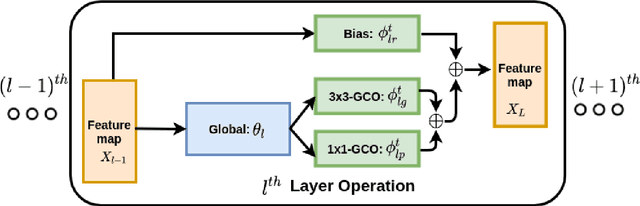

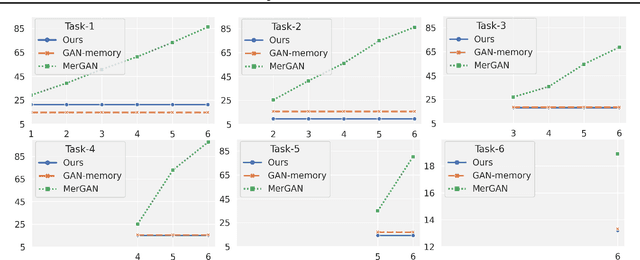

We present a continual learning approach for generative adversarial networks (GANs), by designing and leveraging parameter-efficient feature map transformations. Our approach is based on learning a set of global and task-specific parameters. The global parameters are fixed across tasks whereas the task specific parameters act as local adapters for each task, and help in efficiently transforming the previous task's feature map to the new task's feature map. Moreover, we propose an element-wise residual bias in the transformed feature space which highly stabilizes GAN training. In contrast to the recent approaches for continual GANs, we do not rely on memory replay, regularization towards previous tasks' parameters, or expensive weight transformations. Through extensive experiments on challenging and diverse datasets, we show that the feature-map transformation based approach outperforms state-of-the-art continual GANs methods, with substantially fewer parameters, and also generates high-quality samples that can be used in generative replay based continual learning of discriminative tasks.
Meta-Learned Attribute Self-Gating for Continual Generalized Zero-Shot Learning
Feb 23, 2021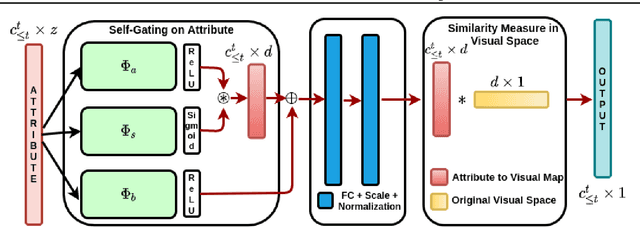
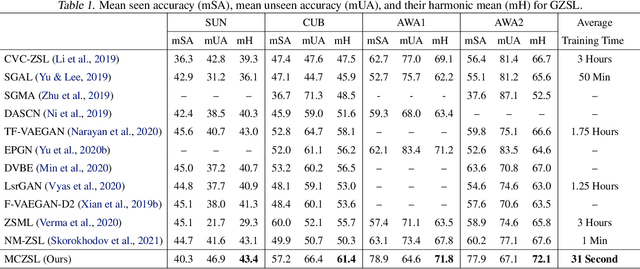
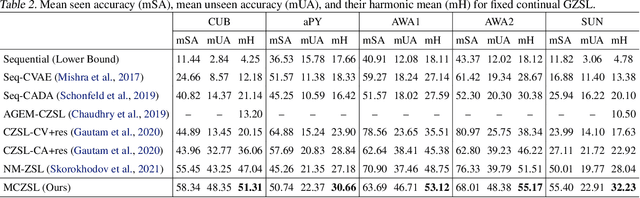
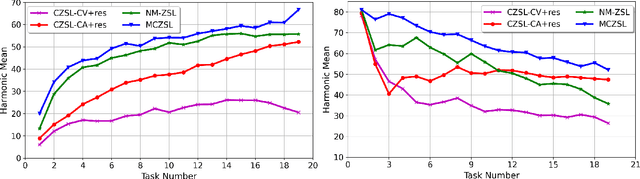
Zero-shot learning (ZSL) has been shown to be a promising approach to generalizing a model to categories unseen during training by leveraging class attributes, but challenges still remain. Recently, methods using generative models to combat bias towards classes seen during training have pushed the state of the art of ZSL, but these generative models can be slow or computationally expensive to train. Additionally, while many previous ZSL methods assume a one-time adaptation to unseen classes, in reality, the world is always changing, necessitating a constant adjustment for deployed models. Models unprepared to handle a sequential stream of data are likely to experience catastrophic forgetting. We propose a meta-continual zero-shot learning (MCZSL) approach to address both these issues. In particular, by pairing self-gating of attributes and scaled class normalization with meta-learning based training, we are able to outperform state-of-the-art results while being able to train our models substantially faster ($>100\times$) than expensive generative-based approaches. We demonstrate this by performing experiments on five standard ZSL datasets (CUB, aPY, AWA1, AWA2 and SUN) in both generalized zero-shot learning and generalized continual zero-shot learning settings.
FLOP: Federated Learning on Medical Datasets using Partial Networks
Feb 10, 2021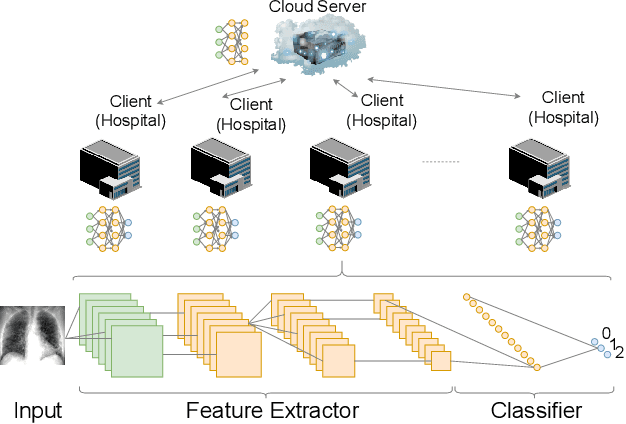
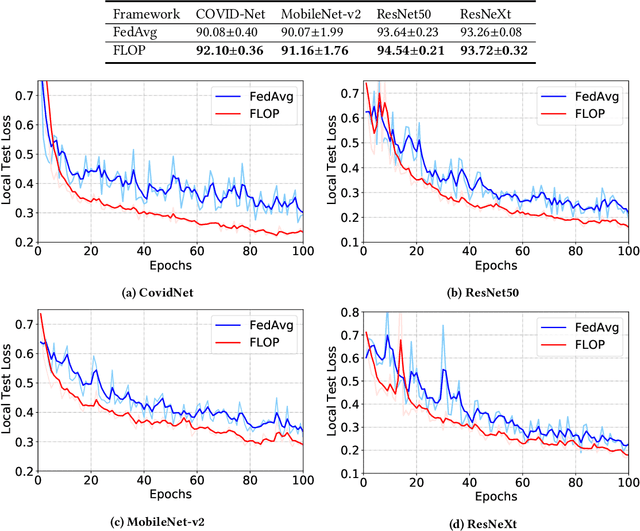
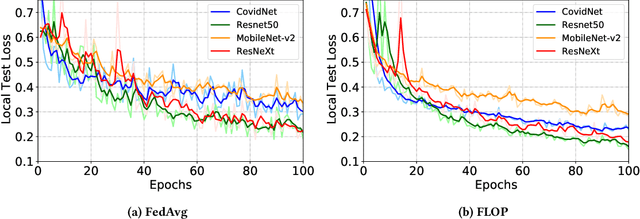

The outbreak of COVID-19 Disease due to the novel coronavirus has caused a shortage of medical resources. To aid and accelerate the diagnosis process, automatic diagnosis of COVID-19 via deep learning models has recently been explored by researchers across the world. While different data-driven deep learning models have been developed to mitigate the diagnosis of COVID-19, the data itself is still scarce due to patient privacy concerns. Federated Learning (FL) is a natural solution because it allows different organizations to cooperatively learn an effective deep learning model without sharing raw data. However, recent studies show that FL still lacks privacy protection and may cause data leakage. We investigate this challenging problem by proposing a simple yet effective algorithm, named \textbf{F}ederated \textbf{L}earning \textbf{o}n Medical Datasets using \textbf{P}artial Networks (FLOP), that shares only a partial model between the server and clients. Extensive experiments on benchmark data and real-world healthcare tasks show that our approach achieves comparable or better performance while reducing the privacy and security risks. Of particular interest, we conduct experiments on the COVID-19 dataset and find that our FLOP algorithm can allow different hospitals to collaboratively and effectively train a partially shared model without sharing local patients' data.
Reinforcement Learning for Flexibility Design Problems
Jan 18, 2021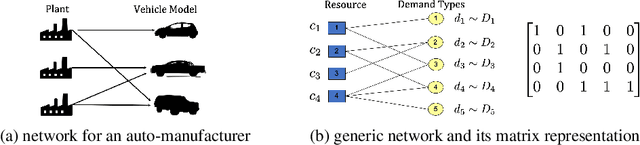

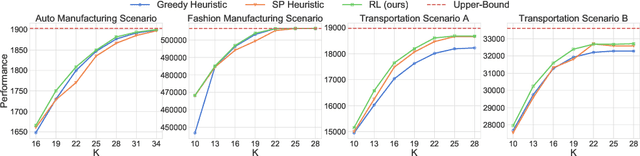

Flexibility design problems are a class of problems that appear in strategic decision-making across industries, where the objective is to design a ($e.g.$, manufacturing) network that affords flexibility and adaptivity. The underlying combinatorial nature and stochastic objectives make flexibility design problems challenging for standard optimization methods. In this paper, we develop a reinforcement learning (RL) framework for flexibility design problems. Specifically, we carefully design mechanisms with noisy exploration and variance reduction to ensure empirical success and show the unique advantage of RL in terms of fast-adaptation. Empirical results show that the RL-based method consistently finds better solutions compared to classical heuristics.
What Makes Good In-Context Examples for GPT-$3$?
Jan 17, 2021
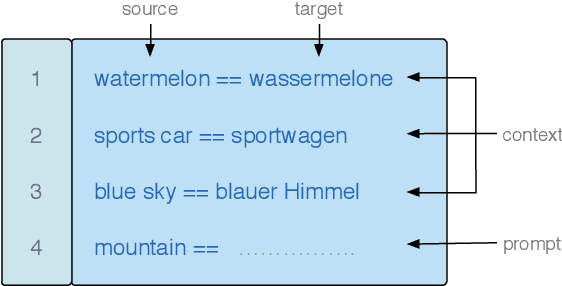
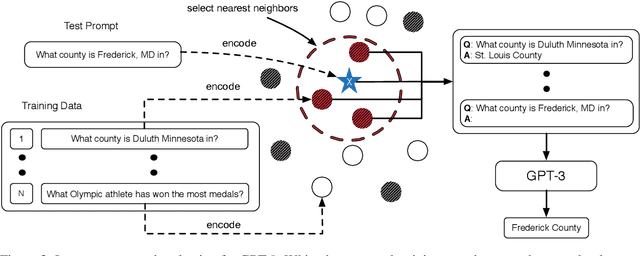
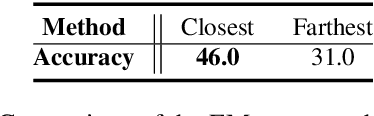
GPT-$3$ has attracted lots of attention due to its superior performance across a wide range of NLP tasks, especially with its powerful and versatile in-context few-shot learning ability. Despite its success, we found that the empirical results of GPT-$3$ depend heavily on the choice of in-context examples. In this work, we investigate whether there are more effective strategies for judiciously selecting in-context examples (relative to random sampling) that better leverage GPT-$3$'s few-shot capabilities. Inspired by the recent success of leveraging a retrieval module to augment large-scale neural network models, we propose to retrieve examples that are semantically-similar to a test sample to formulate its corresponding prompt. Intuitively, the in-context examples selected with such a strategy may serve as more informative inputs to unleash GPT-$3$'s extensive knowledge. We evaluate the proposed approach on several natural language understanding and generation benchmarks, where the retrieval-based prompt selection approach consistently outperforms the random baseline. Moreover, it is observed that the sentence encoders fine-tuned on task-related datasets yield even more helpful retrieval results. Notably, significant gains are observed on tasks such as table-to-text generation (41.9% on the ToTTo dataset) and open-domain question answering (45.5% on the NQ dataset). We hope our investigation could help understand the behaviors of GPT-$3$ and large-scale pre-trained LMs in general and enhance their few-shot capabilities.
Learning Graphons via Structured Gromov-Wasserstein Barycenters
Dec 17, 2020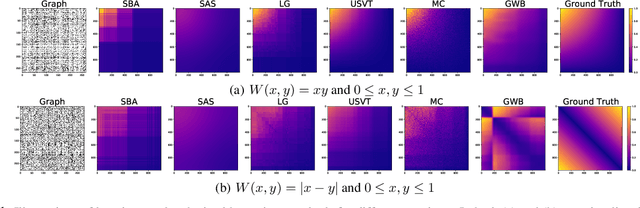
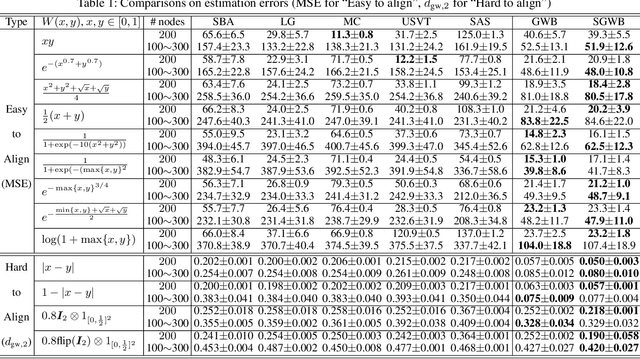
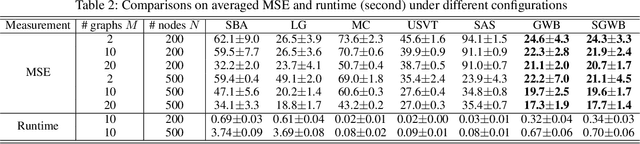
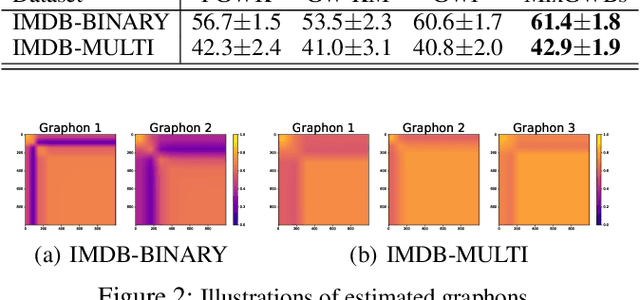
We propose a novel and principled method to learn a nonparametric graph model called graphon, which is defined in an infinite-dimensional space and represents arbitrary-size graphs. Based on the weak regularity lemma from the theory of graphons, we leverage a step function to approximate a graphon. We show that the cut distance of graphons can be relaxed to the Gromov-Wasserstein distance of their step functions. Accordingly, given a set of graphs generated by an underlying graphon, we learn the corresponding step function as the Gromov-Wasserstein barycenter of the given graphs. Furthermore, we develop several enhancements and extensions of the basic algorithm, $e.g.$, the smoothed Gromov-Wasserstein barycenter for guaranteeing the continuity of the learned graphons and the mixed Gromov-Wasserstein barycenters for learning multiple structured graphons. The proposed approach overcomes drawbacks of prior state-of-the-art methods, and outperforms them on both synthetic and real-world data. The code is available at https://github.com/HongtengXu/SGWB-Graphon.