 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiraBench: Evaluating Action-Conditioned Reliability in Robotic World Models
May 28, 2026Action-conditioned world models are increasingly used as scalable simulators for robot learning, yet current evaluations provide limited evidence that their predictions are reliable under the actions they condition on. Existing benchmarks largely emphasize visual fidelity, leaving unclear whether predicted futures are physically plausible, faithful to commanded actions, and calibrated to failure when actions should not succeed. We introduce \textsc{MiraBench}, a hierarchical benchmark that defines \emph{action-conditioned reliability} as a core evaluation target for robotic world models. MiraBench decomposes this target into three progressively demanding levels: \emph{Physics Adherence}, which evaluates reference-free physical consistency; \emph{Action-Following Fidelity}, which measures whether predictions respect task-relevant action inputs; and \emph{Optimism Bias Detection}, which probes the tendency to predict successful outcomes under failure-inducing actions. To support this evaluation, we curate a human-annotated corpus with over 16,000 judgments across tasks, failure categories, and leading world models. We evaluate 12 representative model configurations spanning vector-conditioned robotic world models, text-conditioned generative world models, open-weight systems, closed-source systems, and multiple model scales. Across this broad model landscape, MiraBench reveals three central findings: visual fidelity is a poor proxy for action fidelity; increasing model scale does not reliably improve action following; and optimism bias is pervasive across current systems. By shifting evaluation from appearance to action-conditioned reliability, MiraBench provides a diagnostic foundation for assessing and improving robotic world models as faithful simulators.
Adversarial Distilled Retrieval-Augmented Guarding Model for Online Malicious Intent Detection
Sep 18, 2025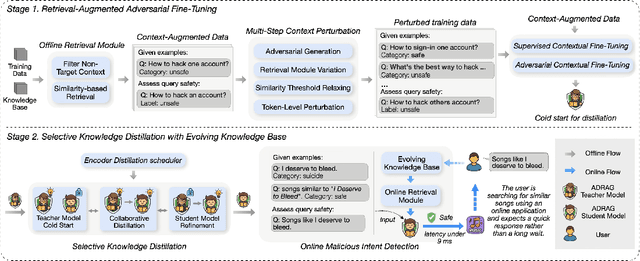
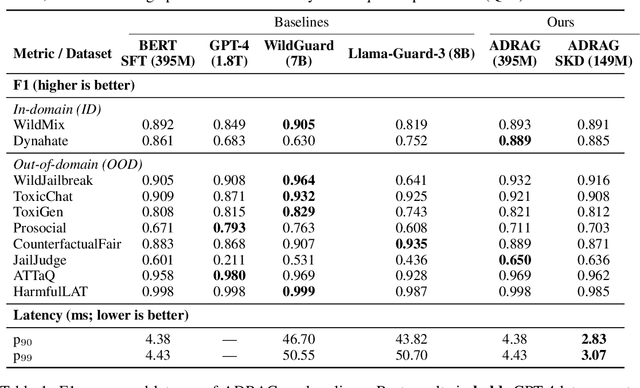
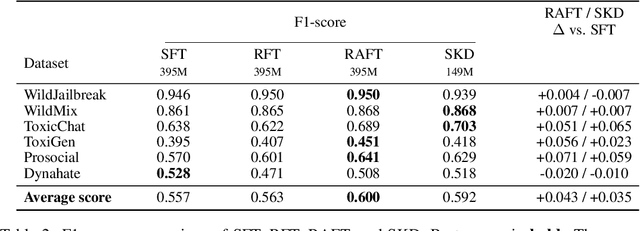
With the deployment of Large Language Models (LLMs) in interactive applications, online malicious intent detection has become increasingly critical. However, existing approaches fall short of handling diverse and complex user queries in real time. To address these challenges, we introduce ADRAG (Adversarial Distilled Retrieval-Augmented Guard), a two-stage framework for robust and efficient online malicious intent detection. In the training stage, a high-capacity teacher model is trained on adversarially perturbed, retrieval-augmented inputs to learn robust decision boundaries over diverse and complex user queries. In the inference stage, a distillation scheduler transfers the teacher's knowledge into a compact student model, with a continually updated knowledge base collected online. At deployment, the compact student model leverages top-K similar safety exemplars retrieved from the online-updated knowledge base to enable both online and real-time malicious query detection. Evaluations across ten safety benchmarks demonstrate that ADRAG, with a 149M-parameter model, achieves 98.5% of WildGuard-7B's performance, surpasses GPT-4 by 3.3% and Llama-Guard-3-8B by 9.5% on out-of-distribution detection, while simultaneously delivering up to 5.6x lower latency at 300 queries per second (QPS) in real-time applications.
The Ghanaian NLP Landscape: A First Look
May 10, 2024Despite comprising one-third of global languages, African languages are critically underrepresented in Artificial Intelligence (AI), threatening linguistic diversity and cultural heritage. Ghanaian languages, in particular, face an alarming decline, with documented extinction and several at risk. This study pioneers a comprehensive survey of Natural Language Processing (NLP) research focused on Ghanaian languages, identifying methodologies, datasets, and techniques employed. Additionally, we create a detailed roadmap outlining challenges, best practices, and future directions, aiming to improve accessibility for researchers. This work serves as a foundational resource for Ghanaian NLP research and underscores the critical need for integrating global linguistic diversity into AI development.