 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJEDA: Query-Free Clinical Order Search from Ambient Dialogues
Oct 16, 2025Clinical conversations mix explicit directives (order a chest X-ray) with implicit reasoning (the cough worsened overnight, we should check for pneumonia). Many systems rely on LLM rewriting, adding latency, instability, and opacity that hinder real-time ordering. We present JEDA (Joint Embedding for Direct and Ambient clinical orders), a domain-initialized bi-encoder that retrieves canonical orders directly and, in a query-free mode, encodes a short rolling window of ambient dialogue to trigger retrieval. Initialized from PubMedBERT and fine-tuned with a duplicate-safe contrastive objective, JEDA aligns heterogeneous expressions of intent to shared order concepts. Training uses constrained LLM guidance to tie each signed order to complementary formulations (command only, context only, command+context, context+reasoning), producing clearer inter-order separation, tighter query extendash order coupling, and stronger generalization. The query-free mode is noise-resilient, reducing sensitivity to disfluencies and ASR errors by conditioning on a short window rather than a single utterance. Deployed in practice, JEDA yields large gains and substantially outperforms its base encoder and recent open embedders (Linq Embed Mistral, SFR Embedding, GTE Qwen, BGE large, Embedding Gemma). The result is a fast, interpretable, LLM-free retrieval layer that links ambient context to actionable clinical orders in real time.
RedactOR: An LLM-Powered Framework for Automatic Clinical Data De-Identification
May 23, 2025Ensuring clinical data privacy while preserving utility is critical for AI-driven healthcare and data analytics. Existing de-identification (De-ID) methods, including rule-based techniques, deep learning models, and large language models (LLMs), often suffer from recall errors, limited generalization, and inefficiencies, limiting their real-world applicability. We propose a fully automated, multi-modal framework, RedactOR for de-identifying structured and unstructured electronic health records, including clinical audio records. Our framework employs cost-efficient De-ID strategies, including intelligent routing, hybrid rule and LLM based approaches, and a two-step audio redaction approach. We present a retrieval-based entity relexicalization approach to ensure consistent substitutions of protected entities, thereby enhancing data coherence for downstream applications. We discuss key design desiderata, de-identification and relexicalization methodology, and modular architecture of RedactX and its integration with the Oracle Health Clinical AI system. Evaluated on the i2b2 2014 De-ID dataset using standard metrics with strict recall, our approach achieves competitive performance while optimizing token usage to reduce LLM costs. Finally, we discuss key lessons and insights from deployment in real-world AI- driven healthcare data pipelines.
Mitigating Uncertainty of Classifier for Unsupervised Domain Adaptation
Jul 01, 2021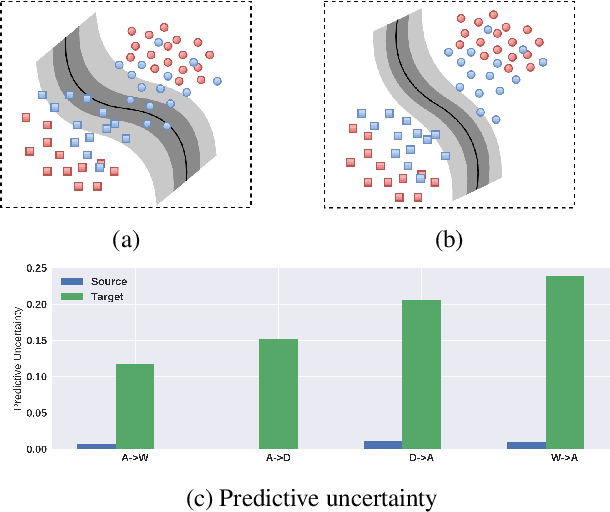
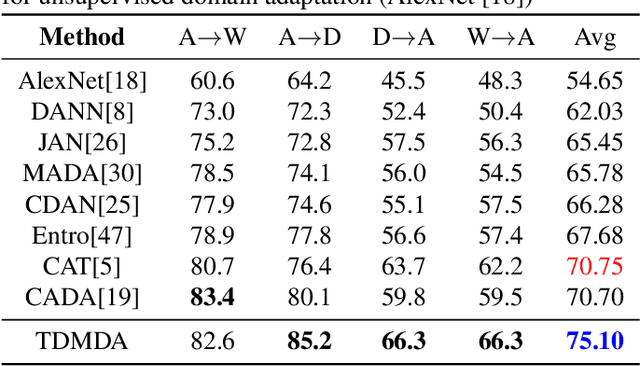

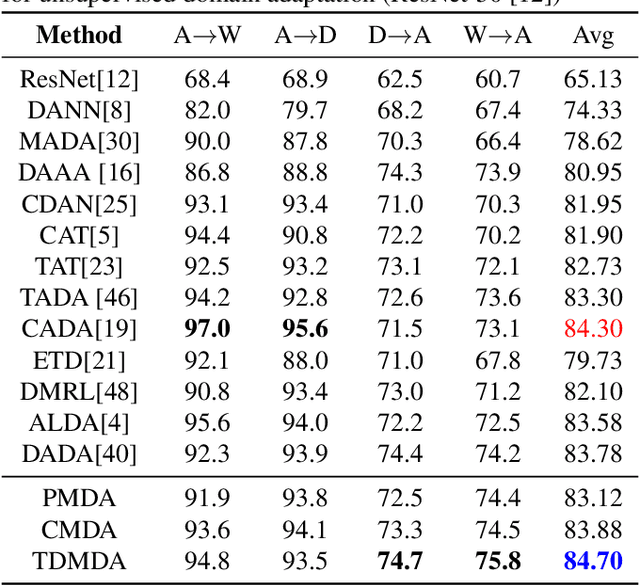
Understanding unsupervised domain adaptation has been an important task that has been well explored. However, the wide variety of methods have not analyzed the role of a classifier's performance in detail. In this paper, we thoroughly examine the role of a classifier in terms of matching source and target distributions. We specifically investigate the classifier ability by matching a) the distribution of features, b) probabilistic uncertainty for samples and c) certainty activation mappings. Our analysis suggests that using these three distributions does result in a consistently improved performance on all the datasets. Our work thus extends present knowledge on the role of the various distributions obtained from the classifier towards solving unsupervised domain adaptation.