 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Analysis of State-Funded News Coverage of the Israel-Hamas War on YouTube Shorts
Apr 01, 2026YouTube Shorts have become central to news consumption on the platform, yet research on how geopolitical events are represented in this format remains limited. To address this gap, we present a multimodal pipeline that combines automatic transcription, aspect-based sentiment analysis (ABSA), and semantic scene classification. The pipeline is first assessed for feasibility and then applied to analyze short-form coverage of the Israel-Hamas war by state-funded outlets. Using over 2,300 conflict-related Shorts and more than 94,000 visual frames, we systematically examine war reporting across major international broadcasters. Our findings reveal that the sentiment expressed in transcripts regarding specific aspects differs across outlets and over time, whereas scene-type classifications reflect visual cues consistent with real-world events. Notably, smaller domain-adapted models outperform large transformers and even LLMs for sentiment analysis, underscoring the value of resource-efficient approaches for humanities research. The pipeline serves as a template for other short-form platforms, such as TikTok and Instagram, and demonstrates how multimodal methods, combined with qualitative interpretation, can characterize sentiment patterns and visual cues in algorithmically driven video environments.
OCNLI: Original Chinese Natural Language Inference
Oct 12, 2020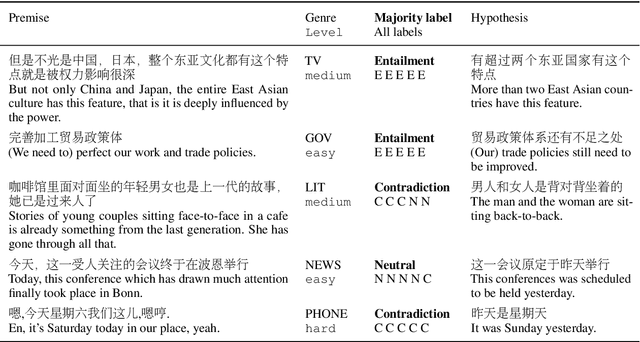
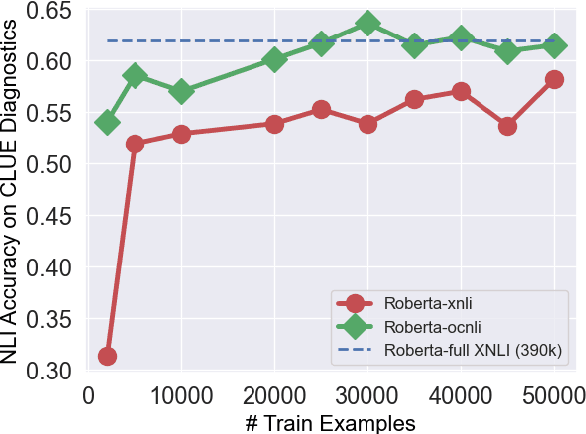
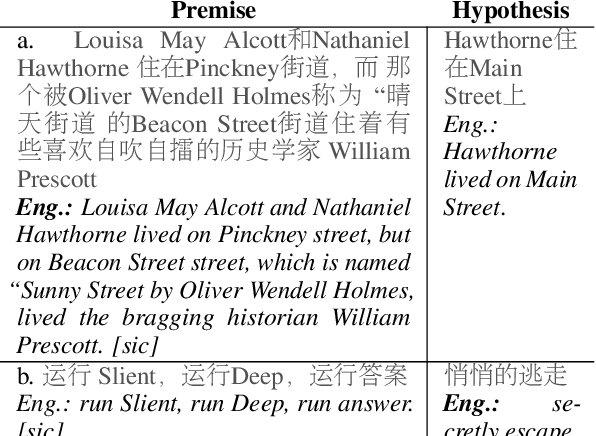
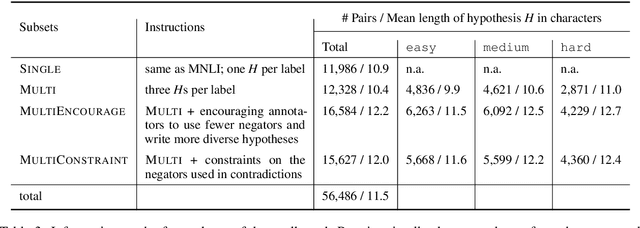
Despite the tremendous recent progress on natural language inference (NLI), driven largely by large-scale investment in new datasets (e.g., SNLI, MNLI) and advances in modeling, most progress has been limited to English due to a lack of reliable datasets for most of the world's languages. In this paper, we present the first large-scale NLI dataset (consisting of ~56,000 annotated sentence pairs) for Chinese called the Original Chinese Natural Language Inference dataset (OCNLI). Unlike recent attempts at extending NLI to other languages, our dataset does not rely on any automatic translation or non-expert annotation. Instead, we elicit annotations from native speakers specializing in linguistics. We follow closely the annotation protocol used for MNLI, but create new strategies for eliciting diverse hypotheses. We establish several baseline results on our dataset using state-of-the-art pre-trained models for Chinese, and find even the best performing models to be far outpaced by human performance (~12% absolute performance gap), making it a challenging new resource that we hope will help to accelerate progress in Chinese NLU. To the best of our knowledge, this is the first human-elicited MNLI-style corpus for a non-English language.
MonaLog: a Lightweight System for Natural Language Inference Based on Monotonicity
Oct 19, 2019

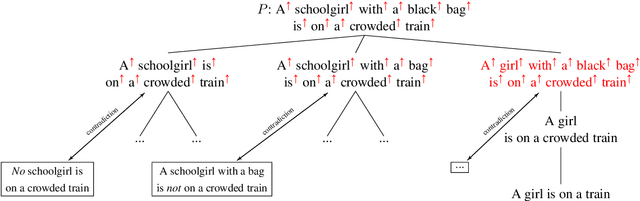
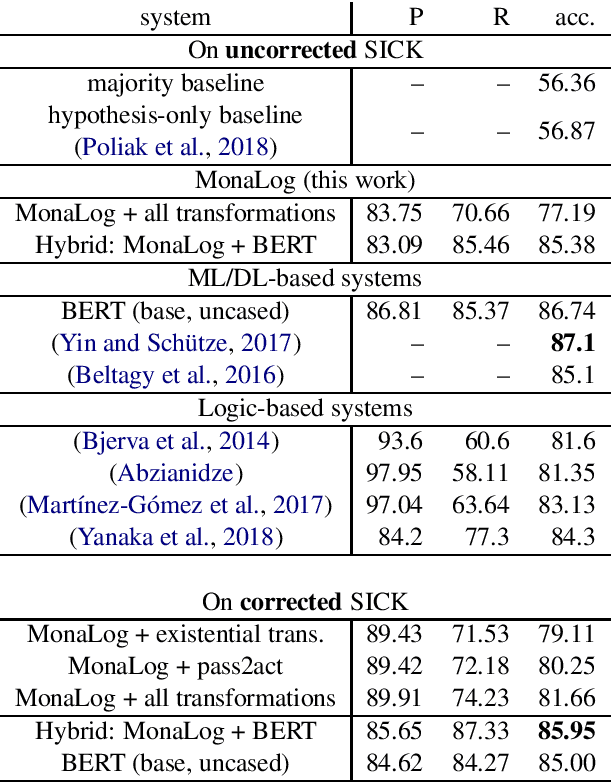
We present a new logic-based inference engine for natural language inference (NLI) called MonaLog, which is based on natural logic and the monotonicity calculus. In contrast to existing logic-based approaches, our system is intentionally designed to be as lightweight as possible, and operates using a small set of well-known (surface-level) monotonicity facts about quantifiers, lexical items and tokenlevel polarity information. Despite its simplicity, we find our approach to be competitive with other logic-based NLI models on the SICK benchmark. We also use MonaLog in combination with the current state-of-the-art model BERT in a variety of settings, including for compositional data augmentation. We show that MonaLog is capable of generating large amounts of high-quality training data for BERT, improving its accuracy on SICK.