 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-MAE: A Scale-Aware Masked Autoencoder for Multiscale Geospatial Representation Learning
Jan 02, 2023



Remote sensing imagery provides comprehensive views of the Earth, where different sensors collect complementary data at different spatial scales. Large, pretrained models are commonly finetuned with imagery that is heavily augmented to mimic different conditions and scales, with the resulting models used for various tasks with imagery from a range of spatial scales. Such models overlook scale-specific information in the data. In this paper, we present Scale-MAE, a pretraining method that explicitly learns relationships between data at different, known scales throughout the pretraining process. Scale-MAE pretrains a network by masking an input image at a known input scale, where the area of the Earth covered by the image determines the scale of the ViT positional encoding, not the image resolution. Scale-MAE encodes the masked image with a standard ViT backbone, and then decodes the masked image through a bandpass filter to reconstruct low/high frequency images at lower/higher scales. We find that tasking the network with reconstructing both low/high frequency images leads to robust multiscale representations for remote sensing imagery. Scale-MAE achieves an average of a $5.0\%$ non-parametric kNN classification improvement across eight remote sensing datasets compared to current state-of-the-art and obtains a $0.9$ mIoU to $3.8$ mIoU improvement on the SpaceNet building segmentation transfer task for a range of evaluation scales.
CSQ: Growing Mixed-Precision Quantization Scheme with Bi-level Continuous Sparsification
Dec 06, 2022Mixed-precision quantization has been widely applied on deep neural networks (DNNs) as it leads to significantly better efficiency-accuracy tradeoffs compared to uniform quantization. Meanwhile, determining the exact precision of each layer remains challenging. Previous attempts on bit-level regularization and pruning-based dynamic precision adjustment during training suffer from noisy gradients and unstable convergence. In this work, we propose Continuous Sparsification Quantization (CSQ), a bit-level training method to search for mixed-precision quantization schemes with improved stability. CSQ stabilizes the bit-level mixed-precision training process with a bi-level gradual continuous sparsification on both the bit values of the quantized weights and the bit selection in determining the quantization precision of each layer. The continuous sparsification scheme enables fully-differentiable training without gradient approximation while achieving an exact quantized model in the end.A budget-aware regularization of total model size enables the dynamic growth and pruning of each layer's precision towards a mixed-precision quantization scheme of the desired size. Extensive experiments show CSQ achieves better efficiency-accuracy tradeoff than previous methods on multiple models and datasets.
Multitask Vision-Language Prompt Tuning
Dec 05, 2022



Prompt Tuning, conditioning on task-specific learned prompt vectors, has emerged as a data-efficient and parameter-efficient method for adapting large pretrained vision-language models to multiple downstream tasks. However, existing approaches usually consider learning prompt vectors for each task independently from scratch, thereby failing to exploit the rich shareable knowledge across different vision-language tasks. In this paper, we propose multitask vision-language prompt tuning (MVLPT), which incorporates cross-task knowledge into prompt tuning for vision-language models. Specifically, (i) we demonstrate the effectiveness of learning a single transferable prompt from multiple source tasks to initialize the prompt for each target task; (ii) we show many target tasks can benefit each other from sharing prompt vectors and thus can be jointly learned via multitask prompt tuning. We benchmark the proposed MVLPT using three representative prompt tuning methods, namely text prompt tuning, visual prompt tuning, and the unified vision-language prompt tuning. Results in 20 vision tasks demonstrate that the proposed approach outperforms all single-task baseline prompt tuning methods, setting the new state-of-the-art on the few-shot ELEVATER benchmarks and cross-task generalization benchmarks. To understand where the cross-task knowledge is most effective, we also conduct a large-scale study on task transferability with 20 vision tasks in 400 combinations for each prompt tuning method. It shows that the most performant MVLPT for each prompt tuning method prefers different task combinations and many tasks can benefit each other, depending on their visual similarity and label similarity. Code is available at https://github.com/sIncerass/MVLPT.
NoisyQuant: Noisy Bias-Enhanced Post-Training Activation Quantization for Vision Transformers
Nov 29, 2022The complicated architecture and high training cost of vision transformers urge the exploration of post-training quantization. However, the heavy-tailed distribution of vision transformer activations hinders the effectiveness of previous post-training quantization methods, even with advanced quantizer designs. Instead of tuning the quantizer to better fit the complicated activation distribution, this paper proposes NoisyQuant, a quantizer-agnostic enhancement for the post-training activation quantization performance of vision transformers. We make a surprising theoretical discovery that for a given quantizer, adding a fixed Uniform noisy bias to the values being quantized can significantly reduce the quantization error under provable conditions. Building on the theoretical insight, NoisyQuant achieves the first success on actively altering the heavy-tailed activation distribution with additive noisy bias to fit a given quantizer. Extensive experiments show NoisyQuant largely improves the post-training quantization performance of vision transformer with minimal computation overhead. For instance, on linear uniform 6-bit activation quantization, NoisyQuant improves SOTA top-1 accuracy on ImageNet by up to 1.7%, 1.1% and 0.5% for ViT, DeiT, and Swin Transformer respectively, achieving on-par or even higher performance than previous nonlinear, mixed-precision quantization.
Time Will Tell: New Outlooks and A Baseline for Temporal Multi-View 3D Object Detection
Oct 05, 2022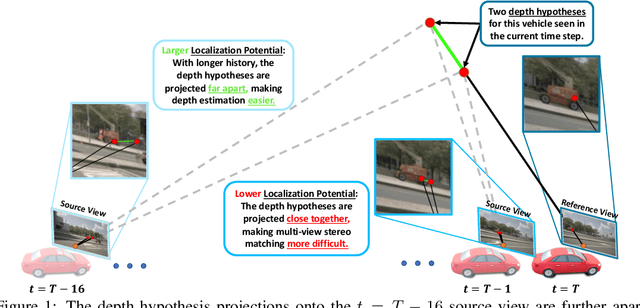
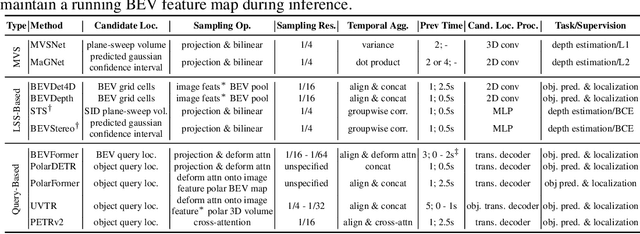
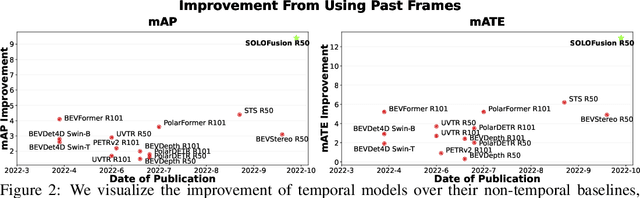
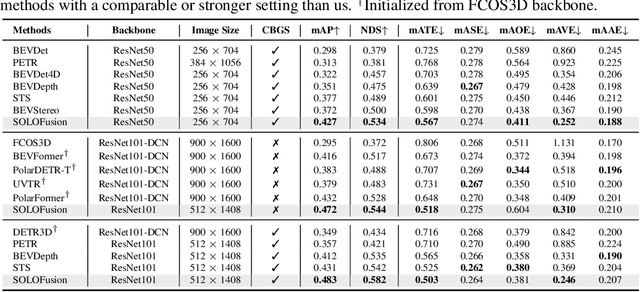
While recent camera-only 3D detection methods leverage multiple timesteps, the limited history they use significantly hampers the extent to which temporal fusion can improve object perception. Observing that existing works' fusion of multi-frame images are instances of temporal stereo matching, we find that performance is hindered by the interplay between 1) the low granularity of matching resolution and 2) the sub-optimal multi-view setup produced by limited history usage. Our theoretical and empirical analysis demonstrates that the optimal temporal difference between views varies significantly for different pixels and depths, making it necessary to fuse many timesteps over long-term history. Building on our investigation, we propose to generate a cost volume from a long history of image observations, compensating for the coarse but efficient matching resolution with a more optimal multi-view matching setup. Further, we augment the per-frame monocular depth predictions used for long-term, coarse matching with short-term, fine-grained matching and find that long and short term temporal fusion are highly complementary. While maintaining high efficiency, our framework sets new state-of-the-art on nuScenes, achieving first place on the test set and outperforming previous best art by 5.2% mAP and 3.7% NDS on the validation set. Code will be released $\href{https://github.com/Divadi/SOLOFusion}{here.}$
Analysis of Quantization on MLP-based Vision Models
Sep 14, 2022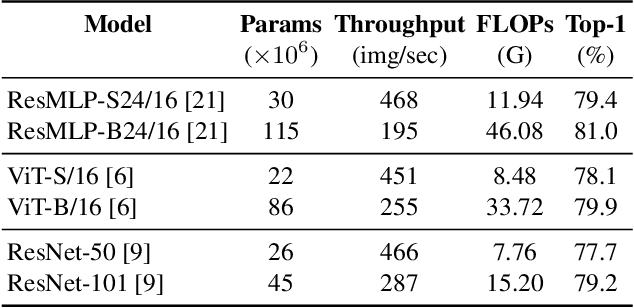

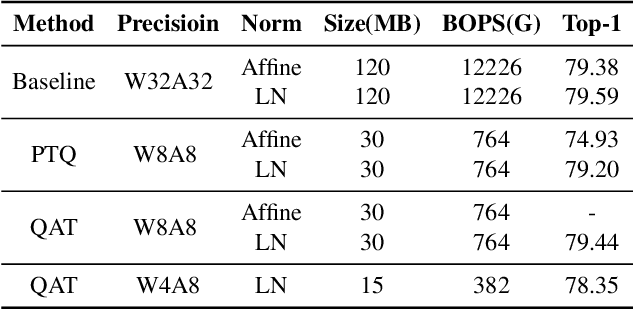
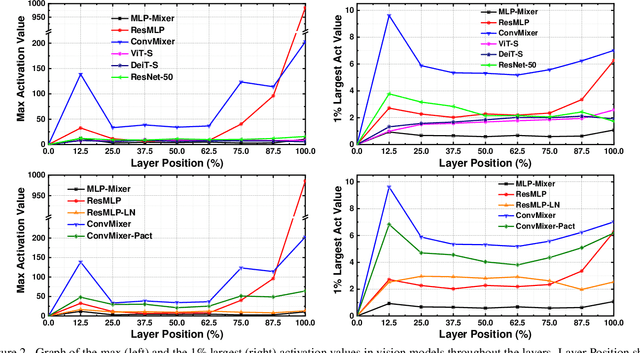
Quantization is wildly taken as a model compression technique, which obtains efficient models by converting floating-point weights and activations in the neural network into lower-bit integers. Quantization has been proven to work well on convolutional neural networks and transformer-based models. Despite the decency of these models, recent works have shown that MLP-based models are able to achieve comparable results on various tasks ranging from computer vision, NLP to 3D point cloud, while achieving higher throughput due to the parallelism and network simplicity. However, as we show in the paper, directly applying quantization to MLP-based models will lead to significant accuracy degradation. Based on our analysis, two major issues account for the accuracy gap: 1) the range of activations in MLP-based models can be too large to quantize, and 2) specific components in the MLP-based models are sensitive to quantization. Consequently, we propose to 1) apply LayerNorm to control the quantization range of activations, 2) utilize bounded activation functions, 3) apply percentile quantization on activations, 4) use our improved module named multiple token-mixing MLPs, and 5) apply linear asymmetric quantizer for sensitive operations. Equipped with the abovementioned techniques, our Q-MLP models can achieve 79.68% accuracy on ImageNet with 8-bit uniform quantization (model size 30 MB) and 78.47% with 4-bit quantization (15 MB).
Prior Knowledge-Guided Attention in Self-Supervised Vision Transformers
Sep 07, 2022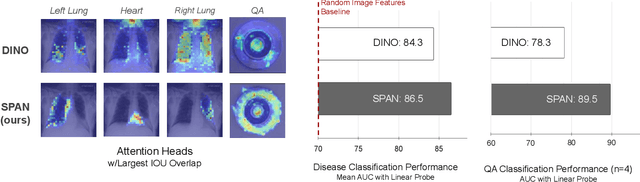
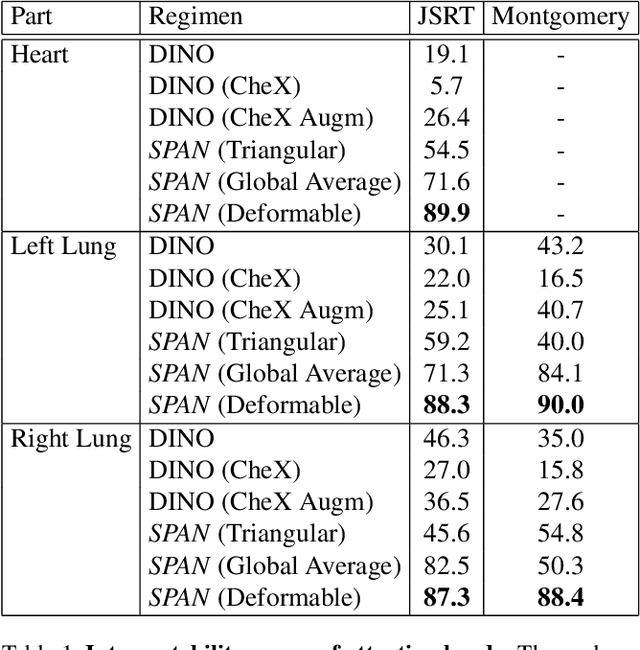
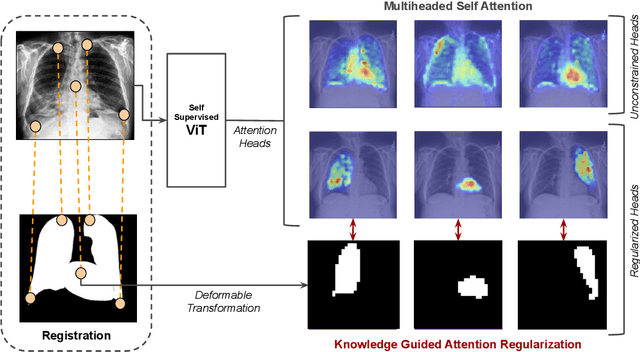

Recent trends in self-supervised representation learning have focused on removing inductive biases from training pipelines. However, inductive biases can be useful in settings when limited data are available or provide additional insight into the underlying data distribution. We present spatial prior attention (SPAN), a framework that takes advantage of consistent spatial and semantic structure in unlabeled image datasets to guide Vision Transformer attention. SPAN operates by regularizing attention masks from separate transformer heads to follow various priors over semantic regions. These priors can be derived from data statistics or a single labeled sample provided by a domain expert. We study SPAN through several detailed real-world scenarios, including medical image analysis and visual quality assurance. We find that the resulting attention masks are more interpretable than those derived from domain-agnostic pretraining. SPAN produces a 58.7 mAP improvement for lung and heart segmentation. We also find that our method yields a 2.2 mAUC improvement compared to domain-agnostic pretraining when transferring the pretrained model to a downstream chest disease classification task. Lastly, we show that SPAN pretraining leads to higher downstream classification performance in low-data regimes compared to domain-agnostic pretraining.
Open-Vocabulary 3D Detection via Image-level Class and Debiased Cross-modal Contrastive Learning
Jul 05, 2022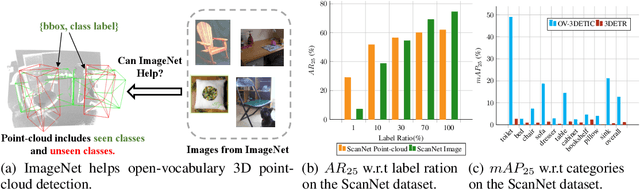
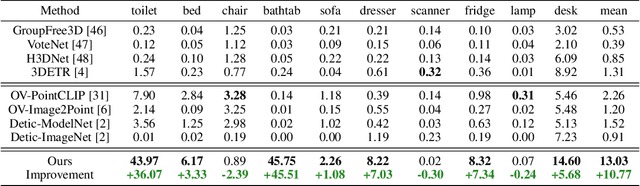
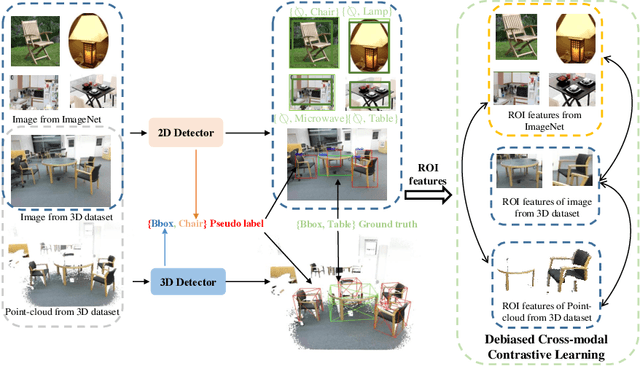
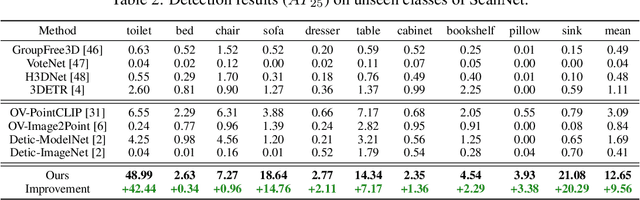
Current point-cloud detection methods have difficulty detecting the open-vocabulary objects in the real world, due to their limited generalization capability. Moreover, it is extremely laborious and expensive to collect and fully annotate a point-cloud detection dataset with numerous classes of objects, leading to the limited classes of existing point-cloud datasets and hindering the model to learn general representations to achieve open-vocabulary point-cloud detection. As far as we know, we are the first to study the problem of open-vocabulary 3D point-cloud detection. Instead of seeking a point-cloud dataset with full labels, we resort to ImageNet1K to broaden the vocabulary of the point-cloud detector. We propose OV-3DETIC, an Open-Vocabulary 3D DETector using Image-level Class supervision. Specifically, we take advantage of two modalities, the image modality for recognition and the point-cloud modality for localization, to generate pseudo labels for unseen classes. Then we propose a novel debiased cross-modal contrastive learning method to transfer the knowledge from image modality to point-cloud modality during training. Without hurting the latency during inference, OV-3DETIC makes the point-cloud detector capable of achieving open-vocabulary detection. Extensive experiments demonstrate that the proposed OV-3DETIC achieves at least 10.77 % mAP improvement (absolute value) and 9.56 % mAP improvement (absolute value) by a wide range of baselines on the SUN-RGBD dataset and ScanNet dataset, respectively. Besides, we conduct sufficient experiments to shed light on why the proposed OV-3DETIC works.
The ArtBench Dataset: Benchmarking Generative Models with Artworks
Jun 22, 2022
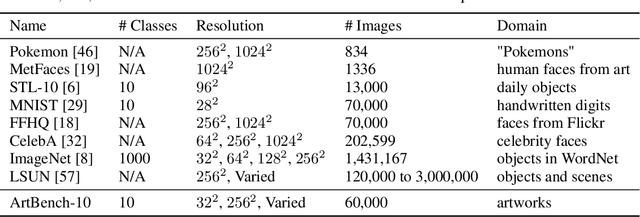
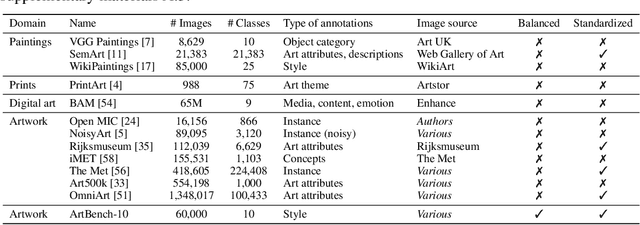
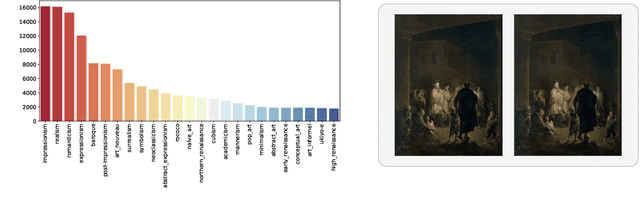
We introduce ArtBench-10, the first class-balanced, high-quality, cleanly annotated, and standardized dataset for benchmarking artwork generation. It comprises 60,000 images of artwork from 10 distinctive artistic styles, with 5,000 training images and 1,000 testing images per style. ArtBench-10 has several advantages over previous artwork datasets. Firstly, it is class-balanced while most previous artwork datasets suffer from the long tail class distributions. Secondly, the images are of high quality with clean annotations. Thirdly, ArtBench-10 is created with standardized data collection, annotation, filtering, and preprocessing procedures. We provide three versions of the dataset with different resolutions ($32\times32$, $256\times256$, and original image size), formatted in a way that is easy to be incorporated by popular machine learning frameworks. We also conduct extensive benchmarking experiments using representative image synthesis models with ArtBench-10 and present in-depth analysis. The dataset is available at https://github.com/liaopeiyuan/artbench under a Fair Use license.
Domain-Adaptive Text Classification with Structured Knowledge from Unlabeled Data
Jun 20, 2022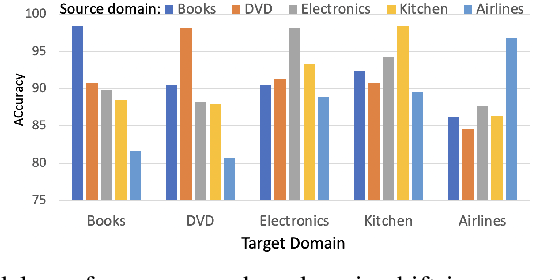
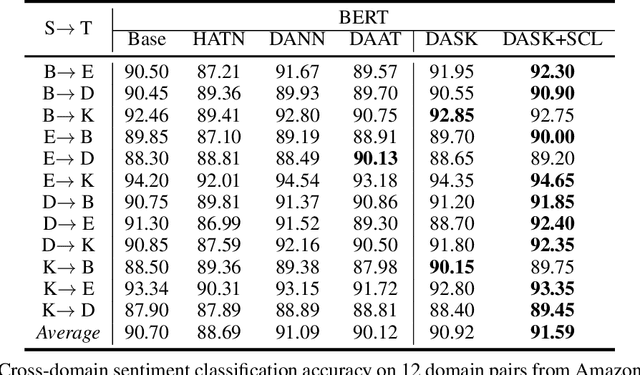
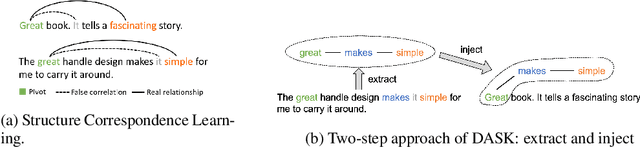
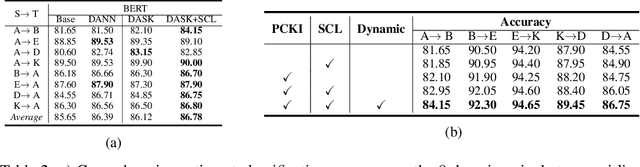
Domain adaptive text classification is a challenging problem for the large-scale pretrained language models because they often require expensive additional labeled data to adapt to new domains. Existing works usually fails to leverage the implicit relationships among words across domains. In this paper, we propose a novel method, called Domain Adaptation with Structured Knowledge (DASK), to enhance domain adaptation by exploiting word-level semantic relationships. DASK first builds a knowledge graph to capture the relationship between pivot terms (domain-independent words) and non-pivot terms in the target domain. Then during training, DASK injects pivot-related knowledge graph information into source domain texts. For the downstream task, these knowledge-injected texts are fed into a BERT variant capable of processing knowledge-injected textual data. Thanks to the knowledge injection, our model learns domain-invariant features for non-pivots according to their relationships with pivots. DASK ensures the pivots to have domain-invariant behaviors by dynamically inferring via the polarity scores of candidate pivots during training with pseudo-labels. We validate DASK on a wide range of cross-domain sentiment classification tasks and observe up to 2.9% absolute performance improvement over baselines for 20 different domain pairs. Code will be made available at https://github.com/hikaru-nara/DASK.