 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Segmentation as Semantic-Based Regularization
May 13, 2026Weakly supervised semantic segmentation (WSSS) trains dense pixel-level segmentation models from partial or coarse annotations such as bounding boxes, scribbles, or image-level tags. While recent work leverages foundation models such as the Segment Anything Model (SAM) to generate pseudo-labels, these approaches typically depend on heuristic prompt choices and offer limited ways to incorporate prior knowledge or heterogeneous labels. We address this gap by taking a neurosymbolic perspective: integrating differentiable fuzzy logic with deep segmentation models. Weak annotations and domain-specific priors are unified as continuous logical constraints that fine-tune SAM under weak supervision. The refined foundation model then produces improved pseudo-labels, from which we train a second-stage prompt-free segmentation model. Experiments on Pascal VOC 2012 and the REFUGE2 optic disc/cup segmentation dataset show that our logic-guided fine-tuning yields higher-quality pseudo-labels, leading to state-of-the-art segmentation accuracy that often exceeds densely supervised baselines.
ExplainFuzz: Explainable and Constraint-Conditioned Test Generation with Probabilistic Circuits
Apr 08, 2026Understanding and explaining the structure of generated test inputs is essential for effective software testing and debugging. Existing approaches--including grammar-based fuzzers, probabilistic Context-Free Grammars (pCFGs), and Large Language Models (LLMs)--suffer from critical limitations. They frequently produce ill-formed inputs that fail to reflect realistic data distributions, struggle to capture context-sensitive probabilistic dependencies, and lack explainability. We introduce ExplainFuzz, a test generation framework that leverages Probabilistic Circuits (PCs) to learn and query structured distributions over grammar-based test inputs interpretably and controllably. Starting from a Context-Free Grammar (CFG), ExplainFuzz compiles a grammar-aware PC and trains it on existing inputs. New inputs are then generated via sampling. ExplainFuzz utilizes the conditioning capability of PCs to incorporate test-specific constraints (e.g., a query must have GROUP BY), enabling constrained probabilistic sampling to generate inputs satisfying grammar and user-provided constraints. Our results show that ExplainFuzz improves the coherence and realism of generated inputs, achieving significant perplexity reduction compared to pCFGs, grammar-unaware PCs, and LLMs. By leveraging its native conditioning capability, ExplainFuzz significantly enhances the diversity of inputs that satisfy a user-provided constraint. Compared to grammar-aware mutational fuzzing, ExplainFuzz increases bug-triggering rates from 35% to 63% in SQL and from 10% to 100% in XML. These results demonstrate the power of a learned input distribution over mutational fuzzing, which is often limited to exploring the local neighborhood of seed inputs. These capabilities highlight the potential of PCs to serve as a foundation for grammar-aware, controllable test generation that captures context-sensitive, probabilistic dependencies.
The Gradient of Algebraic Model Counting
Feb 25, 2025Algebraic model counting unifies many inference tasks on logic formulas by exploiting semirings. Rather than focusing on inference, we consider learning, especially in statistical-relational and neurosymbolic AI, which combine logical, probabilistic and neural representations. Concretely, we show that the very same semiring perspective of algebraic model counting also applies to learning. This allows us to unify various learning algorithms by generalizing gradients and backpropagation to different semirings. Furthermore, we show how cancellation and ordering properties of a semiring can be exploited for more memory-efficient backpropagation. This allows us to obtain some interesting variations of state-of-the-art gradient-based optimisation methods for probabilistic logical models. We also discuss why algebraic model counting on tractable circuits does not lead to more efficient second-order optimization. Empirically, our algebraic backpropagation exhibits considerable speed-ups as compared to existing approaches.
KLay: Accelerating Neurosymbolic AI
Oct 15, 2024



A popular approach to neurosymbolic AI involves mapping logic formulas to arithmetic circuits (computation graphs consisting of sums and products) and passing the outputs of a neural network through these circuits. This approach enforces symbolic constraints onto a neural network in a principled and end-to-end differentiable way. Unfortunately, arithmetic circuits are challenging to run on modern AI accelerators as they exhibit a high degree of irregular sparsity. To address this limitation, we introduce knowledge layers (KLay), a new data structure to represent arithmetic circuits that can be efficiently parallelized on GPUs. Moreover, we contribute two algorithms used in the translation of traditional circuit representations to KLay and a further algorithm that exploits parallelization opportunities during circuit evaluations. We empirically show that KLay achieves speedups of multiple orders of magnitude over the state of the art, thereby paving the way towards scaling neurosymbolic AI to larger real-world applications.
Extracting Finite State Machines from Transformers
Oct 08, 2024



Fueled by the popularity of the transformer architecture in deep learning, several works have investigated what formal languages a transformer can learn. Nonetheless, existing results remain hard to compare and a fine-grained understanding of the trainability of transformers on regular languages is still lacking. We investigate transformers trained on regular languages from a mechanistic interpretability perspective. Using an extension of the $L^*$ algorithm, we extract Moore machines from transformers. We empirically find tighter lower bounds on the trainability of transformers, when a finite number of symbols determine the state. Additionally, our mechanistic insight allows us to characterise the regular languages a one-layer transformer can learn with good length generalisation. However, we also identify failure cases where the determining symbols get misrecognised due to saturation of the attention mechanism.
On the Hardness of Probabilistic Neurosymbolic Learning
Jun 06, 2024The limitations of purely neural learning have sparked an interest in probabilistic neurosymbolic models, which combine neural networks with probabilistic logical reasoning. As these neurosymbolic models are trained with gradient descent, we study the complexity of differentiating probabilistic reasoning. We prove that although approximating these gradients is intractable in general, it becomes tractable during training. Furthermore, we introduce WeightME, an unbiased gradient estimator based on model sampling. Under mild assumptions, WeightME approximates the gradient with probabilistic guarantees using a logarithmic number of calls to a SAT solver. Lastly, we evaluate the necessity of these guarantees on the gradient. Our experiments indicate that the existing biased approximations indeed struggle to optimize even when exact solving is still feasible.
Towards Understanding Iterative Magnitude Pruning: Why Lottery Tickets Win
Jun 13, 2021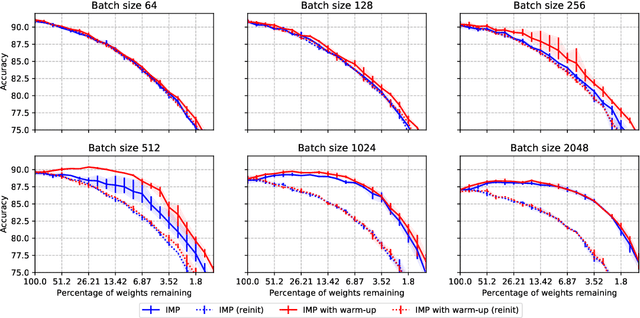
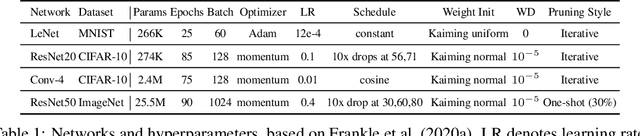
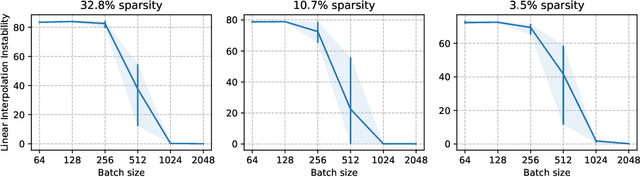
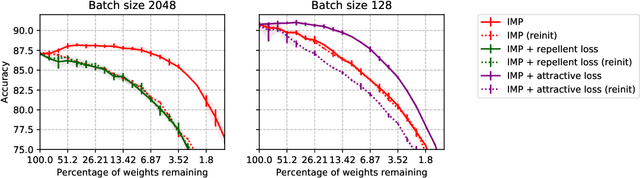
The lottery ticket hypothesis states that sparse subnetworks exist in randomly initialized dense networks that can be trained to the same accuracy as the dense network they reside in. However, the subsequent work has failed to replicate this on large-scale models and required rewinding to an early stable state instead of initialization. We show that by using a training method that is stable with respect to linear mode connectivity, large networks can also be entirely rewound to initialization. Our subsequent experiments on common vision tasks give strong credence to the hypothesis in Evci et al. (2020b) that lottery tickets simply retrain to the same regions (although not necessarily to the same basin). These results imply that existing lottery tickets could not have been found without the preceding dense training by iterative magnitude pruning, raising doubts about the use of the lottery ticket hypothesis.
NeurIPS 2020 NLC2CMD Competition: Translating Natural Language to Bash Commands
Mar 03, 2021
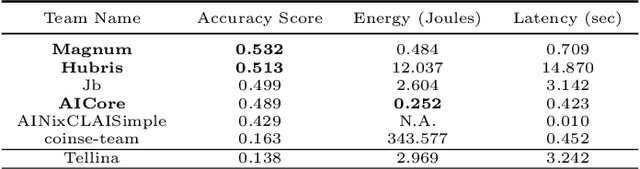

The NLC2CMD Competition hosted at NeurIPS 2020 aimed to bring the power of natural language processing to the command line. Participants were tasked with building models that can transform descriptions of command line tasks in English to their Bash syntax. This is a report on the competition with details of the task, metrics, data, attempted solutions, and lessons learned.