 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyna-bAbI: unlocking bAbI's potential with dynamic synthetic benchmarking
Nov 30, 2021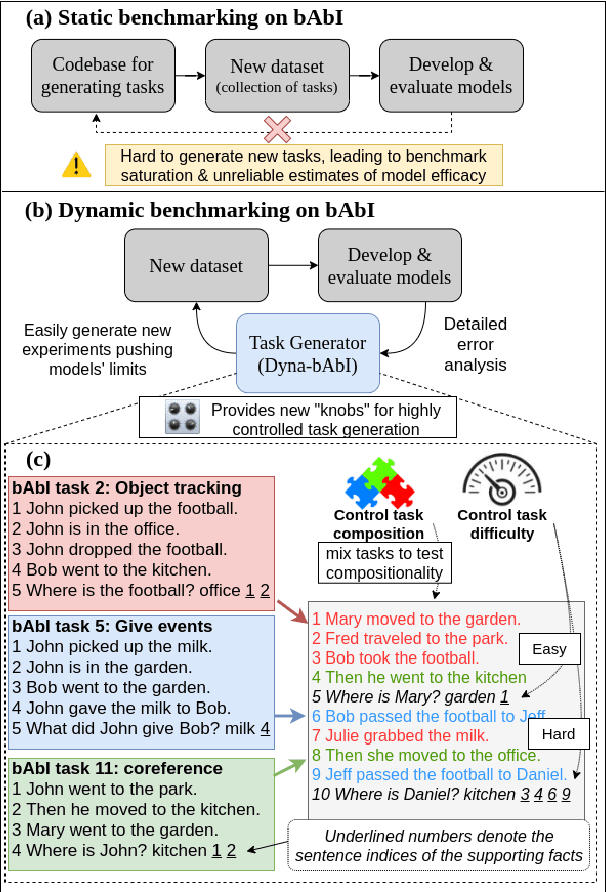
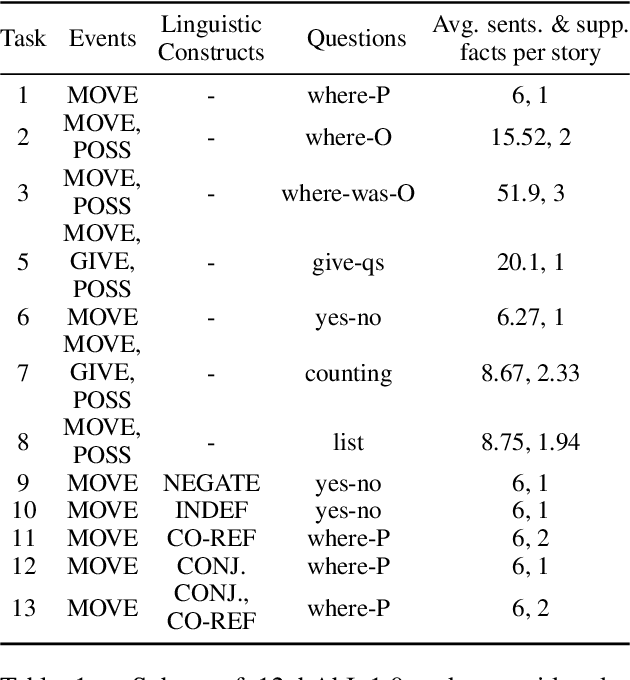
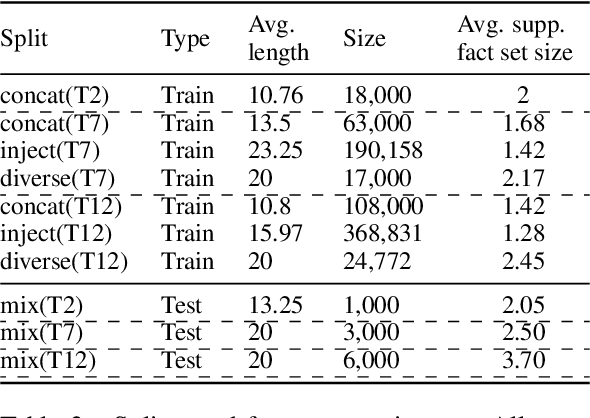
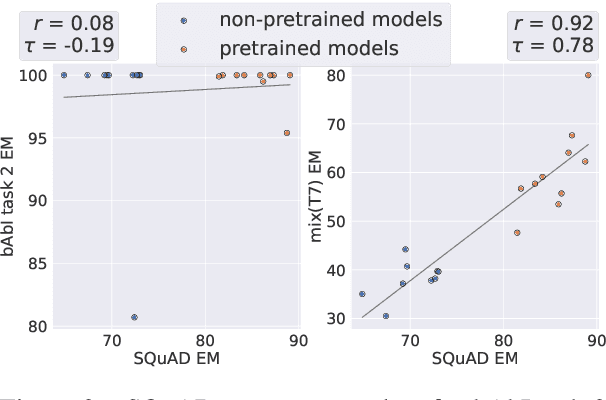
While neural language models often perform surprisingly well on natural language understanding (NLU) tasks, their strengths and limitations remain poorly understood. Controlled synthetic tasks are thus an increasingly important resource for diagnosing model behavior. In this work we focus on story understanding, a core competency for NLU systems. However, the main synthetic resource for story understanding, the bAbI benchmark, lacks such a systematic mechanism for controllable task generation. We develop Dyna-bAbI, a dynamic framework providing fine-grained control over task generation in bAbI. We demonstrate our ideas by constructing three new tasks requiring compositional generalization, an important evaluation setting absent from the original benchmark. We tested both special-purpose models developed for bAbI as well as state-of-the-art pre-trained methods, and found that while both approaches solve the original tasks (>99% accuracy), neither approach succeeded in the compositional generalization setting, indicating the limitations of the original training data. We explored ways to augment the original data, and found that though diversifying training data was far more useful than simply increasing dataset size, it was still insufficient for driving robust compositional generalization (with <70% accuracy for complex compositions). Our results underscore the importance of highly controllable task generators for creating robust NLU systems through a virtuous cycle of model and data development.
Learning to Solve Complex Tasks by Talking to Agents
Oct 16, 2021


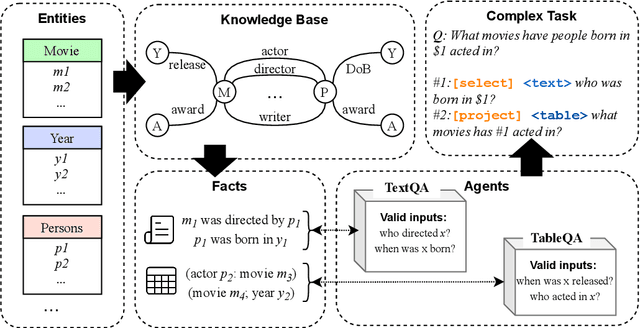
Humans often solve complex problems by interacting (in natural language) with existing agents, such as AI assistants, that can solve simpler sub-tasks. These agents themselves can be powerful systems built using extensive resources and privately held data. In contrast, common NLP benchmarks aim for the development of self-sufficient models for every task. To address this gap and facilitate research towards ``green'' AI systems that build upon existing agents, we propose a new benchmark called CommaQA that contains three kinds of complex reasoning tasks that are designed to be solved by ``talking'' to four agents with different capabilities. We demonstrate that state-of-the-art black-box models, which are unable to leverage existing agents, struggle on CommaQA (exact match score only reaches 40pts) even when given access to the agents' internal knowledge and gold fact supervision. On the other hand, models using gold question decomposition supervision can indeed solve CommaQA to a high accuracy (over 96\% exact match) by learning to utilize the agents. Even these additional supervision models, however, do not solve our compositional generalization test set. Finally the end-goal of learning to solve complex tasks by communicating with existing agents \emph{without relying on any additional supervision} remains unsolved and we hope CommaQA serves as a novel benchmark to enable the development of such systems.
DeepA2: A Modular Framework for Deep Argument Analysis with Pretrained Neural Text2Text Language Models
Oct 04, 2021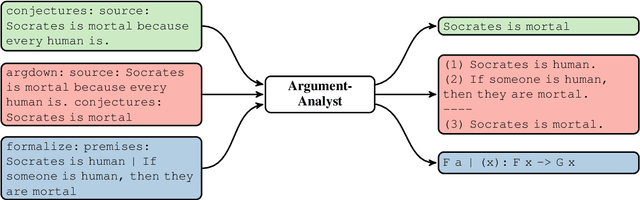
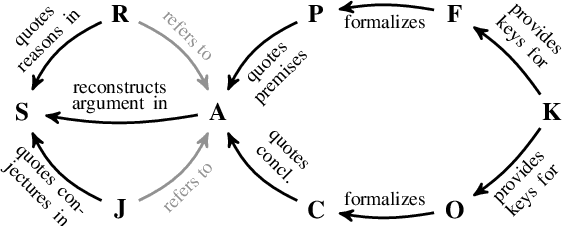
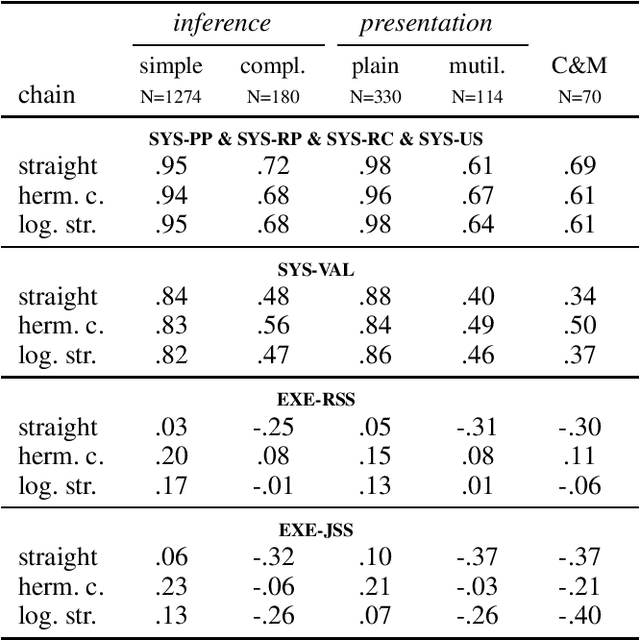
In this paper, we present and implement a multi-dimensional, modular framework for performing deep argument analysis (DeepA2) using current pre-trained language models (PTLMs). ArgumentAnalyst -- a T5 model (Raffel et al. 2020) set up and trained within DeepA2 -- reconstructs argumentative texts, which advance an informal argumentation, as valid arguments: It inserts, e.g., missing premises and conclusions, formalizes inferences, and coherently links the logical reconstruction to the source text. We create a synthetic corpus for deep argument analysis, and evaluate ArgumentAnalyst on this new dataset as well as on existing data, specifically EntailmentBank (Dalvi et al. 2021). Our empirical findings vindicate the overall framework and highlight the advantages of a modular design, in particular its ability to emulate established heuristics (such as hermeneutic cycles), to explore the model's uncertainty, to cope with the plurality of correct solutions (underdetermination), and to exploit higher-order evidence.
Investigating Transfer Learning in Multilingual Pre-trained Language Models through Chinese Natural Language Inference
Jun 07, 2021


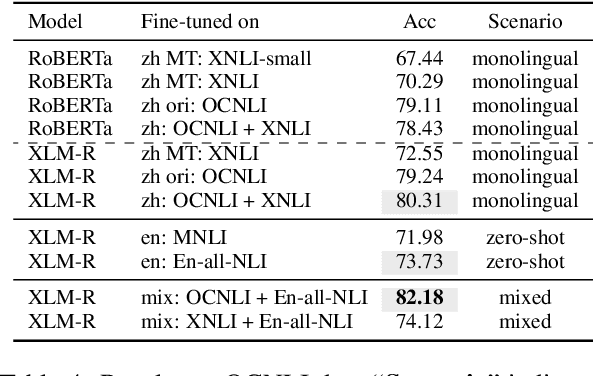
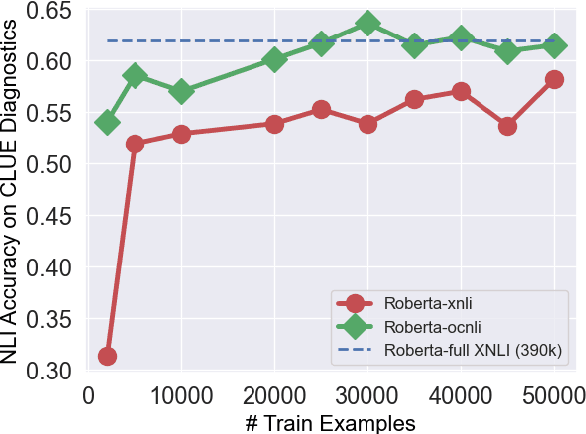
Multilingual transformers (XLM, mT5) have been shown to have remarkable transfer skills in zero-shot settings. Most transfer studies, however, rely on automatically translated resources (XNLI, XQuAD), making it hard to discern the particular linguistic knowledge that is being transferred, and the role of expert annotated monolingual datasets when developing task-specific models. We investigate the cross-lingual transfer abilities of XLM-R for Chinese and English natural language inference (NLI), with a focus on the recent large-scale Chinese dataset OCNLI. To better understand linguistic transfer, we created 4 categories of challenge and adversarial tasks (totaling 17 new datasets) for Chinese that build on several well-known resources for English (e.g., HANS, NLI stress-tests). We find that cross-lingual models trained on English NLI do transfer well across our Chinese tasks (e.g., in 3/4 of our challenge categories, they perform as well/better than the best monolingual models, even on 3/5 uniquely Chinese linguistic phenomena such as idioms, pro drop). These results, however, come with important caveats: cross-lingual models often perform best when trained on a mixture of English and high-quality monolingual NLI data (OCNLI), and are often hindered by automatically translated resources (XNLI-zh). For many phenomena, all models continue to struggle, highlighting the need for our new diagnostics to help benchmark Chinese and cross-lingual models. All new datasets/code are released at https://github.com/huhailinguist/ChineseNLIProbing.
Thinking Aloud: Dynamic Context Generation Improves Zero-Shot Reasoning Performance of GPT-2
Mar 24, 2021

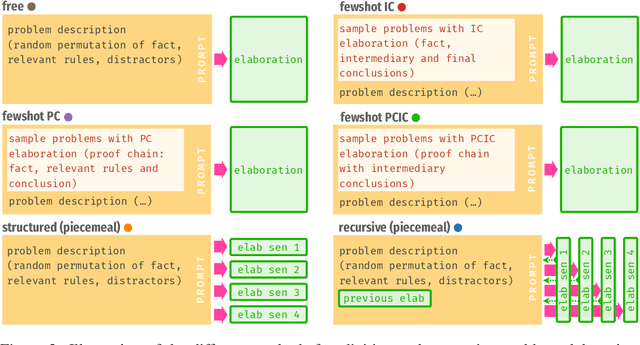
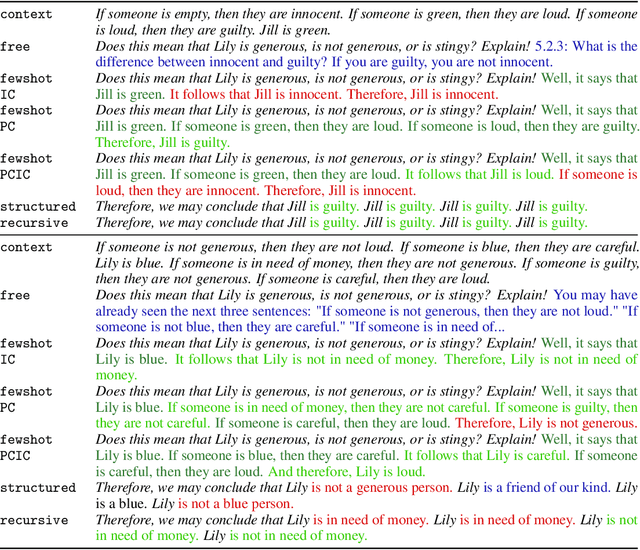
Thinking aloud is an effective meta-cognitive strategy human reasoners apply to solve difficult problems. We suggest to improve the reasoning ability of pre-trained neural language models in a similar way, namely by expanding a task's context with problem elaborations that are dynamically generated by the language model itself. Our main result is that dynamic problem elaboration significantly improves the zero-shot performance of GPT-2 in a deductive reasoning and natural language inference task: While the model uses a syntactic heuristic for predicting an answer, it is capable (to some degree) of generating reasoned additional context which facilitates the successful application of its heuristic. We explore different ways of generating elaborations, including fewshot learning, and find that their relative performance varies with the specific problem characteristics (such as problem difficulty). Moreover, the effectiveness of an elaboration can be explained in terms of the degree to which the elaboration semantically coheres with the corresponding problem. In particular, elaborations that are most faithful to the original problem description may boost accuracy by up to 24%.
Think you have Solved Direct-Answer Question Answering? Try ARC-DA, the Direct-Answer AI2 Reasoning Challenge
Feb 05, 2021
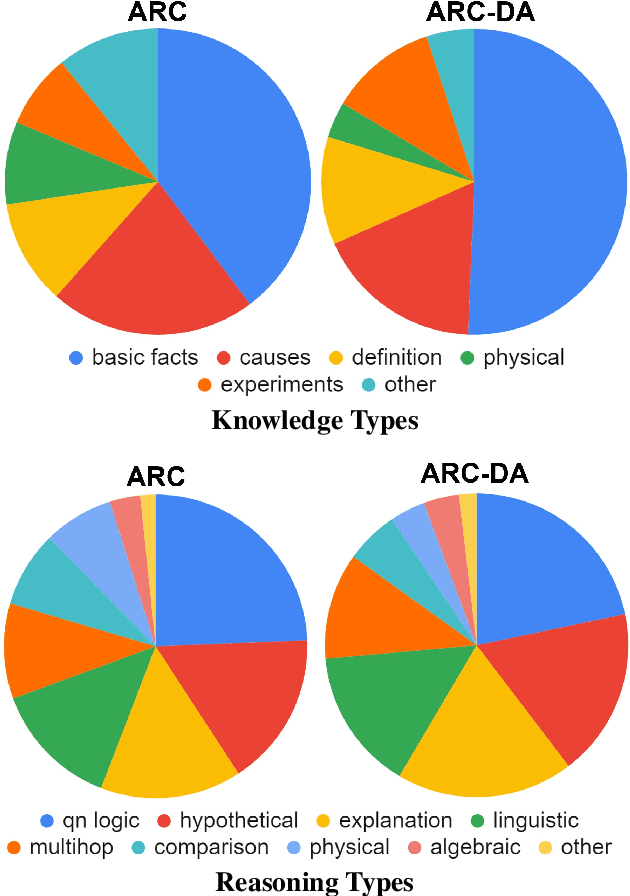
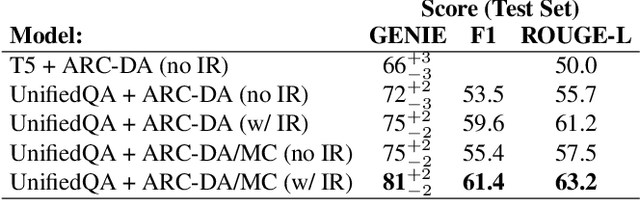
We present the ARC-DA dataset, a direct-answer ("open response", "freeform") version of the ARC (AI2 Reasoning Challenge) multiple-choice dataset. While ARC has been influential in the community, its multiple-choice format is unrepresentative of real-world questions, and multiple choice formats can be particularly susceptible to artifacts. The ARC-DA dataset addresses these concerns by converting questions to direct-answer format using a combination of crowdsourcing and expert review. The resulting dataset contains 2985 questions with a total of 8436 valid answers (questions typically have more than one valid answer). ARC-DA is one of the first DA datasets of natural questions that often require reasoning, and where appropriate question decompositions are not evident from the questions themselves. We describe the conversion approach taken, appropriate evaluation metrics, and several strong models. Although high, the best scores (81% GENIE, 61.4% F1, 63.2% ROUGE-L) still leave considerable room for improvement. In addition, the dataset provides a natural setting for new research on explanation, as many questions require reasoning to construct answers. We hope the dataset spurs further advances in complex question-answering by the community. ARC-DA is available at https://allenai.org/data/arc-da
A Dataset for Tracking Entities in Open Domain Procedural Text
Oct 31, 2020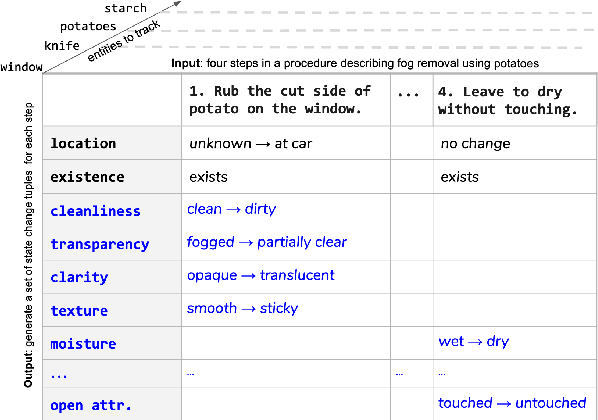
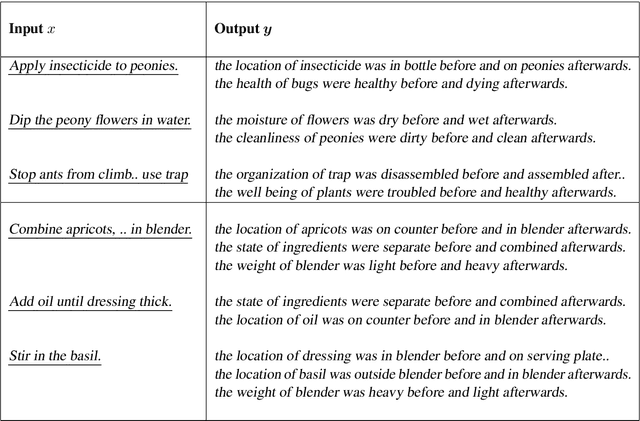
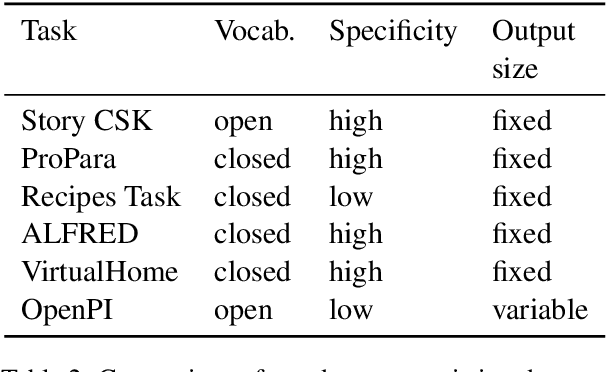

We present the first dataset for tracking state changes in procedural text from arbitrary domains by using an unrestricted (open) vocabulary. For example, in a text describing fog removal using potatoes, a car window may transition between being foggy, sticky,opaque, and clear. Previous formulations of this task provide the text and entities involved,and ask how those entities change for just a small, pre-defined set of attributes (e.g., location), limiting their fidelity. Our solution is a new task formulation where given just a procedural text as input, the task is to generate a set of state change tuples(entity, at-tribute, before-state, after-state)for each step,where the entity, attribute, and state values must be predicted from an open vocabulary. Using crowdsourcing, we create OPENPI1, a high-quality (91.5% coverage as judged by humans and completely vetted), and large-scale dataset comprising 29,928 state changes over 4,050 sentences from 810 procedural real-world paragraphs from WikiHow.com. A current state-of-the-art generation model on this task achieves 16.1% F1 based on BLEU metric, leaving enough room for novel model architectures.
Temporal Reasoning on Implicit Events from Distant Supervision
Oct 24, 2020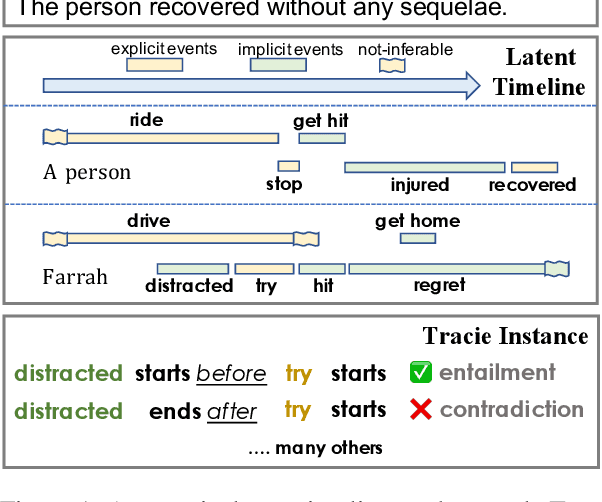
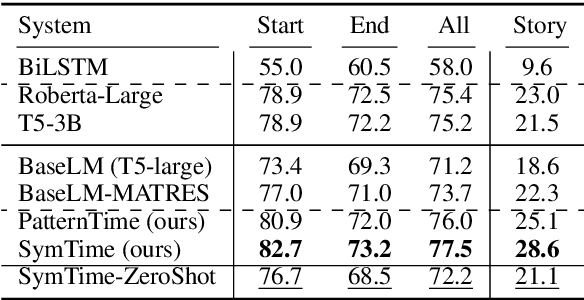

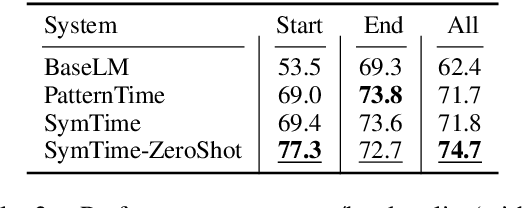
Existing works on temporal reasoning among events described in text focus on modeling relationships between explicitly mentioned events and do not handle event end time effectively. However, human readers can infer from natural language text many implicit events that help them better understand the situation and, consequently, better reason about time. This work proposes a new crowd-sourced dataset, TRACIE, which evaluates systems' understanding of implicit events - events that are not mentioned explicitly in the text but can be inferred from it. This is done via textual entailment instances querying both start and end times of events. We show that TRACIE is challenging for state-of-the-art language models. Our proposed model, SymTime, exploits distant supervision signals from the text itself and reasons over events' start time and duration to infer events' end time points. We show that our approach improves over baseline language models, gaining 5% on the i.i.d. split and 9% on an out-of-distribution test split. Our approach is also general to other annotation schemes, gaining 2%-8% on MATRES, an extrinsic temporal relation benchmark.
OCNLI: Original Chinese Natural Language Inference
Oct 12, 2020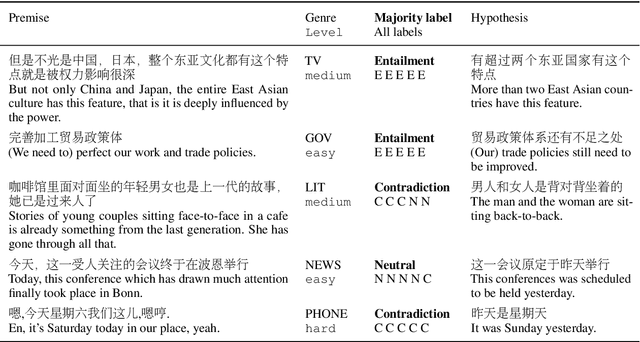
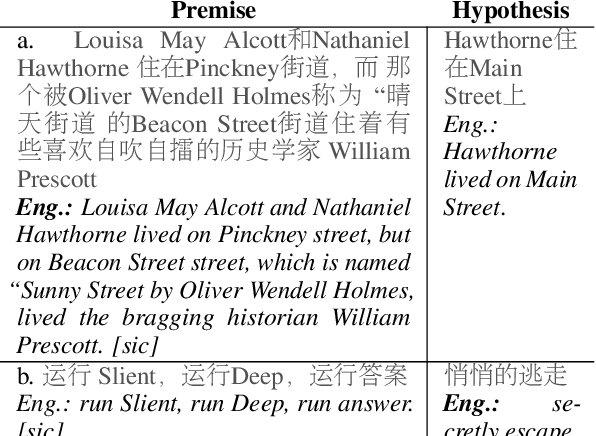
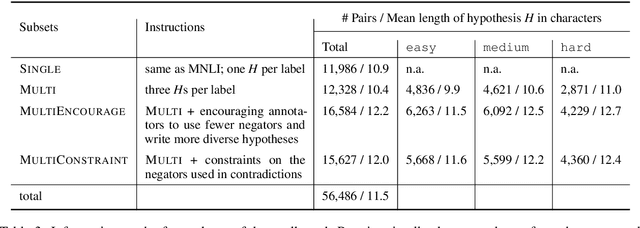
Despite the tremendous recent progress on natural language inference (NLI), driven largely by large-scale investment in new datasets (e.g., SNLI, MNLI) and advances in modeling, most progress has been limited to English due to a lack of reliable datasets for most of the world's languages. In this paper, we present the first large-scale NLI dataset (consisting of ~56,000 annotated sentence pairs) for Chinese called the Original Chinese Natural Language Inference dataset (OCNLI). Unlike recent attempts at extending NLI to other languages, our dataset does not rely on any automatic translation or non-expert annotation. Instead, we elicit annotations from native speakers specializing in linguistics. We follow closely the annotation protocol used for MNLI, but create new strategies for eliciting diverse hypotheses. We establish several baseline results on our dataset using state-of-the-art pre-trained models for Chinese, and find even the best performing models to be far outpaced by human performance (~12% absolute performance gap), making it a challenging new resource that we hope will help to accelerate progress in Chinese NLU. To the best of our knowledge, this is the first human-elicited MNLI-style corpus for a non-English language.
Text Modular Networks: Learning to Decompose Tasks in the Language of Existing Models
Sep 01, 2020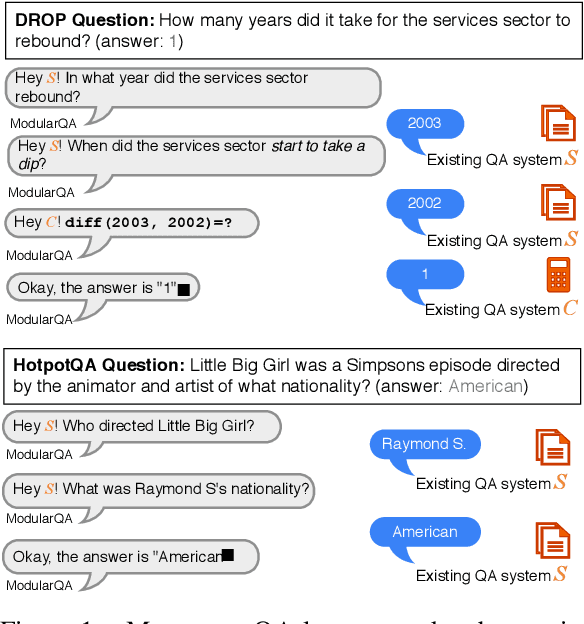

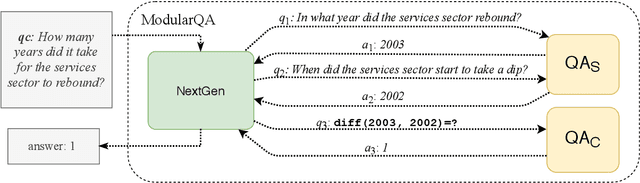
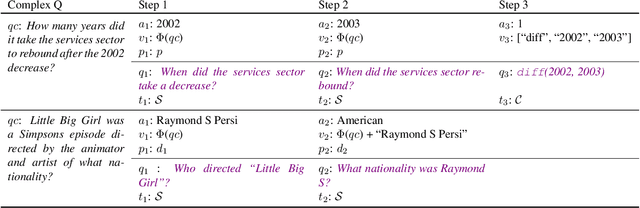
A common approach to solve complex tasks is by breaking them down into simple sub-problems that can then be solved by simpler modules. However, these approaches often need to be designed and trained specifically for each complex task. We propose a general approach, Text Modular Networks(TMNs), where the system learns to decompose any complex task into the language of existing models. Specifically, we focus on Question Answering (QA) and learn to decompose complex questions into sub-questions answerable by existing QA models. TMNs treat these models as blackboxes and learn their textual input-output behavior (i.e., their language) through their task datasets. Our next-question generator then learns to sequentially produce sub-questions that help answer a given complex question. These sub-questions are posed to different existing QA models and, together with their answers, provide a natural language explanation of the exact reasoning used by the model. We present the first system, incorporating a neural factoid QA model and a symbolic calculator, that uses decomposition for the DROP dataset, while also generalizing to the multi-hop HotpotQA dataset. Our system, ModularQA, outperforms a cross-task baseline by 10-60 F1 points and performs comparable to task-specific systems, while also providing an easy-to-read explanation of its reasoning.