 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNearest-Neighbor Density Estimation for Dependency Suppression
Mar 04, 2026The ability to remove unwanted dependencies from data is crucial in various domains, including fairness, robust learning, and privacy protection. In this work, we propose an encoder-based approach that learns a representation independent of a sensitive variable but otherwise preserving essential data characteristics. Unlike existing methods that rely on decorrelation or adversarial learning, our approach explicitly estimates and modifies the data distribution to neutralize statistical dependencies. To achieve this, we combine a specialized variational autoencoder with a novel loss function driven by non-parametric nearest-neighbor density estimation, enabling direct optimization of independence. We evaluate our approach on multiple datasets, demonstrating that it can outperform existing unsupervised techniques and even rival supervised methods in balancing information removal and utility.
The Resurrection of the ReLU
May 28, 2025Modeling sophisticated activation functions within deep learning architectures has evolved into a distinct research direction. Functions such as GELU, SELU, and SiLU offer smooth gradients and improved convergence properties, making them popular choices in state-of-the-art models. Despite this trend, the classical ReLU remains appealing due to its simplicity, inherent sparsity, and other advantageous topological characteristics. However, ReLU units are prone to becoming irreversibly inactive - a phenomenon known as the dying ReLU problem - which limits their overall effectiveness. In this work, we introduce surrogate gradient learning for ReLU (SUGAR) as a novel, plug-and-play regularizer for deep architectures. SUGAR preserves the standard ReLU function during the forward pass but replaces its derivative in the backward pass with a smooth surrogate that avoids zeroing out gradients. We demonstrate that SUGAR, when paired with a well-chosen surrogate function, substantially enhances generalization performance over convolutional network architectures such as VGG-16 and ResNet-18, providing sparser activations while effectively resurrecting dead ReLUs. Moreover, we show that even in modern architectures like Conv2NeXt and Swin Transformer - which typically employ GELU - substituting these with SUGAR yields competitive and even slightly superior performance. These findings challenge the prevailing notion that advanced activation functions are necessary for optimal performance. Instead, they suggest that the conventional ReLU, particularly with appropriate gradient handling, can serve as a strong, versatile revived classic across a broad range of deep learning vision models.
Why LLMs Cannot Think and How to Fix It
Mar 12, 2025This paper elucidates that current state-of-the-art Large Language Models (LLMs) are fundamentally incapable of making decisions or developing "thoughts" within the feature space due to their architectural constraints. We establish a definition of "thought" that encompasses traditional understandings of that term and adapt it for application to LLMs. We demonstrate that the architectural design and language modeling training methodology of contemporary LLMs inherently preclude them from engaging in genuine thought processes. Our primary focus is on this theoretical realization rather than practical insights derived from experimental data. Finally, we propose solutions to enable thought processes within the feature space and discuss the broader implications of these architectural modifications.
Revealing Unintentional Information Leakage in Low-Dimensional Facial Portrait Representations
Mar 12, 2025We evaluate the information that can unintentionally leak into the low dimensional output of a neural network, by reconstructing an input image from a 40- or 32-element feature vector that intends to only describe abstract attributes of a facial portrait. The reconstruction uses blackbox-access to the image encoder which generates the feature vector. Other than previous work, we leverage recent knowledge about image generation and facial similarity, implementing a method that outperforms the current state-of-the-art. Our strategy uses a pretrained StyleGAN and a new loss function that compares the perceptual similarity of portraits by mapping them into the latent space of a FaceNet embedding. Additionally, we present a new technique that fuses the output of an ensemble, to deliberately generate specific aspects of the recreated image.
Convolutional Neural Networks Do Work with Pre-Defined Filters
Nov 27, 2024



We present a novel class of Convolutional Neural Networks called Pre-defined Filter Convolutional Neural Networks (PFCNNs), where all nxn convolution kernels with n>1 are pre-defined and constant during training. It involves a special form of depthwise convolution operation called a Pre-defined Filter Module (PFM). In the channel-wise convolution part, the 1xnxn kernels are drawn from a fixed pool of only a few (16) different pre-defined kernels. In the 1x1 convolution part linear combinations of the pre-defined filter outputs are learned. Despite this harsh restriction, complex and discriminative features are learned. These findings provide a novel perspective on the way how information is processed within deep CNNs. We discuss various properties of PFCNNs and prove their effectiveness using the popular datasets Caltech101, CIFAR10, CUB-200-2011, FGVC-Aircraft, Flowers102, and Stanford Cars. Our implementation of PFCNNs is provided on Github https://github.com/Criscraft/PredefinedFilterNetworks
Rethinking generalization of classifiers in separable classes scenarios and over-parameterized regimes
Oct 22, 2024



We investigate the learning dynamics of classifiers in scenarios where classes are separable or classifiers are over-parameterized. In both cases, Empirical Risk Minimization (ERM) results in zero training error. However, there are many global minima with a training error of zero, some of which generalize well and some of which do not. We show that in separable classes scenarios the proportion of "bad" global minima diminishes exponentially with the number of training data n. Our analysis provides bounds and learning curves dependent solely on the density distribution of the true error for the given classifier function set, irrespective of the set's size or complexity (e.g., number of parameters). This observation may shed light on the unexpectedly good generalization of over-parameterized Neural Networks. For the over-parameterized scenario, we propose a model for the density distribution of the true error, yielding learning curves that align with experiments on MNIST and CIFAR-10.
Leaky ReLUs That Differ in Forward and Backward Pass Facilitate Activation Maximization in Deep Neural Networks
Oct 22, 2024



Activation maximization (AM) strives to generate optimal input stimuli, revealing features that trigger high responses in trained deep neural networks. AM is an important method of explainable AI. We demonstrate that AM fails to produce optimal input stimuli for simple functions containing ReLUs or Leaky ReLUs, casting doubt on the practical usefulness of AM and the visual interpretation of the generated images. This paper proposes a solution based on using Leaky ReLUs with a high negative slope in the backward pass while keeping the original, usually zero, slope in the forward pass. The approach significantly increases the maxima found by AM. The resulting ProxyGrad algorithm implements a novel optimization technique for neural networks that employs a secondary network as a proxy for gradient computation. This proxy network is designed to have a simpler loss landscape with fewer local maxima than the original network. Our chosen proxy network is an identical copy of the original network, including its weights, with distinct negative slopes in the Leaky ReLUs. Moreover, we show that ProxyGrad can be used to train the weights of Convolutional Neural Networks for classification such that, on some of the tested benchmarks, they outperform traditional networks.
Enhancing Generalization in Convolutional Neural Networks through Regularization with Edge and Line Features
Oct 22, 2024This paper proposes a novel regularization approach to bias Convolutional Neural Networks (CNNs) toward utilizing edge and line features in their hidden layers. Rather than learning arbitrary kernels, we constrain the convolution layers to edge and line detection kernels. This intentional bias regularizes the models, improving generalization performance, especially on small datasets. As a result, test accuracies improve by margins of 5-11 percentage points across four challenging fine-grained classification datasets with limited training data and an identical number of trainable parameters. Instead of traditional convolutional layers, we use Pre-defined Filter Modules, which convolve input data using a fixed set of 3x3 pre-defined edge and line filters. A subsequent ReLU erases information that did not trigger any positive response. Next, a 1x1 convolutional layer generates linear combinations. Notably, the pre-defined filters are a fixed component of the architecture, remaining unchanged during the training phase. Our findings reveal that the number of dimensions spanned by the set of pre-defined filters has a low impact on recognition performance. However, the size of the set of filters matters, with nine or more filters providing optimal results.
Highly over-parameterized classifiers generalize since bad solutions are rare
Nov 07, 2022



We study the generalization of over-parameterized classifiers where Empirical Risk Minimization (ERM) for learning leads to zero training error. In these over-parameterized settings there are many global minima with zero training error, some of which generalize better than others. We show that under certain conditions the fraction of "bad" global minima with a true error larger than {\epsilon} decays to zero exponentially fast with the number of training data n. The bound depends on the distribution of the true error over the set of classifier functions used for the given classification problem, and does not necessarily depend on the size or complexity (e.g. the number of parameters) of the classifier function set. This might explain the unexpectedly good generalization even of highly over-parameterized Neural Networks. We support our mathematical framework with experiments on a synthetic data set and a subset of MNIST.
Large Neural Networks Learning from Scratch with Very Few Data and without Regularization
May 18, 2022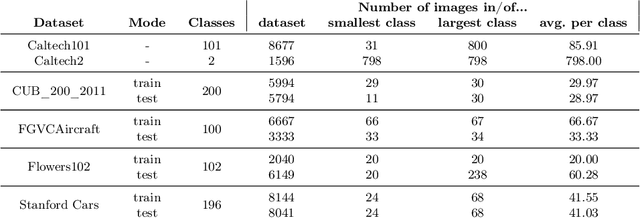


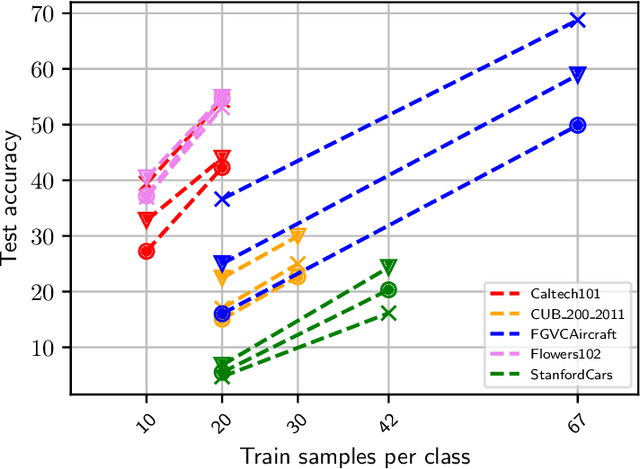
Recent findings have shown that Neural Networks generalize also in over-parametrized regimes with zero training error. This is surprising, since it is completely against traditional machine learning wisdom. In our empirical study we fortify these findings in the domain of fine-grained image classification. We show that very large Convolutional Neural Networks with millions of weights do learn with only a handful of training samples and without image augmentation, explicit regularization or pretraining. We train the architectures ResNet018, ResNet101 and VGG19 on subsets of the difficult benchmark datasets Caltech101, CUB_200_2011, FGVCAircraft, Flowers102 and StanfordCars with 100 classes and more, perform a comprehensive comparative study and draw implications for the practical application of CNNs. Finally, we show that VGG19 with 140 million weights learns to distinguish airplanes and motorbikes up to 95% accuracy with only 20 samples per class.