 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammar Induction with Neural Language Models: An Unusual Replication
Aug 29, 2018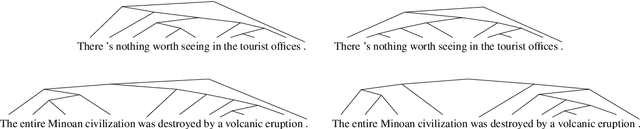
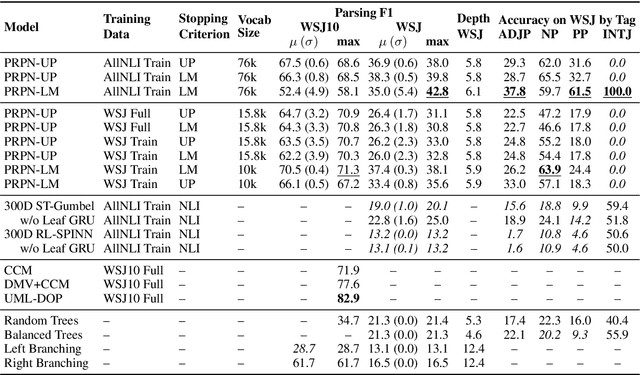
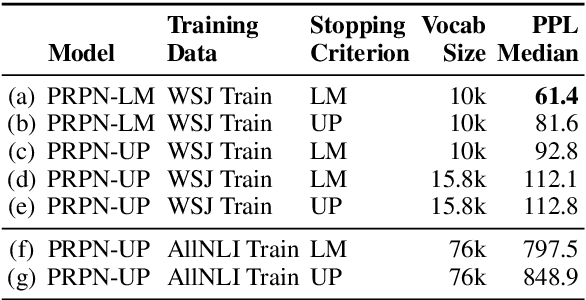
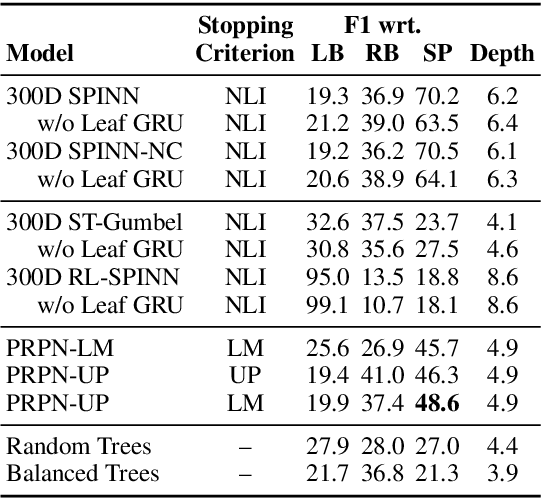
A substantial thread of recent work on latent tree learning has attempted to develop neural network models with parse-valued latent variables and train them on non-parsing tasks, in the hope of having them discover interpretable tree structure. In a recent paper, Shen et al. (2018) introduce such a model and report near-state-of-the-art results on the target task of language modeling, and the first strong latent tree learning result on constituency parsing. In an attempt to reproduce these results, we discover issues that make the original results hard to trust, including tuning and even training on what is effectively the test set. Here, we attempt to reproduce these results in a fair experiment and to extend them to two new datasets. We find that the results of this work are robust: All variants of the model under study outperform all latent tree learning baselines, and perform competitively with symbolic grammar induction systems. We find that this model represents the first empirical success for latent tree learning, and that neural network language modeling warrants further study as a setting for grammar induction.
A Stable and Effective Learning Strategy for Trainable Greedy Decoding
Aug 28, 2018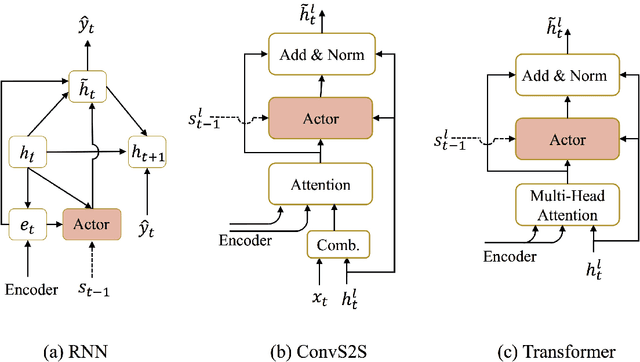
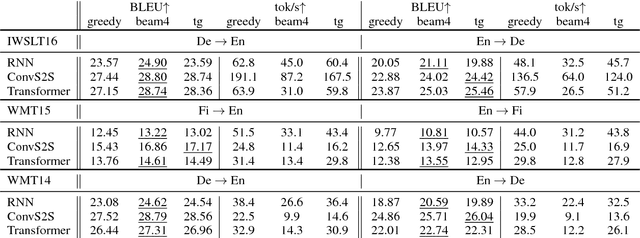
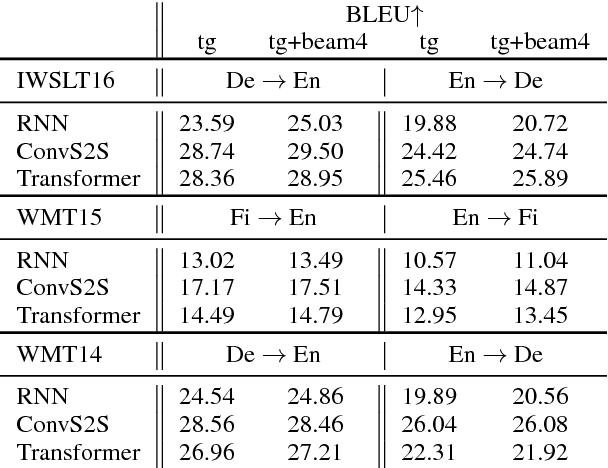
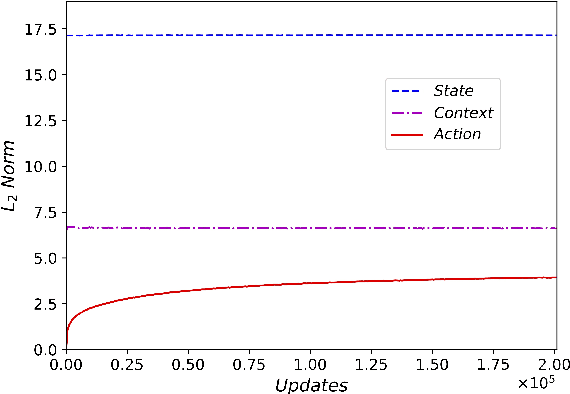
Beam search is a widely used approximate search strategy for neural network decoders, and it generally outperforms simple greedy decoding on tasks like machine translation. However, this improvement comes at substantial computational cost. In this paper, we propose a flexible new method that allows us to reap nearly the full benefits of beam search with nearly no additional computational cost. The method revolves around a small neural network actor that is trained to observe and manipulate the hidden state of a previously-trained decoder. To train this actor network, we introduce the use of a pseudo-parallel corpus built using the output of beam search on a base model, ranked by a target quality metric like BLEU. Our method is inspired by earlier work on this problem, but requires no reinforcement learning, and can be trained reliably on a range of models. Experiments on three parallel corpora and three architectures show that the method yields substantial improvements in translation quality and speed over each base system.
Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement
Aug 27, 2018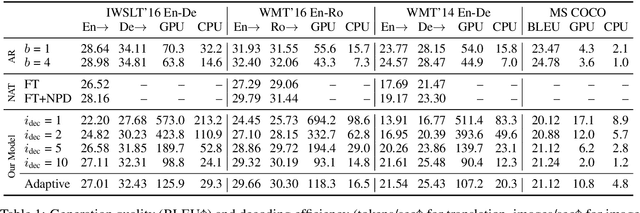
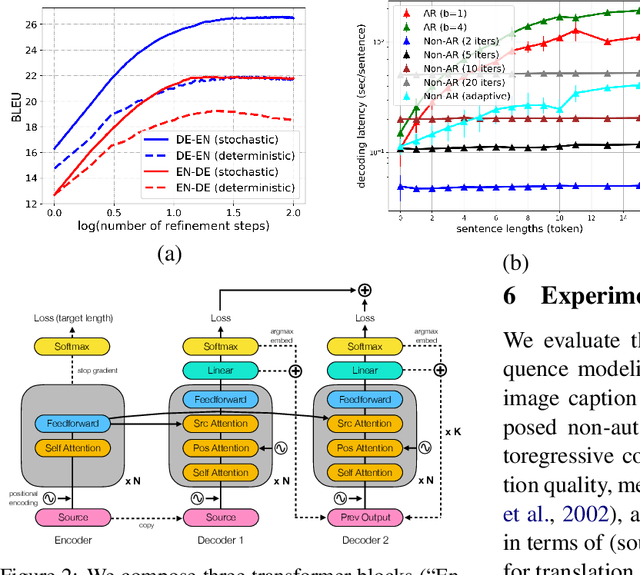
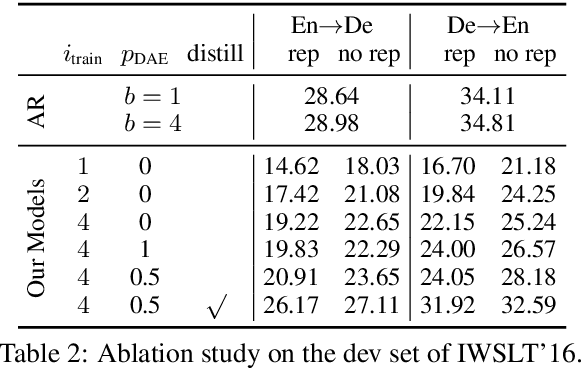
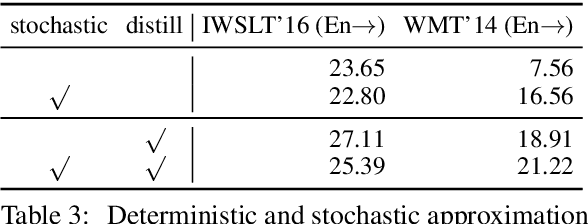
We propose a conditional non-autoregressive neural sequence model based on iterative refinement. The proposed model is designed based on the principles of latent variable models and denoising autoencoders, and is generally applicable to any sequence generation task. We extensively evaluate the proposed model on machine translation (En-De and En-Ro) and image caption generation, and observe that it significantly speeds up decoding while maintaining the generation quality comparable to the autoregressive counterpart.
Spatio-temporal Dynamics of Intrinsic Networks in Functional Magnetic Imaging Data Using Recurrent Neural Networks
Aug 27, 2018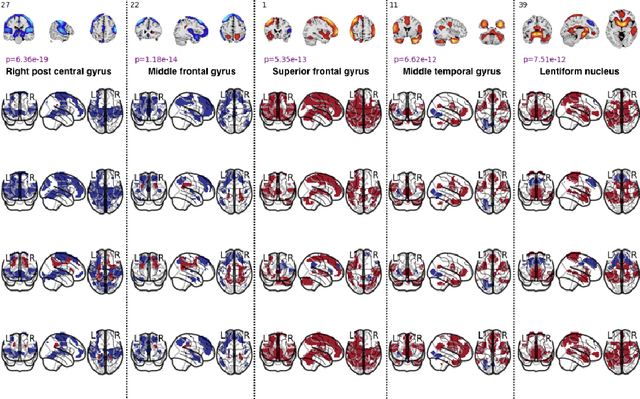
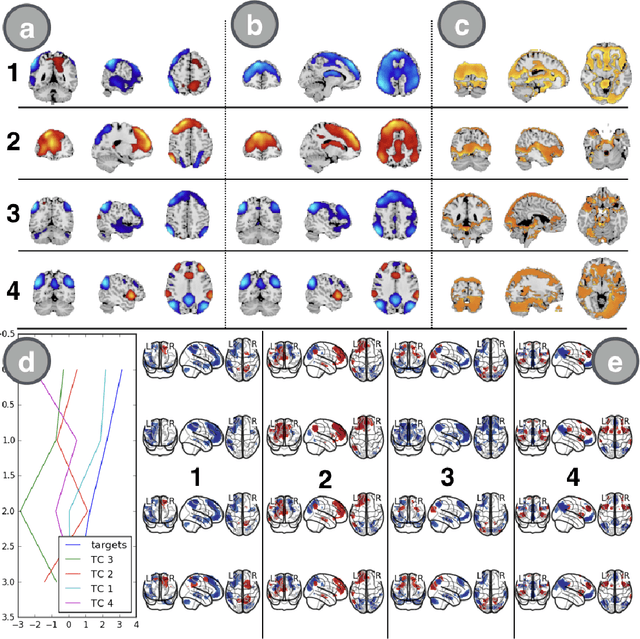
We introduce a novel recurrent neural network (RNN) approach to account for temporal dynamics and dependencies in brain networks observed via functional magnetic resonance imaging (fMRI). Our approach directly parameterizes temporal dynamics through recurrent connections, which can be used to formulate blind source separation with a conditional (rather than marginal) independence assumption, which we call RNN-ICA. This formulation enables us to visualize the temporal dynamics of both first order (activity) and second order (directed connectivity) information in brain networks that are widely studied in a static sense, but not well-characterized dynamically. RNN-ICA predicts dynamics directly from the recurrent states of the RNN in both task and resting state fMRI. Our results show both task-related and group-differentiating directed connectivity.
Meta-Learning for Low-Resource Neural Machine Translation
Aug 25, 2018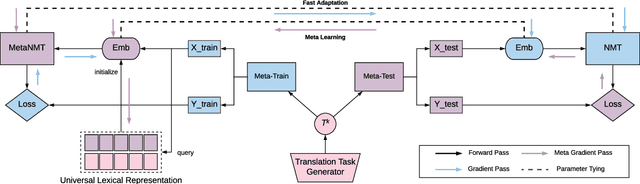
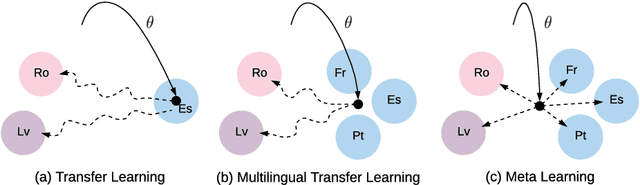
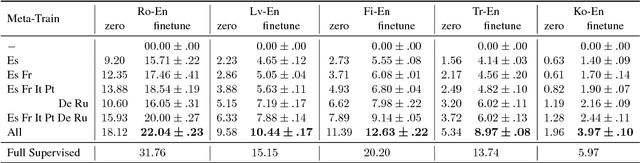
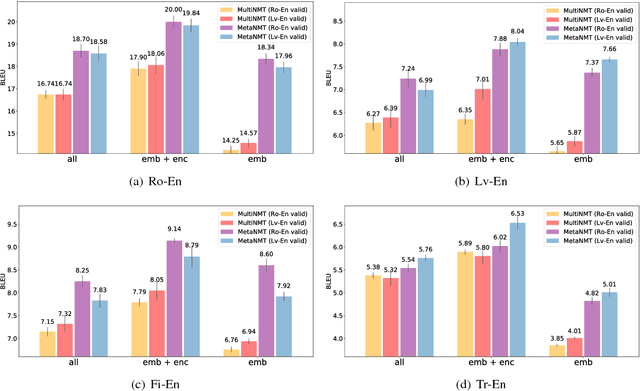
In this paper, we propose to extend the recently introduced model-agnostic meta-learning algorithm (MAML) for low-resource neural machine translation (NMT). We frame low-resource translation as a meta-learning problem, and we learn to adapt to low-resource languages based on multilingual high-resource language tasks. We use the universal lexical representation~\citep{gu2018universal} to overcome the input-output mismatch across different languages. We evaluate the proposed meta-learning strategy using eighteen European languages (Bg, Cs, Da, De, El, Es, Et, Fr, Hu, It, Lt, Nl, Pl, Pt, Sk, Sl, Sv and Ru) as source tasks and five diverse languages (Ro, Lv, Fi, Tr and Ko) as target tasks. We show that the proposed approach significantly outperforms the multilingual, transfer learning based approach~\citep{zoph2016transfer} and enables us to train a competitive NMT system with only a fraction of training examples. For instance, the proposed approach can achieve as high as 22.04 BLEU on Romanian-English WMT'16 by seeing only 16,000 translated words (~600 parallel sentences).
Vehicle Communication Strategies for Simulated Highway Driving
Aug 14, 2018

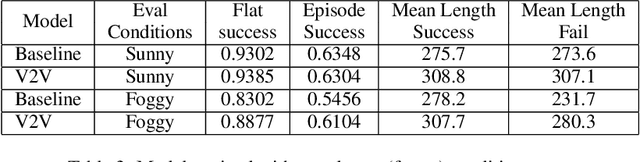
Interest in emergent communication has recently surged in Machine Learning. The focus of this interest has largely been either on investigating the properties of the learned protocol or on utilizing emergent communication to better solve problems that already have a viable solution. Here, we consider self-driving cars coordinating with each other and focus on how communication influences the agents' collective behavior. Our main result is that communication helps (most) with adverse conditions.
Conditional molecular design with deep generative models
Jul 23, 2018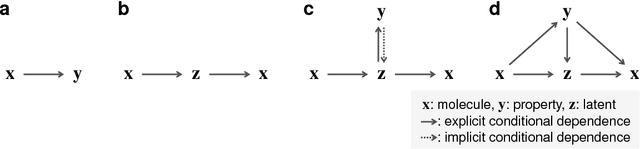
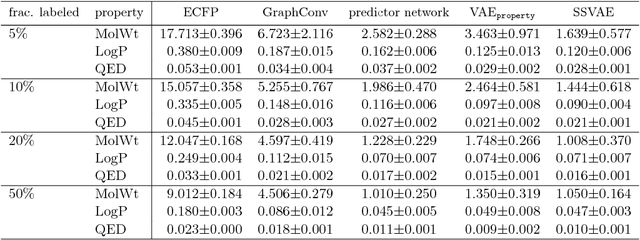
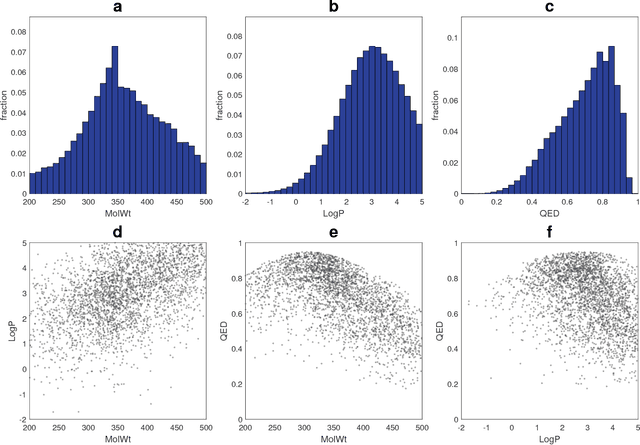
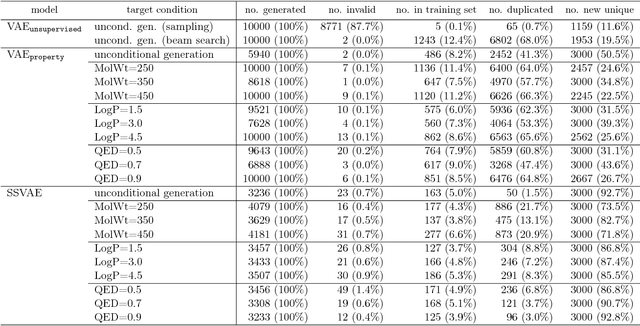
Although machine learning has been successfully used to propose novel molecules that satisfy desired properties, it is still challenging to explore a large chemical space efficiently. In this paper, we present a conditional molecular design method that facilitates generating new molecules with desired properties. The proposed model, which simultaneously performs both property prediction and molecule generation, is built as a semi-supervised variational autoencoder trained on a set of existing molecules with only a partial annotation. We generate new molecules with desired properties by sampling from the generative distribution estimated by the model. We demonstrate the effectiveness of the proposed model by evaluating it on drug-like molecules. The model improves the performance of property prediction by exploiting unlabeled molecules, and efficiently generates novel molecules fulfilling various target conditions.
QCD-Aware Recursive Neural Networks for Jet Physics
Jul 13, 2018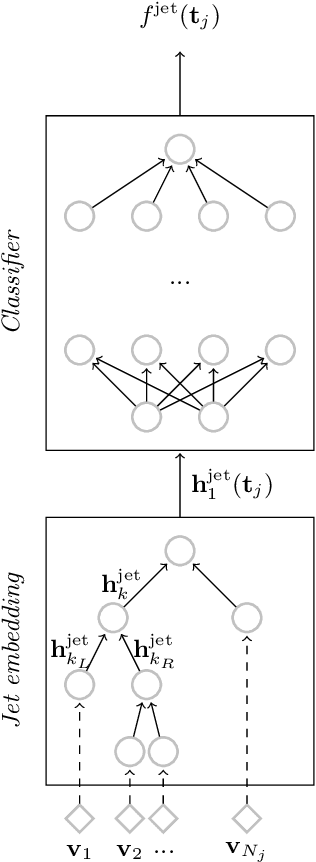
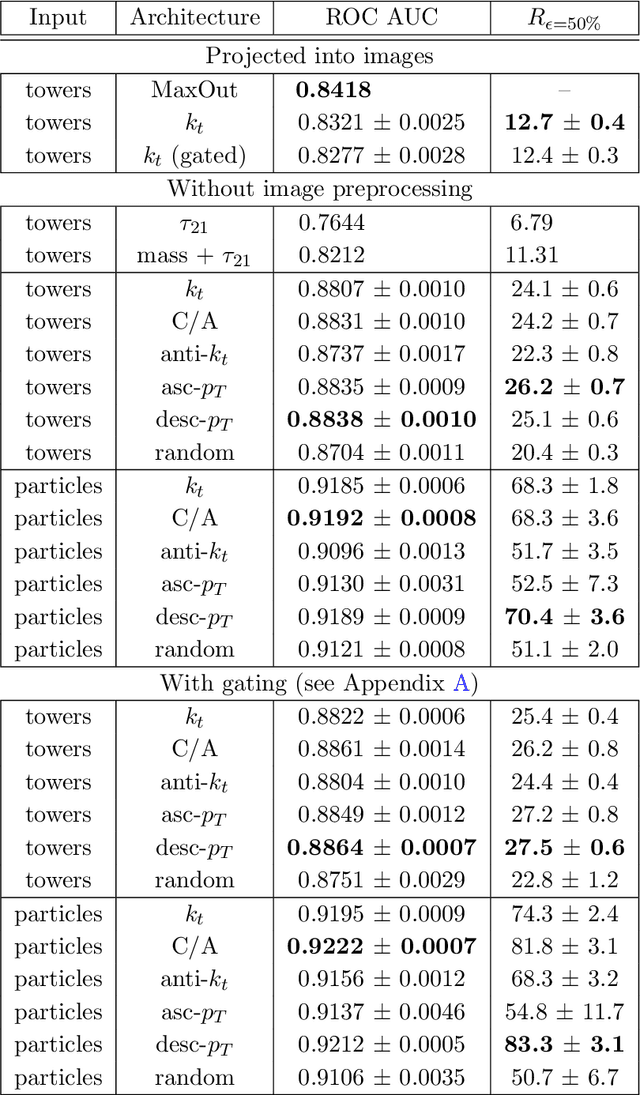
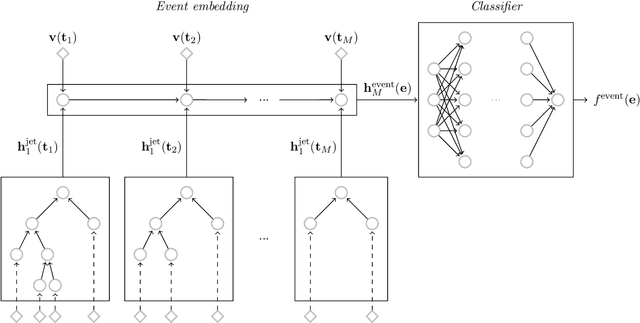
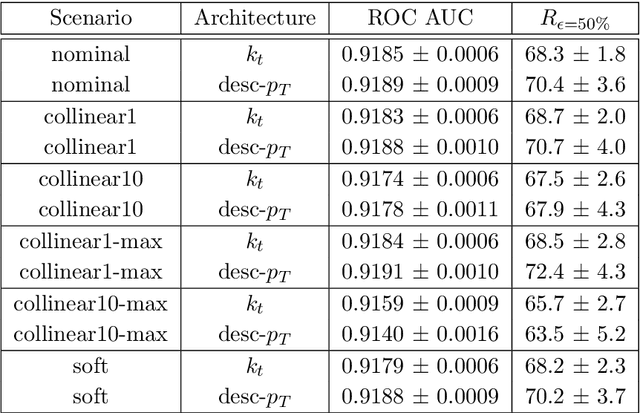
Recent progress in applying machine learning for jet physics has been built upon an analogy between calorimeters and images. In this work, we present a novel class of recursive neural networks built instead upon an analogy between QCD and natural languages. In the analogy, four-momenta are like words and the clustering history of sequential recombination jet algorithms is like the parsing of a sentence. Our approach works directly with the four-momenta of a variable-length set of particles, and the jet-based tree structure varies on an event-by-event basis. Our experiments highlight the flexibility of our method for building task-specific jet embeddings and show that recursive architectures are significantly more accurate and data efficient than previous image-based networks. We extend the analogy from individual jets (sentences) to full events (paragraphs), and show for the first time an event-level classifier operating on all the stable particles produced in an LHC event.
High-Resolution Breast Cancer Screening with Multi-View Deep Convolutional Neural Networks
Jun 28, 2018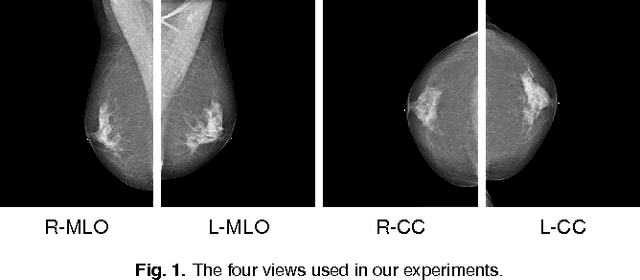

Advances in deep learning for natural images have prompted a surge of interest in applying similar techniques to medical images. The majority of the initial attempts focused on replacing the input of a deep convolutional neural network with a medical image, which does not take into consideration the fundamental differences between these two types of images. Specifically, fine details are necessary for detection in medical images, unlike in natural images where coarse structures matter most. This difference makes it inadequate to use the existing network architectures developed for natural images, because they work on heavily downscaled images to reduce the memory requirements. This hides details necessary to make accurate predictions. Additionally, a single exam in medical imaging often comes with a set of views which must be fused in order to reach a correct conclusion. In our work, we propose to use a multi-view deep convolutional neural network that handles a set of high-resolution medical images. We evaluate it on large-scale mammography-based breast cancer screening (BI-RADS prediction) using 886,000 images. We focus on investigating the impact of the training set size and image size on the prediction accuracy. Our results highlight that performance increases with the size of training set, and that the best performance can only be achieved using the original resolution. In the reader study, performed on a random subset of the test set, we confirmed the efficacy of our model, which achieved performance comparable to a committee of radiologists when presented with the same data.
Learning Distributed Representations from Reviews for Collaborative Filtering
Jun 18, 2018
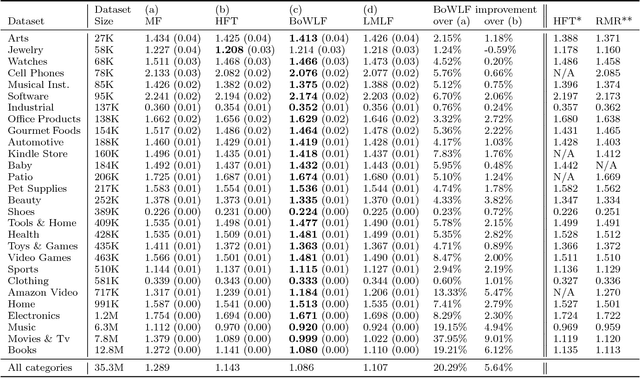
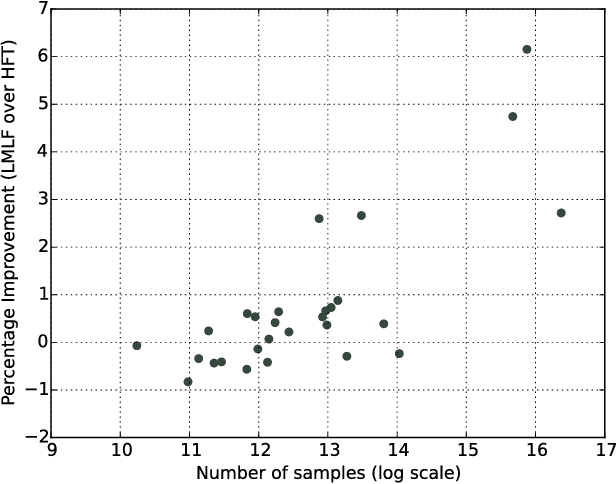
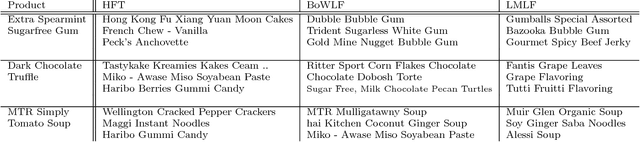
Recent work has shown that collaborative filter-based recommender systems can be improved by incorporating side information, such as natural language reviews, as a way of regularizing the derived product representations. Motivated by the success of this approach, we introduce two different models of reviews and study their effect on collaborative filtering performance. While the previous state-of-the-art approach is based on a latent Dirichlet allocation (LDA) model of reviews, the models we explore are neural network based: a bag-of-words product-of-experts model and a recurrent neural network. We demonstrate that the increased flexibility offered by the product-of-experts model allowed it to achieve state-of-the-art performance on the Amazon review dataset, outperforming the LDA-based approach. However, interestingly, the greater modeling power offered by the recurrent neural network appears to undermine the model's ability to act as a regularizer of the product representations.