 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploration in Approximate Hyper-State Space for Meta Reinforcement Learning
Oct 02, 2020
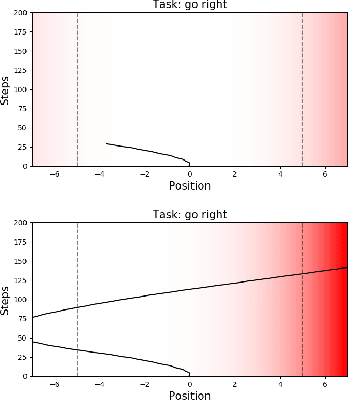

Meta-learning is a powerful tool for learning policies that can adapt efficiently when deployed in new tasks. If however the meta-training tasks have sparse rewards, the need for exploration during meta-training is exacerbated given that the agent has to explore and learn across many tasks. We show that current meta-learning methods can fail catastrophically in such environments. To address this problem, we propose HyperX, a novel method for meta-learning in sparse reward tasks. Using novel reward bonuses for meta-training, we incentivise the agent to explore in approximate hyper-state space, i.e., the joint state and approximate belief space, where the beliefs are over tasks. We show empirically that these bonuses allow an agent to successfully learn to solve sparse reward tasks where existing meta-learning methods fail.
"It's Unwieldy and It Takes a Lot of Time." Challenges and Opportunities for Creating Agents in Commercial Games
Sep 01, 2020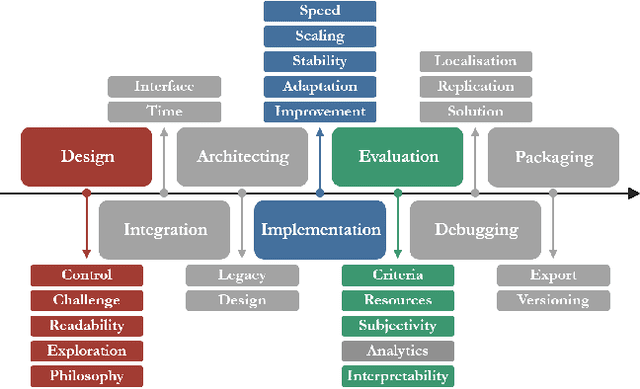
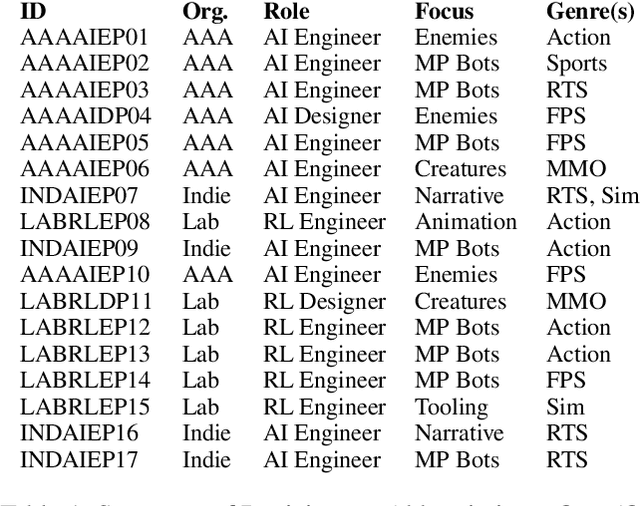

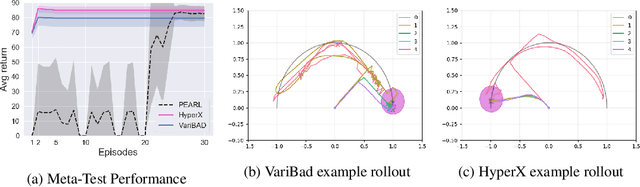
Game agents such as opponents, non-player characters, and teammates are central to player experiences in many modern games. As the landscape of AI techniques used in the games industry evolves to adopt machine learning (ML) more widely, it is vital that the research community learn from the best practices cultivated within the industry over decades creating agents. However, although commercial game agent creation pipelines are more mature than those based on ML, opportunities for improvement still abound. As a foundation for shared progress identifying research opportunities between researchers and practitioners, we interviewed seventeen game agent creators from AAA studios, indie studios, and industrial research labs about the challenges they experienced with their professional workflows. Our study revealed several open challenges ranging from design to implementation and evaluation. We compare with literature from the research community that address the challenges identified and conclude by highlighting promising directions for future research supporting agent creation in the games industry.
Analytic Manifold Learning: Unifying and Evaluating Representations for Continuous Control
Jun 15, 2020
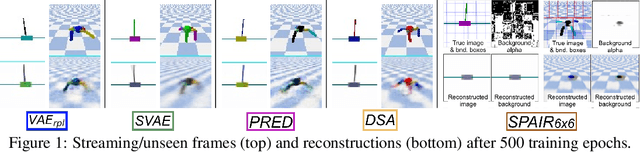
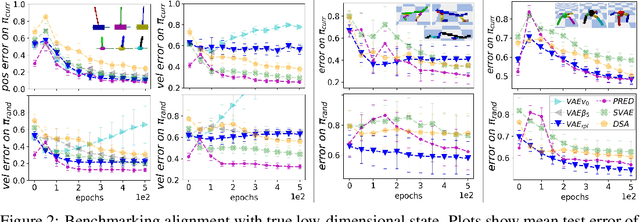

We address the problem of learning reusable state representations from streaming high-dimensional observations. This is important for areas like Reinforcement Learning (RL), which yields non-stationary data distributions during training. We make two key contributions. First, we propose an evaluation suite that measures alignment between latent and true low-dimensional states. We benchmark several widely used unsupervised learning approaches. This uncovers the strengths and limitations of existing approaches that impose additional constraints/objectives on the latent space. Our second contribution is a unifying mathematical formulation for learning latent relations. We learn analytic relations on source domains, then use these relations to help structure the latent space when learning on target domains. This formulation enables a more general, flexible and principled way of shaping the latent space. It formalizes the notion of learning independent relations, without imposing restrictive simplifying assumptions or requiring domain-specific information. We present mathematical properties, concrete algorithms for implementation and experimental validation of successful learning and transfer of latent relations.
Guaranteeing Reproducibility in Deep Learning Competitions
May 12, 2020To encourage the development of methods with reproducible and robust training behavior, we propose a challenge paradigm where competitors are evaluated directly on the performance of their learning procedures rather than pre-trained agents. Since competition organizers re-train proposed methods in a controlled setting they can guarantee reproducibility, and -- by retraining submissions using a held-out test set -- help ensure generalization past the environments on which they were trained.
Recognizing Spatial Configurations of Objects with Graph Neural Networks
Apr 09, 2020

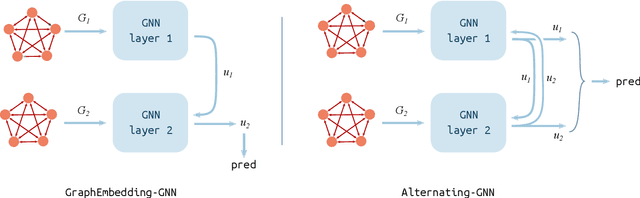
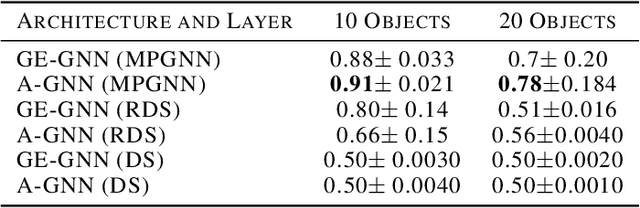
Deep learning algorithms can be seen as compositions of functions acting on learned representations encoded as tensor-structured data. However, in most applications those representations are monolithic, with for instance one single vector encoding an entire image or sentence. In this paper, we build upon the recent successes of Graph Neural Networks (GNNs) to explore the use of graph-structured representations for learning spatial configurations. Motivated by the ability of humans to distinguish arrangements of shapes, we introduce two novel geometrical reasoning tasks, for which we provide the datasets. We introduce novel GNN layers and architectures to solve the tasks and show that graph-structured representations are necessary for good performance.
Trying AGAIN instead of Trying Longer: Prior Learning for Automatic Curriculum Learning
Apr 07, 2020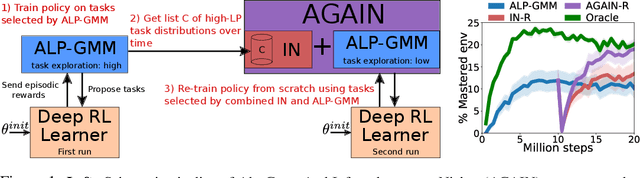
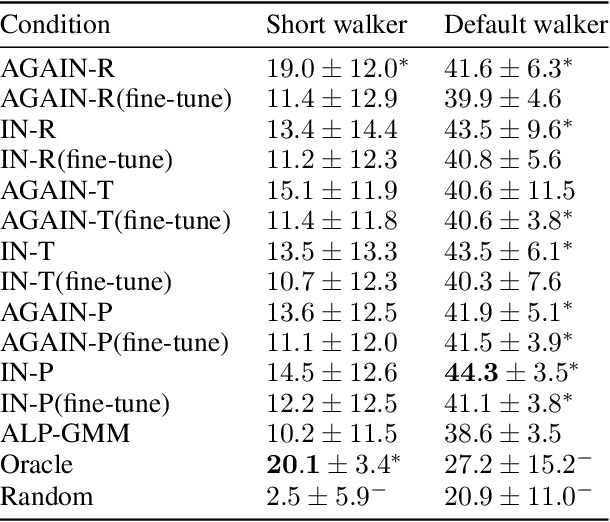
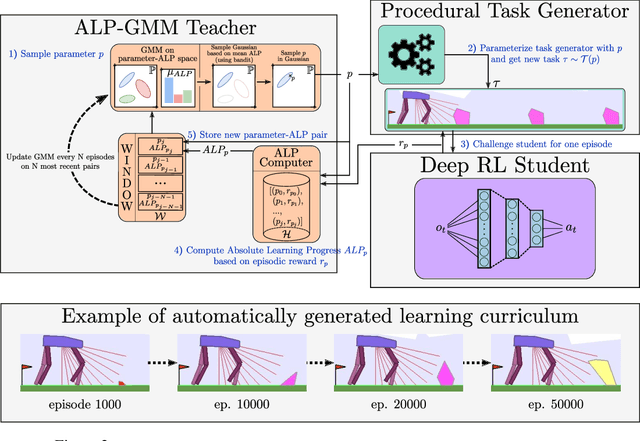
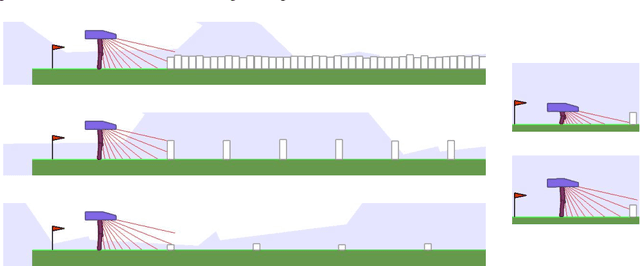
A major challenge in the Deep RL (DRL) community is to train agents able to generalize over unseen situations, which is often approached by training them on a diversity of tasks (or environments). A powerful method to foster diversity is to procedurally generate tasks by sampling their parameters from a multi-dimensional distribution, enabling in particular to propose a different task for each training episode. In practice, to get the high diversity of training tasks necessary for generalization, one has to use complex procedural generation systems. With such generators, it is hard to get prior knowledge on the subset of tasks that are actually learnable at all (many generated tasks may be unlearnable), what is their relative difficulty and what is the most efficient task distribution ordering for training. A typical solution in such cases is to rely on some form of Automated Curriculum Learning (ACL) to adapt the sampling distribution. One limit of current approaches is their need to explore the task space to detect progress niches over time, which leads to a loss of time. Additionally, we hypothesize that the induced noise in the training data may impair the performances of brittle DRL learners. We address this problem by proposing a two stage ACL approach where 1) a teacher algorithm first learns to train a DRL agent with a high-exploration curriculum, and then 2) distills learned priors from the first run to generate an "expert curriculum" to re-train the same agent from scratch. Besides demonstrating 50% improvements on average over the current state of the art, the objective of this work is to give a first example of a new research direction oriented towards refining ACL techniques over multiple learners, which we call Classroom Teaching.
Automatic Curriculum Learning For Deep RL: A Short Survey
Mar 10, 2020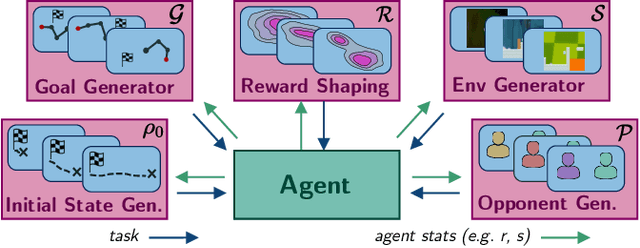
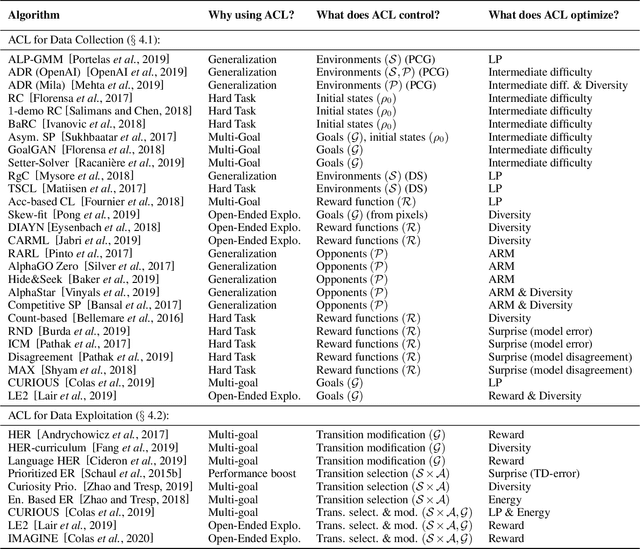
Automatic Curriculum Learning (ACL) has become a cornerstone of recent successes in Deep Reinforcement Learning (DRL).These methods shape the learning trajectories of agents by challenging them with tasks adapted to their capacities. In recent years, they have been used to improve sample efficiency and asymptotic performance, to organize exploration, to encourage generalization or to solve sparse reward problems, among others. The ambition of this work is dual: 1) to present a compact and accessible introduction to the Automatic Curriculum Learning literature and 2) to draw a bigger picture of the current state of the art in ACL to encourage the cross-breeding of existing concepts and the emergence of new ideas.
Generalization in Reinforcement Learning with Selective Noise Injection and Information Bottleneck
Oct 28, 2019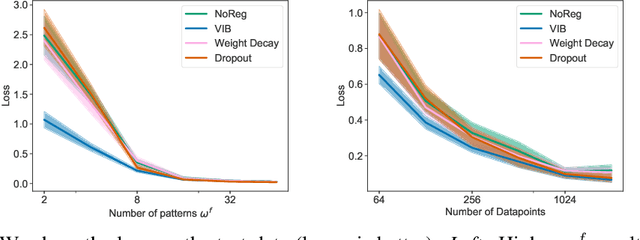
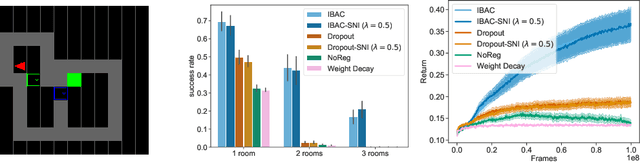
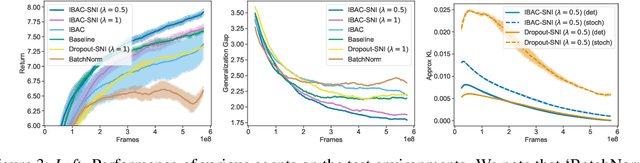
The ability for policies to generalize to new environments is key to the broad application of RL agents. A promising approach to prevent an agent's policy from overfitting to a limited set of training environments is to apply regularization techniques originally developed for supervised learning. However, there are stark differences between supervised learning and RL. We discuss those differences and propose modifications to existing regularization techniques in order to better adapt them to RL. In particular, we focus on regularization techniques relying on the injection of noise into the learned function, a family that includes some of the most widely used approaches such as Dropout and Batch Normalization. To adapt them to RL, we propose Selective Noise Injection (SNI), which maintains the regularizing effect the injected noise has, while mitigating the adverse effects it has on the gradient quality. Furthermore, we demonstrate that the Information Bottleneck (IB) is a particularly well suited regularization technique for RL as it is effective in the low-data regime encountered early on in training RL agents. Combining the IB with SNI, we significantly outperform current state of the art results, including on the recently proposed generalization benchmark Coinrun.
Better Exploration with Optimistic Actor-Critic
Oct 28, 2019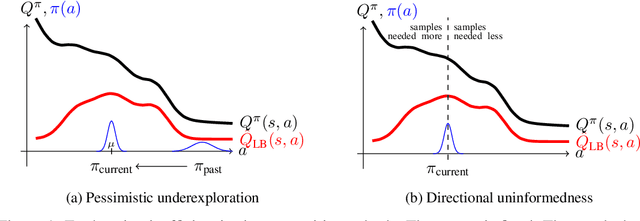
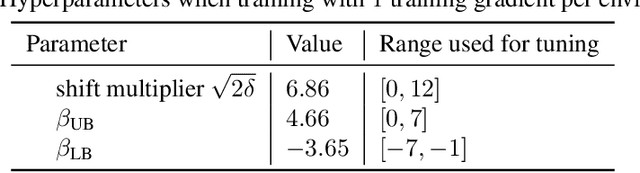
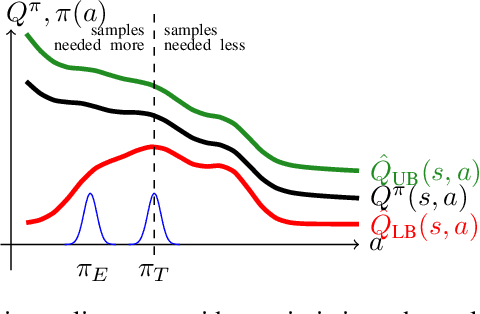
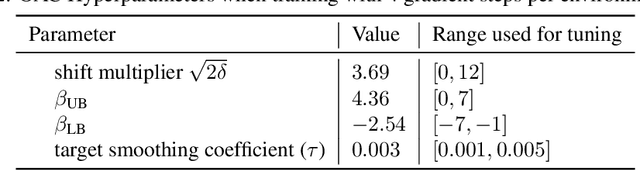
Actor-critic methods, a type of model-free Reinforcement Learning, have been successfully applied to challenging tasks in continuous control, often achieving state-of-the art performance. However, wide-scale adoption of these methods in real-world domains is made difficult by their poor sample efficiency. We address this problem both theoretically and empirically. On the theoretical side, we identify two phenomena preventing efficient exploration in existing state-of-the-art algorithms such as Soft Actor Critic. First, combining a greedy actor update with a pessimistic estimate of the critic leads to the avoidance of actions that the agent does not know about, a phenomenon we call pessimistic underexploration. Second, current algorithms are directionally uninformed, sampling actions with equal probability in opposite directions from the current mean. This is wasteful, since we typically need actions taken along certain directions much more than others. To address both of these phenomena, we introduce a new algorithm, Optimistic Actor Critic, which approximates a lower and upper confidence bound on the state-action value function. This allows us to apply the principle of optimism in the face of uncertainty to perform directed exploration using the upper bound while still using the lower bound to avoid overestimation. We evaluate OAC in several challenging continuous control tasks, achieving state-of the art sample efficiency.
* 20 pages (including supplement)
Variational Integrator Networks for Physically Meaningful Embeddings
Oct 21, 2019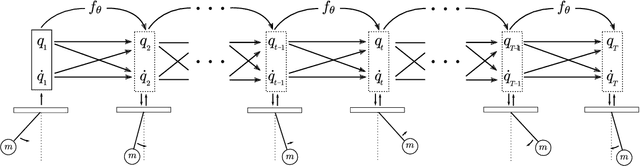
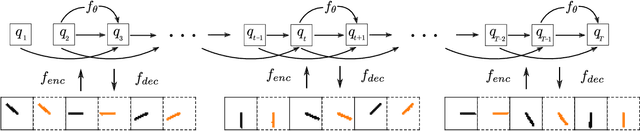
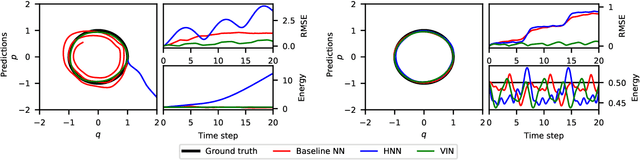
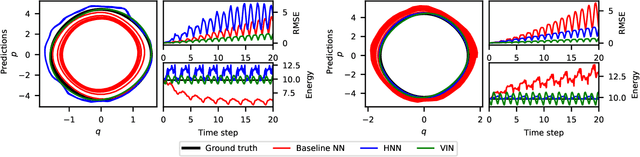
Learning workable representations of dynamical systems is becoming an increasingly important problem in a number of application areas. By leveraging recent work connecting deep neural networks to systems of differential equations, we propose variational integrator networks, a class of neural network architectures designed to ensure faithful representations of the dynamics under study. This class of network architectures facilitates accurate long-term prediction, interpretability, and data-efficient learning, while still remaining highly flexible and capable of modeling complex behavior. We demonstrate that they can accurately learn dynamical systems from both noisy observations in phase space and from image pixels within which the unknown dynamics are embedded.