 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeurIPS 2020 NLC2CMD Competition: Translating Natural Language to Bash Commands
Mar 03, 2021
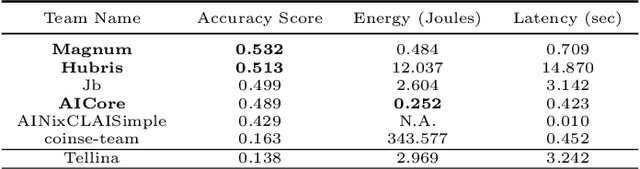

The NLC2CMD Competition hosted at NeurIPS 2020 aimed to bring the power of natural language processing to the command line. Participants were tasked with building models that can transform descriptions of command line tasks in English to their Bash syntax. This is a report on the competition with details of the task, metrics, data, attempted solutions, and lessons learned.
VisualHints: A Visual-Lingual Environment for Multimodal Reinforcement Learning
Oct 26, 2020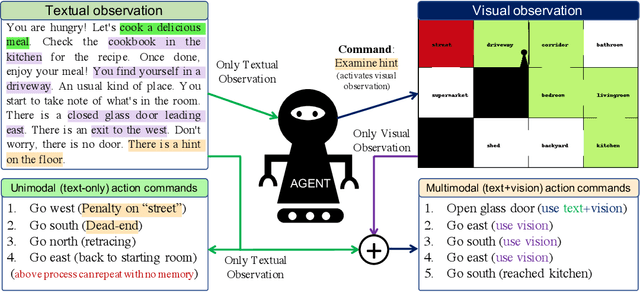
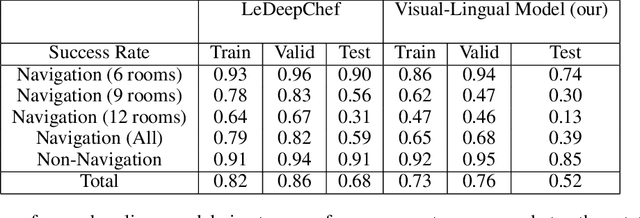
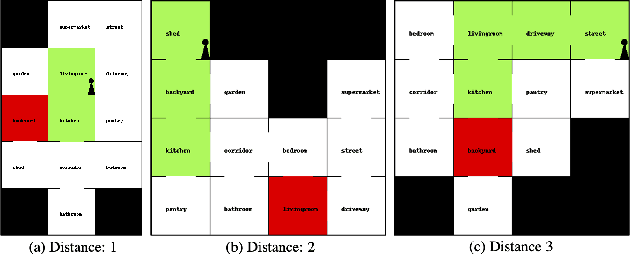
We present VisualHints, a novel environment for multimodal reinforcement learning (RL) involving text-based interactions along with visual hints (obtained from the environment). Real-life problems often demand that agents interact with the environment using both natural language information and visual perception towards solving a goal. However, most traditional RL environments either solve pure vision-based tasks like Atari games or video-based robotic manipulation; or entirely use natural language as a mode of interaction, like Text-based games and dialog systems. In this work, we aim to bridge this gap and unify these two approaches in a single environment for multimodal RL. We introduce an extension of the TextWorld cooking environment with the addition of visual clues interspersed throughout the environment. The goal is to force an RL agent to use both text and visual features to predict natural language action commands for solving the final task of cooking a meal. We enable variations and difficulties in our environment to emulate various interactive real-world scenarios. We present a baseline multimodal agent for solving such problems using CNN-based feature extraction from visual hints and LSTMs for textual feature extraction. We believe that our proposed visual-lingual environment will facilitate novel problem settings for the RL community.
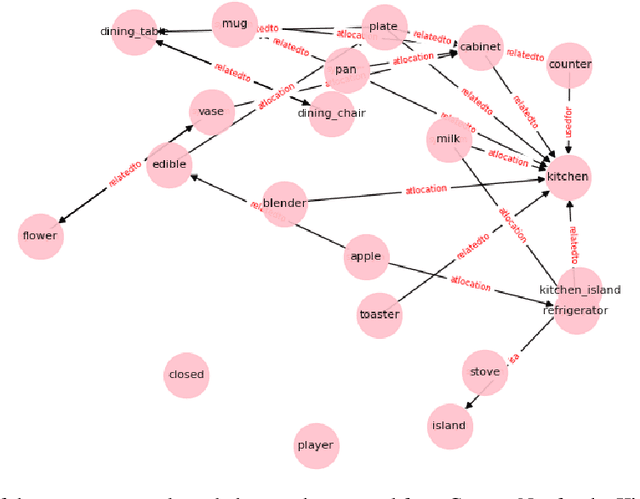
Text-based RL Agents with Commonsense Knowledge: New Challenges, Environments and Baselines
Oct 08, 2020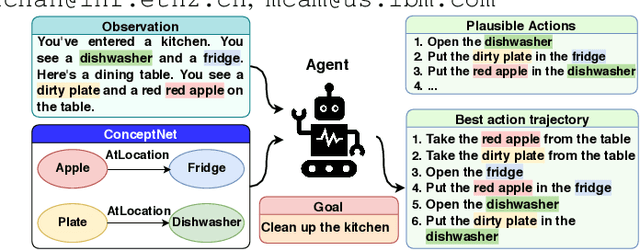


Text-based games have emerged as an important test-bed for Reinforcement Learning (RL) research, requiring RL agents to combine grounded language understanding with sequential decision making. In this paper, we examine the problem of infusing RL agents with commonsense knowledge. Such knowledge would allow agents to efficiently act in the world by pruning out implausible actions, and to perform look-ahead planning to determine how current actions might affect future world states. We design a new text-based gaming environment called TextWorld Commonsense (TWC) for training and evaluating RL agents with a specific kind of commonsense knowledge about objects, their attributes, and affordances. We also introduce several baseline RL agents which track the sequential context and dynamically retrieve the relevant commonsense knowledge from ConceptNet. We show that agents which incorporate commonsense knowledge in TWC perform better, while acting more efficiently. We conduct user-studies to estimate human performance on TWC and show that there is ample room for future improvement.
Reading Comprehension as Natural Language Inference: A Semantic Analysis
Oct 04, 2020
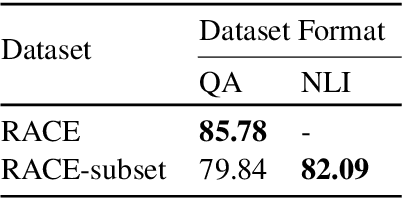
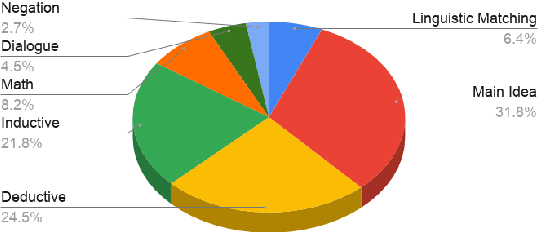
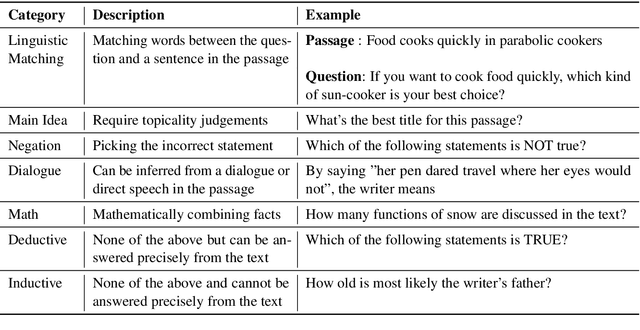
In the recent past, Natural language Inference (NLI) has gained significant attention, particularly given its promise for downstream NLP tasks. However, its true impact is limited and has not been well studied. Therefore, in this paper, we explore the utility of NLI for one of the most prominent downstream tasks, viz. Question Answering (QA). We transform the one of the largest available MRC dataset (RACE) to an NLI form, and compare the performances of a state-of-the-art model (RoBERTa) on both these forms. We propose new characterizations of questions, and evaluate the performance of QA and NLI models on these categories. We highlight clear categories for which the model is able to perform better when the data is presented in a coherent entailment form, and a structured question-answer concatenation form, respectively.
Bootstrapped Q-learning with Context Relevant Observation Pruning to Generalize in Text-based Games
Sep 24, 2020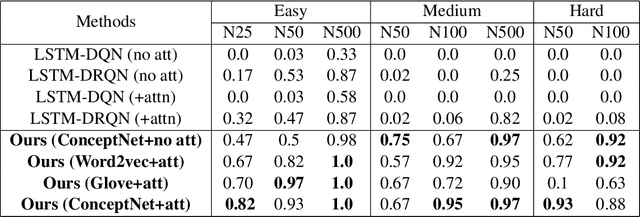
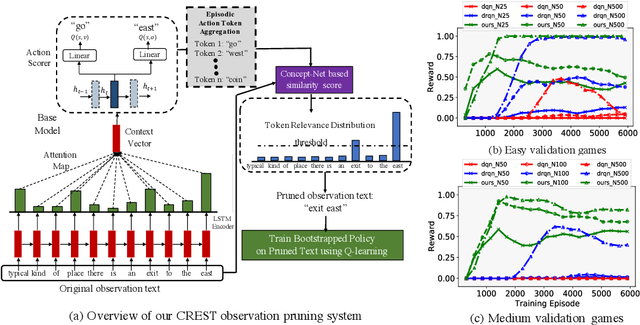
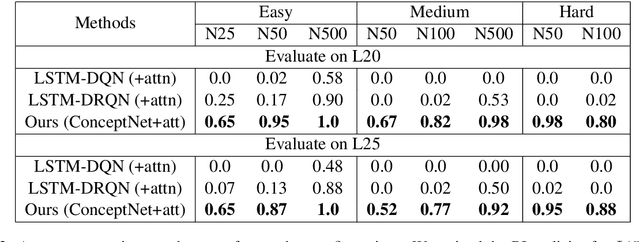
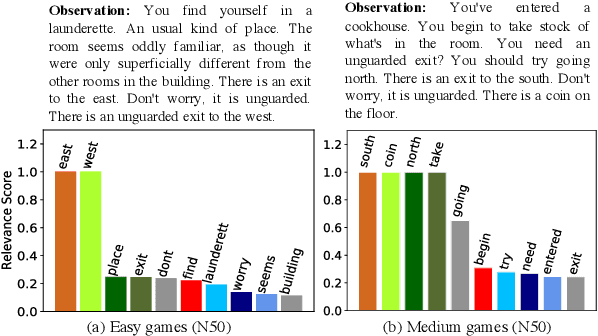
We show that Reinforcement Learning (RL) methods for solving Text-Based Games (TBGs) often fail to generalize on unseen games, especially in small data regimes. To address this issue, we propose Context Relevant Episodic State Truncation (CREST) for irrelevant token removal in observation text for improved generalization. Our method first trains a base model using Q-learning, which typically overfits the training games. The base model's action token distribution is used to perform observation pruning that removes irrelevant tokens. A second bootstrapped model is then retrained on the pruned observation text. Our bootstrapped agent shows improved generalization in solving unseen TextWorld games, using 10x-20x fewer training games compared to previous state-of-the-art methods despite requiring less number of training episodes.
Looking Beyond Sentence-Level Natural Language Inference for Downstream Tasks
Sep 18, 2020
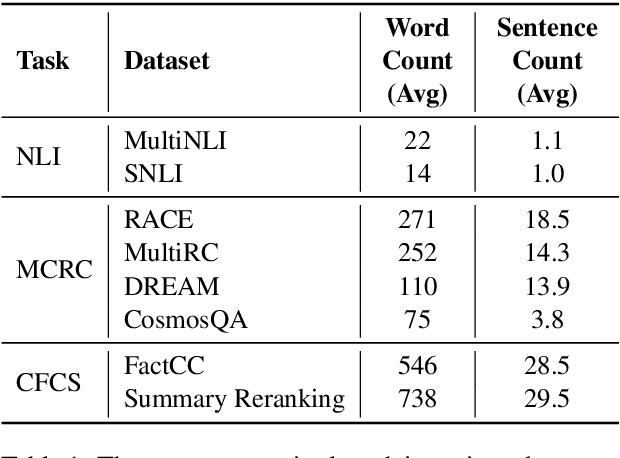
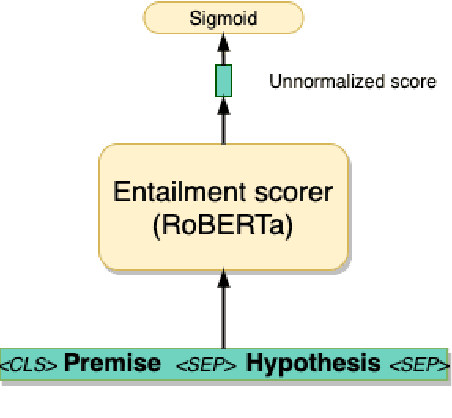
In recent years, the Natural Language Inference (NLI) task has garnered significant attention, with new datasets and models achieving near human-level performance on it. However, the full promise of NLI -- particularly that it learns knowledge that should be generalizable to other downstream NLP tasks -- has not been realized. In this paper, we study this unfulfilled promise from the lens of two downstream tasks: question answering (QA), and text summarization. We conjecture that a key difference between the NLI datasets and these downstream tasks concerns the length of the premise; and that creating new long premise NLI datasets out of existing QA datasets is a promising avenue for training a truly generalizable NLI model. We validate our conjecture by showing competitive results on the task of QA and obtaining the best reported results on the task of Checking Factual Correctness of Summaries.
Type-augmented Relation Prediction in Knowledge Graphs
Sep 16, 2020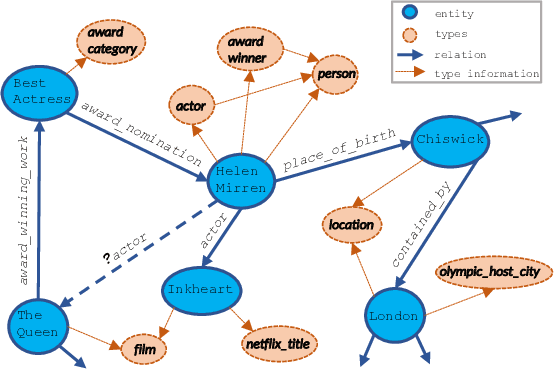

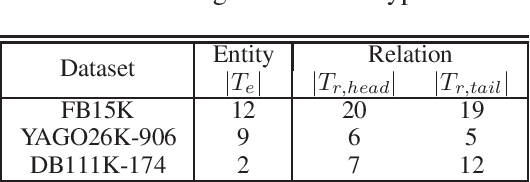
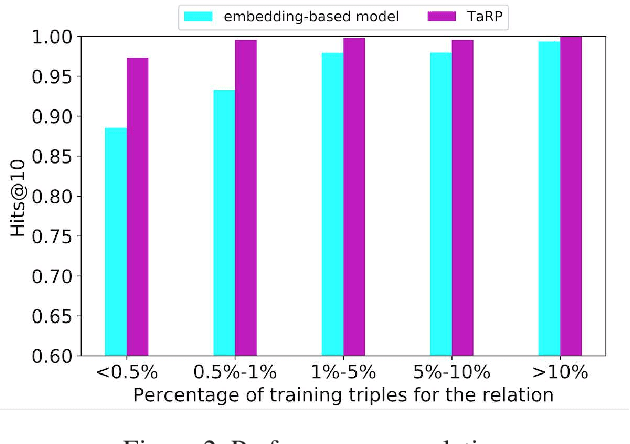
Knowledge graphs (KGs) are of great importance to many real world applications, but they generally suffer from incomplete information in the form of missing relations between entities. Knowledge graph completion (also known as relation prediction) is the task of inferring missing facts given existing ones. Most of the existing work is proposed by maximizing the likelihood of observed instance-level triples. Not much attention, however, is paid to the ontological information, such as type information of entities and relations. In this work, we propose a type-augmented relation prediction (TaRP) method, where we apply both the type information and instance-level information for relation prediction. In particular, type information and instance-level information are encoded as prior probabilities and likelihoods of relations respectively, and are combined by following Bayes' rule. Our proposed TaRP method achieves significantly better performance than state-of-the-art methods on three benchmark datasets: FB15K, YAGO26K-906, and DB111K-174. In addition, we show that TaRP achieves significantly improved data efficiency. More importantly, the type information extracted from a specific dataset can generalize well to other datasets through the proposed TaRP model.
An Atlas of Cultural Commonsense for Machine Reasoning
Sep 11, 2020



Existing commonsense reasoning datasets for AI and NLP tasks fail to address an important aspect of human life: cultural differences. In this work, we introduce an approach that extends prior work on crowdsourcing commonsense knowledge by incorporating differences in knowledge that are attributable to cultural or national groups. We demonstrate the technique by collecting commonsense knowledge that surrounds three fairly universal rituals---coming-of-age, marriage, and funerals---across three different national groups: the United States, India, and the Philippines. Our pilot study expands the different types of relationships identified by existing work in the field of commonsense reasoning for commonplace events, and uses these new types to gather information that distinguishes the knowledge of the different groups. It also moves us a step closer towards building a machine that doesn't assume a rigid framework of universal (and likely Western-biased) commonsense knowledge, but rather has the ability to reason in a contextually and culturally sensitive way. Our hope is that cultural knowledge of this sort will lead to more human-like performance in NLP tasks such as question answering (QA) and text understanding and generation.
Enhancing Text-based Reinforcement Learning Agents with Commonsense Knowledge
May 02, 2020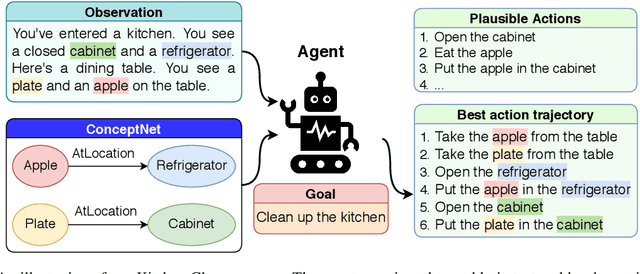
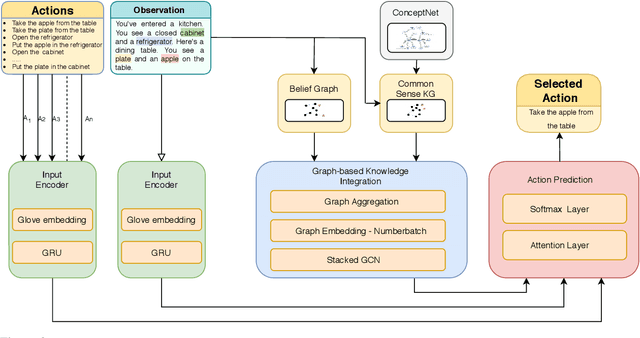
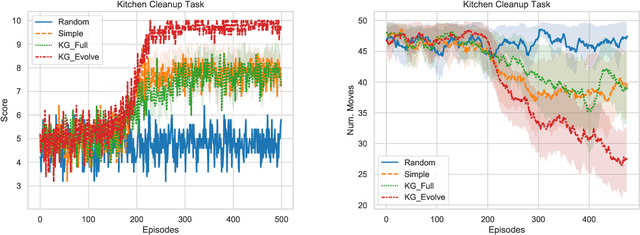
In this paper, we consider the recent trend of evaluating progress on reinforcement learning technology by using text-based environments and games as evaluation environments. This reliance on text brings advances in natural language processing into the ambit of these agents, with a recurring thread being the use of external knowledge to mimic and better human-level performance. We present one such instantiation of agents that use commonsense knowledge from ConceptNet to show promising performance on two text-based environments.
CLAI: A Platform for AI Skills on the Command Line
Jan 31, 2020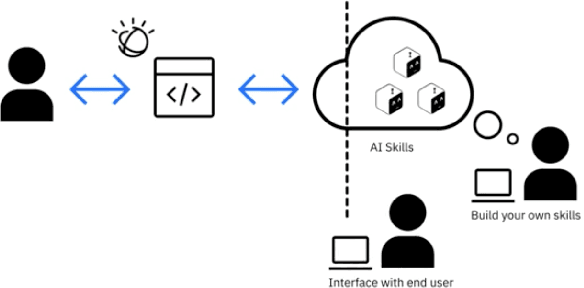

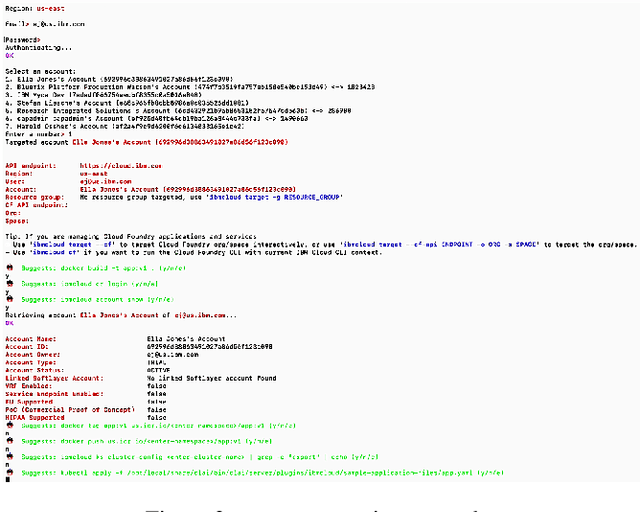
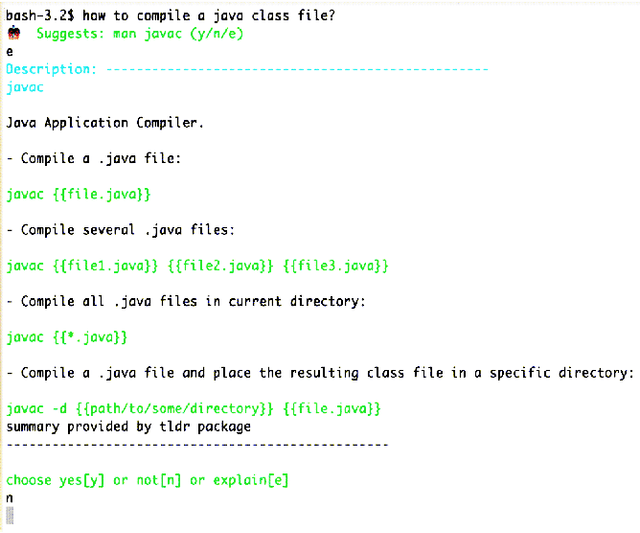
This paper reports on the open source project CLAI (Command Line AI), aimed at bringing the power of AI to the command line interface. The platform sets up the CLI as a new environment for AI researchers to conquer by surfacing the command line as a generic environment that researchers can interface to using a simple sense-act API much like the traditional AI agent architecture. In this paper, we discuss the design and implementation of the platform in detail, through illustrative use cases of new end user interaction patterns enabled by this design, and through quantitative evaluation of the system footprint of a CLAI-enabled terminal. We also report on some early user feedback on its features from an internal survey.