 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Segment Every Thing
Mar 27, 2018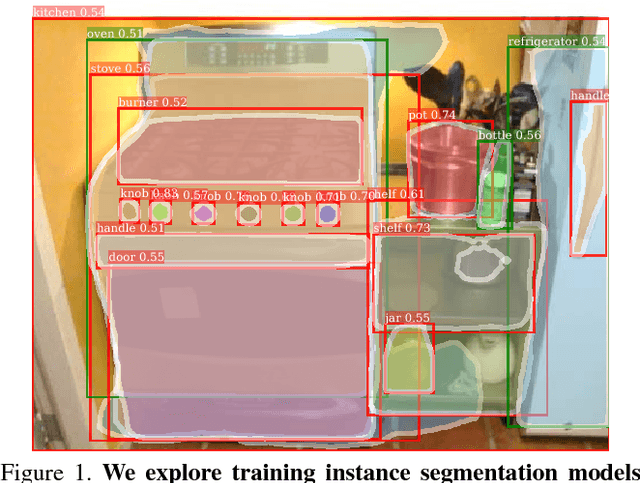

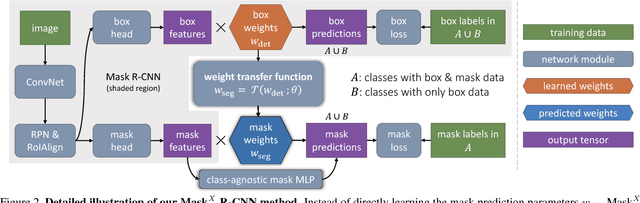
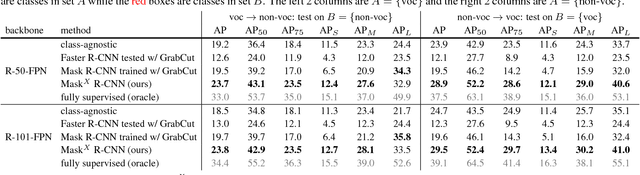
Most methods for object instance segmentation require all training examples to be labeled with segmentation masks. This requirement makes it expensive to annotate new categories and has restricted instance segmentation models to ~100 well-annotated classes. The goal of this paper is to propose a new partially supervised training paradigm, together with a novel weight transfer function, that enables training instance segmentation models on a large set of categories all of which have box annotations, but only a small fraction of which have mask annotations. These contributions allow us to train Mask R-CNN to detect and segment 3000 visual concepts using box annotations from the Visual Genome dataset and mask annotations from the 80 classes in the COCO dataset. We evaluate our approach in a controlled study on the COCO dataset. This work is a first step towards instance segmentation models that have broad comprehension of the visual world.
Detecting and Recognizing Human-Object Interactions
Mar 27, 2018


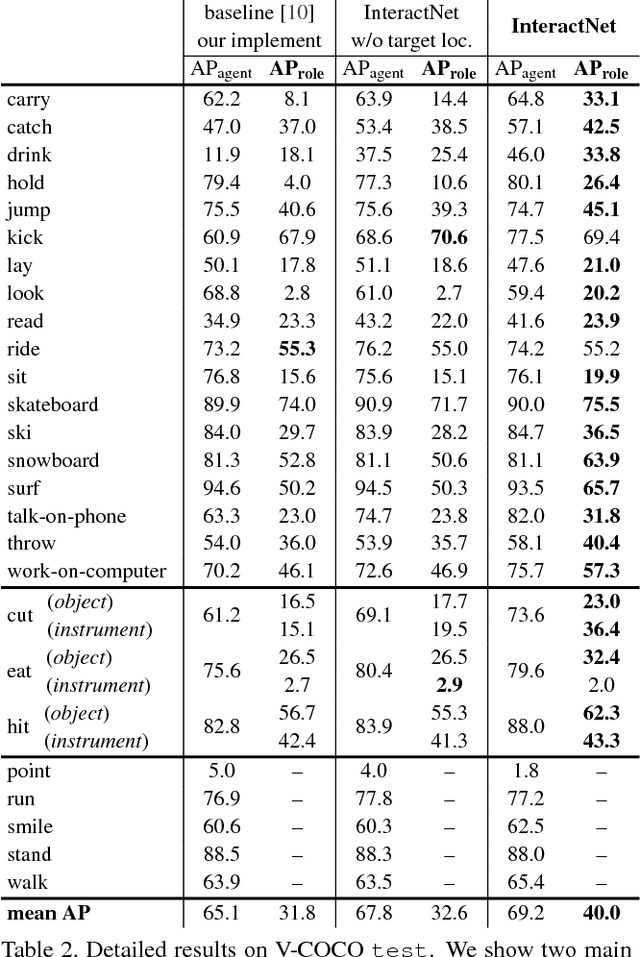
To understand the visual world, a machine must not only recognize individual object instances but also how they interact. Humans are often at the center of such interactions and detecting human-object interactions is an important practical and scientific problem. In this paper, we address the task of detecting <human, verb, object> triplets in challenging everyday photos. We propose a novel model that is driven by a human-centric approach. Our hypothesis is that the appearance of a person -- their pose, clothing, action -- is a powerful cue for localizing the objects they are interacting with. To exploit this cue, our model learns to predict an action-specific density over target object locations based on the appearance of a detected person. Our model also jointly learns to detect people and objects, and by fusing these predictions it efficiently infers interaction triplets in a clean, jointly trained end-to-end system we call InteractNet. We validate our approach on the recently introduced Verbs in COCO (V-COCO) and HICO-DET datasets, where we show quantitatively compelling results.
Focal Loss for Dense Object Detection
Feb 07, 2018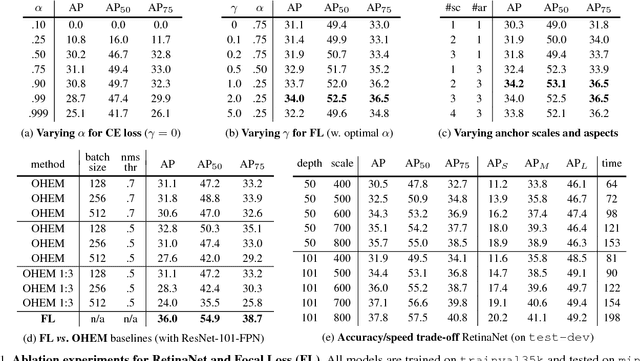
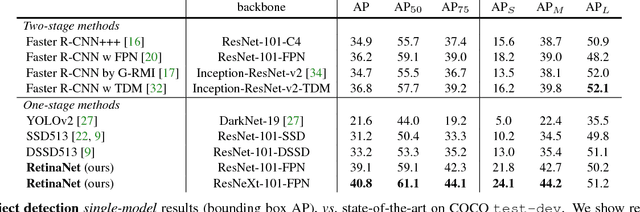
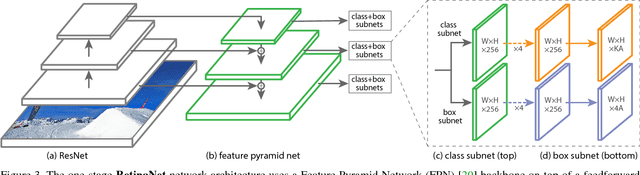
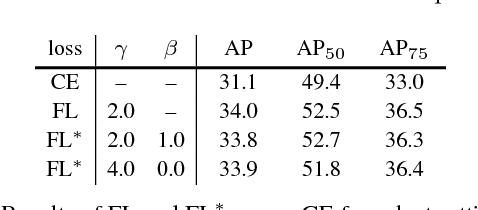
The highest accuracy object detectors to date are based on a two-stage approach popularized by R-CNN, where a classifier is applied to a sparse set of candidate object locations. In contrast, one-stage detectors that are applied over a regular, dense sampling of possible object locations have the potential to be faster and simpler, but have trailed the accuracy of two-stage detectors thus far. In this paper, we investigate why this is the case. We discover that the extreme foreground-background class imbalance encountered during training of dense detectors is the central cause. We propose to address this class imbalance by reshaping the standard cross entropy loss such that it down-weights the loss assigned to well-classified examples. Our novel Focal Loss focuses training on a sparse set of hard examples and prevents the vast number of easy negatives from overwhelming the detector during training. To evaluate the effectiveness of our loss, we design and train a simple dense detector we call RetinaNet. Our results show that when trained with the focal loss, RetinaNet is able to match the speed of previous one-stage detectors while surpassing the accuracy of all existing state-of-the-art two-stage detectors. Code is at: https://github.com/facebookresearch/Detectron.
Mask R-CNN
Jan 24, 2018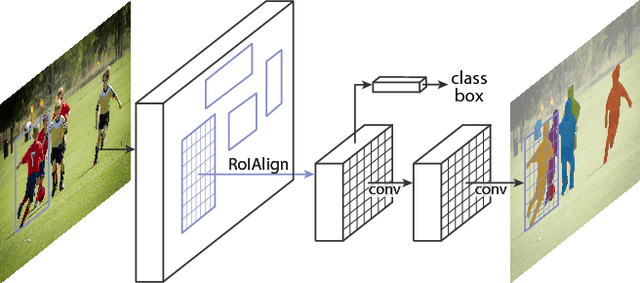
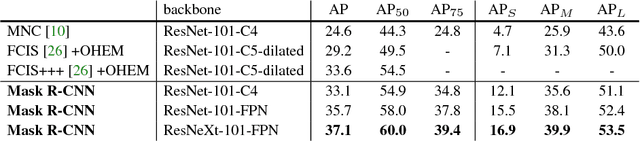


We present a conceptually simple, flexible, and general framework for object instance segmentation. Our approach efficiently detects objects in an image while simultaneously generating a high-quality segmentation mask for each instance. The method, called Mask R-CNN, extends Faster R-CNN by adding a branch for predicting an object mask in parallel with the existing branch for bounding box recognition. Mask R-CNN is simple to train and adds only a small overhead to Faster R-CNN, running at 5 fps. Moreover, Mask R-CNN is easy to generalize to other tasks, e.g., allowing us to estimate human poses in the same framework. We show top results in all three tracks of the COCO suite of challenges, including instance segmentation, bounding-box object detection, and person keypoint detection. Without bells and whistles, Mask R-CNN outperforms all existing, single-model entries on every task, including the COCO 2016 challenge winners. We hope our simple and effective approach will serve as a solid baseline and help ease future research in instance-level recognition. Code has been made available at: https://github.com/facebookresearch/Detectron
Data Distillation: Towards Omni-Supervised Learning
Dec 12, 2017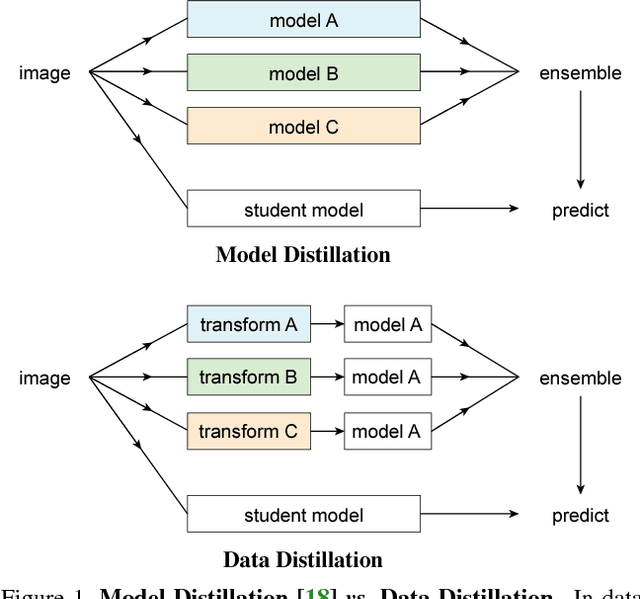
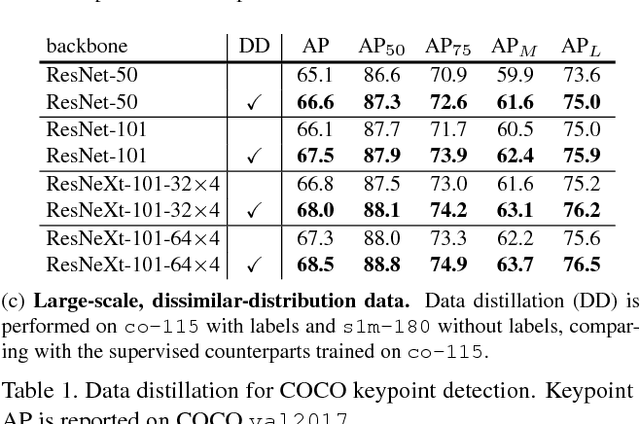

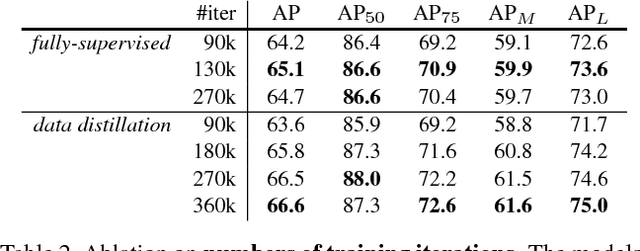
We investigate omni-supervised learning, a special regime of semi-supervised learning in which the learner exploits all available labeled data plus internet-scale sources of unlabeled data. Omni-supervised learning is lower-bounded by performance on existing labeled datasets, offering the potential to surpass state-of-the-art fully supervised methods. To exploit the omni-supervised setting, we propose data distillation, a method that ensembles predictions from multiple transformations of unlabeled data, using a single model, to automatically generate new training annotations. We argue that visual recognition models have recently become accurate enough that it is now possible to apply classic ideas about self-training to challenging real-world data. Our experimental results show that in the cases of human keypoint detection and general object detection, state-of-the-art models trained with data distillation surpass the performance of using labeled data from the COCO dataset alone.
Transitive Invariance for Self-supervised Visual Representation Learning
Aug 15, 2017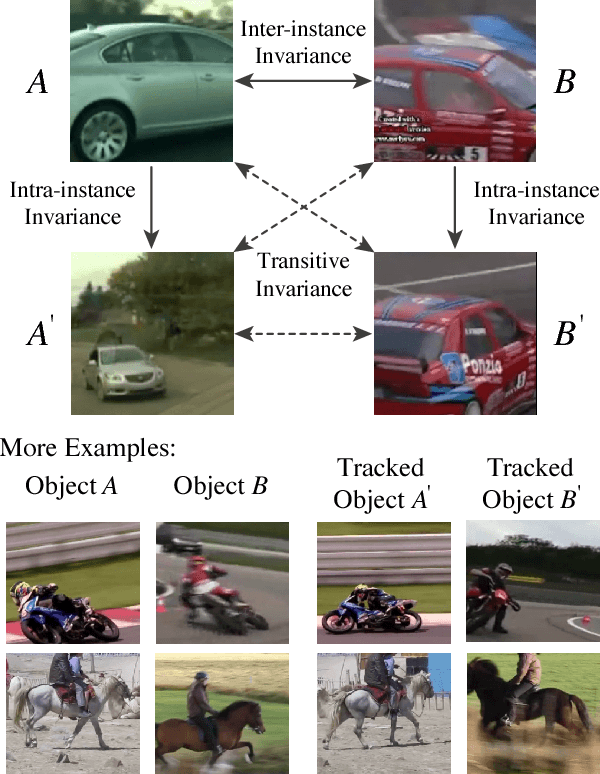

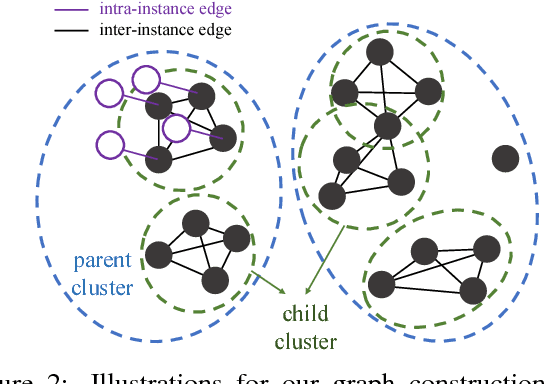

Learning visual representations with self-supervised learning has become popular in computer vision. The idea is to design auxiliary tasks where labels are free to obtain. Most of these tasks end up providing data to learn specific kinds of invariance useful for recognition. In this paper, we propose to exploit different self-supervised approaches to learn representations invariant to (i) inter-instance variations (two objects in the same class should have similar features) and (ii) intra-instance variations (viewpoint, pose, deformations, illumination, etc). Instead of combining two approaches with multi-task learning, we argue to organize and reason the data with multiple variations. Specifically, we propose to generate a graph with millions of objects mined from hundreds of thousands of videos. The objects are connected by two types of edges which correspond to two types of invariance: "different instances but a similar viewpoint and category" and "different viewpoints of the same instance". By applying simple transitivity on the graph with these edges, we can obtain pairs of images exhibiting richer visual invariance. We use this data to train a Triplet-Siamese network with VGG16 as the base architecture and apply the learned representations to different recognition tasks. For object detection, we achieve 63.2% mAP on PASCAL VOC 2007 using Fast R-CNN (compare to 67.3% with ImageNet pre-training). For the challenging COCO dataset, our method is surprisingly close (23.5%) to the ImageNet-supervised counterpart (24.4%) using the Faster R-CNN framework. We also show that our network can perform significantly better than the ImageNet network in the surface normal estimation task.
Feature Pyramid Networks for Object Detection
Apr 19, 2017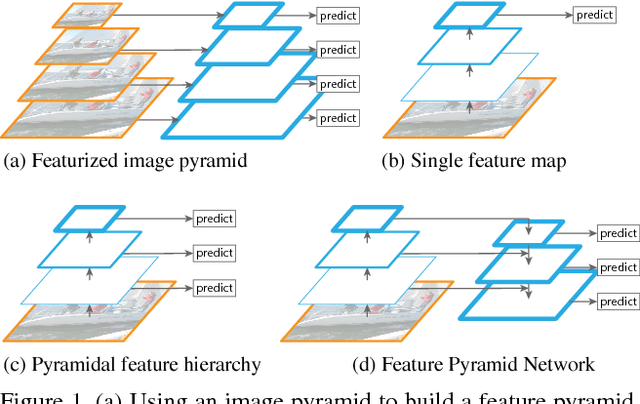
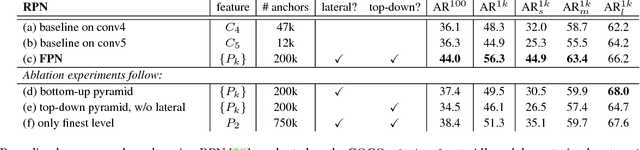
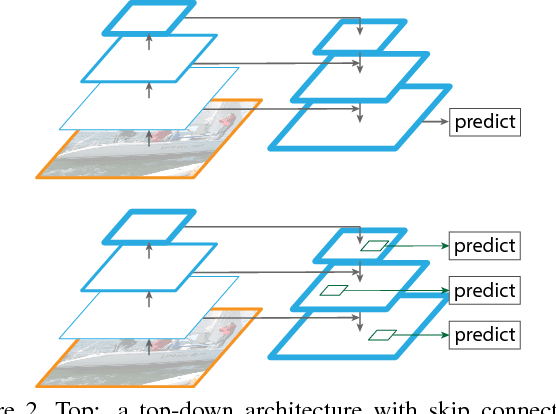

Feature pyramids are a basic component in recognition systems for detecting objects at different scales. But recent deep learning object detectors have avoided pyramid representations, in part because they are compute and memory intensive. In this paper, we exploit the inherent multi-scale, pyramidal hierarchy of deep convolutional networks to construct feature pyramids with marginal extra cost. A top-down architecture with lateral connections is developed for building high-level semantic feature maps at all scales. This architecture, called a Feature Pyramid Network (FPN), shows significant improvement as a generic feature extractor in several applications. Using FPN in a basic Faster R-CNN system, our method achieves state-of-the-art single-model results on the COCO detection benchmark without bells and whistles, surpassing all existing single-model entries including those from the COCO 2016 challenge winners. In addition, our method can run at 5 FPS on a GPU and thus is a practical and accurate solution to multi-scale object detection. Code will be made publicly available.
Aggregated Residual Transformations for Deep Neural Networks
Apr 11, 2017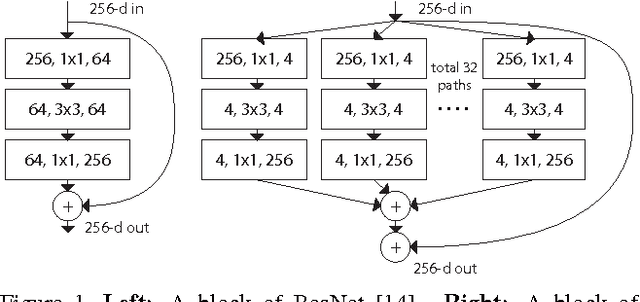
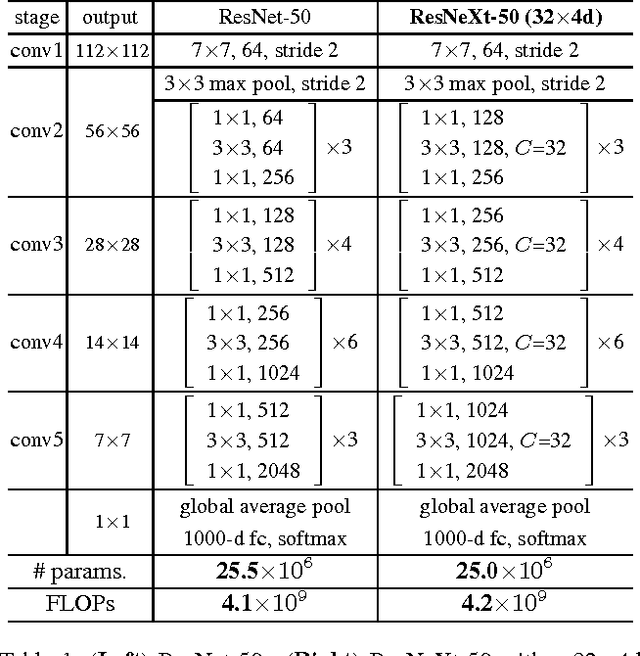
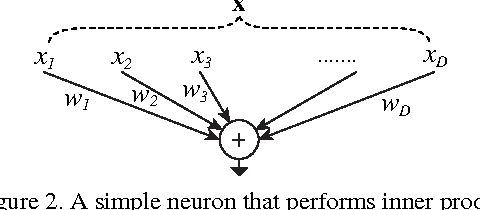
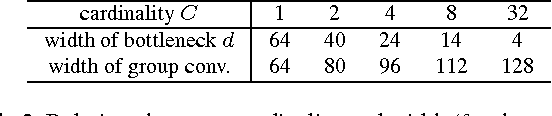
We present a simple, highly modularized network architecture for image classification. Our network is constructed by repeating a building block that aggregates a set of transformations with the same topology. Our simple design results in a homogeneous, multi-branch architecture that has only a few hyper-parameters to set. This strategy exposes a new dimension, which we call "cardinality" (the size of the set of transformations), as an essential factor in addition to the dimensions of depth and width. On the ImageNet-1K dataset, we empirically show that even under the restricted condition of maintaining complexity, increasing cardinality is able to improve classification accuracy. Moreover, increasing cardinality is more effective than going deeper or wider when we increase the capacity. Our models, named ResNeXt, are the foundations of our entry to the ILSVRC 2016 classification task in which we secured 2nd place. We further investigate ResNeXt on an ImageNet-5K set and the COCO detection set, also showing better results than its ResNet counterpart. The code and models are publicly available online.
Object Detection Networks on Convolutional Feature Maps
Aug 17, 2016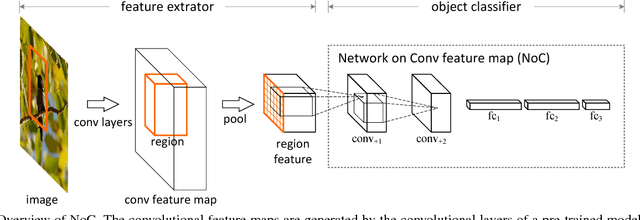
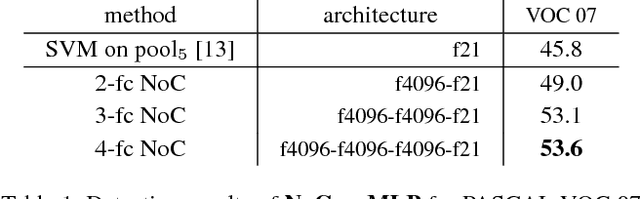
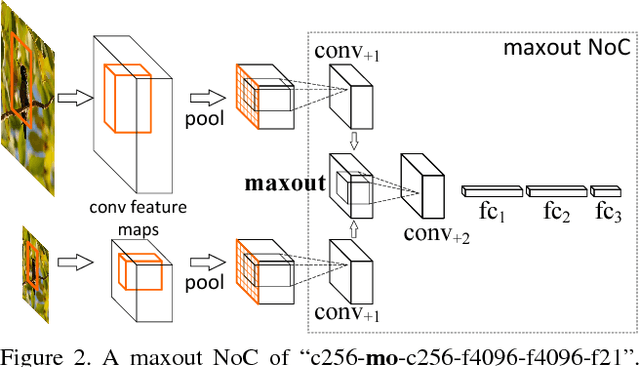
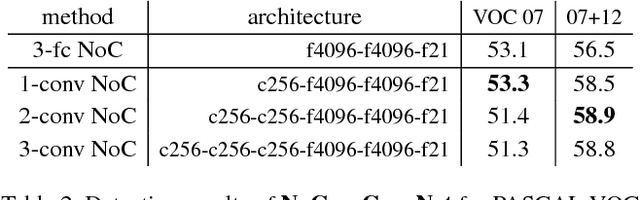
Most object detectors contain two important components: a feature extractor and an object classifier. The feature extractor has rapidly evolved with significant research efforts leading to better deep convolutional architectures. The object classifier, however, has not received much attention and many recent systems (like SPPnet and Fast/Faster R-CNN) use simple multi-layer perceptrons. This paper demonstrates that carefully designing deep networks for object classification is just as important. We experiment with region-wise classifier networks that use shared, region-independent convolutional features. We call them "Networks on Convolutional feature maps" (NoCs). We discover that aside from deep feature maps, a deep and convolutional per-region classifier is of particular importance for object detection, whereas latest superior image classification models (such as ResNets and GoogLeNets) do not directly lead to good detection accuracy without using such a per-region classifier. We show by experiments that despite the effective ResNets and Faster R-CNN systems, the design of NoCs is an essential element for the 1st-place winning entries in ImageNet and MS COCO challenges 2015.
Is Faster R-CNN Doing Well for Pedestrian Detection?
Jul 27, 2016
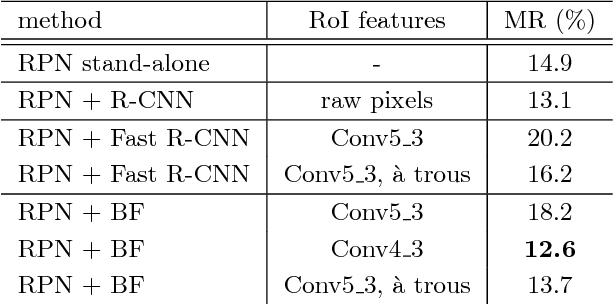

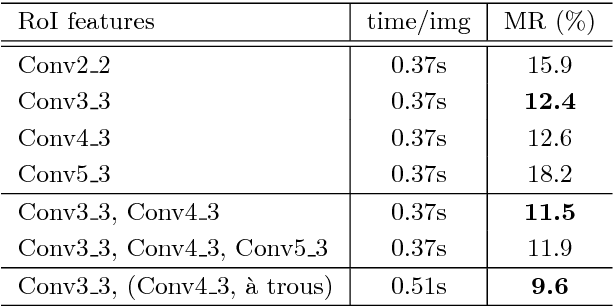
Detecting pedestrian has been arguably addressed as a special topic beyond general object detection. Although recent deep learning object detectors such as Fast/Faster R-CNN [1, 2] have shown excellent performance for general object detection, they have limited success for detecting pedestrian, and previous leading pedestrian detectors were in general hybrid methods combining hand-crafted and deep convolutional features. In this paper, we investigate issues involving Faster R-CNN [2] for pedestrian detection. We discover that the Region Proposal Network (RPN) in Faster R-CNN indeed performs well as a stand-alone pedestrian detector, but surprisingly, the downstream classifier degrades the results. We argue that two reasons account for the unsatisfactory accuracy: (i) insufficient resolution of feature maps for handling small instances, and (ii) lack of any bootstrapping strategy for mining hard negative examples. Driven by these observations, we propose a very simple but effective baseline for pedestrian detection, using an RPN followed by boosted forests on shared, high-resolution convolutional feature maps. We comprehensively evaluate this method on several benchmarks (Caltech, INRIA, ETH, and KITTI), presenting competitive accuracy and good speed. Code will be made publicly available.