 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFundamental Bounds on Online Strategic Classification
Paper and Code
Feb 23, 2023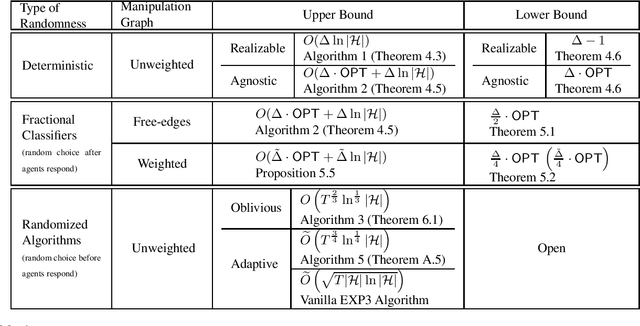
We study the problem of online binary classification where strategic agents can manipulate their observable features in predefined ways, modeled by a manipulation graph, in order to receive a positive classification. We show this setting differs in fundamental ways from non-strategic online classification. For instance, whereas in the non-strategic case, a mistake bound of $\ln|H|$ is achievable via the halving algorithm when the target function belongs to a known class $H$, we show that no deterministic algorithm can achieve a mistake bound $o(\Delta)$ in the strategic setting, where $\Delta$ is the maximum degree of the manipulation graph (even when $|H|=O(\Delta)$). We obtain an algorithm achieving mistake bound $O(\Delta\ln|H|)$. We also extend this to the agnostic setting and obtain an algorithm with a $\Delta$ multiplicative regret, and we show no deterministic algorithm can achieve $o(\Delta)$ multiplicative regret. Next, we study two randomized models based on whether the random choices are made before or after agents respond, and show they exhibit fundamental differences. In the first model, at each round the learner deterministically chooses a probability distribution over classifiers inducing expected values on each vertex (probabilities of being classified as positive), which the strategic agents respond to. We show that any learner in this model has to suffer linear regret. On the other hand, in the second model, while the adversary who selects the next agent must respond to the learner's probability distribution over classifiers, the agent then responds to the actual hypothesis classifier drawn from this distribution. Surprisingly, we show this model is more advantageous to the learner, and we design randomized algorithms that achieve sublinear regret bounds against both oblivious and adaptive adversaries.