 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearch Engine Guided Non-Parametric Neural Machine Translation
Mar 08, 2018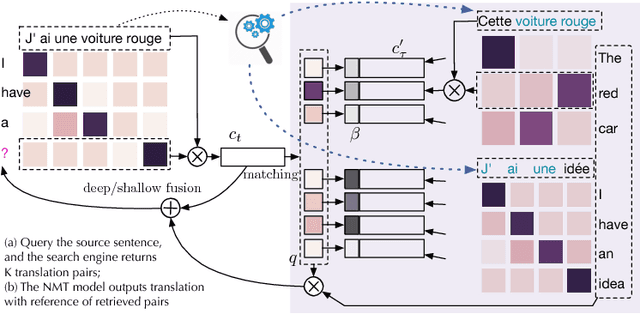
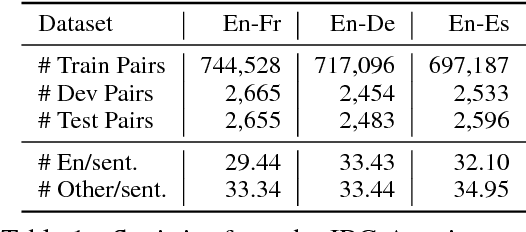
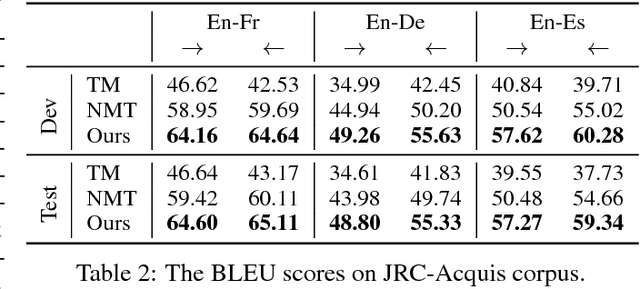
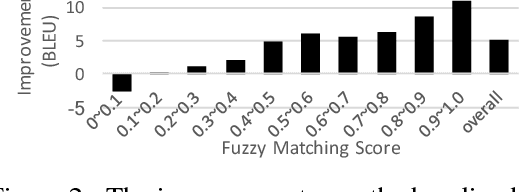
In this paper, we extend an attention-based neural machine translation (NMT) model by allowing it to access an entire training set of parallel sentence pairs even after training. The proposed approach consists of two stages. In the first stage--retrieval stage--, an off-the-shelf, black-box search engine is used to retrieve a small subset of sentence pairs from a training set given a source sentence. These pairs are further filtered based on a fuzzy matching score based on edit distance. In the second stage--translation stage--, a novel translation model, called translation memory enhanced NMT (TM-NMT), seamlessly uses both the source sentence and a set of retrieved sentence pairs to perform the translation. Empirical evaluation on three language pairs (En-Fr, En-De, and En-Es) shows that the proposed approach significantly outperforms the baseline approach and the improvement is more significant when more relevant sentence pairs were retrieved.
Retrieval-Augmented Convolutional Neural Networks for Improved Robustness against Adversarial Examples
Feb 26, 2018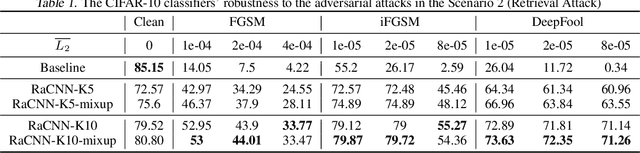
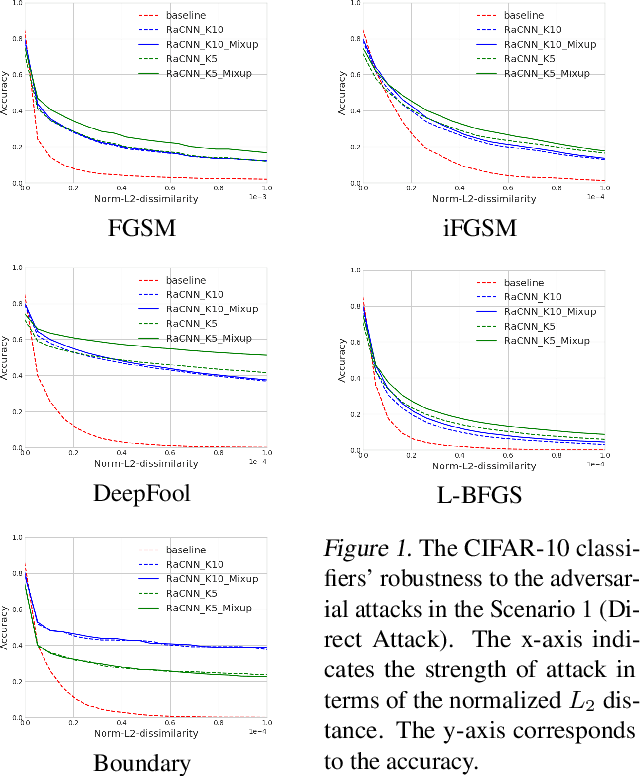
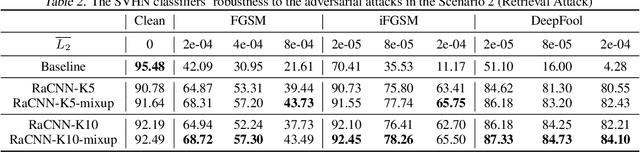
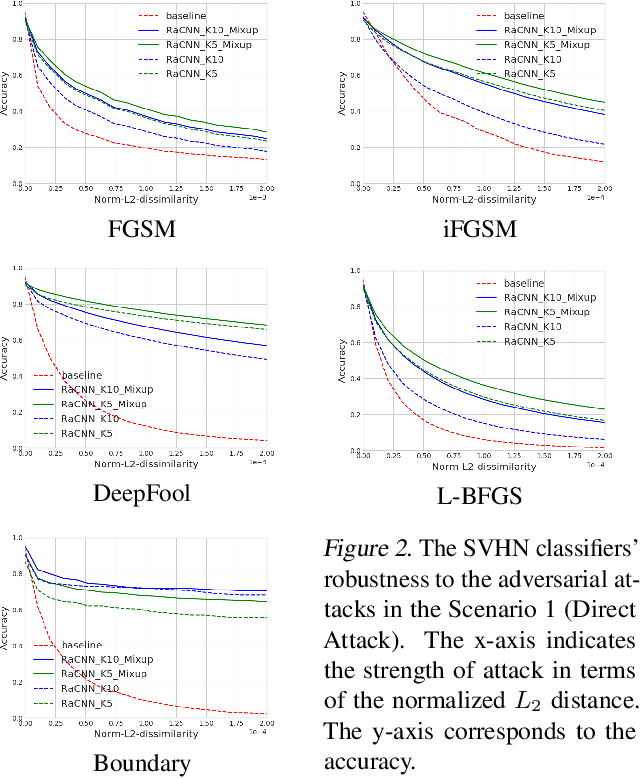
We propose a retrieval-augmented convolutional network and propose to train it with local mixup, a novel variant of the recently proposed mixup algorithm. The proposed hybrid architecture combining a convolutional network and an off-the-shelf retrieval engine was designed to mitigate the adverse effect of off-manifold adversarial examples, while the proposed local mixup addresses on-manifold ones by explicitly encouraging the classifier to locally behave linearly on the data manifold. Our evaluation of the proposed approach against five readily-available adversarial attacks on three datasets--CIFAR-10, SVHN and ImageNet--demonstrate the improved robustness compared to the vanilla convolutional network.
Unsupervised Neural Machine Translation
Feb 26, 2018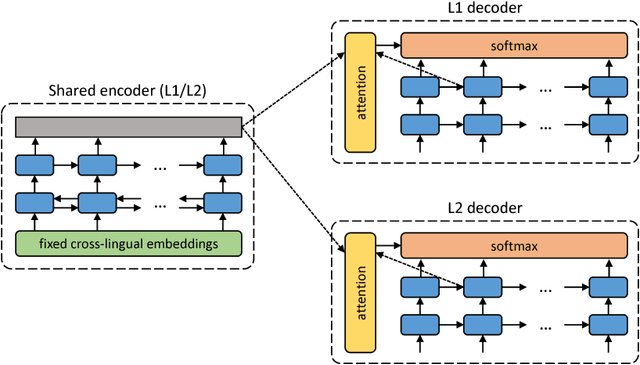
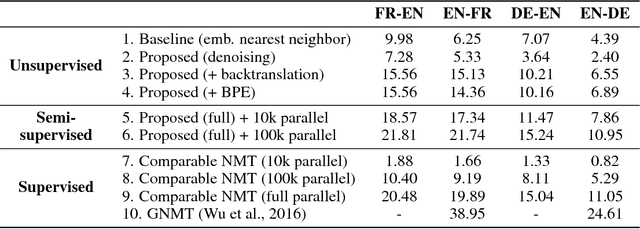
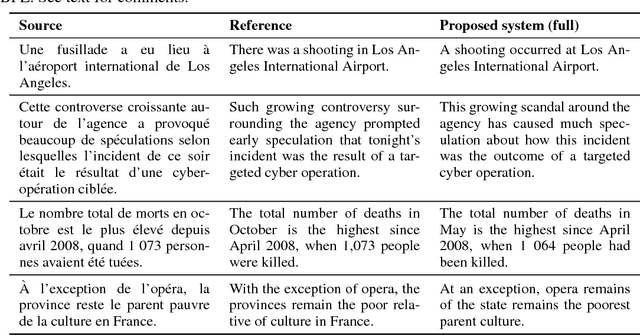
In spite of the recent success of neural machine translation (NMT) in standard benchmarks, the lack of large parallel corpora poses a major practical problem for many language pairs. There have been several proposals to alleviate this issue with, for instance, triangulation and semi-supervised learning techniques, but they still require a strong cross-lingual signal. In this work, we completely remove the need of parallel data and propose a novel method to train an NMT system in a completely unsupervised manner, relying on nothing but monolingual corpora. Our model builds upon the recent work on unsupervised embedding mappings, and consists of a slightly modified attentional encoder-decoder model that can be trained on monolingual corpora alone using a combination of denoising and backtranslation. Despite the simplicity of the approach, our system obtains 15.56 and 10.21 BLEU points in WMT 2014 French-to-English and German-to-English translation. The model can also profit from small parallel corpora, and attains 21.81 and 15.24 points when combined with 100,000 parallel sentences, respectively. Our implementation is released as an open source project.
Graph Convolutional Networks for Classification with a Structured Label Space
Feb 22, 2018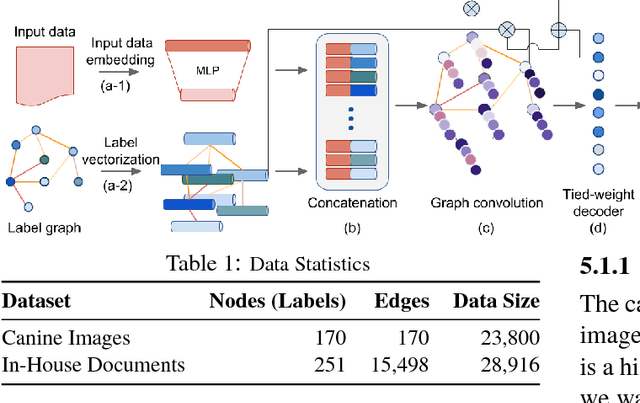
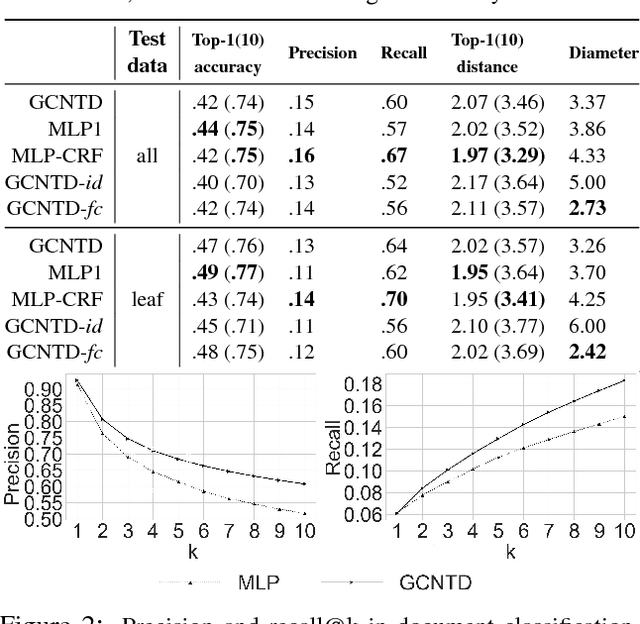
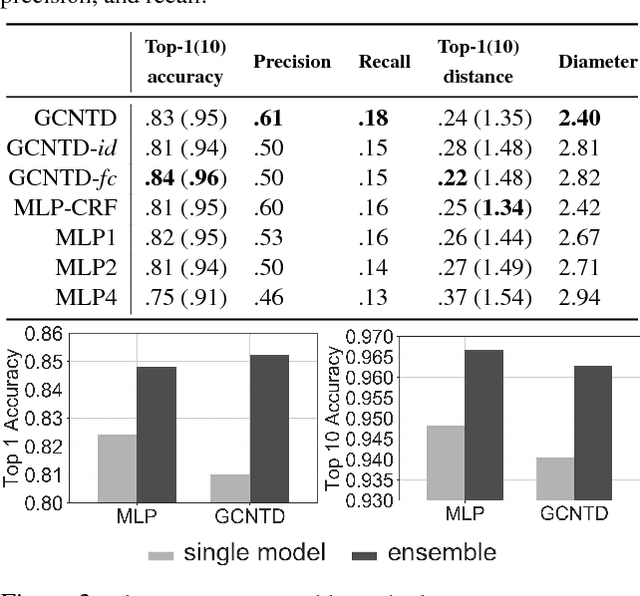
It is a usual practice to ignore any structural information underlying classes in multi-class classification. In this paper, we propose a graph convolutional network (GCN) augmented neural network classifier to exploit a known, underlying graph structure of labels. The proposed approach resembles an (approximate) inference procedure in, for instance, a conditional random field (CRF). We evaluate the proposed approach on document classification and object recognition and report both accuracies and graph-theoretic metrics that correspond to the consistency of the model's prediction. The experiment results reveal that the proposed model outperforms a baseline method which ignores the graph structures of a label space in terms of graph-theoretic metrics.
Boundary-Seeking Generative Adversarial Networks
Feb 21, 2018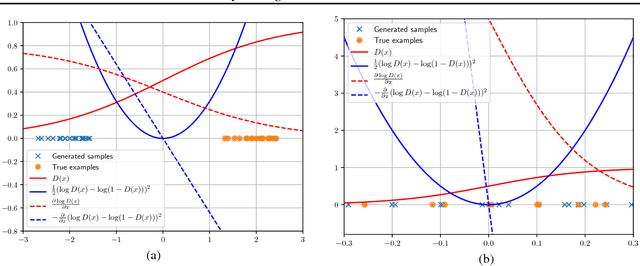

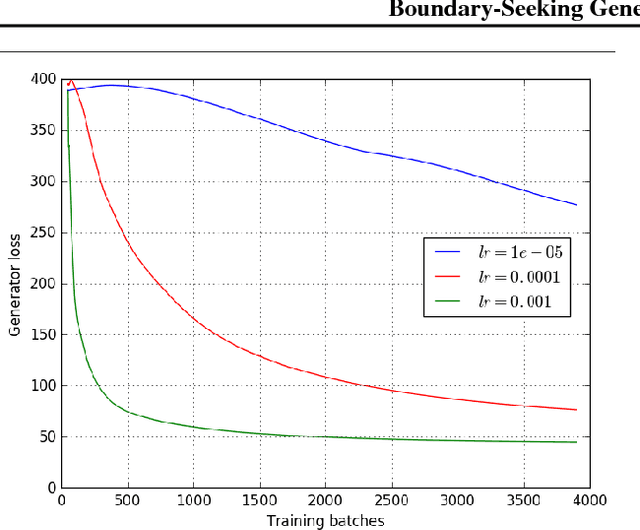
Generative adversarial networks (GANs) are a learning framework that rely on training a discriminator to estimate a measure of difference between a target and generated distributions. GANs, as normally formulated, rely on the generated samples being completely differentiable w.r.t. the generative parameters, and thus do not work for discrete data. We introduce a method for training GANs with discrete data that uses the estimated difference measure from the discriminator to compute importance weights for generated samples, thus providing a policy gradient for training the generator. The importance weights have a strong connection to the decision boundary of the discriminator, and we call our method boundary-seeking GANs (BGANs). We demonstrate the effectiveness of the proposed algorithm with discrete image and character-based natural language generation. In addition, the boundary-seeking objective extends to continuous data, which can be used to improve stability of training, and we demonstrate this on Celeba, Large-scale Scene Understanding (LSUN) bedrooms, and Imagenet without conditioning.
Iterative Refinement of the Approximate Posterior for Directed Belief Networks
Feb 20, 2018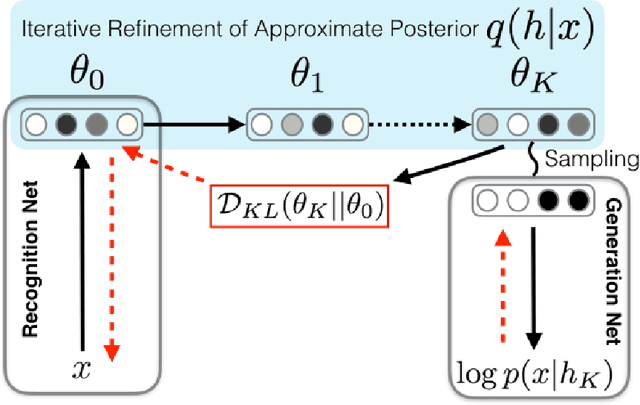
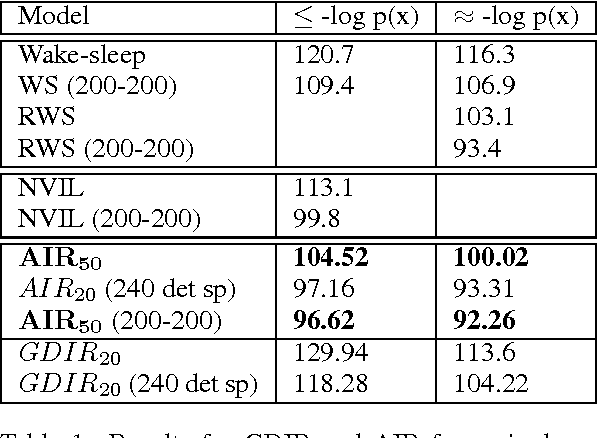

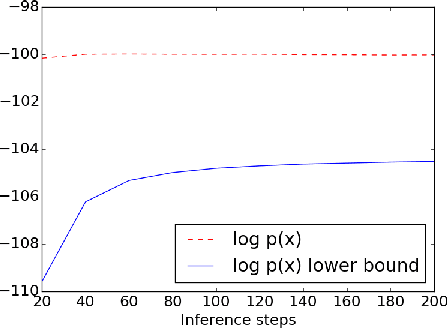
Variational methods that rely on a recognition network to approximate the posterior of directed graphical models offer better inference and learning than previous methods. Recent advances that exploit the capacity and flexibility in this approach have expanded what kinds of models can be trained. However, as a proposal for the posterior, the capacity of the recognition network is limited, which can constrain the representational power of the generative model and increase the variance of Monte Carlo estimates. To address these issues, we introduce an iterative refinement procedure for improving the approximate posterior of the recognition network and show that training with the refined posterior is competitive with state-of-the-art methods. The advantages of refinement are further evident in an increased effective sample size, which implies a lower variance of gradient estimates.
Saliency-based Sequential Image Attention with Multiset Prediction
Nov 14, 2017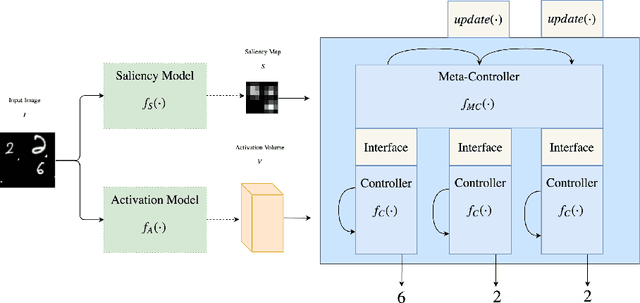
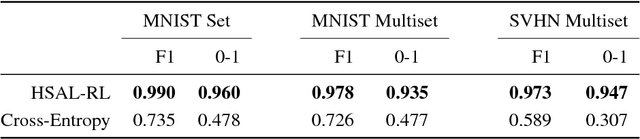


Humans process visual scenes selectively and sequentially using attention. Central to models of human visual attention is the saliency map. We propose a hierarchical visual architecture that operates on a saliency map and uses a novel attention mechanism to sequentially focus on salient regions and take additional glimpses within those regions. The architecture is motivated by human visual attention, and is used for multi-label image classification on a novel multiset task, demonstrating that it achieves high precision and recall while localizing objects with its attention. Unlike conventional multi-label image classification models, the model supports multiset prediction due to a reinforcement-learning based training process that allows for arbitrary label permutation and multiple instances per label.
The Effects of Noisy Labels on Deep Convolutional Neural Networks for Music Tagging
Nov 14, 2017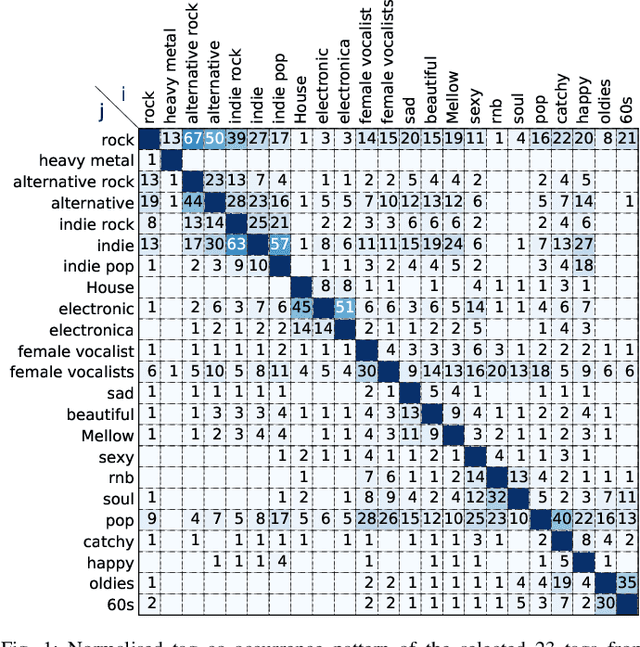
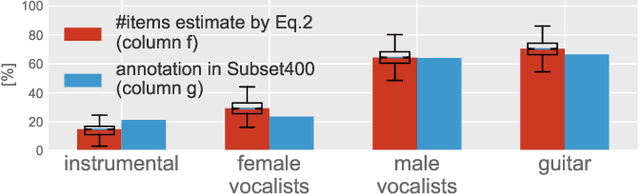
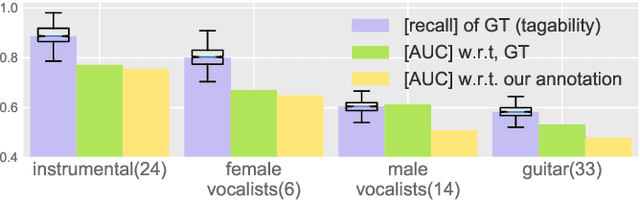
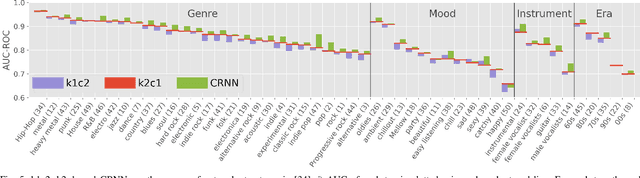
Deep neural networks (DNN) have been successfully applied to music classification including music tagging. However, there are several open questions regarding the training, evaluation, and analysis of DNNs. In this article, we investigate specific aspects of neural networks, the effects of noisy labels, to deepen our understanding of their properties. We analyse and (re-)validate a large music tagging dataset to investigate the reliability of training and evaluation. Using a trained network, we compute label vector similarities which is compared to groundtruth similarity. The results highlight several important aspects of music tagging and neural networks. We show that networks can be effective despite relatively large error rates in groundtruth datasets, while conjecturing that label noise can be the cause of varying tag-wise performance differences. Lastly, the analysis of our trained network provides valuable insight into the relationships between music tags. These results highlight the benefit of using data-driven methods to address automatic music tagging.
Breast density classification with deep convolutional neural networks
Nov 10, 2017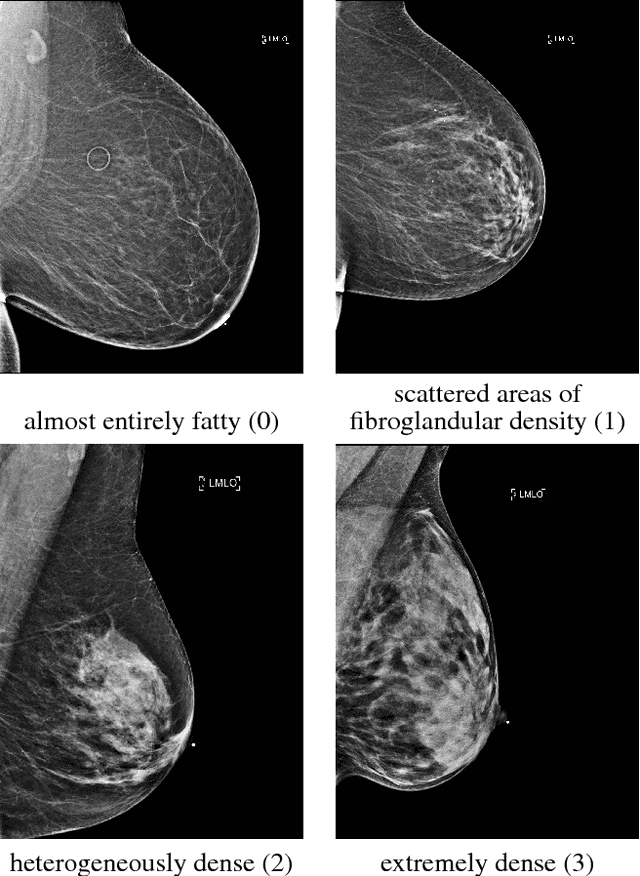
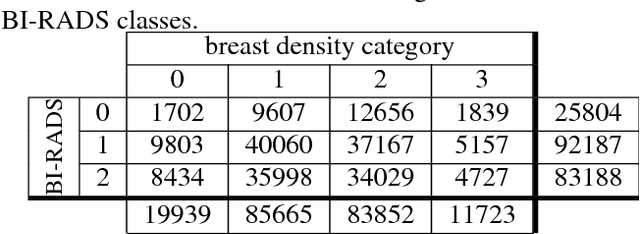
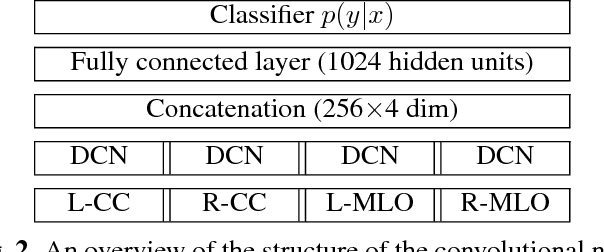
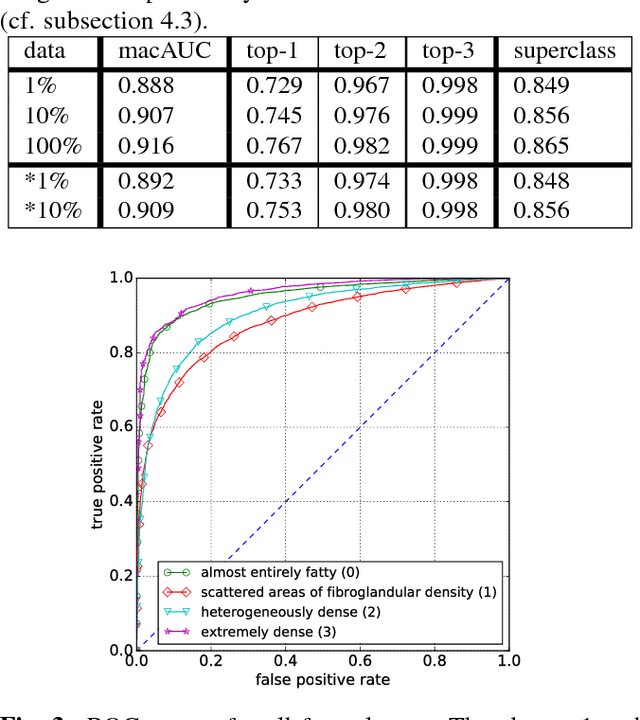
Breast density classification is an essential part of breast cancer screening. Although a lot of prior work considered this problem as a task for learning algorithms, to our knowledge, all of them used small and not clinically realistic data both for training and evaluation of their models. In this work, we explore the limits of this task with a data set coming from over 200,000 breast cancer screening exams. We use this data to train and evaluate a strong convolutional neural network classifier. In a reader study, we find that our model can perform this task comparably to a human expert.
Attention-based Mixture Density Recurrent Networks for History-based Recommendation
Sep 22, 2017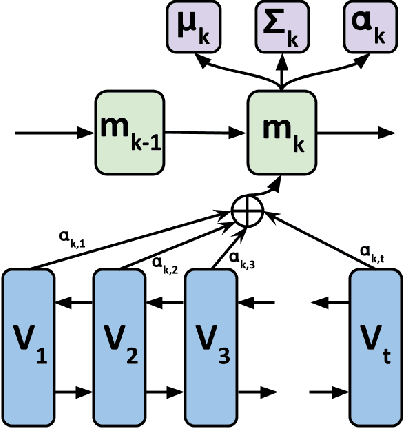
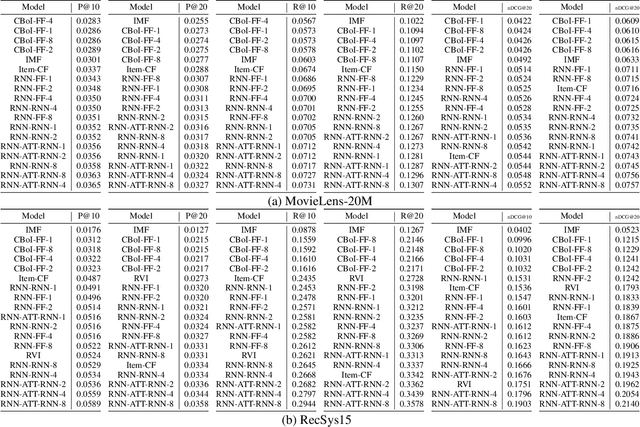
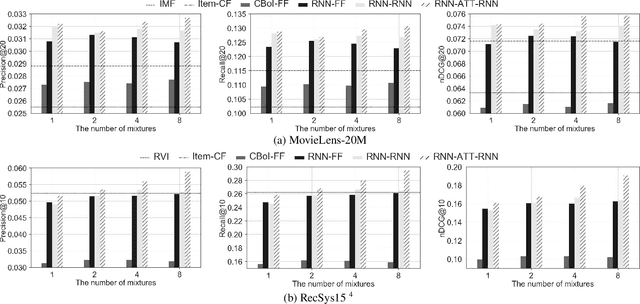
The goal of personalized history-based recommendation is to automatically output a distribution over all the items given a sequence of previous purchases of a user. In this work, we present a novel approach that uses a recurrent network for summarizing the history of purchases, continuous vectors representing items for scalability, and a novel attention-based recurrent mixture density network, which outputs each component in a mixture sequentially, for modelling a multi-modal conditional distribution. We evaluate the proposed approach on two publicly available datasets, MovieLens-20M and RecSys15. The experiments show that the proposed approach, which explicitly models the multi-modal nature of the predictive distribution, is able to improve the performance over various baselines in terms of precision, recall and nDCG.