 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Compression Perspective on Simplicity Bias
Mar 26, 2026Deep neural networks exhibit a simplicity bias, a well-documented tendency to favor simple functions over complex ones. In this work, we cast new light on this phenomenon through the lens of the Minimum Description Length principle, formalizing supervised learning as a problem of optimal two-part lossless compression. Our theory explains how simplicity bias governs feature selection in neural networks through a fundamental trade-off between model complexity (the cost of describing the hypothesis) and predictive power (the cost of describing the data). Our framework predicts that as the amount of available training data increases, learners transition through qualitatively different features -- from simple spurious shortcuts to complex features -- only when the reduction in data encoding cost justifies the increased model complexity. Consequently, we identify distinct data regimes where increasing data promotes robustness by ruling out trivial shortcuts, and conversely, regimes where limiting data can act as a form of complexity-based regularization, preventing the learning of unreliable complex environmental cues. We validate our theory on a semi-synthetic benchmark showing that the feature selection of neural networks follows the same trajectory of solutions as optimal two-part compressors.
Joint Bayesian Inference of Graphical Structure and Parameters with a Single Generative Flow Network
May 30, 2023



Generative Flow Networks (GFlowNets), a class of generative models over discrete and structured sample spaces, have been previously applied to the problem of inferring the marginal posterior distribution over the directed acyclic graph (DAG) of a Bayesian Network, given a dataset of observations. Based on recent advances extending this framework to non-discrete sample spaces, we propose in this paper to approximate the joint posterior over not only the structure of a Bayesian Network, but also the parameters of its conditional probability distributions. We use a single GFlowNet whose sampling policy follows a two-phase process: the DAG is first generated sequentially one edge at a time, and then the corresponding parameters are picked once the full structure is known. Since the parameters are included in the posterior distribution, this leaves more flexibility for the local probability models of the Bayesian Network, making our approach applicable even to non-linear models parametrized by neural networks. We show that our method, called JSP-GFN, offers an accurate approximation of the joint posterior, while comparing favorably against existing methods on both simulated and real data.
Bayesian learning of Causal Structure and Mechanisms with GFlowNets and Variational Bayes
Nov 04, 2022



Bayesian causal structure learning aims to learn a posterior distribution over directed acyclic graphs (DAGs), and the mechanisms that define the relationship between parent and child variables. By taking a Bayesian approach, it is possible to reason about the uncertainty of the causal model. The notion of modelling the uncertainty over models is particularly crucial for causal structure learning since the model could be unidentifiable when given only a finite amount of observational data. In this paper, we introduce a novel method to jointly learn the structure and mechanisms of the causal model using Variational Bayes, which we call Variational Bayes-DAG-GFlowNet (VBG). We extend the method of Bayesian causal structure learning using GFlowNets to learn not only the posterior distribution over the structure, but also the parameters of a linear-Gaussian model. Our results on simulated data suggest that VBG is competitive against several baselines in modelling the posterior over DAGs and mechanisms, while offering several advantages over existing methods, including the guarantee to sample acyclic graphs, and the flexibility to generalize to non-linear causal mechanisms.
Semi-supervised Learning of Galaxy Morphology using Equivariant Transformer Variational Autoencoders
Nov 17, 2020
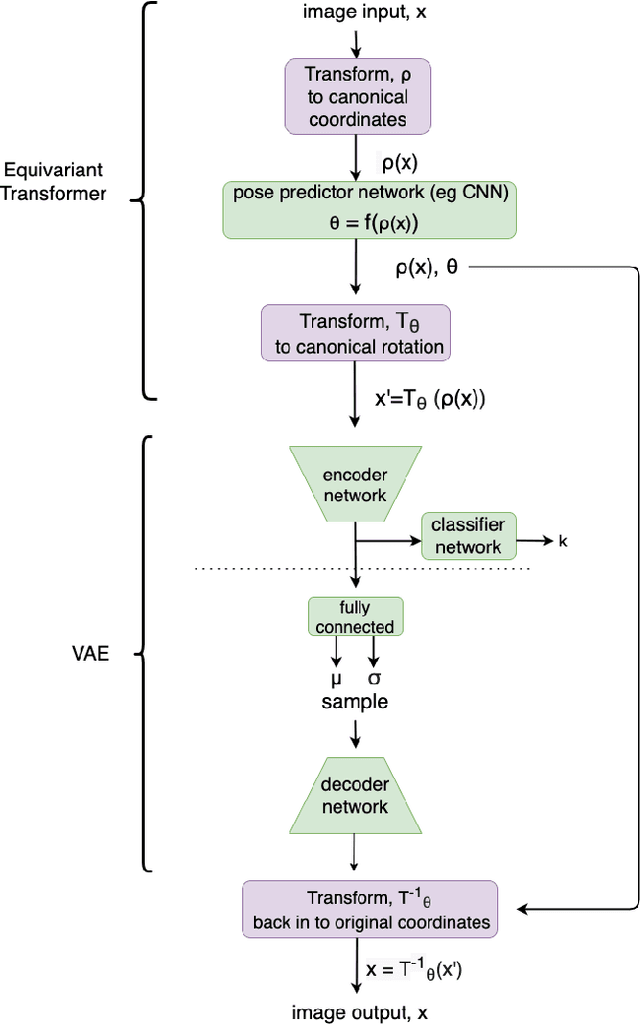
The growth in the number of galaxy images is much faster than the speed at which these galaxies can be labelled by humans. However, by leveraging the information present in the ever growing set of unlabelled images, semi-supervised learning could be an effective way of reducing the required labelling and increasing classification accuracy. We develop a Variational Autoencoder (VAE) with Equivariant Transformer layers with a classifier network from the latent space. We show that this novel architecture leads to improvements in accuracy when used for the galaxy morphology classification task on the Galaxy Zoo data set. In addition we show that pre-training the classifier network as part of the VAE using the unlabelled data leads to higher accuracy with fewer labels compared to exiting approaches. This novel VAE has the potential to automate galaxy morphology classification with reduced human labelling efforts.