 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Modular LLMs by Building and Reusing a Library of LoRAs
May 18, 2024



The growing number of parameter-efficient adaptations of a base large language model (LLM) calls for studying whether we can reuse such trained adapters to improve performance for new tasks. We study how to best build a library of adapters given multi-task data and devise techniques for both zero-shot and supervised task generalization through routing in such library. We benchmark existing approaches to build this library and introduce model-based clustering, MBC, a method that groups tasks based on the similarity of their adapter parameters, indirectly optimizing for transfer across the multi-task dataset. To re-use the library, we present a novel zero-shot routing mechanism, Arrow, which enables dynamic selection of the most relevant adapters for new inputs without the need for retraining. We experiment with several LLMs, such as Phi-2 and Mistral, on a wide array of held-out tasks, verifying that MBC-based adapters and Arrow routing lead to superior generalization to new tasks. We make steps towards creating modular, adaptable LLMs that can match or outperform traditional joint training.
Integrating Present and Past in Unsupervised Continual Learning
Apr 29, 2024



We formulate a unifying framework for unsupervised continual learning (UCL), which disentangles learning objectives that are specific to the present and the past data, encompassing stability, plasticity, and cross-task consolidation. The framework reveals that many existing UCL approaches overlook cross-task consolidation and try to balance plasticity and stability in a shared embedding space. This results in worse performance due to a lack of within-task data diversity and reduced effectiveness in learning the current task. Our method, Osiris, which explicitly optimizes all three objectives on separate embedding spaces, achieves state-of-the-art performance on all benchmarks, including two novel benchmarks proposed in this paper featuring semantically structured task sequences. Compared to standard benchmarks, these two structured benchmarks more closely resemble visual signals received by humans and animals when navigating real-world environments. Finally, we show some preliminary evidence that continual models can benefit from such realistic learning scenarios.
LitLLM: A Toolkit for Scientific Literature Review
Feb 02, 2024



Conducting literature reviews for scientific papers is essential for understanding research, its limitations, and building on existing work. It is a tedious task which makes an automatic literature review generator appealing. Unfortunately, many existing works that generate such reviews using Large Language Models (LLMs) have significant limitations. They tend to hallucinate-generate non-actual information-and ignore the latest research they have not been trained on. To address these limitations, we propose a toolkit that operates on Retrieval Augmented Generation (RAG) principles, specialized prompting and instructing techniques with the help of LLMs. Our system first initiates a web search to retrieve relevant papers by summarizing user-provided abstracts into keywords using an off-the-shelf LLM. Authors can enhance the search by supplementing it with relevant papers or keywords, contributing to a tailored retrieval process. Second, the system re-ranks the retrieved papers based on the user-provided abstract. Finally, the related work section is generated based on the re-ranked results and the abstract. There is a substantial reduction in time and effort for literature review compared to traditional methods, establishing our toolkit as an efficient alternative. Our open-source toolkit is accessible at https://github.com/shubhamagarwal92/LitLLM and Huggingface space (https://huggingface.co/spaces/shubhamagarwal92/LitLLM) with the video demo at https://youtu.be/E2ggOZBAFw0.
Improving the generalizability and robustness of large-scale traffic signal control
Jun 08, 2023A number of deep reinforcement-learning (RL) approaches propose to control traffic signals. In this work, we study the robustness of such methods along two axes. First, sensor failures and GPS occlusions create missing-data challenges and we show that recent methods remain brittle in the face of these missing data. Second, we provide a more systematic study of the generalization ability of RL methods to new networks with different traffic regimes. Again, we identify the limitations of recent approaches. We then propose using a combination of distributional and vanilla reinforcement learning through a policy ensemble. Building upon the state-of-the-art previous model which uses a decentralized approach for large-scale traffic signal control with graph convolutional networks (GCNs), we first learn models using a distributional reinforcement learning (DisRL) approach. In particular, we use implicit quantile networks (IQN) to model the state-action return distribution with quantile regression. For traffic signal control problems, an ensemble of standard RL and DisRL yields superior performance across different scenarios, including different levels of missing sensor data and traffic flow patterns. Furthermore, the learning scheme of the resulting model can improve zero-shot transferability to different road network structures, including both synthetic networks and real-world networks (e.g., Luxembourg, Manhattan). We conduct extensive experiments to compare our approach to multi-agent reinforcement learning and traditional transportation approaches. Results show that the proposed method improves robustness and generalizability in the face of missing data, varying road networks, and traffic flows.
Joint Bayesian Inference of Graphical Structure and Parameters with a Single Generative Flow Network
May 30, 2023



Generative Flow Networks (GFlowNets), a class of generative models over discrete and structured sample spaces, have been previously applied to the problem of inferring the marginal posterior distribution over the directed acyclic graph (DAG) of a Bayesian Network, given a dataset of observations. Based on recent advances extending this framework to non-discrete sample spaces, we propose in this paper to approximate the joint posterior over not only the structure of a Bayesian Network, but also the parameters of its conditional probability distributions. We use a single GFlowNet whose sampling policy follows a two-phase process: the DAG is first generated sequentially one edge at a time, and then the corresponding parameters are picked once the full structure is known. Since the parameters are included in the posterior distribution, this leaves more flexibility for the local probability models of the Bayesian Network, making our approach applicable even to non-linear models parametrized by neural networks. We show that our method, called JSP-GFN, offers an accurate approximation of the joint posterior, while comparing favorably against existing methods on both simulated and real data.
Towards Compute-Optimal Transfer Learning
Apr 25, 2023



The field of transfer learning is undergoing a significant shift with the introduction of large pretrained models which have demonstrated strong adaptability to a variety of downstream tasks. However, the high computational and memory requirements to finetune or use these models can be a hindrance to their widespread use. In this study, we present a solution to this issue by proposing a simple yet effective way to trade computational efficiency for asymptotic performance which we define as the performance a learning algorithm achieves as compute tends to infinity. Specifically, we argue that zero-shot structured pruning of pretrained models allows them to increase compute efficiency with minimal reduction in performance. We evaluate our method on the Nevis'22 continual learning benchmark that offers a diverse set of transfer scenarios. Our results show that pruning convolutional filters of pretrained models can lead to more than 20% performance improvement in low computational regimes.
Bayesian learning of Causal Structure and Mechanisms with GFlowNets and Variational Bayes
Nov 04, 2022



Bayesian causal structure learning aims to learn a posterior distribution over directed acyclic graphs (DAGs), and the mechanisms that define the relationship between parent and child variables. By taking a Bayesian approach, it is possible to reason about the uncertainty of the causal model. The notion of modelling the uncertainty over models is particularly crucial for causal structure learning since the model could be unidentifiable when given only a finite amount of observational data. In this paper, we introduce a novel method to jointly learn the structure and mechanisms of the causal model using Variational Bayes, which we call Variational Bayes-DAG-GFlowNet (VBG). We extend the method of Bayesian causal structure learning using GFlowNets to learn not only the posterior distribution over the structure, but also the parameters of a linear-Gaussian model. Our results on simulated data suggest that VBG is competitive against several baselines in modelling the posterior over DAGs and mechanisms, while offering several advantages over existing methods, including the guarantee to sample acyclic graphs, and the flexibility to generalize to non-linear causal mechanisms.
Model-based graph reinforcement learning for inductive traffic signal control
Aug 01, 2022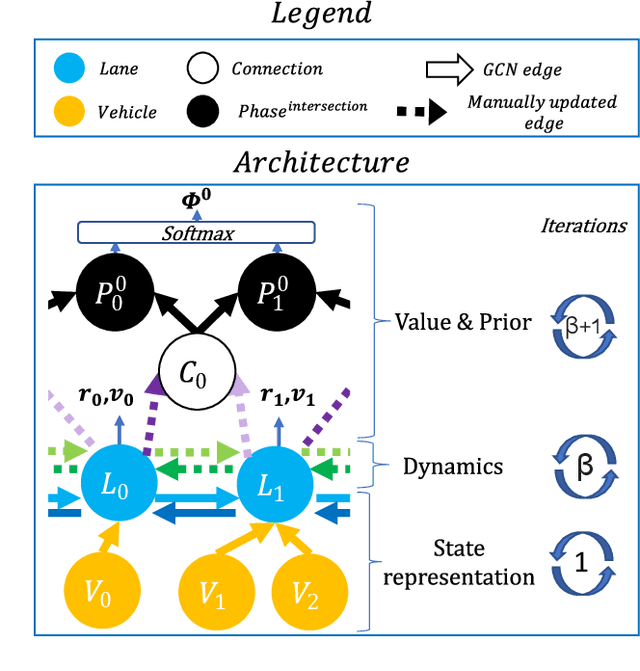
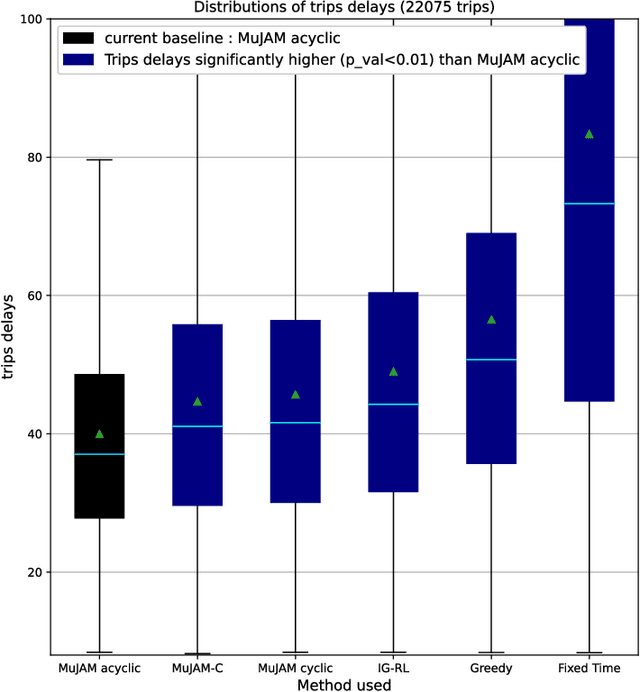
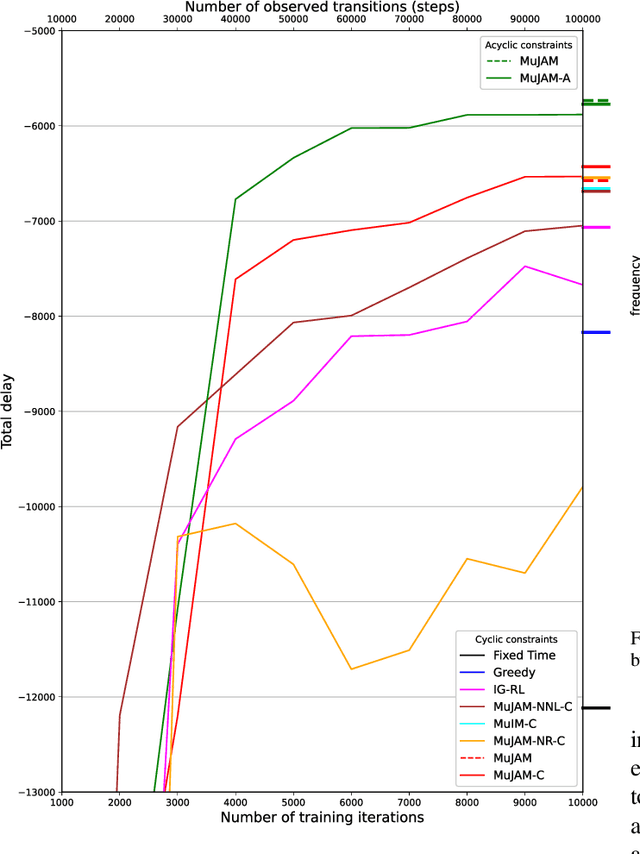
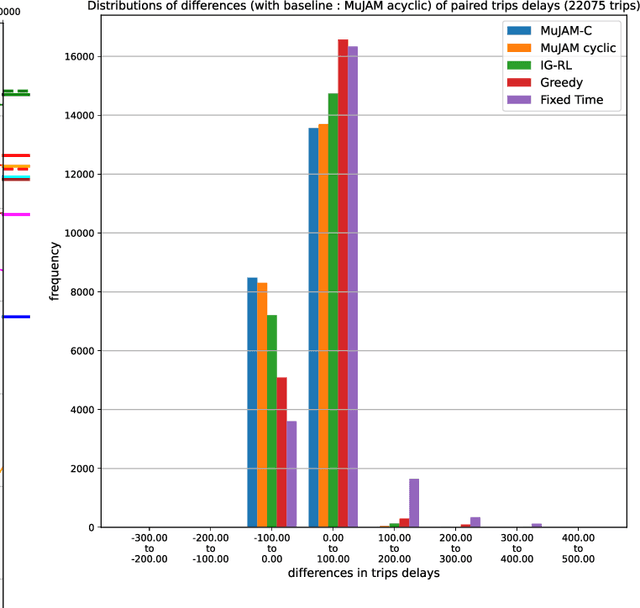
Most reinforcement learning methods for adaptive-traffic-signal-control require training from scratch to be applied on any new intersection or after any modification to the road network, traffic distribution, or behavioral constraints experienced during training. Considering 1) the massive amount of experience required to train such methods, and 2) that experience must be gathered by interacting in an exploratory fashion with real road-network-users, such a lack of transferability limits experimentation and applicability. Recent approaches enable learning policies that generalize for unseen road-network topologies and traffic distributions, partially tackling this challenge. However, the literature remains divided between the learning of cyclic (the evolution of connectivity at an intersection must respect a cycle) and acyclic (less constrained) policies, and these transferable methods 1) are only compatible with cyclic constraints and 2) do not enable coordination. We introduce a new model-based method, MuJAM, which, on top of enabling explicit coordination at scale for the first time, pushes generalization further by allowing a generalization to the controllers' constraints. In a zero-shot transfer setting involving both road networks and traffic settings never experienced during training, and in a larger transfer experiment involving the control of 3,971 traffic signal controllers in Manhattan, we show that MuJAM, using both cyclic and acyclic constraints, outperforms domain-specific baselines as well as another transferable approach.
Scaling the Number of Tasks in Continual Learning
Jul 10, 2022
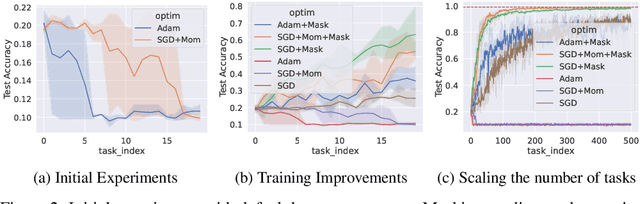

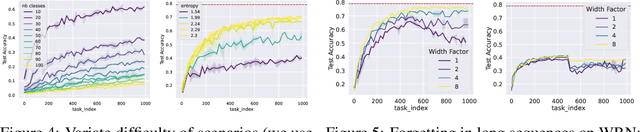
Standard gradient descent algorithms applied to sequences of tasks are known to produce catastrophic forgetting in deep neural networks. When trained on a new task in a sequence, the model updates its parameters on the current task, forgetting past knowledge. This article explores scenarios where we scale the number of tasks in a finite environment. Those scenarios are composed of a long sequence of tasks with reoccurring data. We show that in such setting, stochastic gradient descent can learn, progress, and converge to a solution that according to existing literature needs a continual learning algorithm. In other words, we show that the model performs knowledge retention and accumulation without specific memorization mechanisms. We propose a new experimentation framework, SCoLe (Scaling Continual Learning), to study the knowledge retention and accumulation of algorithms in potentially infinite sequences of tasks. To explore this setting, we performed a large number of experiments on sequences of 1,000 tasks to better understand this new family of settings. We also propose a slight modifications to the vanilla stochastic gradient descent to facilitate continual learning in this setting. The SCoLe framework represents a good simulation of practical training environments with reoccurring situations and allows the study of convergence behavior in long sequences. Our experiments show that previous results on short scenarios cannot always be extrapolated to longer scenarios.
Learning To Cut By Looking Ahead: Cutting Plane Selection via Imitation Learning
Jun 27, 2022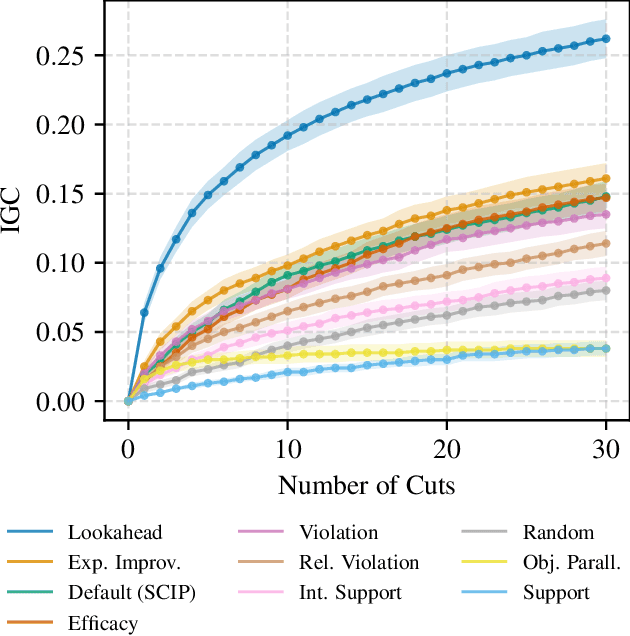
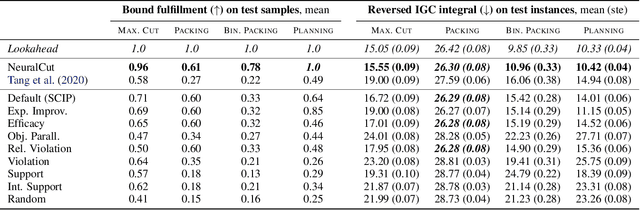
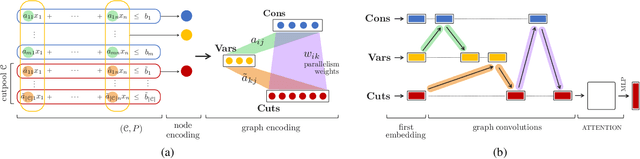
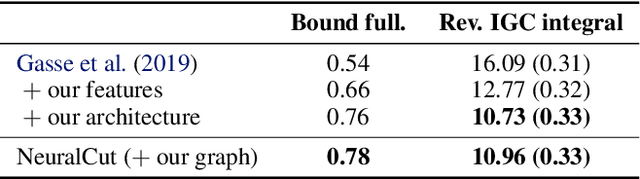
Cutting planes are essential for solving mixed-integer linear problems (MILPs), because they facilitate bound improvements on the optimal solution value. For selecting cuts, modern solvers rely on manually designed heuristics that are tuned to gauge the potential effectiveness of cuts. We show that a greedy selection rule explicitly looking ahead to select cuts that yield the best bound improvement delivers strong decisions for cut selection - but is too expensive to be deployed in practice. In response, we propose a new neural architecture (NeuralCut) for imitation learning on the lookahead expert. Our model outperforms standard baselines for cut selection on several synthetic MILP benchmarks. Experiments with a B&C solver for neural network verification further validate our approach, and exhibit the potential of learning methods in this setting.