 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Visual Continual Learning with Language-Guided Supervision
Mar 24, 2024



Continual learning (CL) aims to empower models to learn new tasks without forgetting previously acquired knowledge. Most prior works concentrate on the techniques of architectures, replay data, regularization, \etc. However, the category name of each class is largely neglected. Existing methods commonly utilize the one-hot labels and randomly initialize the classifier head. We argue that the scarce semantic information conveyed by the one-hot labels hampers the effective knowledge transfer across tasks. In this paper, we revisit the role of the classifier head within the CL paradigm and replace the classifier with semantic knowledge from pretrained language models (PLMs). Specifically, we use PLMs to generate semantic targets for each class, which are frozen and serve as supervision signals during training. Such targets fully consider the semantic correlation between all classes across tasks. Empirical studies show that our approach mitigates forgetting by alleviating representation drifting and facilitating knowledge transfer across tasks. The proposed method is simple to implement and can seamlessly be plugged into existing methods with negligible adjustments. Extensive experiments based on eleven mainstream baselines demonstrate the effectiveness and generalizability of our approach to various protocols. For example, under the class-incremental learning setting on ImageNet-100, our method significantly improves the Top-1 accuracy by 3.2\% to 6.1\% while reducing the forgetting rate by 2.6\% to 13.1\%.
Multilingual and Fully Non-Autoregressive ASR with Large Language Model Fusion: A Comprehensive Study
Jan 23, 2024



In the era of large models, the autoregressive nature of decoding often results in latency serving as a significant bottleneck. We propose a non-autoregressive LM-fused ASR system that effectively leverages the parallelization capabilities of accelerator hardware. Our approach combines the Universal Speech Model (USM) and the PaLM 2 language model in per-segment scoring mode, achieving an average relative WER improvement across all languages of 10.8% on FLEURS and 3.6% on YouTube captioning. Furthermore, our comprehensive ablation study analyzes key parameters such as LLM size, context length, vocabulary size, fusion methodology. For instance, we explore the impact of LLM size ranging from 128M to 340B parameters on ASR performance. This study provides valuable insights into the factors influencing the effectiveness of practical large-scale LM-fused speech recognition systems.
Feature Norm Regularized Federated Learning: Transforming Skewed Distributions into Global Insights
Dec 12, 2023In the field of federated learning, addressing non-independent and identically distributed (non-i.i.d.) data remains a quintessential challenge for improving global model performance. This work introduces the Feature Norm Regularized Federated Learning (FNR-FL) algorithm, which uniquely incorporates class average feature norms to enhance model accuracy and convergence in non-i.i.d. scenarios. Our comprehensive analysis reveals that FNR-FL not only accelerates convergence but also significantly surpasses other contemporary federated learning algorithms in test accuracy, particularly under feature distribution skew scenarios. The novel modular design of FNR-FL facilitates seamless integration with existing federated learning frameworks, reinforcing its adaptability and potential for widespread application. We substantiate our claims through rigorous empirical evaluations, demonstrating FNR-FL's exceptional performance across various skewed data distributions. Relative to FedAvg, FNR-FL exhibits a substantial 66.24\% improvement in accuracy and a significant 11.40\% reduction in training time, underscoring its enhanced effectiveness and efficiency.
Improving Joint Speech-Text Representations Without Alignment
Aug 11, 2023



The last year has seen astonishing progress in text-prompted image generation premised on the idea of a cross-modal representation space in which the text and image domains are represented jointly. In ASR, this idea has found application as joint speech-text encoders that can scale to the capacities of very large parameter models by being trained on both unpaired speech and text. While these methods show promise, they have required special treatment of the sequence-length mismatch inherent in speech and text, either by up-sampling heuristics or an explicit alignment model. In this work, we offer evidence that joint speech-text encoders naturally achieve consistent representations across modalities by disregarding sequence length, and argue that consistency losses could forgive length differences and simply assume the best alignment. We show that such a loss improves downstream WER in both a large-parameter monolingual and multilingual system.
Mixture-of-Expert Conformer for Streaming Multilingual ASR
May 25, 2023End-to-end models with large capacity have significantly improved multilingual automatic speech recognition, but their computation cost poses challenges for on-device applications. We propose a streaming truly multilingual Conformer incorporating mixture-of-expert (MoE) layers that learn to only activate a subset of parameters in training and inference. The MoE layer consists of a softmax gate which chooses the best two experts among many in forward propagation. The proposed MoE layer offers efficient inference by activating a fixed number of parameters as the number of experts increases. We evaluate the proposed model on a set of 12 languages, and achieve an average 11.9% relative improvement in WER over the baseline. Compared to an adapter model using ground truth information, our MoE model achieves similar WER and activates similar number of parameters but without any language information. We further show around 3% relative WER improvement by multilingual shallow fusion.
A Deliberation-based Joint Acoustic and Text Decoder
Mar 23, 2023



We propose a new two-pass E2E speech recognition model that improves ASR performance by training on a combination of paired data and unpaired text data. Previously, the joint acoustic and text decoder (JATD) has shown promising results through the use of text data during model training and the recently introduced deliberation architecture has reduced recognition errors by leveraging first-pass decoding results. Our method, dubbed Deliberation-JATD, combines the spelling correcting abilities of deliberation with JATD's use of unpaired text data to further improve performance. The proposed model produces substantial gains across multiple test sets, especially those focused on rare words, where it reduces word error rate (WER) by between 12% and 22.5% relative. This is done without increasing model size or requiring multi-stage training, making Deliberation-JATD an efficient candidate for on-device applications.
Google USM: Scaling Automatic Speech Recognition Beyond 100 Languages
Mar 03, 2023
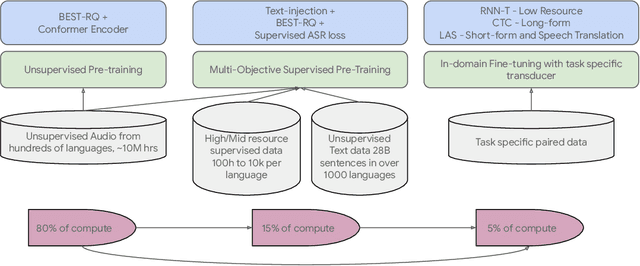
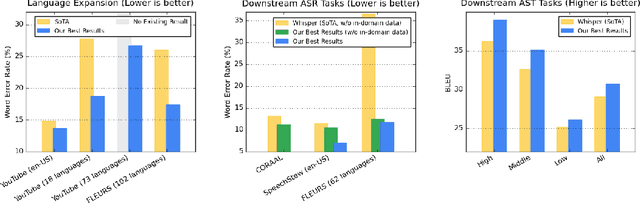

We introduce the Universal Speech Model (USM), a single large model that performs automatic speech recognition (ASR) across 100+ languages. This is achieved by pre-training the encoder of the model on a large unlabeled multilingual dataset of 12 million (M) hours spanning over 300 languages, and fine-tuning on a smaller labeled dataset. We use multilingual pre-training with random-projection quantization and speech-text modality matching to achieve state-of-the-art performance on downstream multilingual ASR and speech-to-text translation tasks. We also demonstrate that despite using a labeled training set 1/7-th the size of that used for the Whisper model, our model exhibits comparable or better performance on both in-domain and out-of-domain speech recognition tasks across many languages.
Massively Multilingual Shallow Fusion with Large Language Models
Feb 17, 2023While large language models (LLM) have made impressive progress in natural language processing, it remains unclear how to utilize them in improving automatic speech recognition (ASR). In this work, we propose to train a single multilingual language model (LM) for shallow fusion in multiple languages. We push the limits of the multilingual LM to cover up to 84 languages by scaling up using a mixture-of-experts LLM, i.e., generalist language model (GLaM). When the number of experts increases, GLaM dynamically selects only two at each decoding step to keep the inference computation roughly constant. We then apply GLaM to a multilingual shallow fusion task based on a state-of-the-art end-to-end model. Compared to a dense LM of similar computation during inference, GLaM reduces the WER of an English long-tail test set by 4.4% relative. In a multilingual shallow fusion task, GLaM improves 41 out of 50 languages with an average relative WER reduction of 3.85%, and a maximum reduction of 10%. Compared to the baseline model, GLaM achieves an average WER reduction of 5.53% over 43 languages.
Scaling Up Deliberation for Multilingual ASR
Oct 11, 2022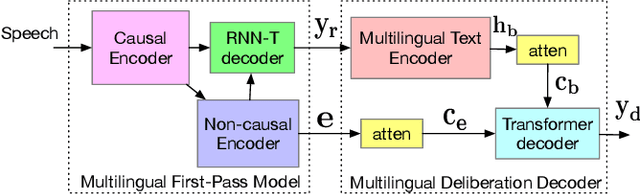
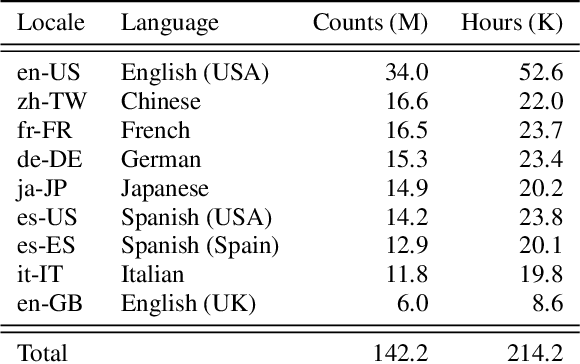
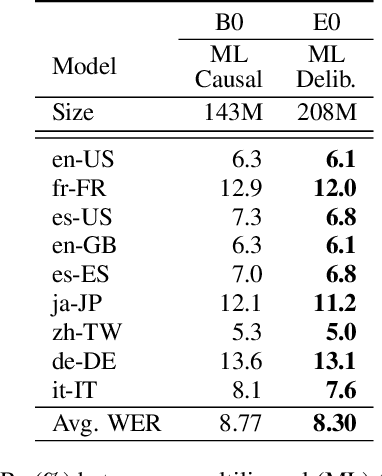
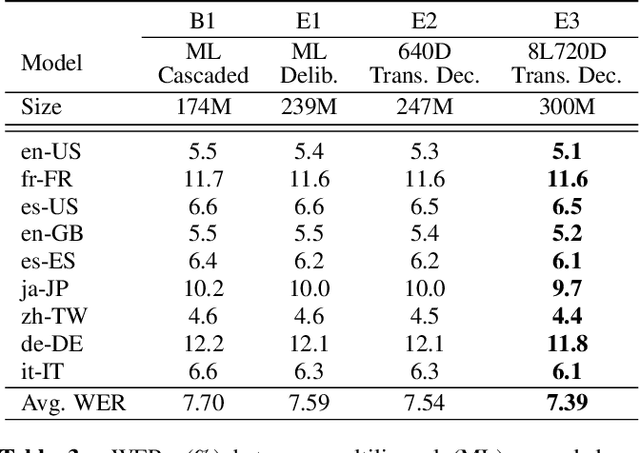
Multilingual end-to-end automatic speech recognition models are attractive due to its simplicity in training and deployment. Recent work on large-scale training of such models has shown promising results compared to monolingual models. However, the work often focuses on multilingual models themselves in a single-pass setup. In this work, we investigate second-pass deliberation for multilingual speech recognition. Our proposed deliberation is multilingual, i.e., the text encoder encodes hypothesis text from multiple languages, and the decoder attends to multilingual text and audio. We investigate scaling the deliberation text encoder and decoder, and compare scaling the deliberation decoder and the first-pass cascaded encoder. We show that deliberation improves the average WER on 9 languages by 4% relative compared to the single-pass model. By increasing the size of the deliberation up to 1B parameters, the average WER improvement increases to 9%, with up to 14% for certain languages. Our deliberation rescorer is based on transformer layers and can be parallelized during rescoring.
Improving Deliberation by Text-Only and Semi-Supervised Training
Jun 29, 2022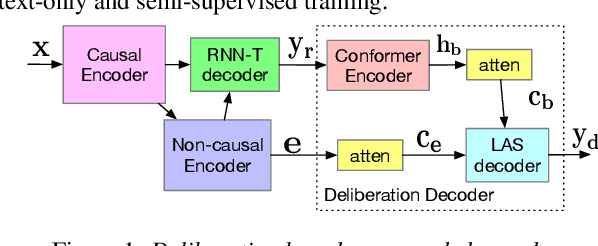
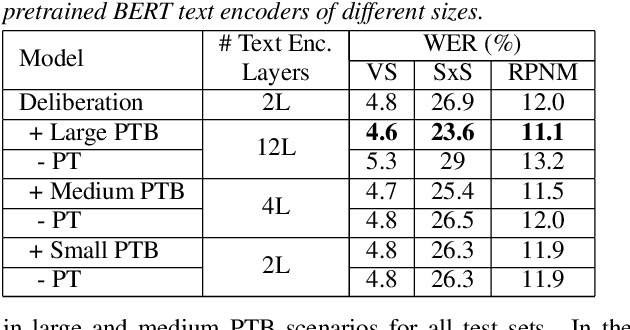
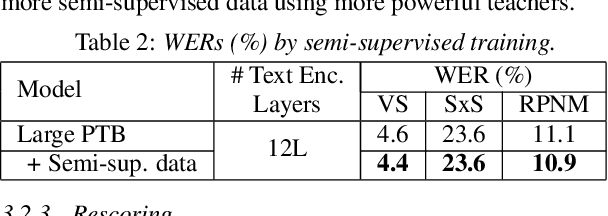
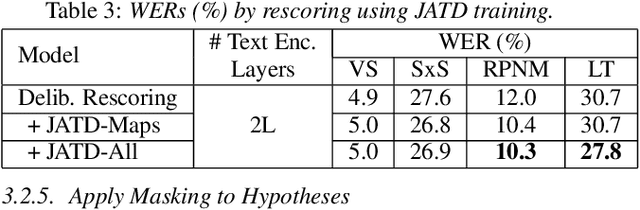
Text-only and semi-supervised training based on audio-only data has gained popularity recently due to the wide availability of unlabeled text and speech data. In this work, we propose incorporating text-only and semi-supervised training into an attention-based deliberation model. By incorporating text-only data in training a bidirectional encoder representation from transformer (BERT) for the deliberation text encoder, and large-scale text-to-speech and audio-only utterances using joint acoustic and text decoder (JATD) and semi-supervised training, we achieved 4%-12% WER reduction for various tasks compared to the baseline deliberation. Compared to a state-of-the-art language model (LM) rescoring method, the deliberation model reduces the Google Voice Search WER by 11% relative. We show that the deliberation model also achieves a positive human side-by-side evaluation compared to the state-of-the-art LM rescorer with reasonable endpointer latencies.