 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroduction to Online Nonstochastic Control
Nov 17, 2022



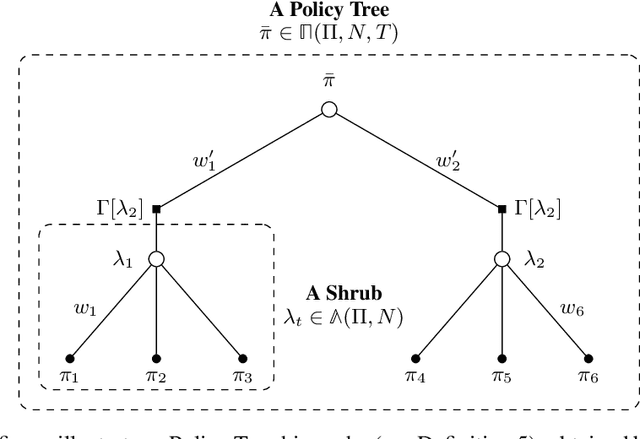
This text presents an introduction to an emerging paradigm in control of dynamical systems and differentiable reinforcement learning called online nonstochastic control. The new approach applies techniques from online convex optimization and convex relaxations to obtain new methods with provable guarantees for classical settings in optimal and robust control. The primary distinction between online nonstochastic control and other frameworks is the objective. In optimal control, robust control, and other control methodologies that assume stochastic noise, the goal is to perform comparably to an offline optimal strategy. In online nonstochastic control, both the cost functions as well as the perturbations from the assumed dynamical model are chosen by an adversary. Thus the optimal policy is not defined a priori. Rather, the target is to attain low regret against the best policy in hindsight from a benchmark class of policies. This objective suggests the use of the decision making framework of online convex optimization as an algorithmic methodology. The resulting methods are based on iterative mathematical optimization algorithms, and are accompanied by finite-time regret and computational complexity guarantees.
Machine Learning for Mechanical Ventilation Control (Extended Abstract)
Nov 23, 2021Mechanical ventilation is one of the most widely used therapies in the ICU. However, despite broad application from anaesthesia to COVID-related life support, many injurious challenges remain. We frame these as a control problem: ventilators must let air in and out of the patient's lungs according to a prescribed trajectory of airway pressure. Industry-standard controllers, based on the PID method, are neither optimal nor robust. Our data-driven approach learns to control an invasive ventilator by training on a simulator itself trained on data collected from the ventilator. This method outperforms popular reinforcement learning algorithms and even controls the physical ventilator more accurately and robustly than PID. These results underscore how effective data-driven methodologies can be for invasive ventilation and suggest that more general forms of ventilation (e.g., non-invasive, adaptive) may also be amenable.
A Boosting Approach to Reinforcement Learning
Aug 22, 2021
We study efficient algorithms for reinforcement learning in Markov decision processes whose complexity is independent of the number of states. This formulation succinctly captures large scale problems, but is also known to be computationally hard in its general form. Previous approaches attempt to circumvent the computational hardness by assuming structure in either transition function or the value function, or by relaxing the solution guarantee to a local optimality condition. We consider the methodology of boosting, borrowed from supervised learning, for converting weak learners into an accurate policy. The notion of weak learning we study is that of sampled-based approximate optimization of linear functions over policies. Under this assumption of weak learnability, we give an efficient algorithm that is capable of improving the accuracy of such weak learning methods, till global optimality is reached. We prove sample complexity and running time bounds on our method, that are polynomial in the natural parameters of the problem: approximation guarantee, discount factor, distribution mismatch and number of actions. In particular, our bound does not depend on the number of states. A technical difficulty in applying previous boosting results, is that the value function over policy space is not convex. We show how to use a non-convex variant of the Frank-Wolfe method, coupled with recent advances in gradient boosting that allow incorporating a weak learner with multiplicative approximation guarantee, to overcome the non-convexity and attain global convergence.
SurgeonAssist-Net: Towards Context-Aware Head-Mounted Display-Based Augmented Reality for Surgical Guidance
Jul 13, 2021


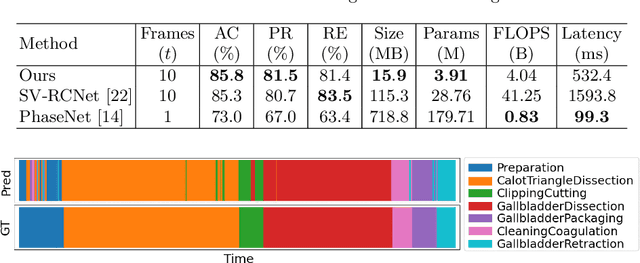
We present SurgeonAssist-Net: a lightweight framework making action-and-workflow-driven virtual assistance, for a set of predefined surgical tasks, accessible to commercially available optical see-through head-mounted displays (OST-HMDs). On a widely used benchmark dataset for laparoscopic surgical workflow, our implementation competes with state-of-the-art approaches in prediction accuracy for automated task recognition, and yet requires 7.4x fewer parameters, 10.2x fewer floating point operations per second (FLOPS), is 7.0x faster for inference on a CPU, and is capable of near real-time performance on the Microsoft HoloLens 2 OST-HMD. To achieve this, we make use of an efficient convolutional neural network (CNN) backbone to extract discriminative features from image data, and a low-parameter recurrent neural network (RNN) architecture to learn long-term temporal dependencies. To demonstrate the feasibility of our approach for inference on the HoloLens 2 we created a sample dataset that included video of several surgical tasks recorded from a user-centric point-of-view. After training, we deployed our model and cataloged its performance in an online simulated surgical scenario for the prediction of the current surgical task. The utility of our approach is explored in the discussion of several relevant clinical use-cases. Our code is publicly available at https://github.com/doughtmw/surgeon-assist-net.
Machine Learning for Mechanical Ventilation Control
Feb 26, 2021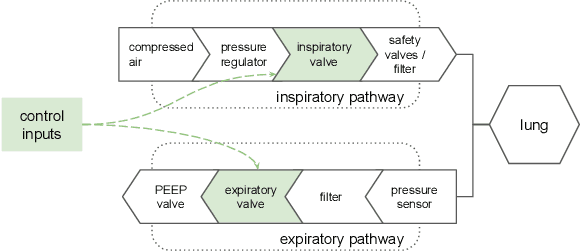
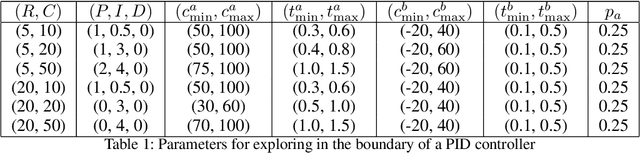
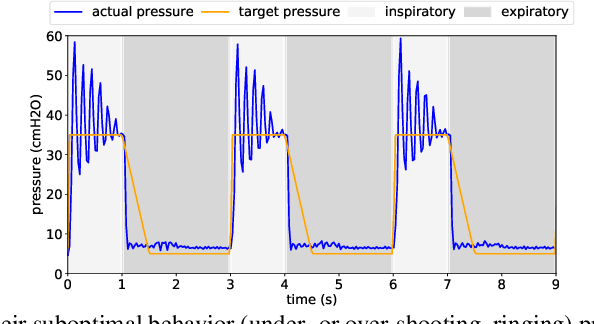
We consider the problem of controlling an invasive mechanical ventilator for pressure-controlled ventilation: a controller must let air in and out of a sedated patient's lungs according to a trajectory of airway pressures specified by a clinician. Hand-tuned PID controllers and similar variants have comprised the industry standard for decades, yet can behave poorly by over- or under-shooting their target or oscillating rapidly. We consider a data-driven machine learning approach: First, we train a simulator based on data we collect from an artificial lung. Then, we train deep neural network controllers on these simulators.We show that our controllers are able to track target pressure waveforms significantly better than PID controllers. We further show that a learned controller generalizes across lungs with varying characteristics much more readily than PID controllers do.
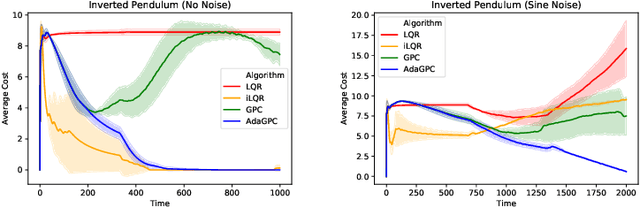
A Regret Minimization Approach to Iterative Learning Control
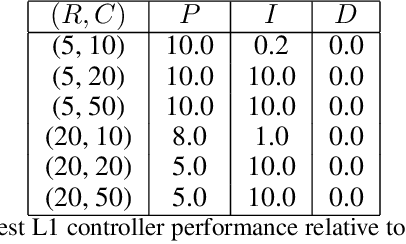
Feb 26, 2021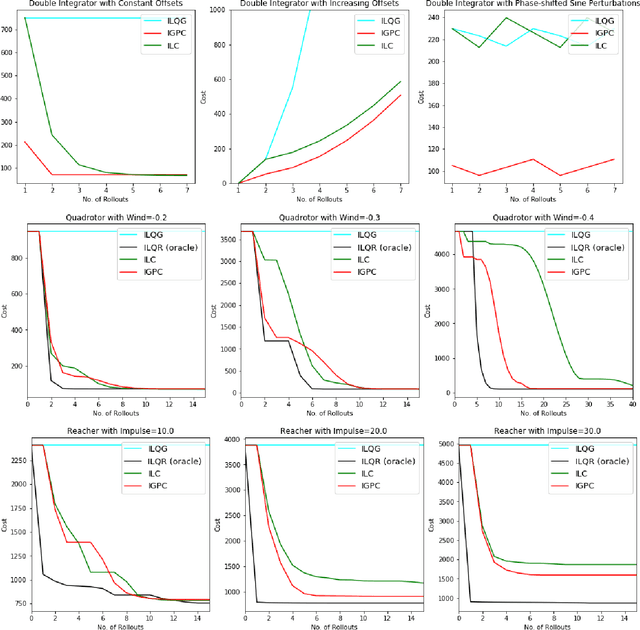
We consider the setting of iterative learning control, or model-based policy learning in the presence of uncertain, time-varying dynamics. In this setting, we propose a new performance metric, planning regret, which replaces the standard stochastic uncertainty assumptions with worst case regret. Based on recent advances in non-stochastic control, we design a new iterative algorithm for minimizing planning regret that is more robust to model mismatch and uncertainty. We provide theoretical and empirical evidence that the proposed algorithm outperforms existing methods on several benchmarks.
Deluca -- A Differentiable Control Library: Environments, Methods, and Benchmarking
Feb 19, 2021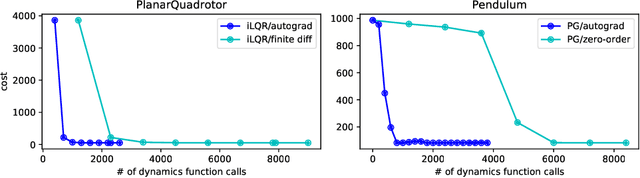
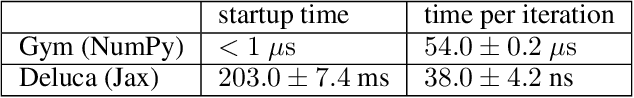
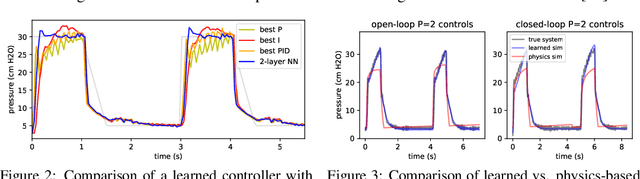
We present an open-source library of natively differentiable physics and robotics environments, accompanied by gradient-based control methods and a benchmark-ing suite. The introduced environments allow auto-differentiation through the simulation dynamics, and thereby permit fast training of controllers. The library features several popular environments, including classical control settings from OpenAI Gym. We also provide a novel differentiable environment, based on deep neural networks, that simulates medical ventilation. We give several use-cases of new scientific results obtained using the library. This includes a medical ventilator simulator and controller, an adaptive control method for time-varying linear dynamical systems, and new gradient-based methods for control of linear dynamical systems with adversarial perturbations.
Boosting for Online Convex Optimization
Feb 18, 2021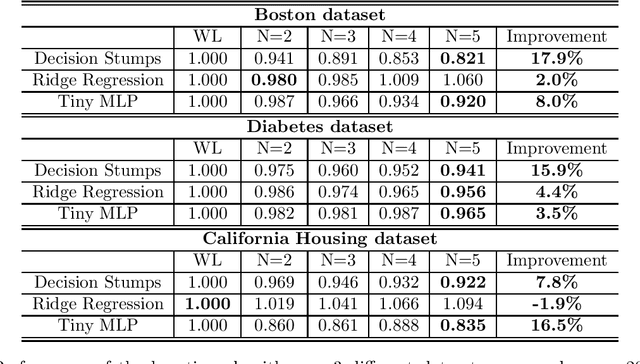
We consider the decision-making framework of online convex optimization with a very large number of experts. This setting is ubiquitous in contextual and reinforcement learning problems, where the size of the policy class renders enumeration and search within the policy class infeasible. Instead, we consider generalizing the methodology of online boosting. We define a weak learning algorithm as a mechanism that guarantees multiplicatively approximate regret against a base class of experts. In this access model, we give an efficient boosting algorithm that guarantees near-optimal regret against the convex hull of the base class. We consider both full and partial (a.k.a. bandit) information feedback models. We also give an analogous efficient boosting algorithm for the i.i.d. statistical setting. Our results simultaneously generalize online boosting and gradient boosting guarantees to contextual learning model, online convex optimization and bandit linear optimization settings.
RigNet: Neural Rigging for Articulated Characters
May 01, 2020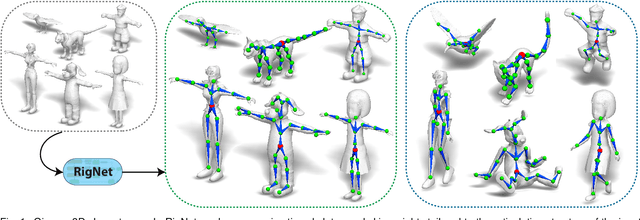
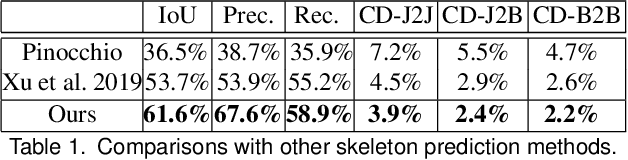
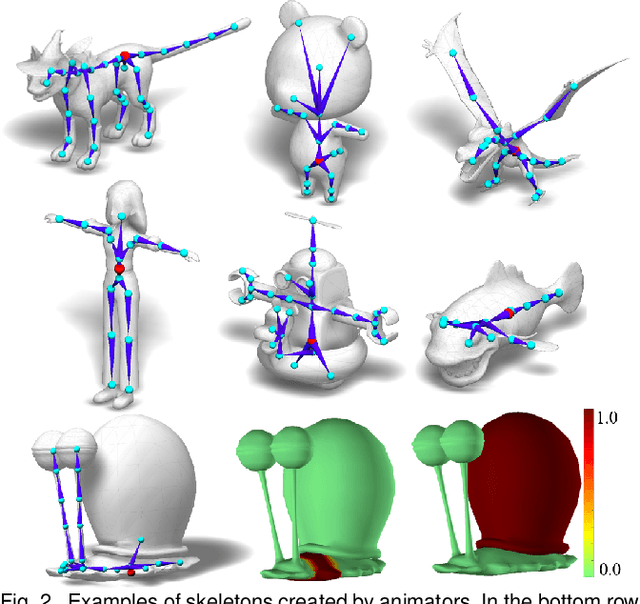
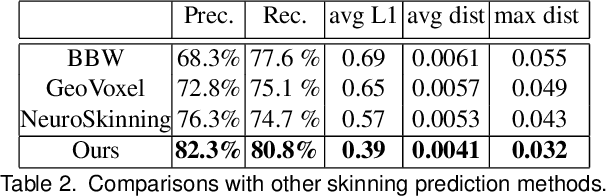
We present RigNet, an end-to-end automated method for producing animation rigs from input character models. Given an input 3D model representing an articulated character, RigNet predicts a skeleton that matches the animator expectations in joint placement and topology. It also estimates surface skin weights based on the predicted skeleton. Our method is based on a deep architecture that directly operates on the mesh representation without making assumptions on shape class and structure. The architecture is trained on a large and diverse collection of rigged models, including their mesh, skeletons and corresponding skin weights. Our evaluation is three-fold: we show better results than prior art when quantitatively compared to animator rigs; qualitatively we show that our rigs can be expressively posed and animated at multiple levels of detail; and finally, we evaluate the impact of various algorithm choices on our output rigs.
No-Regret Prediction in Marginally Stable Systems
Feb 20, 2020We consider the problem of online prediction in a marginally stable linear dynamical system subject to bounded adversarial or (non-isotropic) stochastic perturbations. This poses two challenges. Firstly, the system is in general unidentifiable, so recent and classical results on parameter recovery do not apply. Secondly, because we allow the system to be marginally stable, the state can grow polynomially with time; this causes standard regret bounds in online convex optimization to be vacuous. In spite of these challenges, we show that the online least-squares algorithm achieves sublinear regret (improvable to polylogarithmic in the stochastic setting), with polynomial dependence on the system's parameters. This requires a refined regret analysis, including a structural lemma showing the current state of the system to be a small linear combination of past states, even if the state grows polynomially. By applying our techniques to learning an autoregressive filter, we also achieve logarithmic regret in the partially observed setting under Gaussian noise, with polynomial dependence on the memory of the associated Kalman filter.