 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Local Stackelberg Equilibria from Repeated Interactions with a Learning Agent
Oct 26, 2025Motivated by the question of how a principal can maximize its utility in repeated interactions with a learning agent, we study repeated games between an principal and an agent employing a mean-based learning algorithm. Prior work has shown that computing or even approximating the global Stackelberg value in similar settings can require an exponential number of rounds in the size of the agent's action space, making it computationally intractable. In contrast, we shift focus to the computation of local Stackelberg equilibria and introduce an algorithm that, within the smoothed analysis framework, constitutes a Polynomial Time Approximation Scheme (PTAS) for finding an epsilon-approximate local Stackelberg equilibrium. Notably, the algorithm's runtime is polynomial in the size of the agent's action space yet exponential in (1/epsilon) - a dependency we prove to be unavoidable.
Distortion of AI Alignment: Does Preference Optimization Optimize for Preferences?
May 29, 2025



After pre-training, large language models are aligned with human preferences based on pairwise comparisons. State-of-the-art alignment methods (such as PPO-based RLHF and DPO) are built on the assumption of aligning with a single preference model, despite being deployed in settings where users have diverse preferences. As a result, it is not even clear that these alignment methods produce models that satisfy users on average -- a minimal requirement for pluralistic alignment. Drawing on social choice theory and modeling users' comparisons through individual Bradley-Terry (BT) models, we introduce an alignment method's distortion: the worst-case ratio between the optimal achievable average utility, and the average utility of the learned policy. The notion of distortion helps draw sharp distinctions between alignment methods: Nash Learning from Human Feedback achieves the minimax optimal distortion of $(\frac{1}{2} + o(1)) \cdot \beta$ (for the BT temperature $\beta$), robustly across utility distributions, distributions of comparison pairs, and permissible KL divergences from the reference policy. RLHF and DPO, by contrast, suffer $\geq (1 - o(1)) \cdot \beta$ distortion already without a KL constraint, and $e^{\Omega(\beta)}$ or even unbounded distortion in the full setting, depending on how comparison pairs are sampled.
Is Knowledge Power? On the (Im)possibility of Learning from Strategic Interaction
Aug 15, 2024


When learning in strategic environments, a key question is whether agents can overcome uncertainty about their preferences to achieve outcomes they could have achieved absent any uncertainty. Can they do this solely through interactions with each other? We focus this question on the ability of agents to attain the value of their Stackelberg optimal strategy and study the impact of information asymmetry. We study repeated interactions in fully strategic environments where players' actions are decided based on learning algorithms that take into account their observed histories and knowledge of the game. We study the pure Nash equilibria (PNE) of a meta-game where players choose these algorithms as their actions. We demonstrate that if one player has perfect knowledge about the game, then any initial informational gap persists. That is, while there is always a PNE in which the informed agent achieves her Stackelberg value, there is a game where no PNE of the meta-game allows the partially informed player to achieve her Stackelberg value. On the other hand, if both players start with some uncertainty about the game, the quality of information alone does not determine which agent can achieve her Stackelberg value. In this case, the concept of information asymmetry becomes nuanced and depends on the game's structure. Overall, our findings suggest that repeated strategic interactions alone cannot facilitate learning effectively enough to earn an uninformed player her Stackelberg value.
Truthfulness of Calibration Measures
Jul 19, 2024

We initiate the study of the truthfulness of calibration measures in sequential prediction. A calibration measure is said to be truthful if the forecaster (approximately) minimizes the expected penalty by predicting the conditional expectation of the next outcome, given the prior distribution of outcomes. Truthfulness is an important property of calibration measures, ensuring that the forecaster is not incentivized to exploit the system with deliberate poor forecasts. This makes it an essential desideratum for calibration measures, alongside typical requirements, such as soundness and completeness. We conduct a taxonomy of existing calibration measures and their truthfulness. Perhaps surprisingly, we find that all of them are far from being truthful. That is, under existing calibration measures, there are simple distributions on which a polylogarithmic (or even zero) penalty is achievable, while truthful prediction leads to a polynomial penalty. Our main contribution is the introduction of a new calibration measure termed the Subsampled Smooth Calibration Error (SSCE) under which truthful prediction is optimal up to a constant multiplicative factor.
Strategic Littlestone Dimension: Improved Bounds on Online Strategic Classification
Jul 16, 2024
We study the problem of online binary classification in settings where strategic agents can modify their observable features to receive a positive classification. We model the set of feasible manipulations by a directed graph over the feature space, and assume the learner only observes the manipulated features instead of the original ones. We introduce the Strategic Littlestone Dimension, a new combinatorial measure that captures the joint complexity of the hypothesis class and the manipulation graph. We demonstrate that it characterizes the instance-optimal mistake bounds for deterministic learning algorithms in the realizable setting. We also achieve improved regret in the agnostic setting by a refined agnostic-to-realizable reduction that accounts for the additional challenge of not observing agents' original features. Finally, we relax the assumption that the learner knows the manipulation graph, instead assuming their knowledge is captured by a family of graphs. We derive regret bounds in both the realizable setting where all agents manipulate according to the same graph within the graph family, and the agnostic setting where the manipulation graphs are chosen adversarially and not consistently modeled by a single graph in the family.
Calibrated Stackelberg Games: Learning Optimal Commitments Against Calibrated Agents
Jun 05, 2023
In this paper, we introduce a generalization of the standard Stackelberg Games (SGs) framework: Calibrated Stackelberg Games (CSGs). In CSGs, a principal repeatedly interacts with an agent who (contrary to standard SGs) does not have direct access to the principal's action but instead best-responds to calibrated forecasts about it. CSG is a powerful modeling tool that goes beyond assuming that agents use ad hoc and highly specified algorithms for interacting in strategic settings and thus more robustly addresses real-life applications that SGs were originally intended to capture. Along with CSGs, we also introduce a stronger notion of calibration, termed adaptive calibration, that provides fine-grained any-time calibration guarantees against adversarial sequences. We give a general approach for obtaining adaptive calibration algorithms and specialize them for finite CSGs. In our main technical result, we show that in CSGs, the principal can achieve utility that converges to the optimum Stackelberg value of the game both in finite and continuous settings, and that no higher utility is achievable. Two prominent and immediate applications of our results are the settings of learning in Stackelberg Security Games and strategic classification, both against calibrated agents.
Fundamental Bounds on Online Strategic Classification
Feb 23, 2023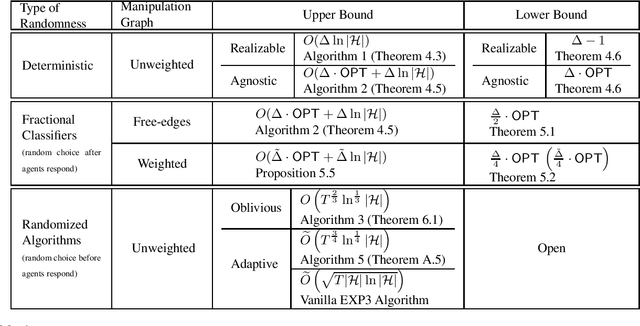
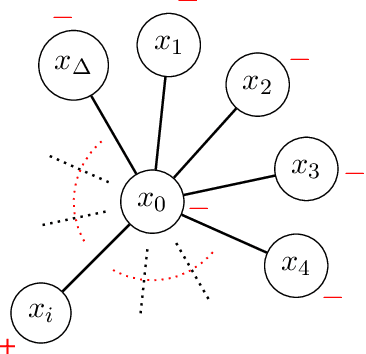
We study the problem of online binary classification where strategic agents can manipulate their observable features in predefined ways, modeled by a manipulation graph, in order to receive a positive classification. We show this setting differs in fundamental ways from non-strategic online classification. For instance, whereas in the non-strategic case, a mistake bound of $\ln|H|$ is achievable via the halving algorithm when the target function belongs to a known class $H$, we show that no deterministic algorithm can achieve a mistake bound $o(\Delta)$ in the strategic setting, where $\Delta$ is the maximum degree of the manipulation graph (even when $|H|=O(\Delta)$). We obtain an algorithm achieving mistake bound $O(\Delta\ln|H|)$. We also extend this to the agnostic setting and obtain an algorithm with a $\Delta$ multiplicative regret, and we show no deterministic algorithm can achieve $o(\Delta)$ multiplicative regret. Next, we study two randomized models based on whether the random choices are made before or after agents respond, and show they exhibit fundamental differences. In the first model, at each round the learner deterministically chooses a probability distribution over classifiers inducing expected values on each vertex (probabilities of being classified as positive), which the strategic agents respond to. We show that any learner in this model has to suffer linear regret. On the other hand, in the second model, while the adversary who selects the next agent must respond to the learner's probability distribution over classifiers, the agent then responds to the actual hypothesis classifier drawn from this distribution. Surprisingly, we show this model is more advantageous to the learner, and we design randomized algorithms that achieve sublinear regret bounds against both oblivious and adaptive adversaries.
Optimal Conservative Offline RL with General Function Approximation via Augmented Lagrangian
Nov 01, 2022Offline reinforcement learning (RL), which refers to decision-making from a previously-collected dataset of interactions, has received significant attention over the past years. Much effort has focused on improving offline RL practicality by addressing the prevalent issue of partial data coverage through various forms of conservative policy learning. While the majority of algorithms do not have finite-sample guarantees, several provable conservative offline RL algorithms are designed and analyzed within the single-policy concentrability framework that handles partial coverage. Yet, in the nonlinear function approximation setting where confidence intervals are difficult to obtain, existing provable algorithms suffer from computational intractability, prohibitively strong assumptions, and suboptimal statistical rates. In this paper, we leverage the marginalized importance sampling (MIS) formulation of RL and present the first set of offline RL algorithms that are statistically optimal and practical under general function approximation and single-policy concentrability, bypassing the need for uncertainty quantification. We identify that the key to successfully solving the sample-based approximation of the MIS problem is ensuring that certain occupancy validity constraints are nearly satisfied. We enforce these constraints by a novel application of the augmented Lagrangian method and prove the following result: with the MIS formulation, augmented Lagrangian is enough for statistically optimal offline RL. In stark contrast to prior algorithms that induce additional conservatism through methods such as behavior regularization, our approach provably eliminates this need and reinterprets regularizers as "enforcers of occupancy validity" than "promoters of conservatism."
Oracle-Efficient Online Learning for Beyond Worst-Case Adversaries
Mar 08, 2022In this paper, we study oracle-efficient algorithms for beyond worst-case analysis of online learning. We focus on two settings. First, the smoothed analysis setting of [RST11, HRS21] where an adversary is constrained to generating samples from distributions whose density is upper bounded by $1/\sigma$ times the uniform density. Second, the setting of $K$-hint transductive learning, where the learner is given access to $K$ hints per time step that are guaranteed to include the true instance. We give the first known oracle-efficient algorithms for both settings that depend only on the VC dimension of the class and parameters $\sigma$ and $K$ that capture the power of the adversary. {In particular, we achieve oracle-efficient regret bounds of $ O ( \sqrt{T d\sigma^{-1/2}} ) $} and $ O ( \sqrt{T d K } )$ respectively for these setting. For the smoothed analysis setting, our results give the first oracle-efficient algorithm for online learning with smoothed adversaries [HRS21]. This contrasts the computational separation between online learning with worst-case adversaries and offline learning established by [HK16]. Our algorithms also achieve improved bounds for worst-case setting with small domains. In particular, we give an oracle-efficient algorithm with regret of $O ( \sqrt{T(d \vert{\mathcal{X}})\vert^{1/2} })$, which is a refinement of the earlier $O ( \sqrt{T\vert{\mathcal{X}}\vert })$ bound by [DS16].
$Q$-learning with Logarithmic Regret
Jun 16, 2020This paper presents the first non-asymptotic result showing that a model-free algorithm can achieve a logarithmic cumulative regret for episodic tabular reinforcement learning if there exists a strictly positive sub-optimality gap in the optimal $Q$-function. We prove that the optimistic $Q$-learning studied in [Jin et al. 2018] enjoys a ${\mathcal{O}}\left(\frac{SA\cdot \mathrm{poly}\left(H\right)}{\mathrm{gap}_{\min}}\log\left(SAT\right)\right)$ cumulative regret bound, where $S$ is the number of states, $A$ is the number of actions, $H$ is the planning horizon, $T$ is the total number of steps, and $\mathrm{gap}_{\min}$ is the minimum sub-optimality gap. This bound matches the information theoretical lower bound in terms of $S,A,T$ up to a $\log\left(SA\right)$ factor. We further extend our analysis to the discounted setting and obtain a similar logarithmic cumulative regret bound.