 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-Source Multi-Viewpoint Surgical Telerobotics
May 16, 2025As robots for minimally invasive surgery (MIS) gradually become more accessible and modular, we believe there is a great opportunity to rethink and expand the visualization and control paradigms that have characterized surgical teleoperation since its inception. We conjecture that introducing one or more additional adjustable viewpoints in the abdominal cavity would not only unlock novel visualization and collaboration strategies for surgeons but also substantially boost the robustness of machine perception toward shared autonomy. Immediate advantages include controlling a second viewpoint and teleoperating surgical tools from a different perspective, which would allow collaborating surgeons to adjust their views independently and still maneuver their robotic instruments intuitively. Furthermore, we believe that capturing synchronized multi-view 3D measurements of the patient's anatomy would unlock advanced scene representations. Accurate real-time intraoperative 3D perception will allow algorithmic assistants to directly control one or more robotic instruments and/or robotic cameras. Toward these goals, we are building a synchronized multi-viewpoint, multi-sensor robotic surgery system by integrating high-performance vision components and upgrading the da Vinci Research Kit control logic. This short paper reports a functional summary of our setup and elaborates on its potential impacts in research and future clinical practice. By fully open-sourcing our system, we will enable the research community to reproduce our setup, improve it, and develop powerful algorithms, effectively boosting clinical translation of cutting-edge research.
Supervising 3D Talking Head Avatars with Analysis-by-Audio-Synthesis
Apr 18, 2025



In order to be widely applicable, speech-driven 3D head avatars must articulate their lips in accordance with speech, while also conveying the appropriate emotions with dynamically changing facial expressions. The key problem is that deterministic models produce high-quality lip-sync but without rich expressions, whereas stochastic models generate diverse expressions but with lower lip-sync quality. To get the best of both, we seek a stochastic model with accurate lip-sync. To that end, we develop a new approach based on the following observation: if a method generates realistic 3D lip motions, it should be possible to infer the spoken audio from the lip motion. The inferred speech should match the original input audio, and erroneous predictions create a novel supervision signal for training 3D talking head avatars with accurate lip-sync. To demonstrate this effect, we propose THUNDER (Talking Heads Under Neural Differentiable Elocution Reconstruction), a 3D talking head avatar framework that introduces a novel supervision mechanism via differentiable sound production. First, we train a novel mesh-to-speech model that regresses audio from facial animation. Then, we incorporate this model into a diffusion-based talking avatar framework. During training, the mesh-to-speech model takes the generated animation and produces a sound that is compared to the input speech, creating a differentiable analysis-by-audio-synthesis supervision loop. Our extensive qualitative and quantitative experiments demonstrate that THUNDER significantly improves the quality of the lip-sync of talking head avatars while still allowing for generation of diverse, high-quality, expressive facial animations.
Capturing and Inferring Dense Full-Body Human-Scene Contact
Jun 20, 2022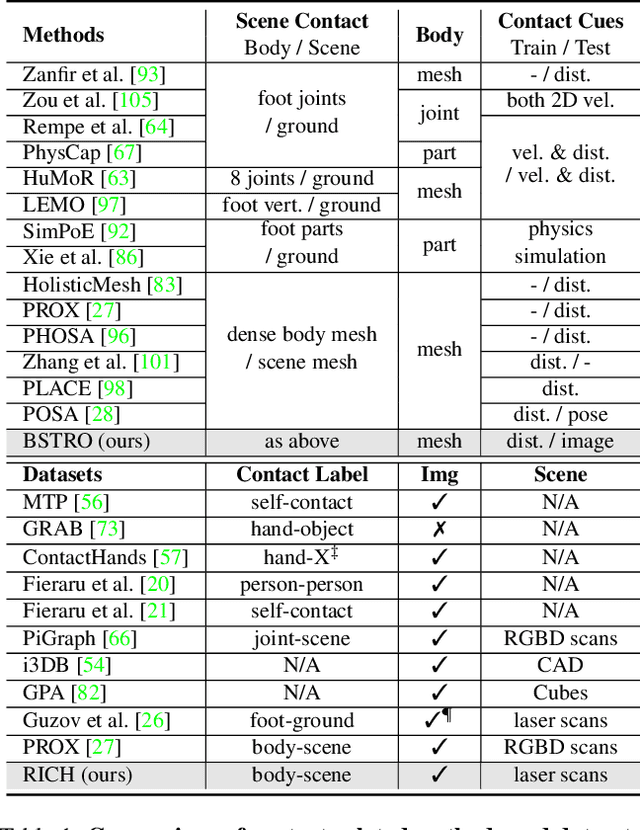
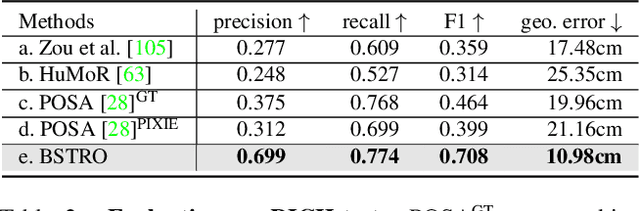
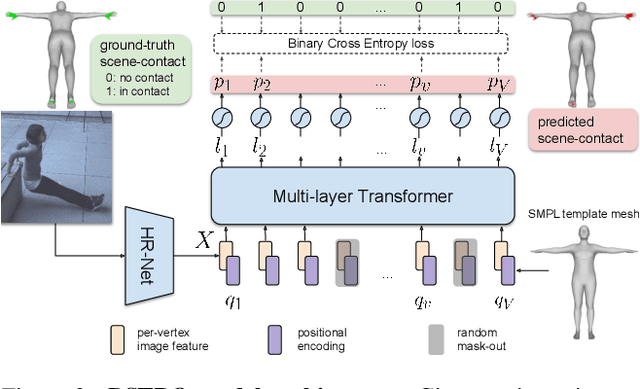
Inferring human-scene contact (HSC) is the first step toward understanding how humans interact with their surroundings. While detecting 2D human-object interaction (HOI) and reconstructing 3D human pose and shape (HPS) have enjoyed significant progress, reasoning about 3D human-scene contact from a single image is still challenging. Existing HSC detection methods consider only a few types of predefined contact, often reduce body and scene to a small number of primitives, and even overlook image evidence. To predict human-scene contact from a single image, we address the limitations above from both data and algorithmic perspectives. We capture a new dataset called RICH for "Real scenes, Interaction, Contact and Humans." RICH contains multiview outdoor/indoor video sequences at 4K resolution, ground-truth 3D human bodies captured using markerless motion capture, 3D body scans, and high resolution 3D scene scans. A key feature of RICH is that it also contains accurate vertex-level contact labels on the body. Using RICH, we train a network that predicts dense body-scene contacts from a single RGB image. Our key insight is that regions in contact are always occluded so the network needs the ability to explore the whole image for evidence. We use a transformer to learn such non-local relationships and propose a new Body-Scene contact TRansfOrmer (BSTRO). Very few methods explore 3D contact; those that do focus on the feet only, detect foot contact as a post-processing step, or infer contact from body pose without looking at the scene. To our knowledge, BSTRO is the first method to directly estimate 3D body-scene contact from a single image. We demonstrate that BSTRO significantly outperforms the prior art. The code and dataset are available at https://rich.is.tue.mpg.de.