 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixels Don't Lie (But Your Detector Might): Bootstrapping MLLM-as-a-Judge for Trustworthy Deepfake Detection and Reasoning Supervision
Feb 23, 2026Deepfake detection models often generate natural-language explanations, yet their reasoning is frequently ungrounded in visual evidence, limiting reliability. Existing evaluations measure classification accuracy but overlook reasoning fidelity. We propose DeepfakeJudge, a framework for scalable reasoning supervision and evaluation, that integrates an out-of-distribution benchmark containing recent generative and editing forgeries, a human-annotated subset with visual reasoning labels, and a suite of evaluation models, that specialize in evaluating reasoning rationales without the need for explicit ground truth reasoning rationales. The Judge is optimized through a bootstrapped generator-evaluator process that scales human feedback into structured reasoning supervision and supports both pointwise and pairwise evaluation. On the proposed meta-evaluation benchmark, our reasoning-bootstrapped model achieves an accuracy of 96.2\%, outperforming \texttt{30x} larger baselines. The reasoning judge attains very high correlation with human ratings and 98.9\% percent pairwise agreement on the human-annotated meta-evaluation subset. These results establish reasoning fidelity as a quantifiable dimension of deepfake detection and demonstrate scalable supervision for interpretable deepfake reasoning. Our user study shows that participants preferred the reasonings generated by our framework 70\% of the time, in terms of faithfulness, groundedness, and usefulness, compared to those produced by other models and datasets. All of our datasets, models, and codebase are \href{https://github.com/KjAeRsTuIsK/DeepfakeJudge}{open-sourced}.
CETBench: A Novel Dataset constructed via Transformations over Programs for Benchmarking LLMs for Code-Equivalence Checking
Jun 04, 2025



LLMs have been extensively used for the task of automated code generation. In this work, we examine the applicability of LLMs for the related but relatively unexplored task of code-equivalence checking, i.e., given two programs, whether they are functionally equivalent or not. This is an important problem since benchmarking code equivalence can play a critical role in evaluating LLM capabilities for tasks such as code re-writing and code translation. Towards this end, we present CETBench - Code Equivalence with Transformations Benchmark, constructed via a repository of programs, where two programs in the repository may be solving the same or different tasks. Each instance in our dataset is obtained by taking a pair of programs in the repository and applying a random series of pre-defined code transformations, resulting in (non-)equivalent pairs. Our analysis on this dataset reveals a surprising finding that very simple code transformations in the underlying pair of programs can result in a significant drop in performance of SOTA LLMs for the task of code-equivalence checking. To remedy this, we present a simple fine-tuning-based approach to boost LLM performance on the transformed pairs of programs. Our approach for dataset generation is generic, and can be used with repositories with varying program difficulty levels and allows for applying varying numbers as well as kinds of transformations. In our experiments, we perform ablations over the difficulty level of original programs, as well as the kind of transformations used in generating pairs for equivalence checking. Our analysis presents deep insights into the working of LLMs for the task of code-equivalence, and points to the fact that they may still be far from what could be termed as a semantic understanding of the underlying code.
Tell me Habibi, is it Real or Fake?
May 28, 2025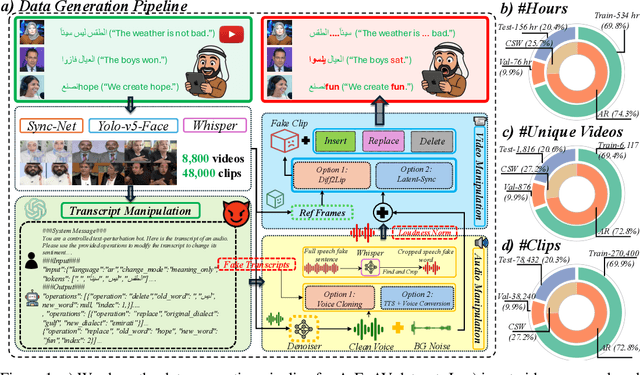
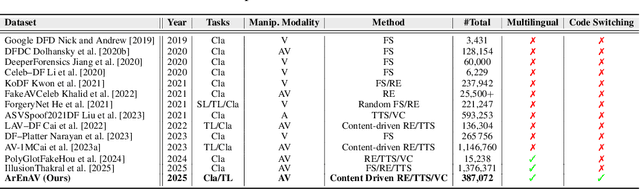
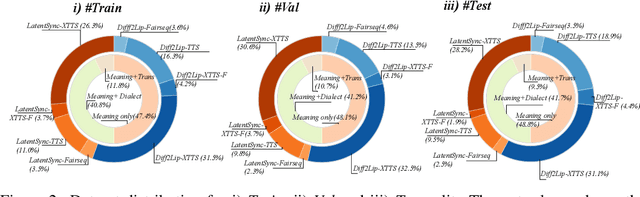

Deepfake generation methods are evolving fast, making fake media harder to detect and raising serious societal concerns. Most deepfake detection and dataset creation research focuses on monolingual content, often overlooking the challenges of multilingual and code-switched speech, where multiple languages are mixed within the same discourse. Code-switching, especially between Arabic and English, is common in the Arab world and is widely used in digital communication. This linguistic mixing poses extra challenges for deepfake detection, as it can confuse models trained mostly on monolingual data. To address this, we introduce \textbf{ArEnAV}, the first large-scale Arabic-English audio-visual deepfake dataset featuring intra-utterance code-switching, dialectal variation, and monolingual Arabic content. It \textbf{contains 387k videos and over 765 hours of real and fake videos}. Our dataset is generated using a novel pipeline integrating four Text-To-Speech and two lip-sync models, enabling comprehensive analysis of multilingual multimodal deepfake detection. We benchmark our dataset against existing monolingual and multilingual datasets, state-of-the-art deepfake detection models, and a human evaluation, highlighting its potential to advance deepfake research. The dataset can be accessed \href{https://huggingface.co/datasets/kartik060702/ArEnAV-Full}{here}.
Conditional Distribution Modelling for Few-Shot Image Synthesis with Diffusion Models
Apr 29, 2024Few-shot image synthesis entails generating diverse and realistic images of novel categories using only a few example images. While multiple recent efforts in this direction have achieved impressive results, the existing approaches are dependent only upon the few novel samples available at test time in order to generate new images, which restricts the diversity of the generated images. To overcome this limitation, we propose Conditional Distribution Modelling (CDM) -- a framework which effectively utilizes Diffusion models for few-shot image generation. By modelling the distribution of the latent space used to condition a Diffusion process, CDM leverages the learnt statistics of the training data to get a better approximation of the unseen class distribution, thereby removing the bias arising due to limited number of few shot samples. Simultaneously, we devise a novel inversion based optimization strategy that further improves the approximated unseen class distribution, and ensures the fidelity of the generated samples to the unseen class. The experimental results on four benchmark datasets demonstrate the effectiveness of our proposed CDM for few-shot generation.
DiffAugment: Diffusion based Long-Tailed Visual Relationship Recognition
Jan 01, 2024The task of Visual Relationship Recognition (VRR) aims to identify relationships between two interacting objects in an image and is particularly challenging due to the widely-spread and highly imbalanced distribution of <subject, relation, object> triplets. To overcome the resultant performance bias in existing VRR approaches, we introduce DiffAugment -- a method which first augments the tail classes in the linguistic space by making use of WordNet and then utilizes the generative prowess of Diffusion Models to expand the visual space for minority classes. We propose a novel hardness-aware component in diffusion which is based upon the hardness of each <S,R,O> triplet and demonstrate the effectiveness of hardness-aware diffusion in generating visual embeddings for the tail classes. We also propose a novel subject and object based seeding strategy for diffusion sampling which improves the discriminative capability of the generated visual embeddings. Extensive experimentation on the GQA-LT dataset shows favorable gains in the subject/object and relation average per-class accuracy using Diffusion augmented samples.
FakeBuster: A DeepFakes Detection Tool for Video Conferencing Scenarios
Jan 09, 2021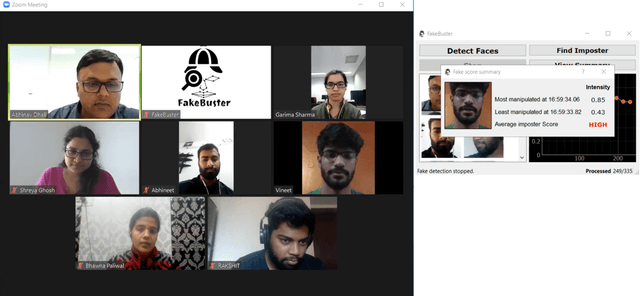
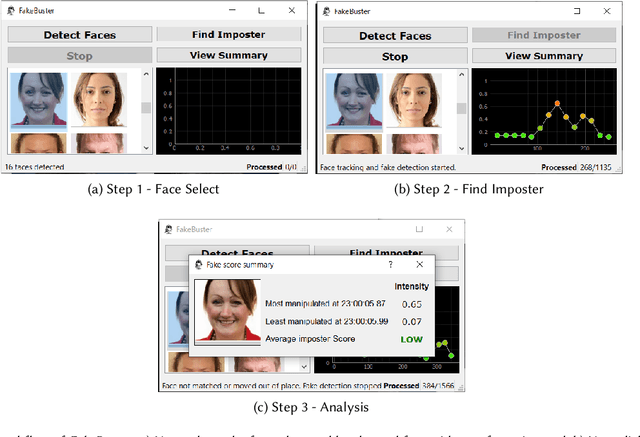
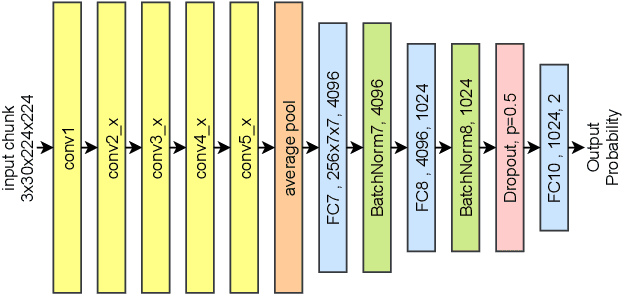
This paper proposes a new DeepFake detector FakeBuster for detecting impostors during video conferencing and manipulated faces on social media. FakeBuster is a standalone deep learning based solution, which enables a user to detect if another person's video is manipulated or spoofed during a video conferencing based meeting. This tool is independent of video conferencing solutions and has been tested with Zoom and Skype applications. It uses a 3D convolutional neural network for predicting video segment-wise fakeness scores. The network is trained on a combination of datasets such as Deeperforensics, DFDC, VoxCeleb, and deepfake videos created using locally captured (for video conferencing scenarios) images. This leads to different environments and perturbations in the dataset, which improves the generalization of the deepfake network.
The eyes know it: FakeET -- An Eye-tracking Database to Understand Deepfake Perception
Jun 18, 2020
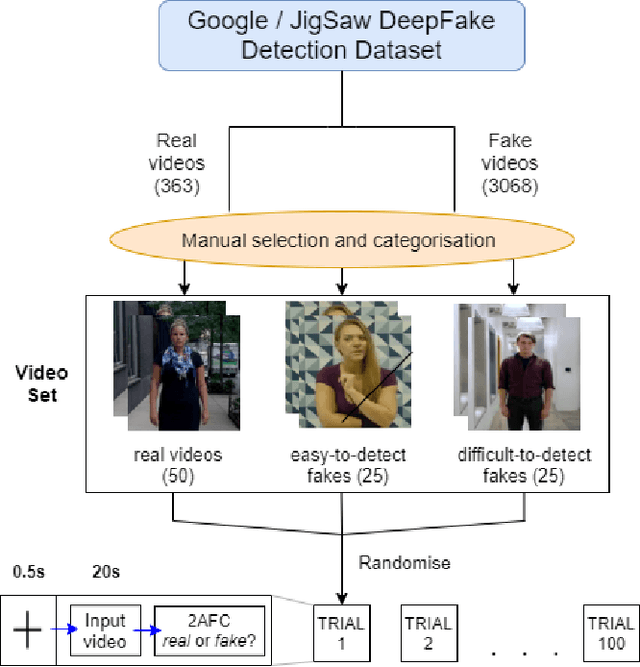

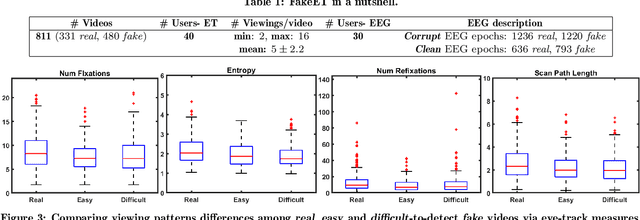
We present \textbf{FakeET}-- an eye-tracking database to understand human visual perception of \emph{deepfake} videos. Given that the principal purpose of deepfakes is to deceive human observers, FakeET is designed to understand and evaluate the ease with which viewers can detect synthetic video artifacts. FakeET contains viewing patterns compiled from 40 users via the \emph{Tobii} desktop eye-tracker for 811 videos from the \textit{Google Deepfake} dataset, with a minimum of two viewings per video. Additionally, EEG responses acquired via the \emph{Emotiv} sensor are also available. The compiled data confirms (a) distinct eye movement characteristics for \emph{real} vs \emph{fake} videos; (b) utility of the eye-track saliency maps for spatial forgery localization and detection, and (c) Error Related Negativity (ERN) triggers in the EEG responses, and the ability of the \emph{raw} EEG signal to distinguish between \emph{real} and \emph{fake} videos.
Not made for each other- Audio-Visual Dissonance-based Deepfake Detection and Localization
Jun 01, 2020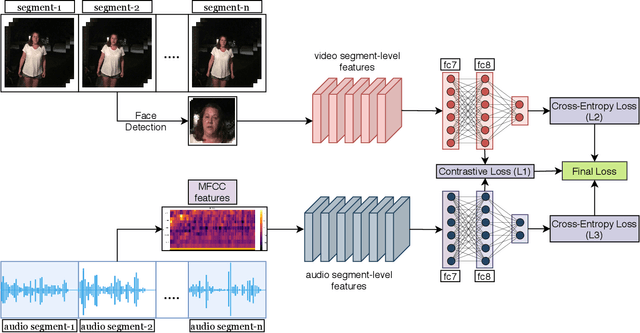

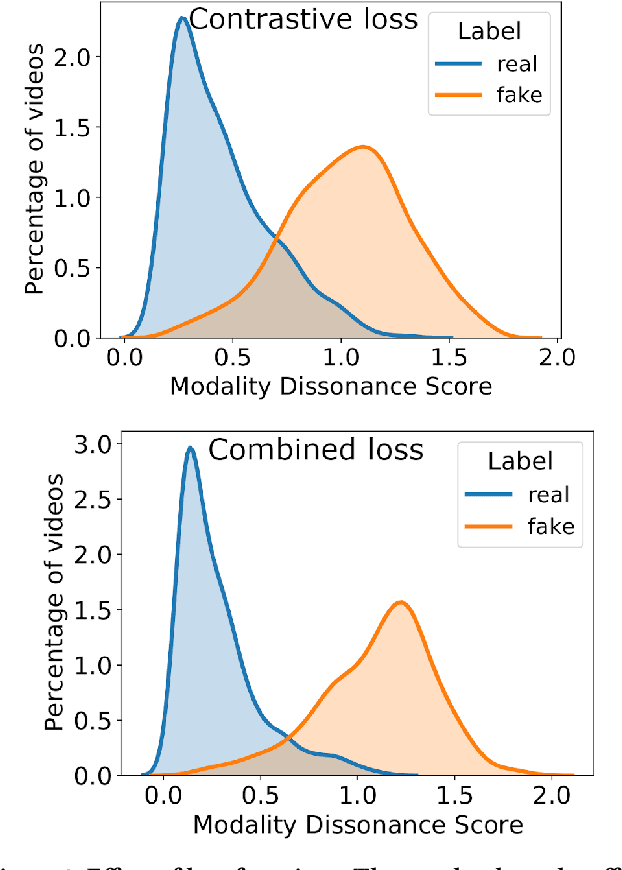
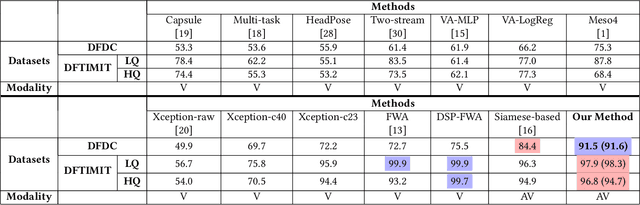
We propose detection of deepfake videos based on the dissimilarity between the audio and visual modalities, termed as the Modality Dissonance Score (MDS). We hypothesize that manipulation of either modality will lead to dis-harmony between the two modalities, eg, loss of lip-sync, unnatural facial and lip movements, etc. MDS is computed as an aggregate of dissimilarity scores between audio and visual segments in a video. Discriminative features are learnt for the audio and visual channels in a chunk-wise manner, employing the cross-entropy loss for individual modalities, and a contrastive loss that models inter-modality similarity. Extensive experiments on the DFDC and DeepFake-TIMIT Datasets show that our approach outperforms the state-of-the-art by up to 7%. We also demonstrate temporal forgery localization, and show how our technique identifies the manipulated video segments.