 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Industrial-Scale Sequential Recommender for LinkedIn Feed Ranking
Feb 12, 2026LinkedIn Feed enables professionals worldwide to discover relevant content, build connections, and share knowledge at scale. We present Feed Sequential Recommender (Feed-SR), a transformer-based sequential ranking model for LinkedIn Feed that replaces a DCNv2-based ranker and meets strict production constraints. We detail the modeling choices, training techniques, and serving optimizations that enable deployment at LinkedIn scale. Feed-SR is currently the primary member experience on LinkedIn's Feed and shows significant improvements in member engagement (+2.10% time spent) in online A/B tests compared to the existing production model. We also describe our deployment experience with alternative sequential and LLM-based ranking architectures and why Feed-SR provided the best combination of online metrics and production efficiency.
CADET: Context-Conditioned Ads CTR Prediction With a Decoder-Only Transformer
Feb 11, 2026Click-through rate (CTR) prediction is fundamental to online advertising systems. While Deep Learning Recommendation Models (DLRMs) with explicit feature interactions have long dominated this domain, recent advances in generative recommenders have shown promising results in content recommendation. However, adapting these transformer-based architectures to ads CTR prediction still presents unique challenges, including handling post-scoring contextual signals, maintaining offline-online consistency, and scaling to industrial workloads. We present CADET (Context-Conditioned Ads Decoder-Only Transformer), an end-to-end decoder-only transformer for ads CTR prediction deployed at LinkedIn. Our approach introduces several key innovations: (1) a context-conditioned decoding architecture with multi-tower prediction heads that explicitly model post-scoring signals such as ad position, resolving the chicken-and-egg problem between predicted CTR and ranking; (2) a self-gated attention mechanism that stabilizes training by adaptively regulating information flow at both representation and interaction levels; (3) a timestamp-based variant of Rotary Position Embedding (RoPE) that captures temporal relationships across timescales from seconds to months; (4) session masking strategies that prevent the model from learning dependencies on unavailable in-session events, addressing train-serve skew; and (5) production engineering techniques including tensor packing, sequence chunking, and custom Flash Attention kernels that enable efficient training and serving at scale. In online A/B testing, CADET achieves a 11.04\% CTR lift compared to the production LiRank baseline model, a hybrid ensemble of DCNv2 and sequential encoders. The system has been successfully deployed on LinkedIn's advertising platform, serving the main traffic for homefeed sponsored updates.
From Features to Transformers: Redefining Ranking for Scalable Impact
Feb 05, 2025We present LiGR, a large-scale ranking framework developed at LinkedIn that brings state-of-the-art transformer-based modeling architectures into production. We introduce a modified transformer architecture that incorporates learned normalization and simultaneous set-wise attention to user history and ranked items. This architecture enables several breakthrough achievements, including: (1) the deprecation of most manually designed feature engineering, outperforming the prior state-of-the-art system using only few features (compared to hundreds in the baseline), (2) validation of the scaling law for ranking systems, showing improved performance with larger models, more training data, and longer context sequences, and (3) simultaneous joint scoring of items in a set-wise manner, leading to automated improvements in diversity. To enable efficient serving of large ranking models, we describe techniques to scale inference effectively using single-pass processing of user history and set-wise attention. We also summarize key insights from various ablation studies and A/B tests, highlighting the most impactful technical approaches.
Efficient user history modeling with amortized inference for deep learning recommendation models
Dec 09, 2024



We study user history modeling via Transformer encoders in deep learning recommendation models (DLRM). Such architectures can significantly improve recommendation quality, but usually incur high latency cost necessitating infrastructure upgrades or very small Transformer models. An important part of user history modeling is early fusion of the candidate item and various methods have been studied. We revisit early fusion and compare concatenation of the candidate to each history item against appending it to the end of the list as a separate item. Using the latter method, allows us to reformulate the recently proposed amortized history inference algorithm M-FALCON \cite{zhai2024actions} for the case of DLRM models. We show via experimental results that appending with cross-attention performs on par with concatenation and that amortization significantly reduces inference costs. We conclude with results from deploying this model on the LinkedIn Feed and Ads surfaces, where amortization reduces latency by 30\% compared to non-amortized inference.
LiRank: Industrial Large Scale Ranking Models at LinkedIn
Feb 10, 2024



We present LiRank, a large-scale ranking framework at LinkedIn that brings to production state-of-the-art modeling architectures and optimization methods. We unveil several modeling improvements, including Residual DCN, which adds attention and residual connections to the famous DCNv2 architecture. We share insights into combining and tuning SOTA architectures to create a unified model, including Dense Gating, Transformers and Residual DCN. We also propose novel techniques for calibration and describe how we productionalized deep learning based explore/exploit methods. To enable effective, production-grade serving of large ranking models, we detail how to train and compress models using quantization and vocabulary compression. We provide details about the deployment setup for large-scale use cases of Feed ranking, Jobs Recommendations, and Ads click-through rate (CTR) prediction. We summarize our learnings from various A/B tests by elucidating the most effective technical approaches. These ideas have contributed to relative metrics improvements across the board at LinkedIn: +0.5% member sessions in the Feed, +1.76% qualified job applications for Jobs search and recommendations, and +4.3% for Ads CTR. We hope this work can provide practical insights and solutions for practitioners interested in leveraging large-scale deep ranking systems.
Quantity vs. Quality: On Hyperparameter Optimization for Deep Reinforcement Learning
Jul 30, 2020
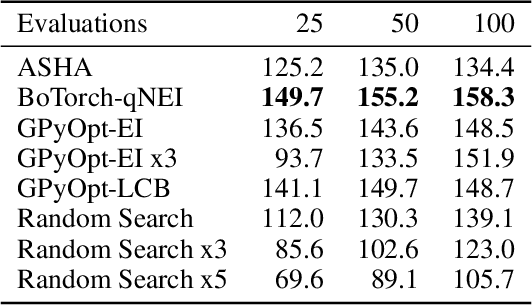
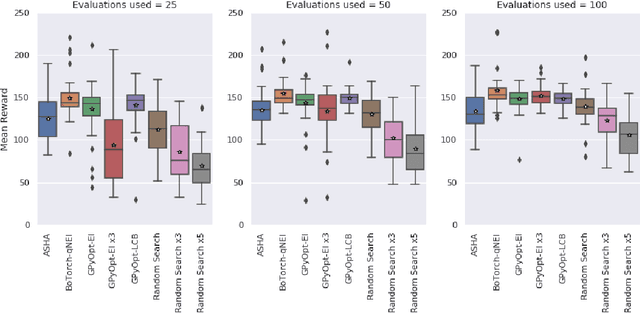
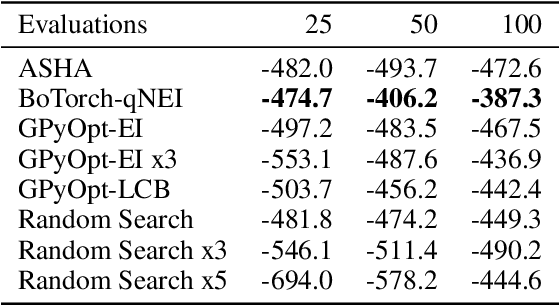
Reinforcement learning algorithms can show strong variation in performance between training runs with different random seeds. In this paper we explore how this affects hyperparameter optimization when the goal is to find hyperparameter settings that perform well across random seeds. In particular, we benchmark whether it is better to explore a large quantity of hyperparameter settings via pruning of bad performers, or if it is better to aim for quality of collected results by using repetitions. For this we consider the Successive Halving, Random Search, and Bayesian Optimization algorithms, the latter two with and without repetitions. We apply these to tuning the PPO2 algorithm on the Cartpole balancing task and the Inverted Pendulum Swing-up task. We demonstrate that pruning may negatively affect the optimization and that repeated sampling does not help in finding hyperparameter settings that perform better across random seeds. From our experiments we conclude that Bayesian optimization with a noise robust acquisition function is the best choice for hyperparameter optimization in reinforcement learning tasks.
Sherpa: Robust Hyperparameter Optimization for Machine Learning
May 08, 2020
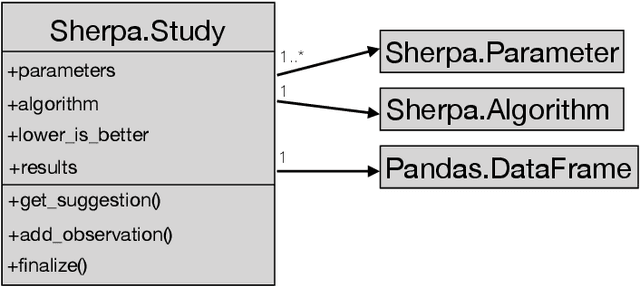
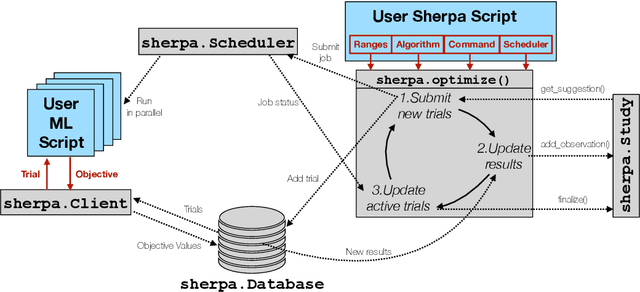
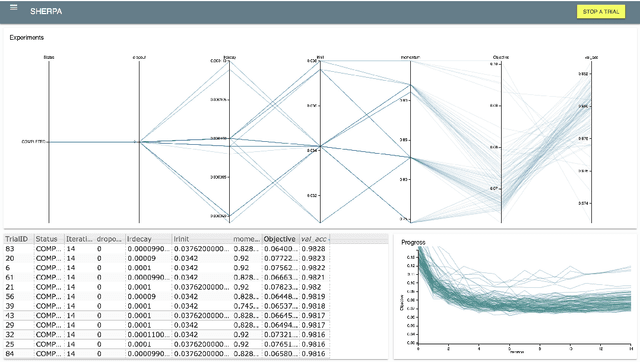
Sherpa is a hyperparameter optimization library for machine learning models. It is specifically designed for problems with computationally expensive, iterative function evaluations, such as the hyperparameter tuning of deep neural networks. With Sherpa, scientists can quickly optimize hyperparameters using a variety of powerful and interchangeable algorithms. Sherpa can be run on either a single machine or in parallel on a cluster. Finally, an interactive dashboard enables users to view the progress of models as they are trained, cancel trials, and explore which hyperparameter combinations are working best. Sherpa empowers machine learning practitioners by automating the more tedious aspects of model tuning. Its source code and documentation are available at https://github.com/sherpa-ai/sherpa.
Deep Convolutional Neural Networks as Generic Feature Extractors
Oct 06, 2017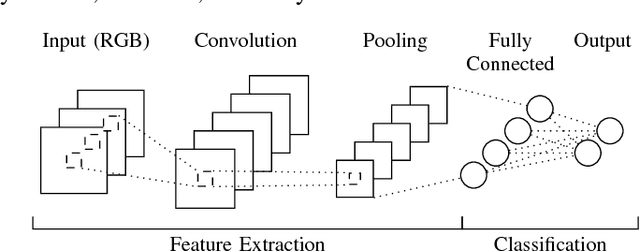
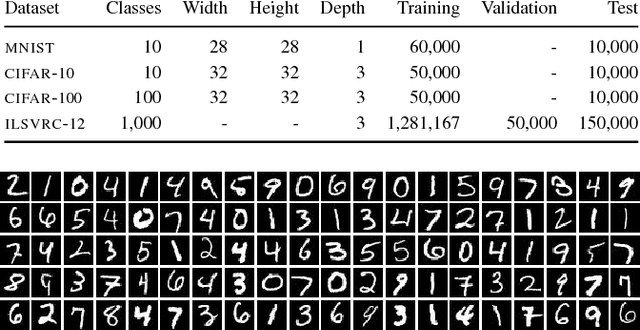


Recognizing objects in natural images is an intricate problem involving multiple conflicting objectives. Deep convolutional neural networks, trained on large datasets, achieve convincing results and are currently the state-of-the-art approach for this task. However, the long time needed to train such deep networks is a major drawback. We tackled this problem by reusing a previously trained network. For this purpose, we first trained a deep convolutional network on the ILSVRC2012 dataset. We then maintained the learned convolution kernels and only retrained the classification part on different datasets. Using this approach, we achieved an accuracy of 67.68 % on CIFAR-100, compared to the previous state-of-the-art result of 65.43 %. Furthermore, our findings indicate that convolutional networks are able to learn generic feature extractors that can be used for different tasks.
CNN-LTE: a Class of 1-X Pooling Convolutional Neural Networks on Label Tree Embeddings for Audio Scene Recognition
Aug 15, 2016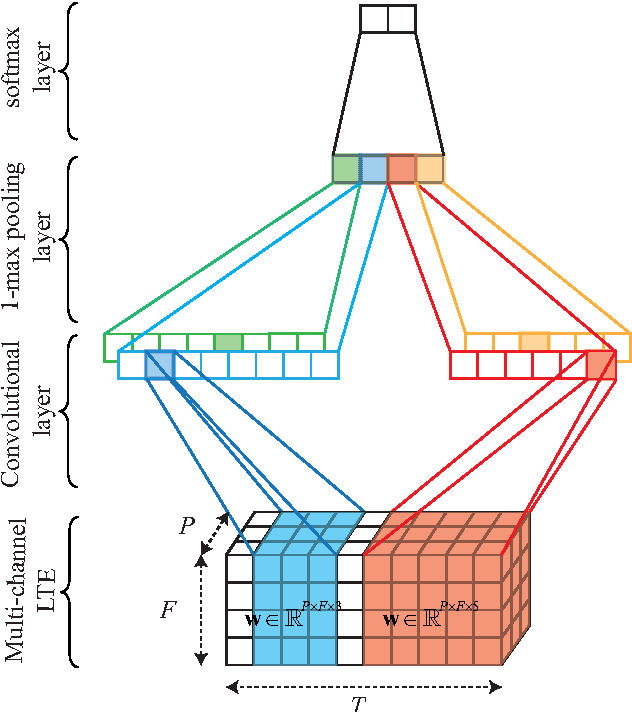
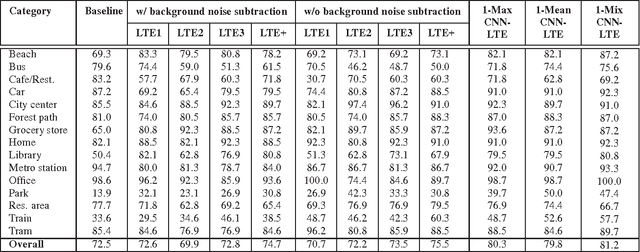

We describe in this report our audio scene recognition system submitted to the DCASE 2016 challenge. Firstly, given the label set of the scenes, a label tree is automatically constructed. This category taxonomy is then used in the feature extraction step in which an audio scene instance is represented by a label tree embedding image. Different convolutional neural networks, which are tailored for the task at hand, are finally learned on top of the image features for scene recognition. Our system reaches an overall recognition accuracy of 81.2% and 83.3% and outperforms the DCASE 2016 baseline with absolute improvements of 8.7% and 6.1% on the development and test data, respectively.
CaR-FOREST: Joint Classification-Regression Decision Forests for Overlapping Audio Event Detection
Aug 15, 2016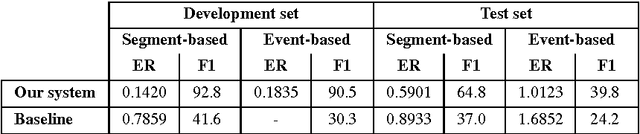
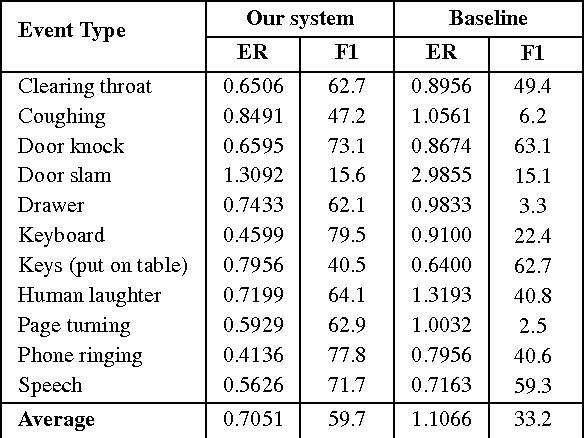
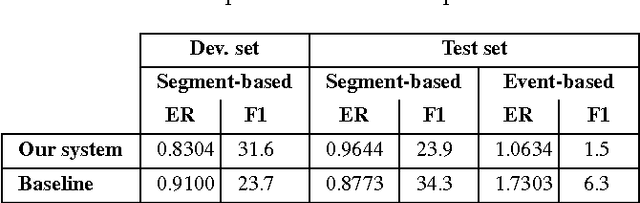
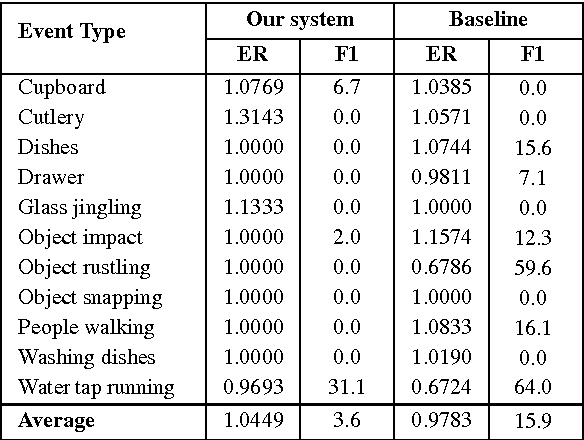
This report describes our submissions to Task2 and Task3 of the DCASE 2016 challenge. The systems aim at dealing with the detection of overlapping audio events in continuous streams, where the detectors are based on random decision forests. The proposed forests are jointly trained for classification and regression simultaneously. Initially, the training is classification-oriented to encourage the trees to select discriminative features from overlapping mixtures to separate positive audio segments from the negative ones. The regression phase is then carried out to let the positive audio segments vote for the event onsets and offsets, and therefore model the temporal structure of audio events. One random decision forest is specifically trained for each event category of interest. Experimental results on the development data show that our systems significantly outperform the baseline on the Task2 evaluation while they are inferior to the baseline in the Task3 evaluation.