 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePut Your Money Where Your Mouth Is: Evaluating Strategic Planning and Execution of LLM Agents in an Auction Arena
Oct 09, 2023Can Large Language Models (LLMs) simulate human behavior in complex environments? LLMs have recently been shown to exhibit advanced reasoning skills but much of NLP evaluation still relies on static benchmarks. Answering this requires evaluation environments that probe strategic reasoning in competitive, dynamic scenarios that involve long-term planning. We introduce AucArena, a novel simulation environment for evaluating LLMs within auctions, a setting chosen for being highly unpredictable and involving many skills related to resource and risk management, while also being easy to evaluate. We conduct several controlled simulations using state-of-the-art LLMs as bidding agents. We find that through simple prompting, LLMs do indeed demonstrate many of the skills needed for effectively engaging in auctions (e.g., managing budget, adhering to long-term goals and priorities), skills that we find can be sharpened by explicitly encouraging models to be adaptive and observe strategies in past auctions. These results are significant as they show the potential of using LLM agents to model intricate social dynamics, especially in competitive settings. However, we also observe considerable variability in the capabilities of individual LLMs. Notably, even our most advanced models (GPT-4) are occasionally surpassed by heuristic baselines and human agents, highlighting the potential for further improvements in the design of LLM agents and the important role that our simulation environment can play in further testing and refining agent architectures.
Language Models with Rationality
May 23, 2023



While large language models (LLMs) are proficient at question-answering (QA), the dependencies between their answers and other "beliefs" they may have about the world are typically unstated, and may even be in conflict. Our goal is to uncover such dependencies and reduce inconsistencies among them, so that answers are supported by faithful, system-believed chains of reasoning drawn from a consistent network of beliefs. Our approach, which we call REFLEX, is to add a "rational", self-reflecting layer on top of the LLM. First, given a question, we construct a belief graph using a backward-chaining process to materialize relevant model "beliefs" (including beliefs about answer candidates) and the inferential relationships between them. Second, we identify and minimize contradictions in that graph using a formal constraint reasoner. We find that REFLEX significantly improves consistency (by 8%-11% absolute) without harming overall answer accuracy, resulting in answers supported by faithful chains of reasoning drawn from a more consistent belief system. This suggests a new style of system architecture, in which an LLM extended with a rational layer of self-reflection can repair latent inconsistencies within the LLM alone.
DISCO: Distilling Phrasal Counterfactuals with Large Language Models
Dec 20, 2022



Recent methods demonstrate that data augmentation using counterfactual knowledge can teach models the causal structure of a task, leading to robust and generalizable models. However, such counterfactual data often has a limited scale and diversity if crowdsourced and is computationally expensive to extend to new perturbation types if generated using supervised methods. To address this, we introduce a new framework called DISCO for automatically generating high-quality counterfactual data at scale. DISCO engineers prompts to generate phrasal perturbations with a large general language model. Then, a task-specific teacher model filters the generation to distill high-quality counterfactual data. We show that learning with this counterfactual data yields a comparatively small student model that is 6% (absolute) more robust and generalizes 5% better across distributions than baselines on various challenging evaluations. This model is also 15% more sensitive in differentiating original and counterfactual examples, on three evaluation sets written by human workers and via human-AI collaboration.
Breakpoint Transformers for Modeling and Tracking Intermediate Beliefs
Nov 15, 2022



Can we teach natural language understanding models to track their beliefs through intermediate points in text? We propose a representation learning framework called breakpoint modeling that allows for learning of this type. Given any text encoder and data marked with intermediate states (breakpoints) along with corresponding textual queries viewed as true/false propositions (i.e., the candidate beliefs of a model, consisting of information changing through time) our approach trains models in an efficient and end-to-end fashion to build intermediate representations that facilitate teaching and direct querying of beliefs at arbitrary points alongside solving other end tasks. To show the benefit of our approach, we experiment with a diverse set of NLU tasks including relational reasoning on CLUTRR and narrative understanding on bAbI. Using novel belief prediction tasks for both tasks, we show the benefit of our main breakpoint transformer, based on T5, over conventional representation learning approaches in terms of processing efficiency, prediction accuracy and prediction consistency, all with minimal to no effect on corresponding QA end tasks. To show the feasibility of incorporating our belief tracker into more complex reasoning pipelines, we also obtain SOTA performance on the three-tiered reasoning challenge for the TRIP benchmark (around 23-32% absolute improvement on Tasks 2-3).
Learning to Decompose: Hypothetical Question Decomposition Based on Comparable Texts
Oct 30, 2022Explicit decomposition modeling, which involves breaking down complex tasks into more straightforward and often more interpretable sub-tasks, has long been a central theme in developing robust and interpretable NLU systems. However, despite the many datasets and resources built as part of this effort, the majority have small-scale annotations and limited scope, which is insufficient to solve general decomposition tasks. In this paper, we look at large-scale intermediate pre-training of decomposition-based transformers using distant supervision from comparable texts, particularly large-scale parallel news. We show that with such intermediate pre-training, developing robust decomposition-based models for a diverse range of tasks becomes more feasible. For example, on semantic parsing, our model, DecompT5, improves 20% to 30% on two datasets, Overnight and TORQUE, over the baseline language model. We further use DecompT5 to build a novel decomposition-based QA system named DecompEntail, improving over state-of-the-art models, including GPT-3, on both HotpotQA and StrategyQA by 8% and 4%, respectively.
Decomposed Prompting: A Modular Approach for Solving Complex Tasks
Oct 05, 2022

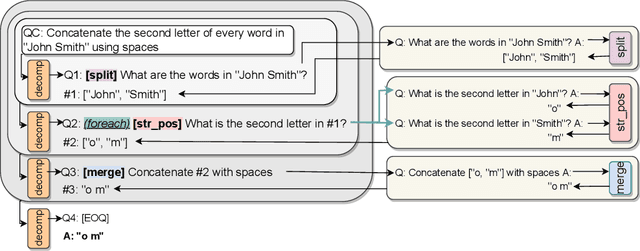

Few-shot prompting is a surprisingly powerful way to use Large Language Models (LLMs) to solve various tasks. However, this approach struggles as the task complexity increases or when the individual reasoning steps of the task themselves are hard to learn, especially when embedded in more complex tasks. To address this, we propose Decomposed Prompting, a new approach to solve complex tasks by decomposing them (via prompting) into simpler sub-tasks that can be delegated to a library of prompting-based LLMs dedicated to these sub-tasks. This modular structure allows each prompt to be optimized for its specific sub-task, further decomposed if necessary, and even easily replaced with more effective prompts, trained models, or symbolic functions if desired. We show that the flexibility and modularity of Decomposed Prompting allows it to outperform prior work on few-shot prompting using GPT3. On symbolic reasoning tasks, we can further decompose sub-tasks that are hard for LLMs into even simpler solvable sub-tasks. When the complexity comes from the input length, we can recursively decompose the task into the same task but with smaller inputs. We also evaluate our approach on textual multi-step reasoning tasks: on long-context multi-hop QA task, we can more effectively teach the sub-tasks via our separate sub-tasks prompts; and on open-domain multi-hop QA, we can incorporate a symbolic information retrieval within our decomposition framework, leading to improved performance on both tasks.
Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models
Jun 10, 2022Language models demonstrate both quantitative improvement and new qualitative capabilities with increasing scale. Despite their potentially transformative impact, these new capabilities are as yet poorly characterized. In order to inform future research, prepare for disruptive new model capabilities, and ameliorate socially harmful effects, it is vital that we understand the present and near-future capabilities and limitations of language models. To address this challenge, we introduce the Beyond the Imitation Game benchmark (BIG-bench). BIG-bench currently consists of 204 tasks, contributed by 442 authors across 132 institutions. Task topics are diverse, drawing problems from linguistics, childhood development, math, common-sense reasoning, biology, physics, social bias, software development, and beyond. BIG-bench focuses on tasks that are believed to be beyond the capabilities of current language models. We evaluate the behavior of OpenAI's GPT models, Google-internal dense transformer architectures, and Switch-style sparse transformers on BIG-bench, across model sizes spanning millions to hundreds of billions of parameters. In addition, a team of human expert raters performed all tasks in order to provide a strong baseline. Findings include: model performance and calibration both improve with scale, but are poor in absolute terms (and when compared with rater performance); performance is remarkably similar across model classes, though with benefits from sparsity; tasks that improve gradually and predictably commonly involve a large knowledge or memorization component, whereas tasks that exhibit "breakthrough" behavior at a critical scale often involve multiple steps or components, or brittle metrics; social bias typically increases with scale in settings with ambiguous context, but this can be improved with prompting.
What Makes Instruction Learning Hard? An Investigation and a New Challenge in a Synthetic Environment
Apr 19, 2022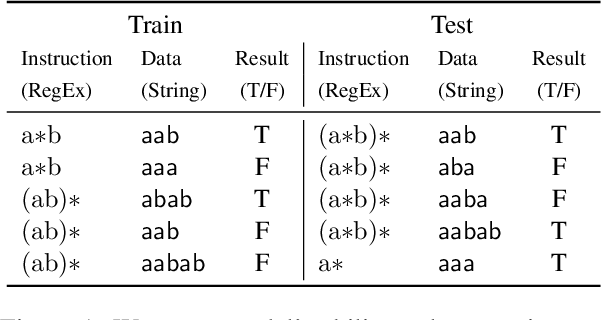
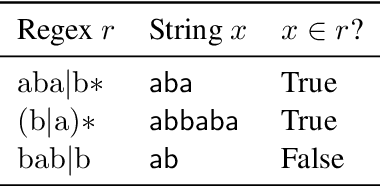
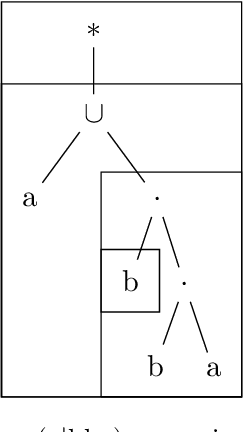
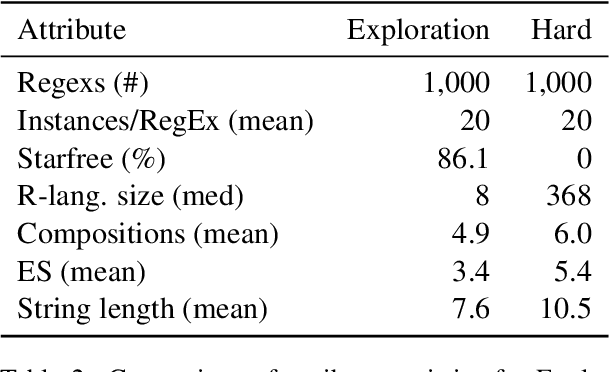
The instruction learning paradigm -- where a model learns to perform new tasks from task descriptions alone -- has become popular in general-purpose model research. The capabilities of large transformer models as instruction learners, however, remain poorly understood. We use a controlled synthetic environment to characterize such capabilities. Specifically, we use the task of deciding whether a given string matches a regular expression (viewed as an instruction) to identify properties of tasks, instructions, and instances that make instruction learning challenging. For instance, we find that our model, a fine-tuned T5-based text2text transformer, struggles with large regular languages, suggesting that less precise instructions are challenging for models. Additionally, instruction executions that require tracking longer contexts of prior steps are also more difficult. We use our findings to systematically construct a challenging instruction learning dataset, which we call Hard RegSet. Fine-tuning on Hard RegSet, our large transformer learns to correctly interpret only 65.6% of test instructions (with at least 90% accuracy), and 11%-24% of the instructions in out-of-distribution generalization settings. We propose Hard RegSet as a challenging instruction learning task, and a controlled environment for studying instruction learning.
Pushing the Limits of Rule Reasoning in Transformers through Natural Language Satisfiability
Dec 16, 2021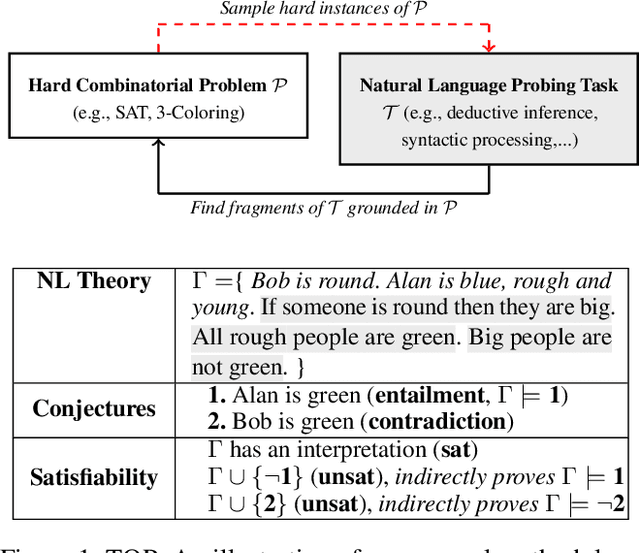

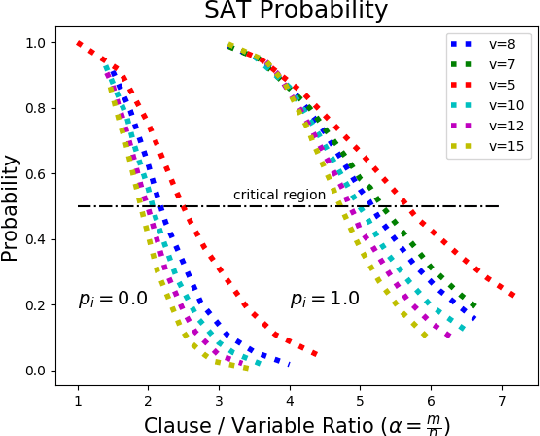
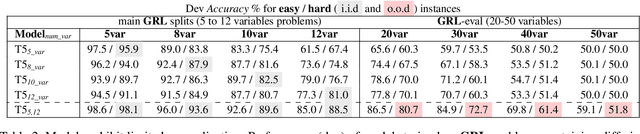
Investigating the reasoning abilities of transformer models, and discovering new challenging tasks for them, has been a topic of much interest. Recent studies have found these models to be surprisingly strong at performing deductive reasoning over formal logical theories expressed in natural language. A shortcoming of these studies, however, is that they do not take into account that logical theories, when sampled uniformly at random, do not necessarily lead to hard instances. We propose a new methodology for creating challenging algorithmic reasoning datasets that focus on natural language satisfiability (NLSat) problems. The key idea is to draw insights from empirical sampling of hard propositional SAT problems and from complexity-theoretic studies of language. This methodology allows us to distinguish easy from hard instances, and to systematically increase the complexity of existing reasoning benchmarks such as RuleTaker. We find that current transformers, given sufficient training data, are surprisingly robust at solving the resulting NLSat problems of substantially increased difficulty. They also exhibit some degree of scale-invariance - the ability to generalize to problems of larger size and scope. Our results, however, reveal important limitations too: a careful sampling of training data is crucial for building models that generalize to larger problems, and transformer models' limited scale-invariance suggests they are far from learning robust deductive reasoning algorithms.
PROMPT WAYWARDNESS: The Curious Case of Discretized Interpretation of Continuous Prompts
Dec 15, 2021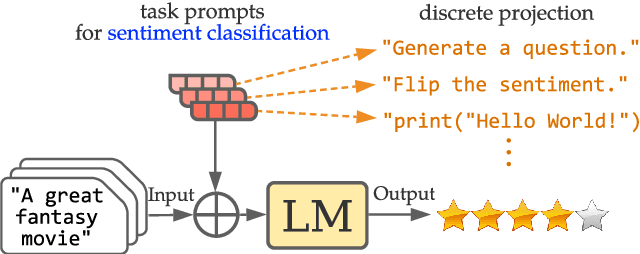
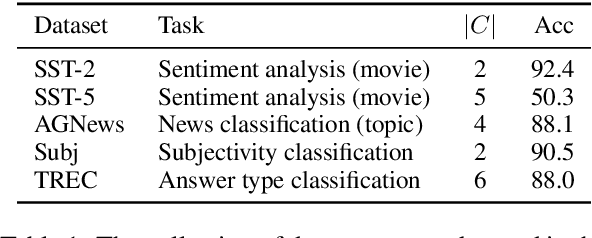
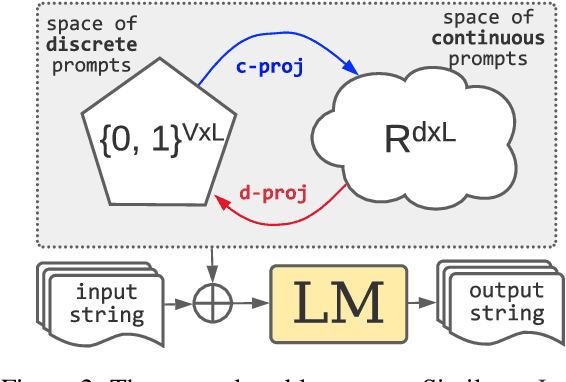
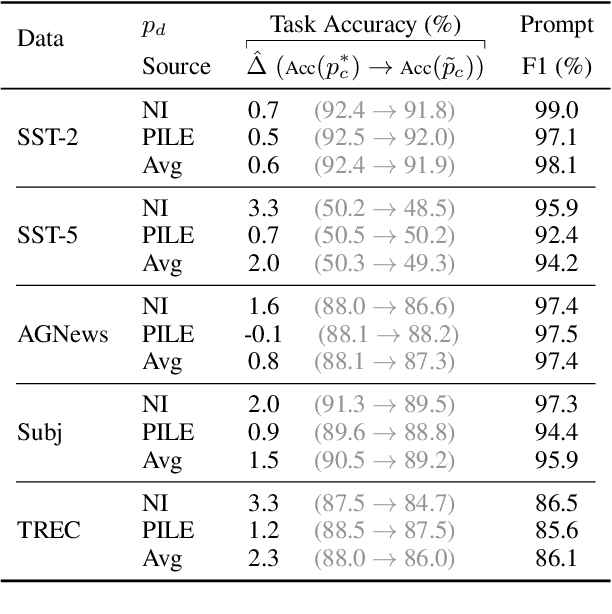
Fine-tuning continuous prompts for target tasks has recently emerged as a compact alternative to full model fine-tuning. Motivated by these promising results, we investigate the feasibility of extracting a discrete (textual) interpretation of continuous prompts that is faithful to the problem they solve. In practice, we observe a "wayward" behavior between the task solved by continuous prompts and their nearest neighbor discrete projections: We can find continuous prompts that solve a task while being projected to an arbitrary text (e.g., definition of a different or even a contradictory task), while being within a very small (2%) margin of the best continuous prompt of the same size for the task. We provide intuitions behind this odd and surprising behavior, as well as extensive empirical analyses quantifying the effect of various parameters. For instance, for larger model sizes we observe higher waywardness, i.e, we can find prompts that more closely map to any arbitrary text with a smaller drop in accuracy. These findings have important implications relating to the difficulty of faithfully interpreting continuous prompts and their generalization across models and tasks, providing guidance for future progress in prompting language models.