 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHERAKLES: Hierarchical Skill Compilation for Open-ended LLM Agents
Aug 20, 2025



Open-ended AI agents need to be able to learn efficiently goals of increasing complexity, abstraction and heterogeneity over their lifetime. Beyond sampling efficiently their own goals, autotelic agents specifically need to be able to keep the growing complexity of goals under control, limiting the associated growth in sample and computational complexity. To adress this challenge, recent approaches have leveraged hierarchical reinforcement learning (HRL) and language, capitalizing on its compositional and combinatorial generalization capabilities to acquire temporally extended reusable behaviours. Existing approaches use expert defined spaces of subgoals over which they instantiate a hierarchy, and often assume pre-trained associated low-level policies. Such designs are inadequate in open-ended scenarios, where goal spaces naturally diversify across a broad spectrum of difficulties. We introduce HERAKLES, a framework that enables a two-level hierarchical autotelic agent to continuously compile mastered goals into the low-level policy, executed by a small, fast neural network, dynamically expanding the set of subgoals available to the high-level policy. We train a Large Language Model (LLM) to serve as the high-level controller, exploiting its strengths in goal decomposition and generalization to operate effectively over this evolving subgoal space. We evaluate HERAKLES in the open-ended Crafter environment and show that it scales effectively with goal complexity, improves sample efficiency through skill compilation, and enables the agent to adapt robustly to novel challenges over time.
WorldLLM: Improving LLMs' world modeling using curiosity-driven theory-making
Jun 07, 2025



Large Language Models (LLMs) possess general world knowledge but often struggle to generate precise predictions in structured, domain-specific contexts such as simulations. These limitations arise from their inability to ground their broad, unstructured understanding in specific environments. To address this, we present WorldLLM, a framework that enhances LLM-based world modeling by combining Bayesian inference and autonomous active exploration with reinforcement learning. WorldLLM leverages the in-context learning abilities of LLMs to guide an LLM-based world model's predictions using natural language hypotheses given in its prompt. These hypotheses are iteratively refined through a Bayesian inference framework that leverages a second LLM as the proposal distribution given collected evidence. This evidence is collected using a curiosity-driven reinforcement learning policy that explores the environment to find transitions with a low log-likelihood under our LLM-based predictive model using the current hypotheses. By alternating between refining hypotheses and collecting new evidence, our framework autonomously drives continual improvement of the predictions. Our experiments demonstrate the effectiveness of WorldLLM in a textual game environment that requires agents to manipulate and combine objects. The framework not only enhances predictive accuracy, but also generates human-interpretable theories of environment dynamics.
MAGELLAN: Metacognitive predictions of learning progress guide autotelic LLM agents in large goal spaces
Feb 12, 2025



Open-ended learning agents must efficiently prioritize goals in vast possibility spaces, focusing on those that maximize learning progress (LP). When such autotelic exploration is achieved by LLM agents trained with online RL in high-dimensional and evolving goal spaces, a key challenge for LP prediction is modeling one's own competence, a form of metacognitive monitoring. Traditional approaches either require extensive sampling or rely on brittle expert-defined goal groupings. We introduce MAGELLAN, a metacognitive framework that lets LLM agents learn to predict their competence and LP online. By capturing semantic relationships between goals, MAGELLAN enables sample-efficient LP estimation and dynamic adaptation to evolving goal spaces through generalization. In an interactive learning environment, we show that MAGELLAN improves LP prediction efficiency and goal prioritization, being the only method allowing the agent to fully master a large and evolving goal space. These results demonstrate how augmenting LLM agents with a metacognitive ability for LP predictions can effectively scale curriculum learning to open-ended goal spaces.
Reinforcement Learning for Aligning Large Language Models Agents with Interactive Environments: Quantifying and Mitigating Prompt Overfitting
Oct 29, 2024



Reinforcement learning (RL) is a promising approach for aligning large language models (LLMs) knowledge with sequential decision-making tasks. However, few studies have thoroughly investigated the impact on LLM agents capabilities of fine-tuning them with RL in a specific environment. In this paper, we propose a novel framework to analyze the sensitivity of LLMs to prompt formulations following RL training in a textual environment. Our findings reveal that the performance of LLMs degrades when faced with prompt formulations different from those used during the RL training phase. Besides, we analyze the source of this sensitivity by examining the model's internal representations and salient tokens. Finally, we propose to use a contrastive loss to mitigate this sensitivity and improve the robustness and generalization capabilities of LLMs.
SAC-GLAM: Improving Online RL for LLM agents with Soft Actor-Critic and Hindsight Relabeling
Oct 16, 2024



The past years have seen Large Language Models (LLMs) strive not only as generative models but also as agents solving textual sequential decision-making tasks. When facing complex environments where their zero-shot abilities are insufficient, recent work showed online Reinforcement Learning (RL) could be used for the LLM agent to discover and learn efficient strategies interactively. However, most prior work sticks to on-policy algorithms, which greatly reduces the scope of methods such agents could use for both exploration and exploitation, such as experience replay and hindsight relabeling. Yet, such methods may be key for LLM learning agents, and in particular when designing autonomous intrinsically motivated agents sampling and pursuing their own goals (i.e. autotelic agents). This paper presents and studies an adaptation of Soft Actor-Critic and hindsight relabeling to LLM agents. Our method not only paves the path towards autotelic LLM agents that learn online but can also outperform on-policy methods in more classic multi-goal RL environments.
Grounding Large Language Models in Interactive Environments with Online Reinforcement Learning
Feb 06, 2023



Recent works successfully leveraged Large Language Models' (LLM) abilities to capture abstract knowledge about world's physics to solve decision-making problems. Yet, the alignment between LLMs' knowledge and the environment can be wrong and limit functional competence due to lack of grounding. In this paper, we study an approach to achieve this alignment through functional grounding: we consider an agent using an LLM as a policy that is progressively updated as the agent interacts with the environment, leveraging online Reinforcement Learning to improve its performance to solve goals. Using an interactive textual environment designed to study higher-level forms of functional grounding, and a set of spatial and navigation tasks, we study several scientific questions: 1) Can LLMs boost sample efficiency for online learning of various RL tasks? 2) How can it boost different forms of generalization? 3) What is the impact of online learning? We study these questions by functionally grounding several variants (size, architecture) of FLAN-T5.
EAGER: Asking and Answering Questions for Automatic Reward Shaping in Language-guided RL
Jun 20, 2022

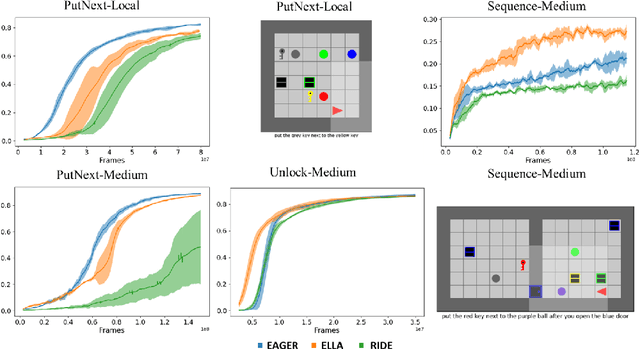

Reinforcement learning (RL) in long horizon and sparse reward tasks is notoriously difficult and requires a lot of training steps. A standard solution to speed up the process is to leverage additional reward signals, shaping it to better guide the learning process. In the context of language-conditioned RL, the abstraction and generalisation properties of the language input provide opportunities for more efficient ways of shaping the reward. In this paper, we leverage this idea and propose an automated reward shaping method where the agent extracts auxiliary objectives from the general language goal. These auxiliary objectives use a question generation (QG) and question answering (QA) system: they consist of questions leading the agent to try to reconstruct partial information about the global goal using its own trajectory. When it succeeds, it receives an intrinsic reward proportional to its confidence in its answer. This incentivizes the agent to generate trajectories which unambiguously explain various aspects of the general language goal. Our experimental study shows that this approach, which does not require engineer intervention to design the auxiliary objectives, improves sample efficiency by effectively directing exploration.
VisualHints: A Visual-Lingual Environment for Multimodal Reinforcement Learning
Oct 26, 2020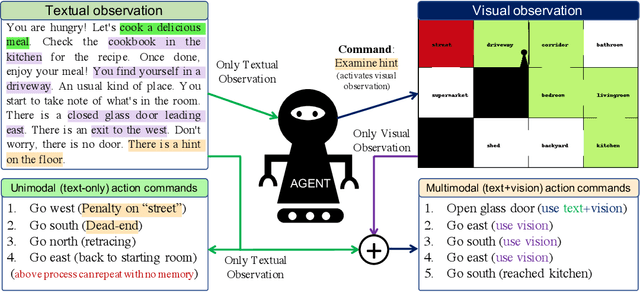
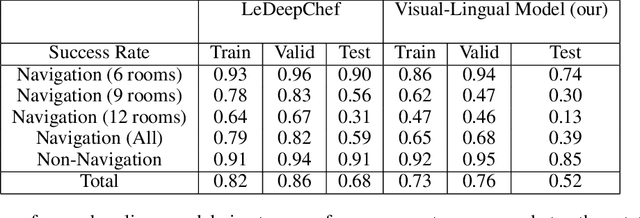
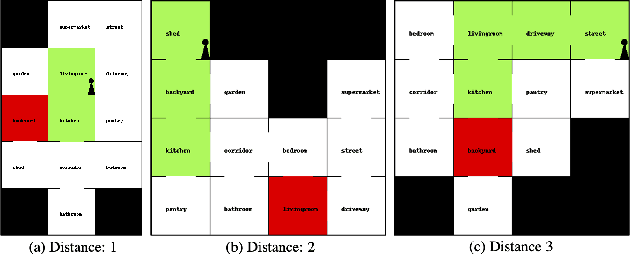
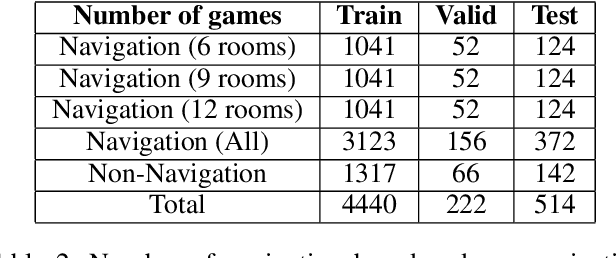
We present VisualHints, a novel environment for multimodal reinforcement learning (RL) involving text-based interactions along with visual hints (obtained from the environment). Real-life problems often demand that agents interact with the environment using both natural language information and visual perception towards solving a goal. However, most traditional RL environments either solve pure vision-based tasks like Atari games or video-based robotic manipulation; or entirely use natural language as a mode of interaction, like Text-based games and dialog systems. In this work, we aim to bridge this gap and unify these two approaches in a single environment for multimodal RL. We introduce an extension of the TextWorld cooking environment with the addition of visual clues interspersed throughout the environment. The goal is to force an RL agent to use both text and visual features to predict natural language action commands for solving the final task of cooking a meal. We enable variations and difficulties in our environment to emulate various interactive real-world scenarios. We present a baseline multimodal agent for solving such problems using CNN-based feature extraction from visual hints and LSTMs for textual feature extraction. We believe that our proposed visual-lingual environment will facilitate novel problem settings for the RL community.