 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Cross-device and Training-free Robotic Grasping in 3D Open World
Nov 27, 2024Robotic grasping in the open world is a critical component of manufacturing and automation processes. While numerous existing approaches depend on 2D segmentation output to facilitate the grasping procedure, accurately determining depth from 2D imagery remains a challenge, often leading to limited performance in complex stacking scenarios. In contrast, techniques utilizing 3D point cloud data inherently capture depth information, thus enabling adeptly navigating and manipulating a diverse range of complex stacking scenes. However, such efforts are considerably hindered by the variance in data capture devices and the unstructured nature of the data, which limits their generalizability. Consequently, much research is narrowly concentrated on managing designated objects within specific settings, which confines their real-world applicability. This paper presents a novel pipeline capable of executing object grasping tasks in open-world scenarios even on previously unseen objects without the necessity for training. Additionally, our pipeline supports the flexible use of different 3D point cloud segmentation models across a variety of scenes. Leveraging the segmentation results, we propose to engage a training-free binary clustering algorithm that not only improves segmentation precision but also possesses the capability to cluster and localize unseen objects for executing grasping operations. In our experiments, we investigate a range of open-world scenarios, and the outcomes underscore the remarkable robustness and generalizability of our pipeline, consistent across various environments, robots, cameras, and objects. The code will be made available upon acceptance of the paper.
A comprehensive survey of oracle character recognition: challenges, benchmarks, and beyond
Nov 18, 2024



Oracle character recognition-an analysis of ancient Chinese inscriptions found on oracle bones-has become a pivotal field intersecting archaeology, paleography, and historical cultural studies. Traditional methods of oracle character recognition have relied heavily on manual interpretation by experts, which is not only labor-intensive but also limits broader accessibility to the general public. With recent breakthroughs in pattern recognition and deep learning, there is a growing movement towards the automation of oracle character recognition (OrCR), showing considerable promise in tackling the challenges inherent to these ancient scripts. However, a comprehensive understanding of OrCR still remains elusive. Therefore, this paper presents a systematic and structured survey of the current landscape of OrCR research. We commence by identifying and analyzing the key challenges of OrCR. Then, we provide an overview of the primary benchmark datasets and digital resources available for OrCR. A review of contemporary research methodologies follows, in which their respective efficacies, limitations, and applicability to the complex nature of oracle characters are critically highlighted and examined. Additionally, our review extends to ancillary tasks associated with OrCR across diverse disciplines, providing a broad-spectrum analysis of its applications. We conclude with a forward-looking perspective, proposing potential avenues for future investigations that could yield significant advancements in the field.
Decentralizing Test-time Adaptation under Heterogeneous Data Streams
Nov 16, 2024



While Test-Time Adaptation (TTA) has shown promise in addressing distribution shifts between training and testing data, its effectiveness diminishes with heterogeneous data streams due to uniform target estimation. As previous attempts merely stabilize model fine-tuning over time to handle continually changing environments, they fundamentally assume a homogeneous target domain at any moment, leaving the intrinsic real-world data heterogeneity unresolved. This paper delves into TTA under heterogeneous data streams, moving beyond current model-centric limitations. By revisiting TTA from a data-centric perspective, we discover that decomposing samples into Fourier space facilitates an accurate data separation across different frequency levels. Drawing from this insight, we propose a novel Frequency-based Decentralized Adaptation (FreDA) framework, which transitions data from globally heterogeneous to locally homogeneous in Fourier space and employs decentralized adaptation to manage diverse distribution shifts.Interestingly, we devise a novel Fourier-based augmentation strategy to assist in decentralizing adaptation, which individually enhances sample quality for capturing each type of distribution shifts. Extensive experiments across various settings (corrupted, natural, and medical environments) demonstrate the superiority of our proposed framework over the state-of-the-arts.
Personalize to generalize: Towards a universal medical multi-modality generalization through personalization
Nov 13, 2024The differences among medical imaging modalities, driven by distinct underlying principles, pose significant challenges for generalization in multi-modal medical tasks. Beyond modality gaps, individual variations, such as differences in organ size and metabolic rate, further impede a model's ability to generalize effectively across both modalities and diverse populations. Despite the importance of personalization, existing approaches to multi-modal generalization often neglect individual differences, focusing solely on common anatomical features. This limitation may result in weakened generalization in various medical tasks. In this paper, we unveil that personalization is critical for multi-modal generalization. Specifically, we propose an approach to achieve personalized generalization through approximating the underlying personalized invariant representation ${X}_h$ across various modalities by leveraging individual-level constraints and a learnable biological prior. We validate the feasibility and benefits of learning a personalized ${X}_h$, showing that this representation is highly generalizable and transferable across various multi-modal medical tasks. Extensive experimental results consistently show that the additionally incorporated personalization significantly improves performance and generalization across diverse scenarios, confirming its effectiveness.
Disentangling Tabular Data towards Better One-Class Anomaly Detection
Nov 12, 2024Tabular anomaly detection under the one-class classification setting poses a significant challenge, as it involves accurately conceptualizing "normal" derived exclusively from a single category to discern anomalies from normal data variations. Capturing the intrinsic correlation among attributes within normal samples presents one promising method for learning the concept. To do so, the most recent effort relies on a learnable mask strategy with a reconstruction task. However, this wisdom may suffer from the risk of producing uniform masks, i.e., essentially nothing is masked, leading to less effective correlation learning. To address this issue, we presume that attributes related to others in normal samples can be divided into two non-overlapping and correlated subsets, defined as CorrSets, to capture the intrinsic correlation effectively. Accordingly, we introduce an innovative method that disentangles CorrSets from normal tabular data. To our knowledge, this is a pioneering effort to apply the concept of disentanglement for one-class anomaly detection on tabular data. Extensive experiments on 20 tabular datasets show that our method substantially outperforms the state-of-the-art methods and leads to an average performance improvement of 6.1% on AUC-PR and 2.1% on AUC-ROC.
Covariance-based Space Regularization for Few-shot Class Incremental Learning
Nov 02, 2024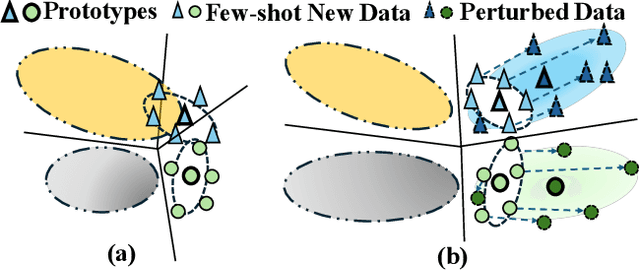
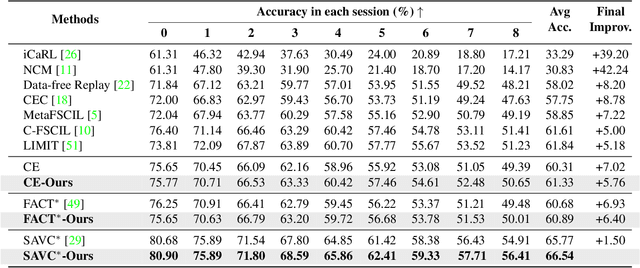
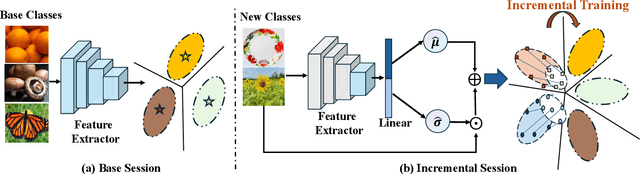
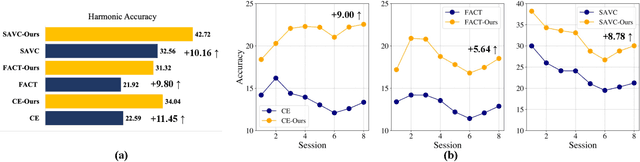
Few-shot Class Incremental Learning (FSCIL) presents a challenging yet realistic scenario, which requires the model to continually learn new classes with limited labeled data (i.e., incremental sessions) while retaining knowledge of previously learned base classes (i.e., base sessions). Due to the limited data in incremental sessions, models are prone to overfitting new classes and suffering catastrophic forgetting of base classes. To tackle these issues, recent advancements resort to prototype-based approaches to constrain the base class distribution and learn discriminative representations of new classes. Despite the progress, the limited data issue still induces ill-divided feature space, leading the model to confuse the new class with old classes or fail to facilitate good separation among new classes. In this paper, we aim to mitigate these issues by directly constraining the span of each class distribution from a covariance perspective. In detail, we propose a simple yet effective covariance constraint loss to force the model to learn each class distribution with the same covariance matrix. In addition, we propose a perturbation approach to perturb the few-shot training samples in the feature space, which encourages the samples to be away from the weighted distribution of other classes. Regarding perturbed samples as new class data, the classifier is forced to establish explicit boundaries between each new class and the existing ones. Our approach is easy to integrate into existing FSCIL approaches to boost performance. Experiments on three benchmarks validate the effectiveness of our approach, achieving a new state-of-the-art performance of FSCIL.
Interpret Your Decision: Logical Reasoning Regularization for Generalization in Visual Classification
Oct 06, 2024Vision models excel in image classification but struggle to generalize to unseen data, such as classifying images from unseen domains or discovering novel categories. In this paper, we explore the relationship between logical reasoning and deep learning generalization in visual classification. A logical regularization termed L-Reg is derived which bridges a logical analysis framework to image classification. Our work reveals that L-Reg reduces the complexity of the model in terms of the feature distribution and classifier weights. Specifically, we unveil the interpretability brought by L-Reg, as it enables the model to extract the salient features, such as faces to persons, for classification. Theoretical analysis and experiments demonstrate that L-Reg enhances generalization across various scenarios, including multi-domain generalization and generalized category discovery. In complex real-world scenarios where images span unknown classes and unseen domains, L-Reg consistently improves generalization, highlighting its practical efficacy.
Mind the Gap: Promoting Missing Modality Brain Tumor Segmentation with Alignment
Sep 28, 2024Brain tumor segmentation is often based on multiple magnetic resonance imaging (MRI). However, in clinical practice, certain modalities of MRI may be missing, which presents an even more difficult scenario. To cope with this challenge, knowledge distillation has emerged as one promising strategy. However, recent efforts typically overlook the modality gaps and thus fail to learn invariant feature representations across different modalities. Such drawback consequently leads to limited performance for both teachers and students. To ameliorate these problems, in this paper, we propose a novel paradigm that aligns latent features of involved modalities to a well-defined distribution anchor. As a major contribution, we prove that our novel training paradigm ensures a tight evidence lower bound, thus theoretically certifying its effectiveness. Extensive experiments on different backbones validate that the proposed paradigm can enable invariant feature representations and produce a teacher with narrowed modality gaps. This further offers superior guidance for missing modality students, achieving an average improvement of 1.75 on dice score.
CathAction: A Benchmark for Endovascular Intervention Understanding
Aug 23, 2024Real-time visual feedback from catheterization analysis is crucial for enhancing surgical safety and efficiency during endovascular interventions. However, existing datasets are often limited to specific tasks, small scale, and lack the comprehensive annotations necessary for broader endovascular intervention understanding. To tackle these limitations, we introduce CathAction, a large-scale dataset for catheterization understanding. Our CathAction dataset encompasses approximately 500,000 annotated frames for catheterization action understanding and collision detection, and 25,000 ground truth masks for catheter and guidewire segmentation. For each task, we benchmark recent related works in the field. We further discuss the challenges of endovascular intentions compared to traditional computer vision tasks and point out open research questions. We hope that CathAction will facilitate the development of endovascular intervention understanding methods that can be applied to real-world applications. The dataset is available at https://airvlab.github.io/cathdata/.
EEG-Defender: Defending against Jailbreak through Early Exit Generation of Large Language Models
Aug 21, 2024Large Language Models (LLMs) are increasingly attracting attention in various applications. Nonetheless, there is a growing concern as some users attempt to exploit these models for malicious purposes, including the synthesis of controlled substances and the propagation of disinformation. In an effort to mitigate such risks, the concept of "Alignment" technology has been developed. However, recent studies indicate that this alignment can be undermined using sophisticated prompt engineering or adversarial suffixes, a technique known as "Jailbreak." Our research takes cues from the human-like generate process of LLMs. We identify that while jailbreaking prompts may yield output logits similar to benign prompts, their initial embeddings within the model's latent space tend to be more analogous to those of malicious prompts. Leveraging this finding, we propose utilizing the early transformer outputs of LLMs as a means to detect malicious inputs, and terminate the generation immediately. Built upon this idea, we introduce a simple yet significant defense approach called EEG-Defender for LLMs. We conduct comprehensive experiments on ten jailbreak methods across three models. Our results demonstrate that EEG-Defender is capable of reducing the Attack Success Rate (ASR) by a significant margin, roughly 85\% in comparison with 50\% for the present SOTAs, with minimal impact on the utility and effectiveness of LLMs.