 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating the World and Ego Models for Self-Driving
Apr 14, 2022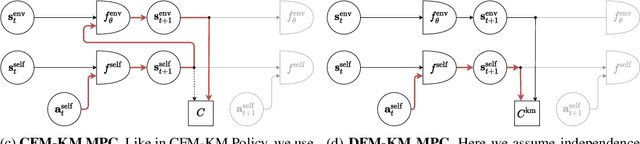

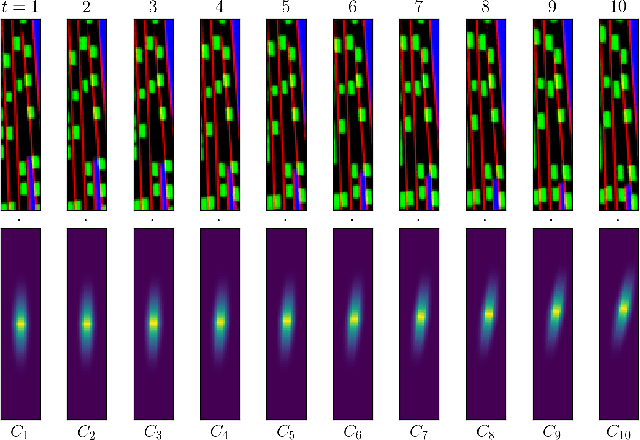
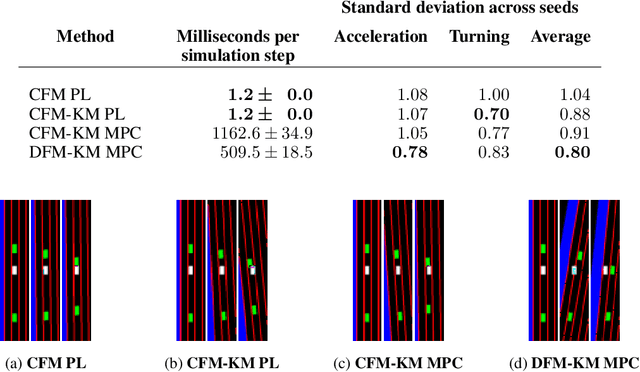
Training self-driving systems to be robust to the long-tail of driving scenarios is a critical problem. Model-based approaches leverage simulation to emulate a wide range of scenarios without putting users at risk in the real world. One promising path to faithful simulation is to train a forward model of the world to predict the future states of both the environment and the ego-vehicle given past states and a sequence of actions. In this paper, we argue that it is beneficial to model the state of the ego-vehicle, which often has simple, predictable and deterministic behavior, separately from the rest of the environment, which is much more complex and highly multimodal. We propose to model the ego-vehicle using a simple and differentiable kinematic model, while training a stochastic convolutional forward model on raster representations of the state to predict the behavior of the rest of the environment. We explore several configurations of such decoupled models, and evaluate their performance both with Model Predictive Control (MPC) and direct policy learning. We test our methods on the task of highway driving and demonstrate lower crash rates and better stability. The code is available at https://github.com/vladisai/pytorch-PPUU/tree/ICLR2022.
Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks
Feb 10, 2022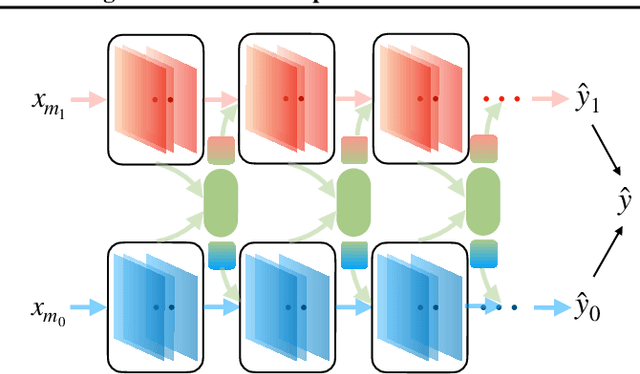

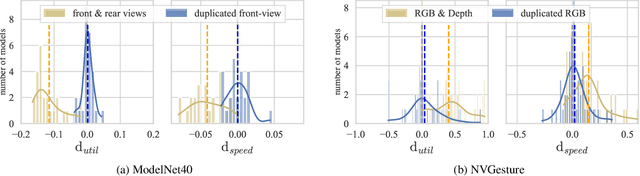
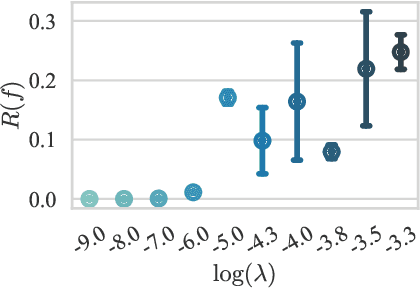
We hypothesize that due to the greedy nature of learning in multi-modal deep neural networks, these models tend to rely on just one modality while under-fitting the other modalities. Such behavior is counter-intuitive and hurts the models' generalization, as we observe empirically. To estimate the model's dependence on each modality, we compute the gain on the accuracy when the model has access to it in addition to another modality. We refer to this gain as the conditional utilization rate. In the experiments, we consistently observe an imbalance in conditional utilization rates between modalities, across multiple tasks and architectures. Since conditional utilization rate cannot be computed efficiently during training, we introduce a proxy for it based on the pace at which the model learns from each modality, which we refer to as the conditional learning speed. We propose an algorithm to balance the conditional learning speeds between modalities during training and demonstrate that it indeed addresses the issue of greedy learning. The proposed algorithm improves the model's generalization on three datasets: Colored MNIST, Princeton ModelNet40, and NVIDIA Dynamic Hand Gesture.
Generative multitask learning mitigates target-causing confounding
Feb 08, 2022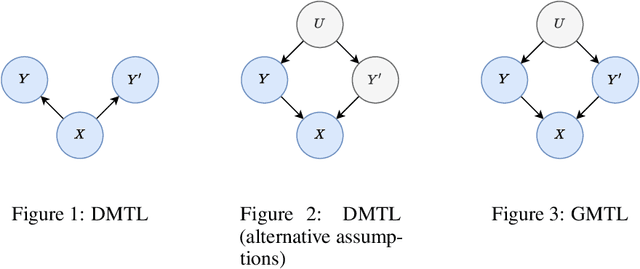


We propose a simple and scalable approach to causal representation learning for multitask learning. Our approach requires minimal modification to existing ML systems, and improves robustness to prior probability shift. The improvement comes from mitigating unobserved confounders that cause the targets, but not the input. We refer to them as target-causing confounders. These confounders induce spurious dependencies between the input and targets. This poses a problem for the conventional approach to multitask learning, due to its assumption that the targets are conditionally independent given the input. Our proposed approach takes into account the dependency between the targets in order to alleviate target-causing confounding. All that is required in addition to usual practice is to estimate the joint distribution of the targets to switch from discriminative to generative classification, and to predict all targets jointly. Our results on the Attributes of People and Taskonomy datasets reflect the conceptual improvement in robustness to prior probability shift.
Causal Scene BERT: Improving object detection by searching for challenging groups of data
Feb 08, 2022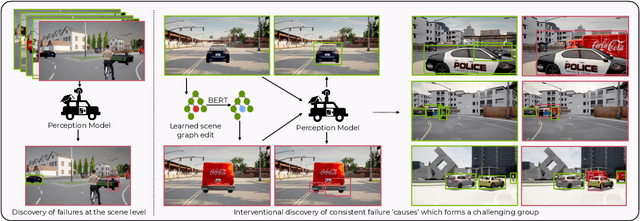
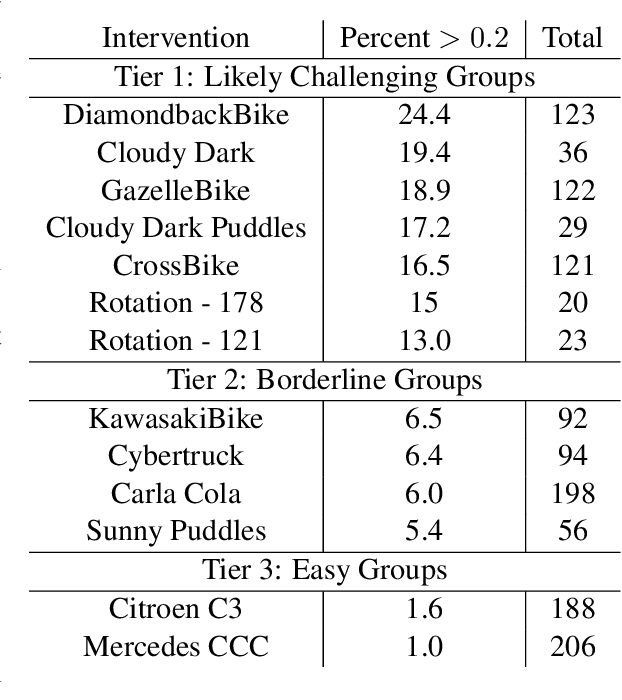
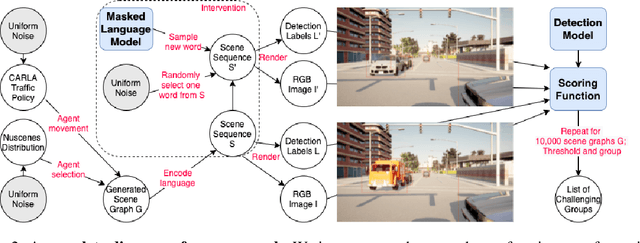
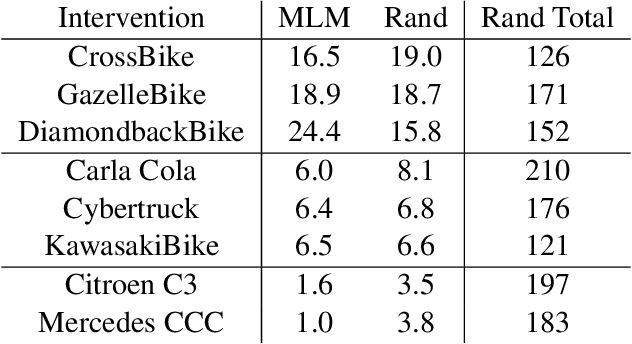
Modern computer vision applications rely on learning-based perception modules parameterized with neural networks for tasks like object detection. These modules frequently have low expected error overall but high error on atypical groups of data due to biases inherent in the training process. In building autonomous vehicles (AV), this problem is an especially important challenge because their perception modules are crucial to the overall system performance. After identifying failures in AV, a human team will comb through the associated data to group perception failures that share common causes. More data from these groups is then collected and annotated before retraining the model to fix the issue. In other words, error groups are found and addressed in hindsight. Our main contribution is a pseudo-automatic method to discover such groups in foresight by performing causal interventions on simulated scenes. To keep our interventions on the data manifold, we utilize masked language models. We verify that the prioritized groups found via intervention are challenging for the object detector and show that retraining with data collected from these groups helps inordinately compared to adding more IID data. We also plan to release software to run interventions in simulated scenes, which we hope will benefit the causality community.
LINDA: Unsupervised Learning to Interpolate in Natural Language Processing
Dec 28, 2021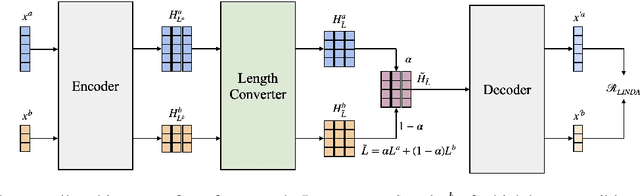
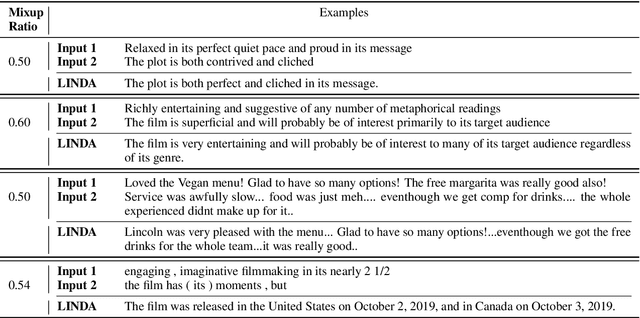
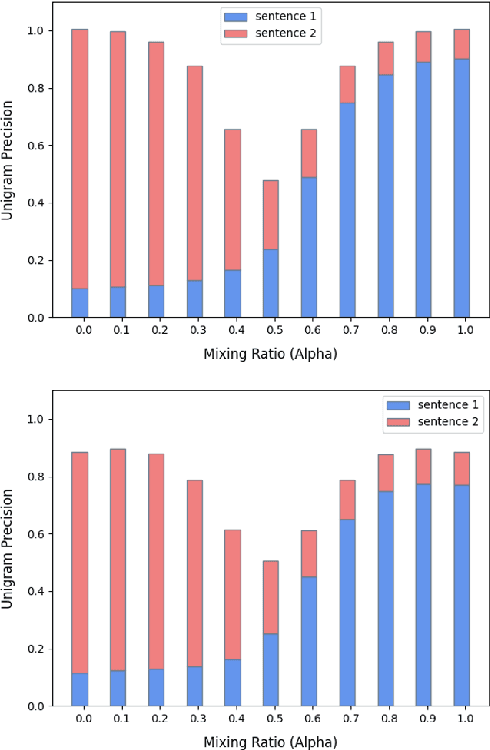
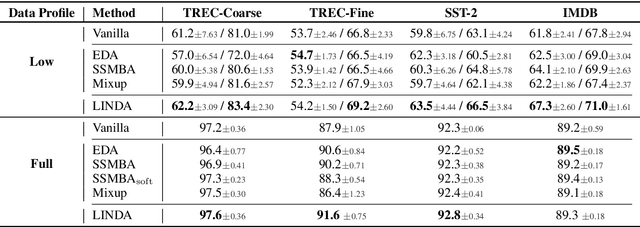
Despite the success of mixup in data augmentation, its applicability to natural language processing (NLP) tasks has been limited due to the discrete and variable-length nature of natural languages. Recent studies have thus relied on domain-specific heuristics and manually crafted resources, such as dictionaries, in order to apply mixup in NLP. In this paper, we instead propose an unsupervised learning approach to text interpolation for the purpose of data augmentation, to which we refer as "Learning to INterpolate for Data Augmentation" (LINDA), that does not require any heuristics nor manually crafted resources but learns to interpolate between any pair of natural language sentences over a natural language manifold. After empirically demonstrating the LINDA's interpolation capability, we show that LINDA indeed allows us to seamlessly apply mixup in NLP and leads to better generalization in text classification both in-domain and out-of-domain.
Characterizing and addressing the issue of oversmoothing in neural autoregressive sequence modeling
Dec 22, 2021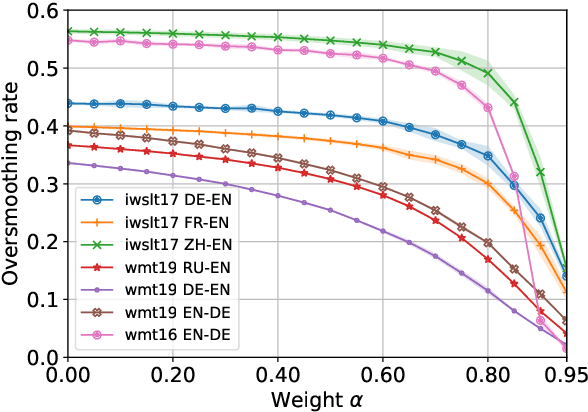
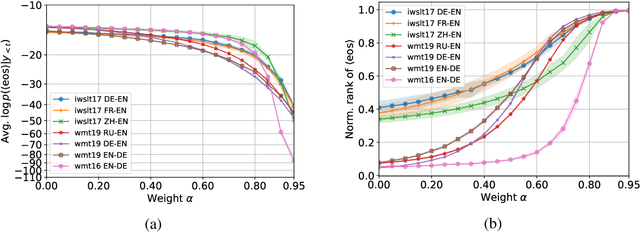
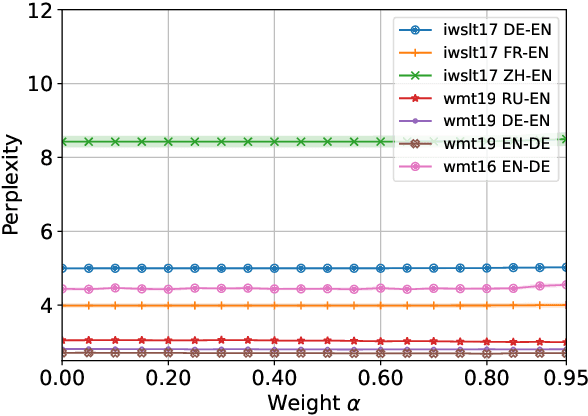
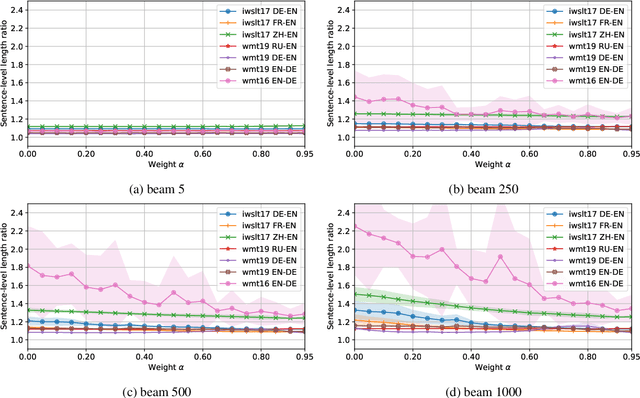
Neural autoregressive sequence models smear the probability among many possible sequences including degenerate ones, such as empty or repetitive sequences. In this work, we tackle one specific case where the model assigns a high probability to unreasonably short sequences. We define the oversmoothing rate to quantify this issue. After confirming the high degree of oversmoothing in neural machine translation, we propose to explicitly minimize the oversmoothing rate during training. We conduct a set of experiments to study the effect of the proposed regularization on both model distribution and decoding performance. We use a neural machine translation task as the testbed and consider three different datasets of varying size. Our experiments reveal three major findings. First, we can control the oversmoothing rate of the model by tuning the strength of the regularization. Second, by enhancing the oversmoothing loss contribution, the probability and the rank of <eos> token decrease heavily at positions where it is not supposed to be. Third, the proposed regularization impacts the outcome of beam search especially when a large beam is used. The degradation of translation quality (measured in BLEU) with a large beam significantly lessens with lower oversmoothing rate, but the degradation compared to smaller beam sizes remains to exist. From these observations, we conclude that the high degree of oversmoothing is the main reason behind the degenerate case of overly probable short sequences in a neural autoregressive model.
Amortized Noisy Channel Neural Machine Translation
Dec 16, 2021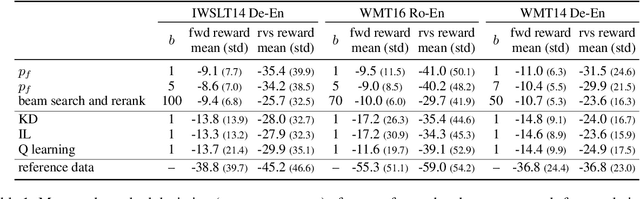
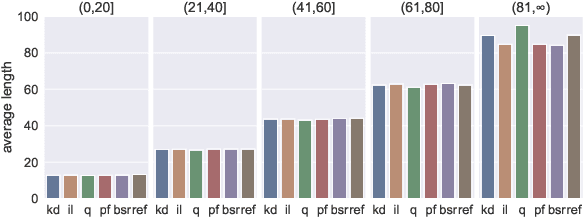
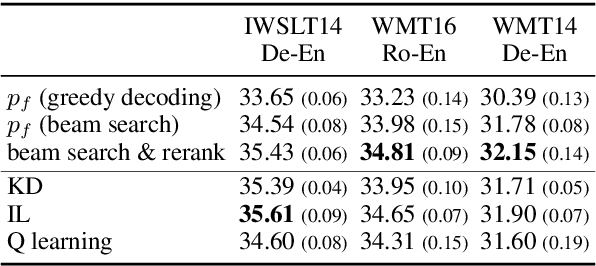
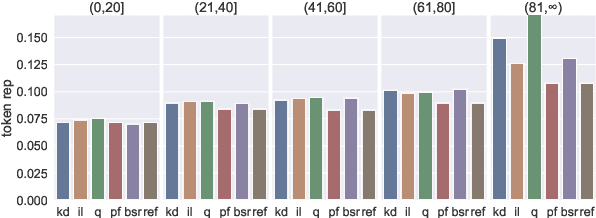
Noisy channel models have been especially effective in neural machine translation (NMT). However, recent approaches like "beam search and rerank" (BSR) incur significant computation overhead during inference, making real-world application infeasible. We aim to build an amortized noisy channel NMT model such that greedily decoding from it would generate translations that maximize the same reward as translations generated using BSR. We attempt three approaches: knowledge distillation, 1-step-deviation imitation learning, and Q learning. The first approach obtains the noisy channel signal from a pseudo-corpus, and the latter two approaches aim to optimize toward a noisy-channel MT reward directly. All three approaches speed up inference by 1-2 orders of magnitude. For all three approaches, the generated translations fail to achieve rewards comparable to BSR, but the translation quality approximated by BLEU is similar to the quality of BSR-produced translations.
Causal Effect Variational Autoencoder with Uniform Treatment
Nov 16, 2021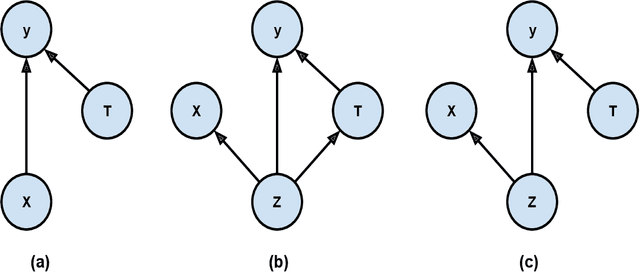


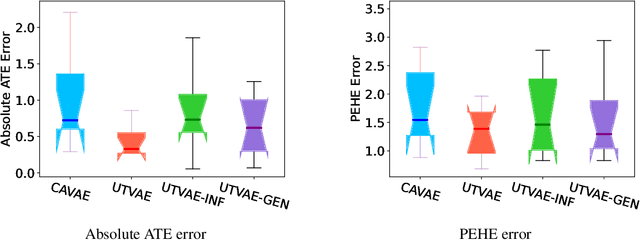
Causal effect variational autoencoder (CEVAE) are trained to predict the outcome given observational treatment data, while uniform treatment variational autoencoders (UTVAE) are trained with uniform treatment distribution using importance sampling. In this paper, we show that using uniform treatment over observational treatment distribution leads to better causal inference by mitigating the distribution shift that occurs from training to test time. We also explore the combination of uniform and observational treatment distributions with inference and generative network training objectives to find a better training procedure for inferring treatment effect. Experimentally, we find that the proposed UTVAE yields better absolute average treatment effect error and precision in estimation of heterogeneous effect error than the CEVAE on synthetic and IHDP datasets.
DEEP: DEnoising Entity Pre-training for Neural Machine Translation
Nov 14, 2021
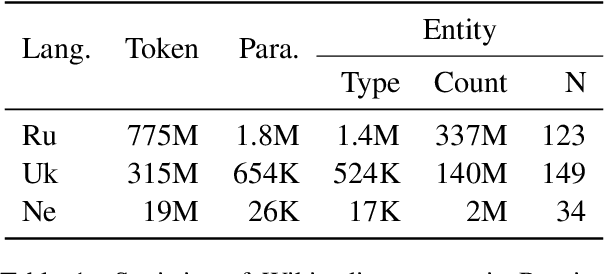
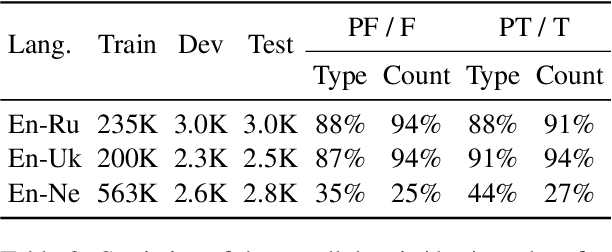
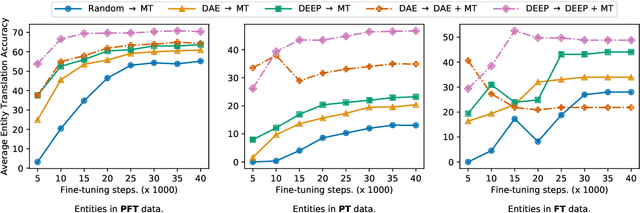
It has been shown that machine translation models usually generate poor translations for named entities that are infrequent in the training corpus. Earlier named entity translation methods mainly focus on phonetic transliteration, which ignores the sentence context for translation and is limited in domain and language coverage. To address this limitation, we propose DEEP, a DEnoising Entity Pre-training method that leverages large amounts of monolingual data and a knowledge base to improve named entity translation accuracy within sentences. Besides, we investigate a multi-task learning strategy that finetunes a pre-trained neural machine translation model on both entity-augmented monolingual data and parallel data to further improve entity translation. Experimental results on three language pairs demonstrate that \method results in significant improvements over strong denoising auto-encoding baselines, with a gain of up to 1.3 BLEU and up to 9.2 entity accuracy points for English-Russian translation.
AlphaD3M: Machine Learning Pipeline Synthesis
Nov 03, 2021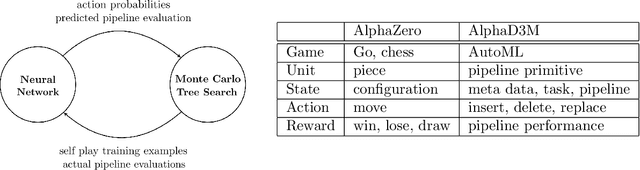
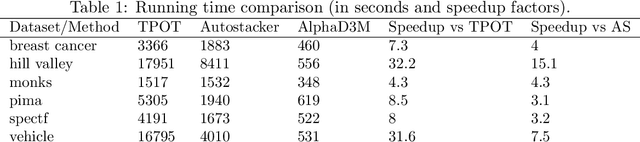
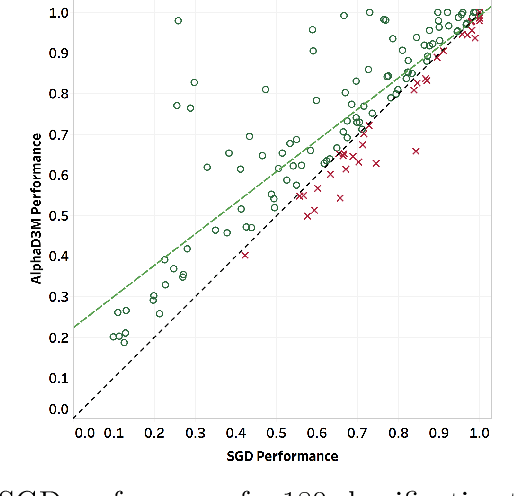
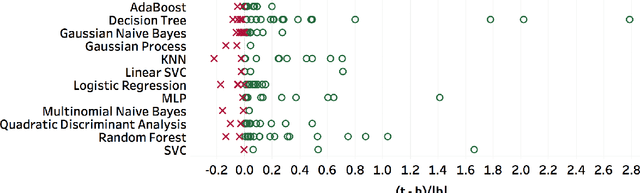
We introduce AlphaD3M, an automatic machine learning (AutoML) system based on meta reinforcement learning using sequence models with self play. AlphaD3M is based on edit operations performed over machine learning pipeline primitives providing explainability. We compare AlphaD3M with state-of-the-art AutoML systems: Autosklearn, Autostacker, and TPOT, on OpenML datasets. AlphaD3M achieves competitive performance while being an order of magnitude faster, reducing computation time from hours to minutes, and is explainable by design.