 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs High Variance Unavoidable in RL? A Case Study in Continuous Control
Oct 21, 2021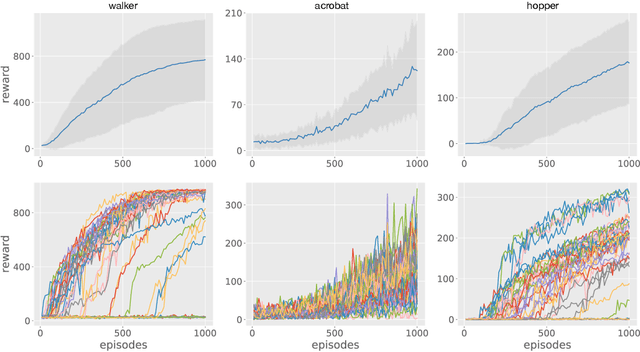
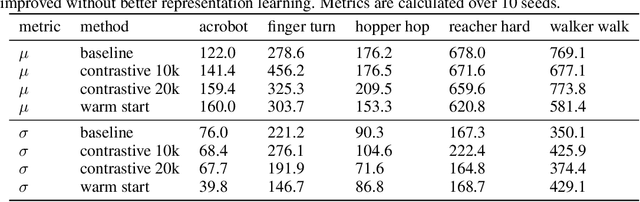
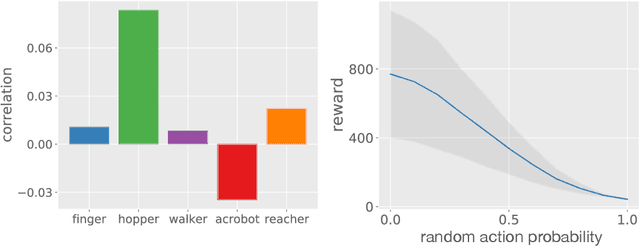
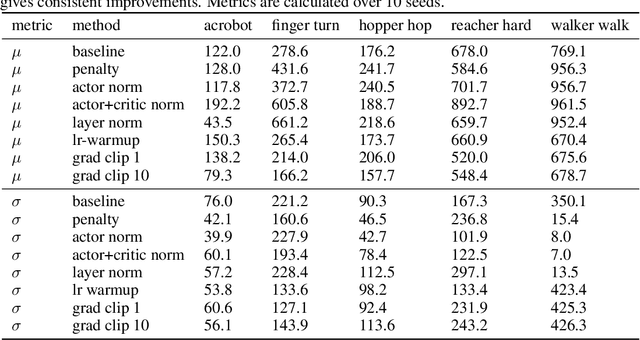
Reinforcement learning (RL) experiments have notoriously high variance, and minor details can have disproportionately large effects on measured outcomes. This is problematic for creating reproducible research and also serves as an obstacle for real-world applications, where safety and predictability are paramount. In this paper, we investigate causes for this perceived instability. To allow for an in-depth analysis, we focus on a specifically popular setup with high variance -- continuous control from pixels with an actor-critic agent. In this setting, we demonstrate that variance mostly arises early in training as a result of poor "outlier" runs, but that weight initialization and initial exploration are not to blame. We show that one cause for early variance is numerical instability which leads to saturating nonlinearities. We investigate several fixes to this issue and find that one particular method is surprisingly effective and simple -- normalizing penultimate features. Addressing the learning instability allows for larger learning rates, and significantly decreases the variance of outcomes. This demonstrates that the perceived variance in RL is not necessarily inherent to the problem definition and may be addressed through simple architectural modifications.
Performance-Efficiency Trade-offs in Unsupervised Pre-training for Speech Recognition
Sep 14, 2021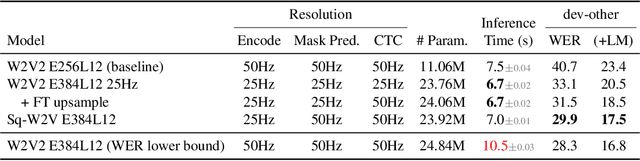
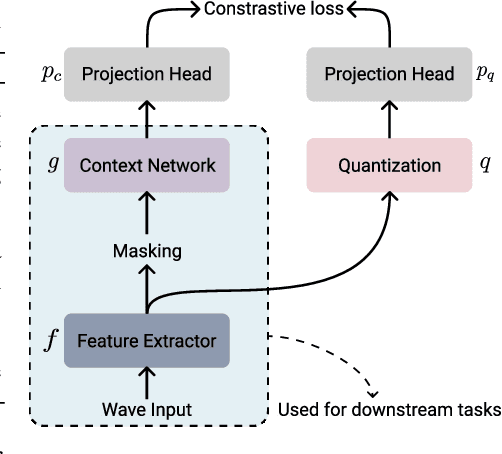
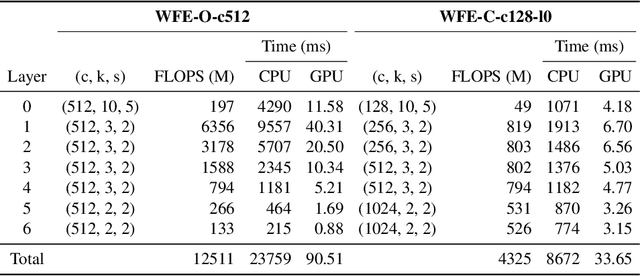
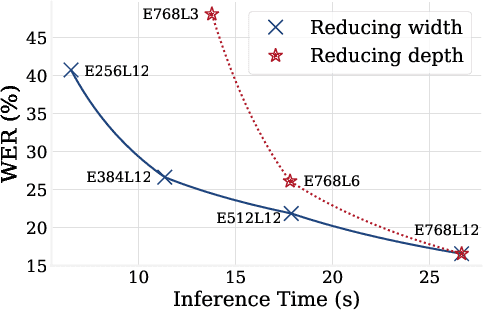
This paper is a study of performance-efficiency trade-offs in pre-trained models for automatic speech recognition (ASR). We focus on wav2vec 2.0, and formalize several architecture designs that influence both the model performance and its efficiency. Putting together all our observations, we introduce SEW (Squeezed and Efficient Wav2vec), a pre-trained model architecture with significant improvements along both performance and efficiency dimensions across a variety of training setups. For example, under the 100h-960h semi-supervised setup on LibriSpeech, SEW achieves a 1.9x inference speedup compared to wav2vec 2.0, with a 13.5% relative reduction in word error rate. With a similar inference time, SEW reduces word error rate by 25-50% across different model sizes.
Online Adaptation to Label Distribution Shift
Jul 09, 2021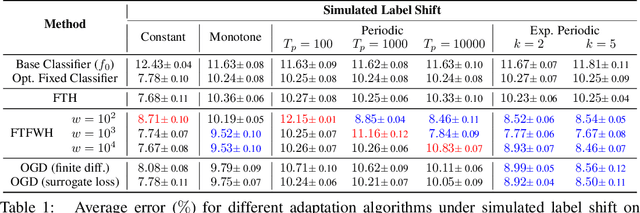
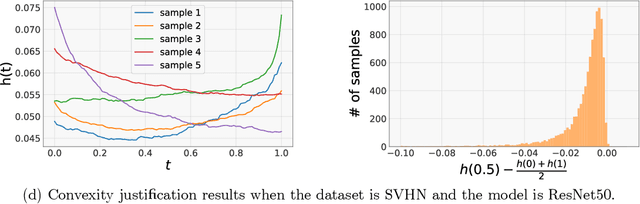

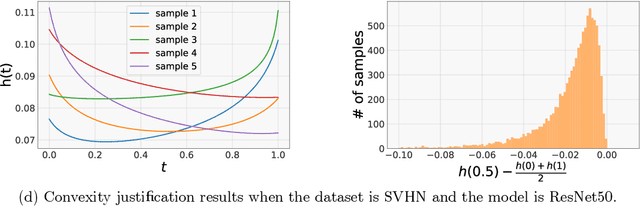
Machine learning models often encounter distribution shifts when deployed in the real world. In this paper, we focus on adaptation to label distribution shift in the online setting, where the test-time label distribution is continually changing and the model must dynamically adapt to it without observing the true label. Leveraging a novel analysis, we show that the lack of true label does not hinder estimation of the expected test loss, which enables the reduction of online label shift adaptation to conventional online learning. Informed by this observation, we propose adaptation algorithms inspired by classical online learning techniques such as Follow The Leader (FTL) and Online Gradient Descent (OGD) and derive their regret bounds. We empirically verify our findings under both simulated and real world label distribution shifts and show that OGD is particularly effective and robust to a variety of challenging label shift scenarios.
Towards Deeper Deep Reinforcement Learning
Jun 02, 2021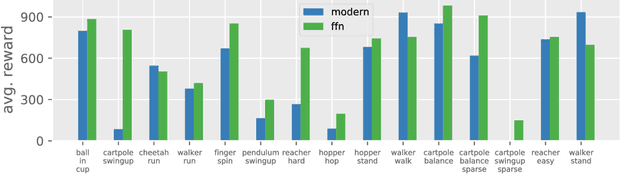
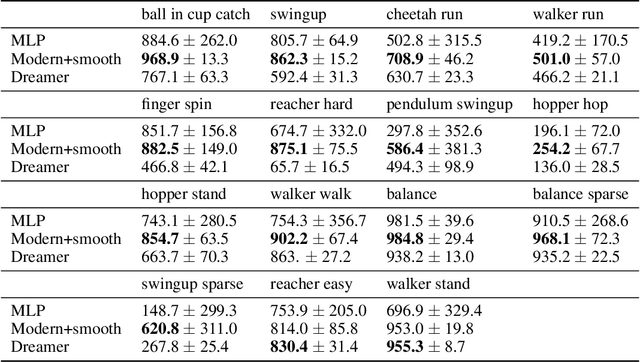
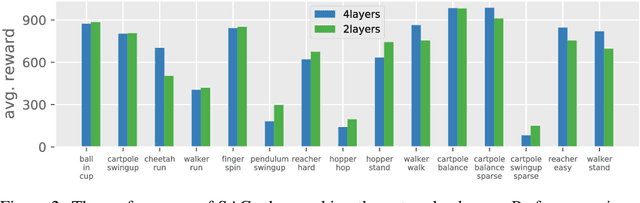

In computer vision and natural language processing, innovations in model architecture that lead to increases in model capacity have reliably translated into gains in performance. In stark contrast with this trend, state-of-the-art reinforcement learning (RL) algorithms often use only small MLPs, and gains in performance typically originate from algorithmic innovations. It is natural to hypothesize that small datasets in RL necessitate simple models to avoid overfitting; however, this hypothesis is untested. In this paper we investigate how RL agents are affected by exchanging the small MLPs with larger modern networks with skip connections and normalization, focusing specifically on soft actor-critic (SAC) algorithms. We verify, empirically, that na\"ively adopting such architectures leads to instabilities and poor performance, likely contributing to the popularity of simple models in practice. However, we show that dataset size is not the limiting factor, and instead argue that intrinsic instability from the actor in SAC taking gradients through the critic is the culprit. We demonstrate that a simple smoothing method can mitigate this issue, which enables stable training with large modern architectures. After smoothing, larger models yield dramatic performance improvements for state-of-the-art agents -- suggesting that more "easy" gains may be had by focusing on model architectures in addition to algorithmic innovations.
Low-Precision Reinforcement Learning
Feb 26, 2021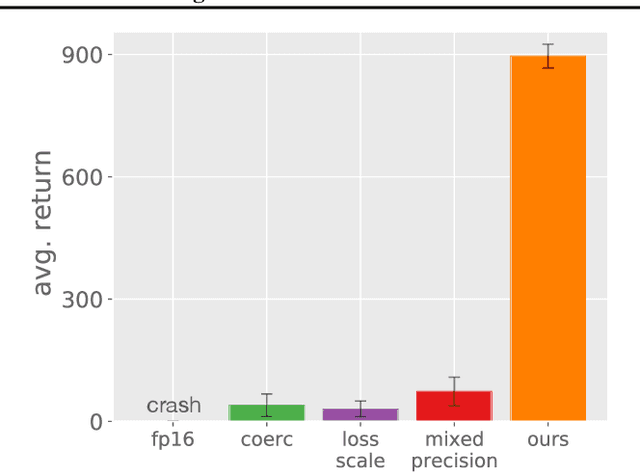

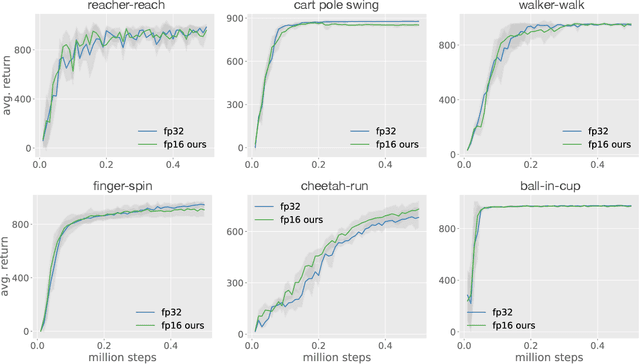
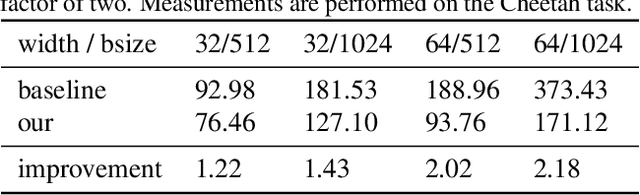
Low-precision training has become a popular approach to reduce computation time, memory footprint, and energy consumption in supervised learning. In contrast, this promising approach has not enjoyed similarly widespread adoption within the reinforcement learning (RL) community, in part because RL agents can be notoriously hard to train -- even in full precision. In this paper we consider continuous control with the state-of-the-art SAC agent and demonstrate that a na\"ive adaptation of low-precision methods from supervised learning fails. We propose a set of six modifications, all straightforward to implement, that leaves the underlying agent unchanged but improves its numerical stability dramatically. The resulting modified SAC agent has lower memory and compute requirements while matching full-precision rewards, thus demonstrating the feasibility of low-precision RL.
Making Paper Reviewing Robust to Bid Manipulation Attacks
Feb 22, 2021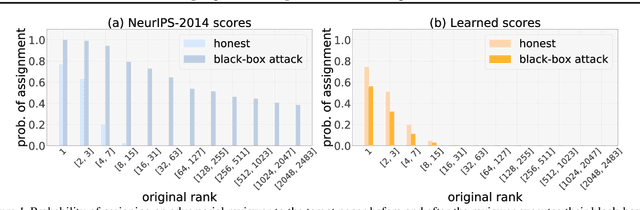
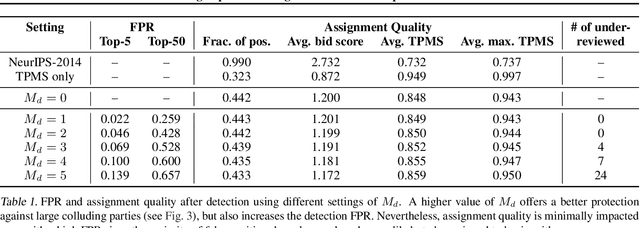
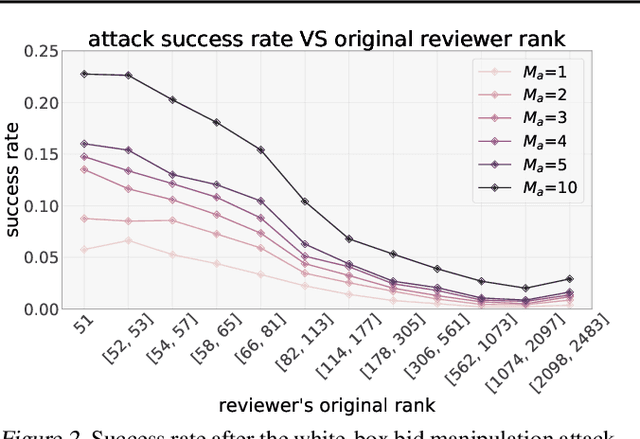
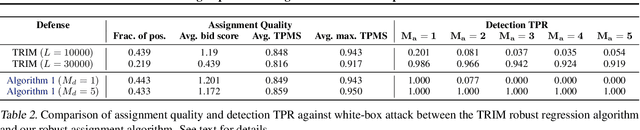
Most computer science conferences rely on paper bidding to assign reviewers to papers. Although paper bidding enables high-quality assignments in days of unprecedented submission numbers, it also opens the door for dishonest reviewers to adversarially influence paper reviewing assignments. Anecdotal evidence suggests that some reviewers bid on papers by "friends" or colluding authors, even though these papers are outside their area of expertise, and recommend them for acceptance without considering the merit of the work. In this paper, we study the efficacy of such bid manipulation attacks and find that, indeed, they can jeopardize the integrity of the review process. We develop a novel approach for paper bidding and assignment that is much more robust against such attacks. We show empirically that our approach provides robustness even when dishonest reviewers collude, have full knowledge of the assignment system's internal workings, and have access to the system's inputs. In addition to being more robust, the quality of our paper review assignments is comparable to that of current, non-robust assignment approaches.
Correlator Convolutional Neural Networks: An Interpretable Architecture for Image-like Quantum Matter Data
Nov 06, 2020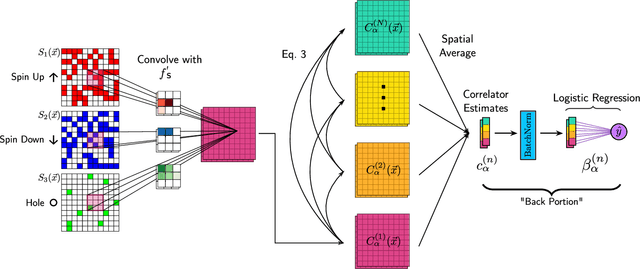
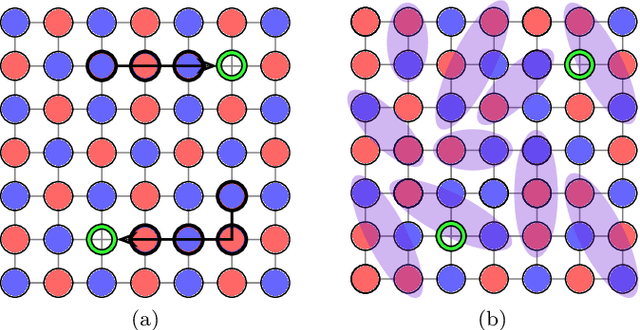
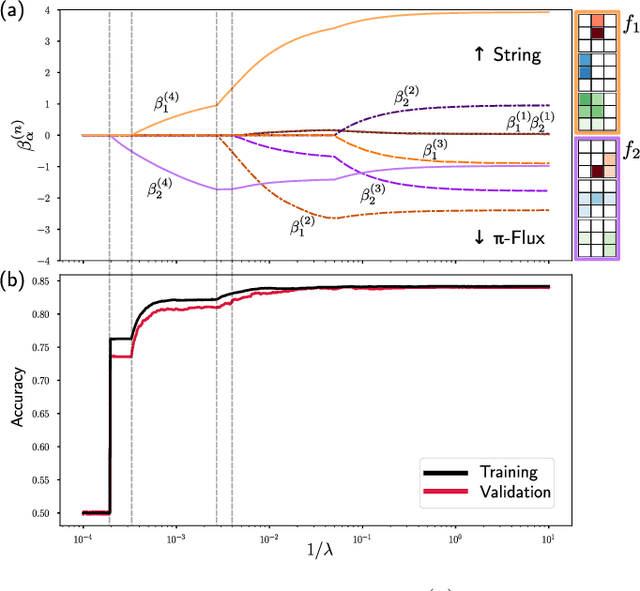
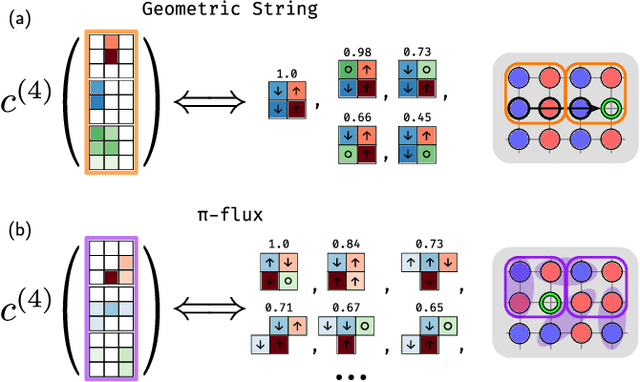
Machine learning models are a powerful theoretical tool for analyzing data from quantum simulators, in which results of experiments are sets of snapshots of many-body states. Recently, they have been successfully applied to distinguish between snapshots that can not be identified using traditional one and two point correlation functions. Thus far, the complexity of these models has inhibited new physical insights from this approach. Here, using a novel set of nonlinearities we develop a network architecture that discovers features in the data which are directly interpretable in terms of physical observables. In particular, our network can be understood as uncovering high-order correlators which significantly differ between the data studied. We demonstrate this new architecture on sets of simulated snapshots produced by two candidate theories approximating the doped Fermi-Hubbard model, which is realized in state-of-the art quantum gas microscopy experiments. From the trained networks, we uncover that the key distinguishing features are fourth-order spin-charge correlators, providing a means to compare experimental data to theoretical predictions. Our approach lends itself well to the construction of simple, end-to-end interpretable architectures and is applicable to arbitrary lattice data, thus paving the way for new physical insights from machine learning studies of experimental as well as numerical data.
MiCo: Mixup Co-Training for Semi-Supervised Domain Adaptation
Jul 24, 2020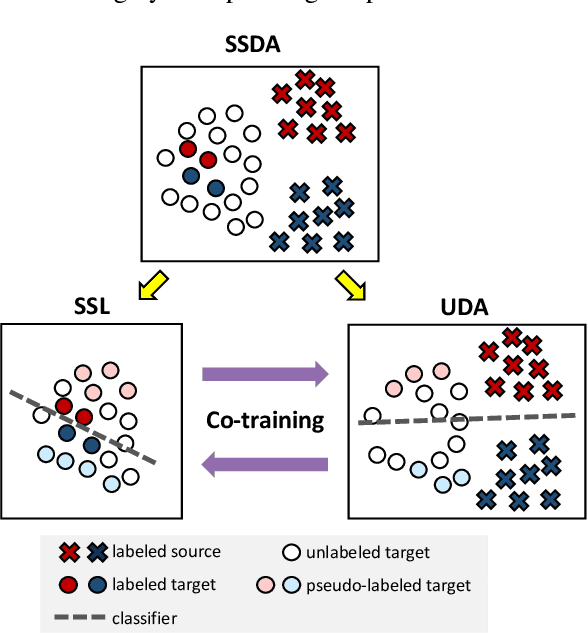
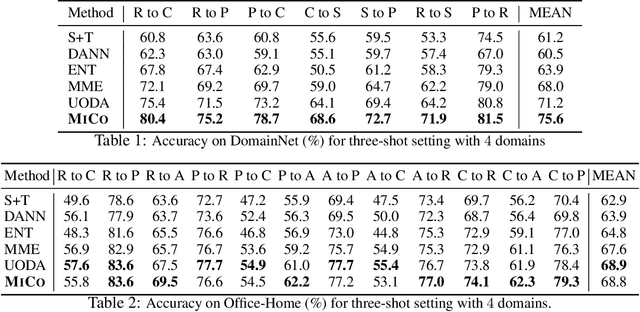
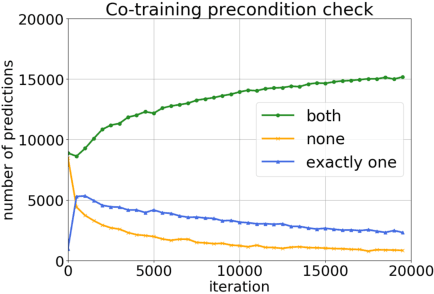
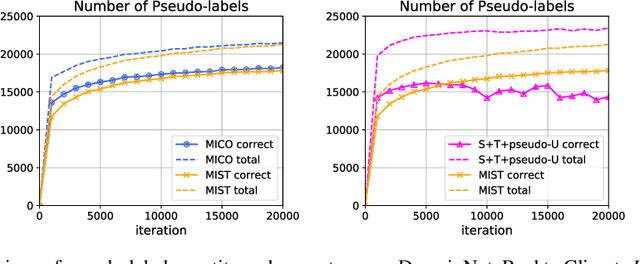
Semi-supervised domain adaptation (SSDA) aims to adapt models from a labeled source domain to a different but related target domain, from which unlabeled data and a small set of labeled data are provided. In this paper we propose a new approach for SSDA, which is to explicitly decompose SSDA into two sub-problems: a semi-supervised learning (SSL) problem in the target domain and an unsupervised domain adaptation (UDA) problem across domains. We show that these two sub-problems yield very different classifiers, which we leverage with our algorithm MixUp Co-training (MiCo). MiCo applies Mixup to bridge the gap between labeled and unlabeled data of each individual model and employs co-training to exchange the expertise between the two classifiers. MiCo needs no adversarial and minmax training, making it easily implementable and stable. MiCo achieves state-of-the-art results on SSDA datasets, outperforming the prior art by a notable 4% margin on DomainNet.
Wasserstein Distances for Stereo Disparity Estimation
Jul 06, 2020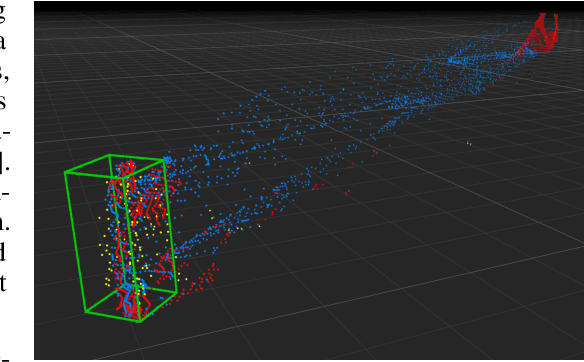
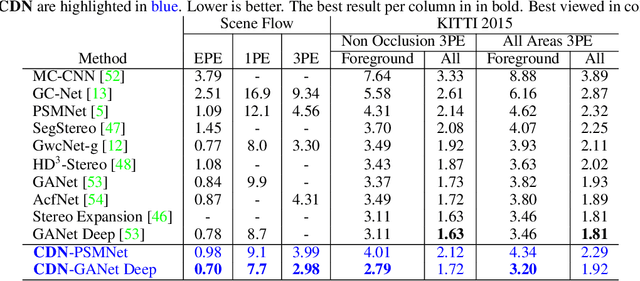
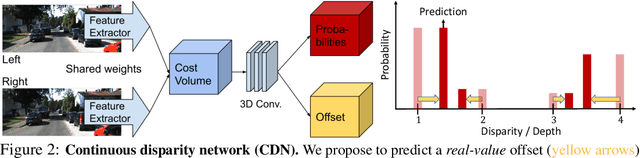
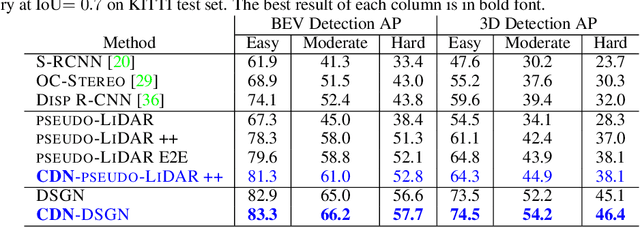
Existing approaches to depth or disparity estimation output a distribution over a set of pre-defined discrete values. This leads to inaccurate results when the true depth or disparity does not match any of these values. The fact that this distribution is usually learned indirectly through a regression loss causes further problems in ambiguous regions around object boundaries. We address these issues using a new neural network architecture that is capable of outputting arbitrary depth values, and a new loss function that is derived from the Wasserstein distance between the true and the predicted distributions. We validate our approach on a variety of tasks, including stereo disparity and depth estimation, and the downstream 3D object detection. Our approach drastically reduces the error in ambiguous regions, especially around object boundaries that greatly affect the localization of objects in 3D, achieving the state-of-the-art in 3D object detection for autonomous driving.
Revisiting Few-sample BERT Fine-tuning
Jul 02, 2020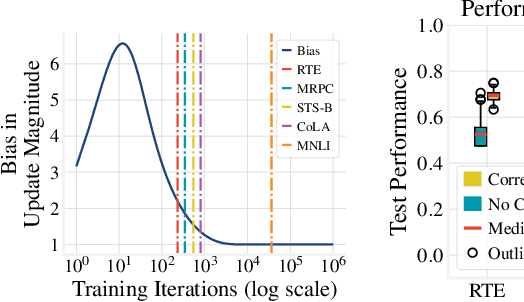
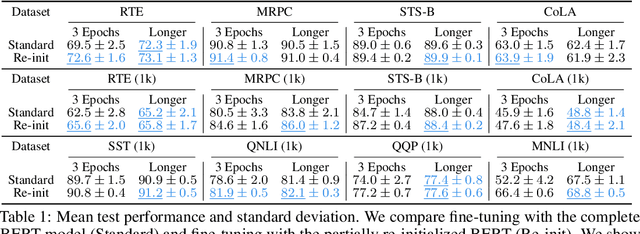

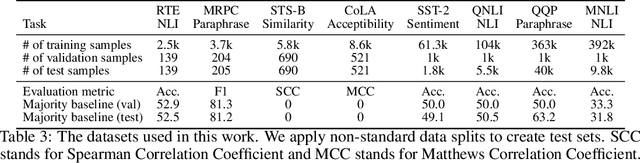
We study the problem of few-sample fine-tuning of BERT contextual representations, and identify three sub-optimal choices in current, broadly adopted practices. First, we observe that the omission of the gradient bias correction in the BERTAdam optimizer results in fine-tuning instability. We also find that parts of the BERT network provide a detrimental starting point for fine-tuning, and simply re-initializing these layers speeds up learning and improves performance. Finally, we study the effect of training time, and observe that commonly used recipes often do not allocate sufficient time for training. In light of these findings, we re-visit recently proposed methods to improve few-sample fine-tuning with BERT and re-evaluate their effectiveness. Generally, we observe a decrease in their relative impact when modifying the fine-tuning process based on our findings.