 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Oct 10, 2023



Language models have outpaced our ability to evaluate them effectively, but for their future development it is essential to study the frontier of their capabilities. We consider real-world software engineering to be a rich, sustainable, and challenging testbed for evaluating the next generation of language models. We therefore introduce SWE-bench, an evaluation framework including $2,294$ software engineering problems drawn from real GitHub issues and corresponding pull requests across $12$ popular Python repositories. Given a codebase along with a description of an issue to be resolved, a language model is tasked with editing the codebase to address the issue. Resolving issues in SWE-bench frequently requires understanding and coordinating changes across multiple functions, classes, and even files simultaneously, calling for models to interact with execution environments, process extremely long contexts and perform complex reasoning that goes far beyond traditional code generation. Our evaluations show that both state-of-the-art proprietary models and our fine-tuned model SWE-Llama can resolve only the simplest issues. Claude 2 and GPT-4 solve a mere $4.8$% and $1.7$% of instances respectively, even when provided with an oracle retriever. Advances on SWE-bench represent steps towards LMs that are more practical, intelligent, and autonomous.
FireAct: Toward Language Agent Fine-tuning
Oct 09, 2023



Recent efforts have augmented language models (LMs) with external tools or environments, leading to the development of language agents that can reason and act. However, most of these agents rely on few-shot prompting techniques with off-the-shelf LMs. In this paper, we investigate and argue for the overlooked direction of fine-tuning LMs to obtain language agents. Using a setup of question answering (QA) with a Google search API, we explore a variety of base LMs, prompting methods, fine-tuning data, and QA tasks, and find language agents are consistently improved after fine-tuning their backbone LMs. For example, fine-tuning Llama2-7B with 500 agent trajectories generated by GPT-4 leads to a 77% HotpotQA performance increase. Furthermore, we propose FireAct, a novel approach to fine-tuning LMs with trajectories from multiple tasks and prompting methods, and show having more diverse fine-tuning data can further improve agents. Along with other findings regarding scaling effects, robustness, generalization, efficiency and cost, our work establishes comprehensive benefits of fine-tuning LMs for agents, and provides an initial set of experimental designs, insights, as well as open questions toward language agent fine-tuning.
Cognitive Architectures for Language Agents
Sep 05, 2023



Recent efforts have incorporated large language models (LLMs) with external resources (e.g., the Internet) or internal control flows (e.g., prompt chaining) for tasks requiring grounding or reasoning. However, these efforts have largely been piecemeal, lacking a systematic framework for constructing a fully-fledged language agent. To address this challenge, we draw on the rich history of agent design in symbolic artificial intelligence to develop a blueprint for a new wave of cognitive language agents. We first show that LLMs have many of the same properties as production systems, and recent efforts to improve their grounding or reasoning mirror the development of cognitive architectures built around production systems. We then propose Cognitive Architectures for Language Agents (CoALA), a conceptual framework to systematize diverse methods for LLM-based reasoning, grounding, learning, and decision making as instantiations of language agents in the framework. Finally, we use the CoALA framework to highlight gaps and propose actionable directions toward more capable language agents in the future.
Scaling Laws for Imitation Learning in NetHack
Jul 18, 2023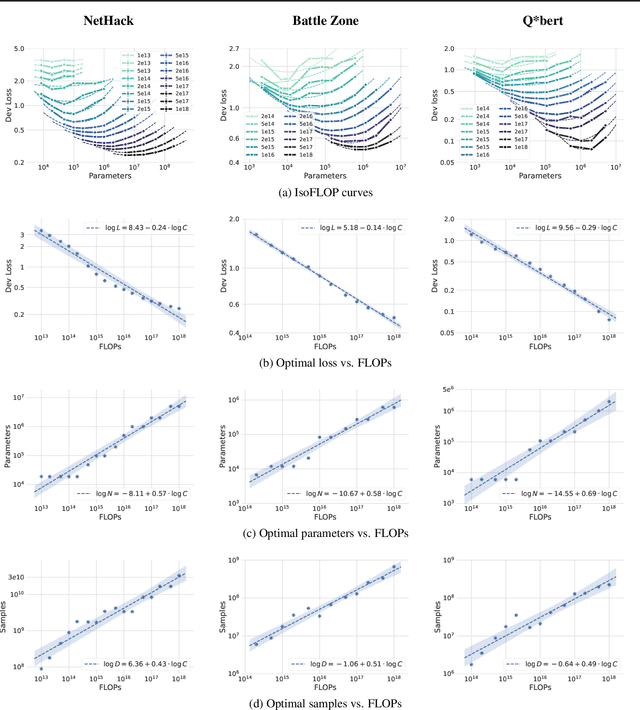

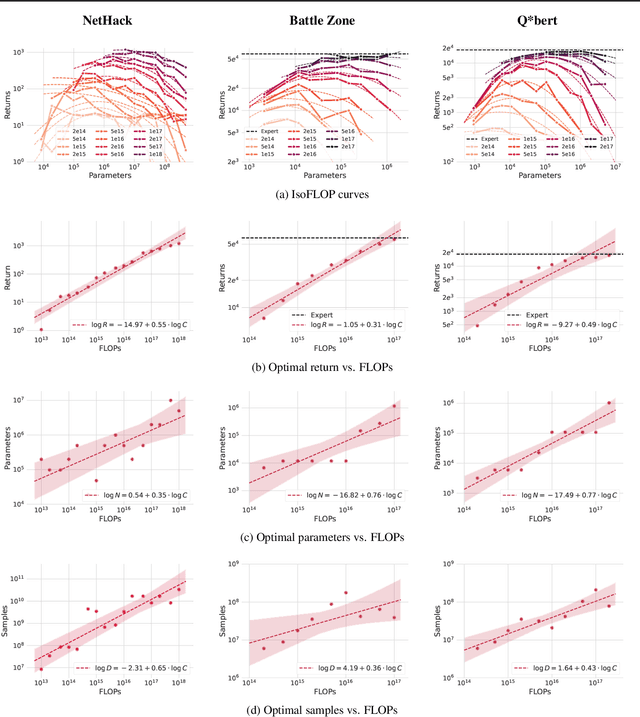
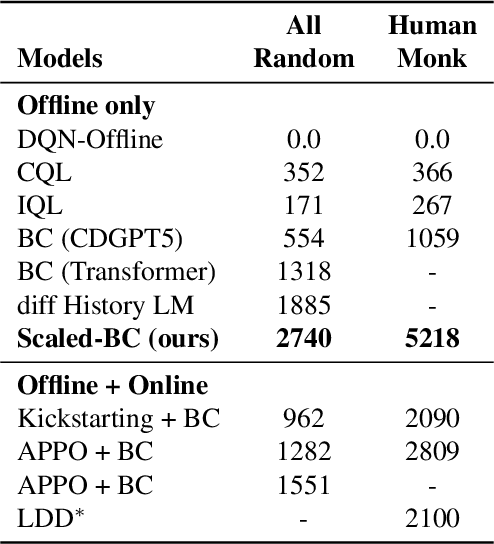
Imitation Learning (IL) is one of the most widely used methods in machine learning. Yet, while powerful, many works find it is often not able to fully recover the underlying expert behavior. However, none of these works deeply investigate the role of scaling up the model and data size. Inspired by recent work in Natural Language Processing (NLP) where "scaling up" has resulted in increasingly more capable LLMs, we investigate whether carefully scaling up model and data size can bring similar improvements in the imitation learning setting. To demonstrate our findings, we focus on the game of NetHack, a challenging environment featuring procedural generation, stochasticity, long-term dependencies, and partial observability. We find IL loss and mean return scale smoothly with the compute budget and are strongly correlated, resulting in power laws for training compute-optimal IL agents with respect to model size and number of samples. We forecast and train several NetHack agents with IL and find they outperform prior state-of-the-art by at least 2x in all settings. Our work both demonstrates the scaling behavior of imitation learning in a challenging domain, as well as the viability of scaling up current approaches for increasingly capable agents in NetHack, a game that remains elusively hard for current AI systems.
COLLIE: Systematic Construction of Constrained Text Generation Tasks
Jul 17, 2023Text generation under constraints have seen increasing interests in natural language processing, especially with the rapidly improving capabilities of large language models. However, existing benchmarks for constrained generation usually focus on fixed constraint types (e.g.,generate a sentence containing certain words) that have proved to be easy for state-of-the-art models like GPT-4. We present COLLIE, a grammar-based framework that allows the specification of rich, compositional constraints with diverse generation levels (word, sentence, paragraph, passage) and modeling challenges (e.g.,language understanding, logical reasoning, counting, semantic planning). We also develop tools for automatic extraction of task instances given a constraint structure and a raw text corpus. Using COLLIE, we compile the COLLIE-v1 dataset with 2080 instances comprising 13 constraint structures. We perform systematic experiments across five state-of-the-art instruction-tuned language models and analyze their performances to reveal shortcomings. COLLIE is designed to be extensible and lightweight, and we hope the community finds it useful to develop more complex constraints and evaluations in the future.
InstructEval: Systematic Evaluation of Instruction Selection Methods
Jul 16, 2023



In-context learning (ICL) performs tasks by prompting a large language model (LLM) using an instruction and a small set of annotated examples called demonstrations. Recent work has shown that precise details of the inputs used in the ICL prompt significantly impact performance, which has incentivized instruction selection algorithms. The effect of instruction-choice however is severely underexplored, with existing analyses restricted to shallow subsets of models and tasks, limiting the generalizability of their insights. We develop InstructEval, an ICL evaluation suite to conduct a thorough assessment of these techniques. The suite includes 13 open-sourced LLMs of varying scales from four model families, and covers nine tasks across three categories. Using the suite, we evaluate the relative performance of seven popular instruction selection methods over five metrics relevant to ICL. Our experiments reveal that using curated manually-written instructions or simple instructions without any task-specific descriptions often elicits superior ICL performance overall than that of automatic instruction-induction methods, pointing to a lack of generalizability among the latter. We release our evaluation suite for benchmarking instruction selection approaches and enabling more generalizable methods in this space.
InterCode: Standardizing and Benchmarking Interactive Coding with Execution Feedback
Jun 27, 2023



Humans write code in a fundamentally interactive manner and rely on constant execution feedback to correct errors, resolve ambiguities, and decompose tasks. While LLMs have recently exhibited promising coding capabilities, current coding benchmarks mostly consider a static instruction-to-code sequence transduction process, which has the potential for error propagation and a disconnect between the generated code and its final execution environment. To address this gap, we introduce InterCode, a lightweight, flexible, and easy-to-use framework of interactive coding as a standard reinforcement learning (RL) environment, with code as actions and execution feedback as observations. Our framework is language and platform agnostic, uses self-contained Docker environments to provide safe and reproducible execution, and is compatible out-of-the-box with traditional seq2seq coding methods, while enabling the development of new methods for interactive code generation. We use InterCode to create two interactive code environments with Bash and SQL as action spaces, leveraging data from the static Spider and NL2Bash datasets. We demonstrate InterCode's viability as a testbed by evaluating multiple state-of-the-art LLMs configured with different prompting strategies such as ReAct and Plan & Solve. Our results showcase the benefits of interactive code generation and demonstrate that InterCode can serve as a challenging benchmark for advancing code understanding and generation capabilities. InterCode is designed to be easily extensible and can even be used to incorporate new tasks such as Capture the Flag, a popular coding puzzle that is inherently multi-step and involves multiple programming languages. Project site with code and data: https://intercode-benchmark.github.io
Anthropomorphization of AI: Opportunities and Risks
May 24, 2023Anthropomorphization is the tendency to attribute human-like traits to non-human entities. It is prevalent in many social contexts -- children anthropomorphize toys, adults do so with brands, and it is a literary device. It is also a versatile tool in science, with behavioral psychology and evolutionary biology meticulously documenting its consequences. With widespread adoption of AI systems, and the push from stakeholders to make it human-like through alignment techniques, human voice, and pictorial avatars, the tendency for users to anthropomorphize it increases significantly. We take a dyadic approach to understanding this phenomenon with large language models (LLMs) by studying (1) the objective legal implications, as analyzed through the lens of the recent blueprint of AI bill of rights and the (2) subtle psychological aspects customization and anthropomorphization. We find that anthropomorphized LLMs customized for different user bases violate multiple provisions in the legislative blueprint. In addition, we point out that anthropomorphization of LLMs affects the influence they can have on their users, thus having the potential to fundamentally change the nature of human-AI interaction, with potential for manipulation and negative influence. With LLMs being hyper-personalized for vulnerable groups like children and patients among others, our work is a timely and important contribution. We propose a conservative strategy for the cautious use of anthropomorphization to improve trustworthiness of AI systems.
CSTS: Conditional Semantic Textual Similarity
May 24, 2023



Semantic textual similarity (STS) has been a cornerstone task in NLP that measures the degree of similarity between a pair of sentences, with applications in information retrieval, question answering, and embedding methods. However, it is an inherently ambiguous task, with the sentence similarity depending on the specific aspect of interest. We resolve this ambiguity by proposing a novel task called conditional STS (C-STS) which measures similarity conditioned on an aspect elucidated in natural language (hereon, condition). As an example, the similarity between the sentences "The NBA player shoots a three-pointer." and "A man throws a tennis ball into the air to serve." is higher for the condition "The motion of the ball." (both upward) and lower for "The size of the ball." (one large and one small). C-STS's advantages are two-fold: (1) it reduces the subjectivity and ambiguity of STS, and (2) enables fine-grained similarity evaluation using diverse conditions. C-STS contains almost 20,000 instances from diverse domains and we evaluate several state-of-the-art models to demonstrate that even the most performant fine-tuning and in-context learning models (GPT-4, Flan, SimCSE) find it challenging, with Spearman correlation scores of <50. We encourage the community to evaluate their models on C-STS to provide a more holistic view of semantic similarity and natural language understanding.
PruMUX: Augmenting Data Multiplexing with Model Compression
May 24, 2023



As language models increase in size by the day, methods for efficient inference are critical to leveraging their capabilities for various applications. Prior work has investigated techniques like model pruning, knowledge distillation, and data multiplexing to increase model throughput without sacrificing accuracy. In this paper, we combine two such methods -- structured pruning and data multiplexing -- to compound the speedup gains obtained by either method. Our approach, PruMUX, obtains up to 7.5-29.5X throughput improvement over BERT-base model with accuracy threshold from 80% to 74%. We further study various combinations of parameters (such as sparsity and multiplexing factor) in the two techniques to provide a comprehensive analysis of the tradeoff between accuracy and throughput in the resulting models. We then propose Auto-PruMUX, a meta-level model that can predict the high-performance parameters for pruning and multiplexing given a desired accuracy loss budget, providing a practical method to leverage the combination effectively.