 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoolNet: Minimizing The Energy Consumption of Binary Neural Networks
Jun 13, 2021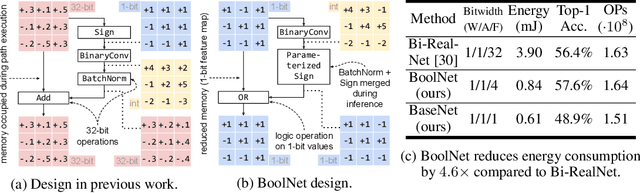
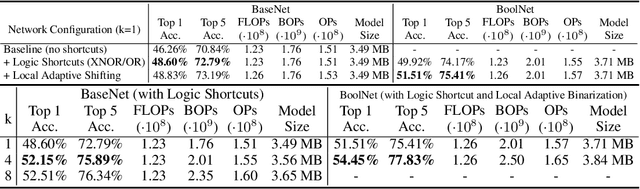
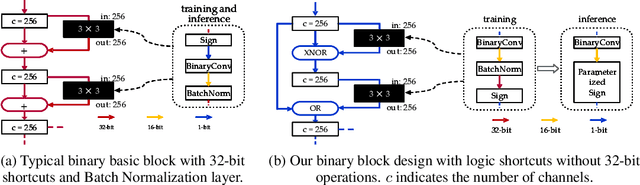
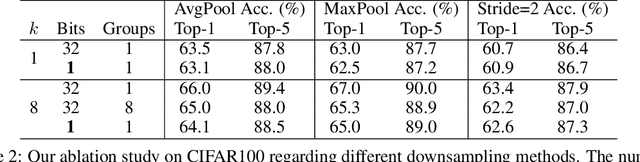
Recent works on Binary Neural Networks (BNNs) have made promising progress in narrowing the accuracy gap of BNNs to their 32-bit counterparts. However, the accuracy gains are often based on specialized model designs using additional 32-bit components. Furthermore, almost all previous BNNs use 32-bit for feature maps and the shortcuts enclosing the corresponding binary convolution blocks, which helps to effectively maintain the accuracy, but is not friendly to hardware accelerators with limited memory, energy, and computing resources. Thus, we raise the following question: How can accuracy and energy consumption be balanced in a BNN network design? We extensively study this fundamental problem in this work and propose a novel BNN architecture without most commonly used 32-bit components: \textit{BoolNet}. Experimental results on ImageNet demonstrate that BoolNet can achieve 4.6x energy reduction coupled with 1.2\% higher accuracy than the commonly used BNN architecture Bi-RealNet. Code and trained models are available at: https://github.com/hpi-xnor/BoolNet.
Accelerating Inference for Sparse Extreme Multi-Label Ranking Trees
Jun 09, 2021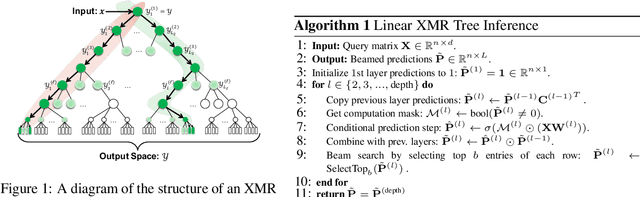

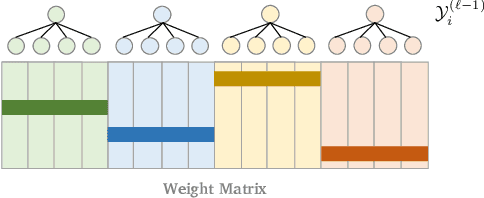
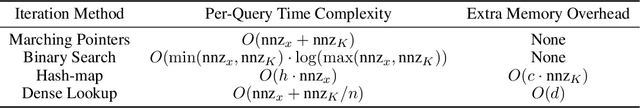
Tree-based models underpin many modern semantic search engines and recommender systems due to their sub-linear inference times. In industrial applications, these models operate at extreme scales, where every bit of performance is critical. Memory constraints at extreme scales also require that models be sparse, hence tree-based models are often back-ended by sparse matrix algebra routines. However, there are currently no sparse matrix techniques specifically designed for the sparsity structure one encounters in tree-based models for extreme multi-label ranking/classification (XMR/XMC) problems. To address this issue, we present the masked sparse chunk multiplication (MSCM) technique, a sparse matrix technique specifically tailored to XMR trees. MSCM is easy to implement, embarrassingly parallelizable, and offers a significant performance boost to any existing tree inference pipeline at no cost. We perform a comprehensive study of MSCM applied to several different sparse inference schemes and benchmark our methods on a general purpose extreme multi-label ranking framework. We observe that MSCM gives consistently dramatic speedups across both the online and batch inference settings, single- and multi-threaded settings, and on many different tree models and datasets. To demonstrate its utility in industrial applications, we apply MSCM to an enterprise-scale semantic product search problem with 100 million products and achieve sub-millisecond latency of 0.88 ms per query on a single thread -- an 8x reduction in latency over vanilla inference techniques. The MSCM technique requires absolutely no sacrifices to model accuracy as it gives exactly the same results as standard sparse matrix techniques. Therefore, we believe that MSCM will enable users of XMR trees to save a substantial amount of compute resources in their inference pipelines at very little cost.
Machine Learning for Electronic Design Automation: A Survey
Jan 10, 2021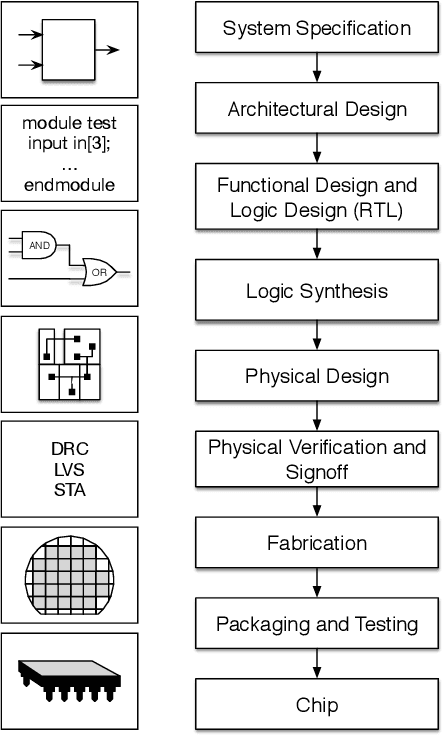

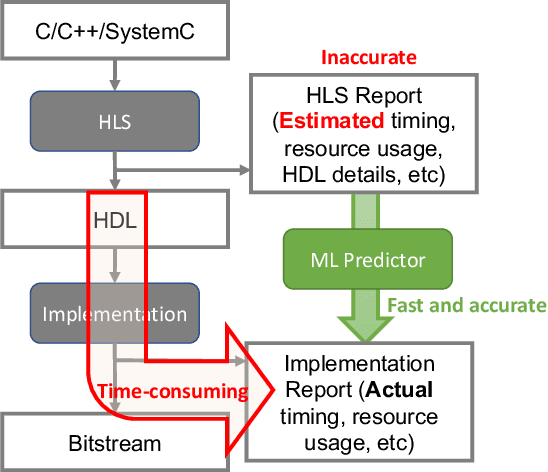
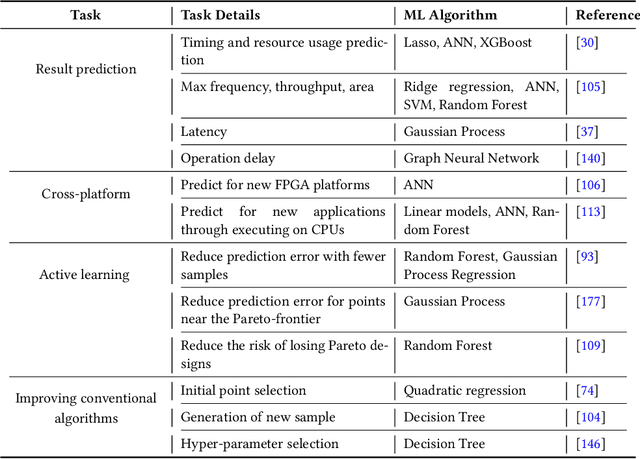
With the down-scaling of CMOS technology, the design complexity of very large-scale integrated (VLSI) is increasing. Although the application of machine learning (ML) techniques in electronic design automation (EDA) can trace its history back to the 90s, the recent breakthrough of ML and the increasing complexity of EDA tasks have aroused more interests in incorporating ML to solve EDA tasks. In this paper, we present a comprehensive review of existing ML for EDA studies, organized following the EDA hierarchy.
PECOS: Prediction for Enormous and Correlated Output Spaces
Oct 12, 2020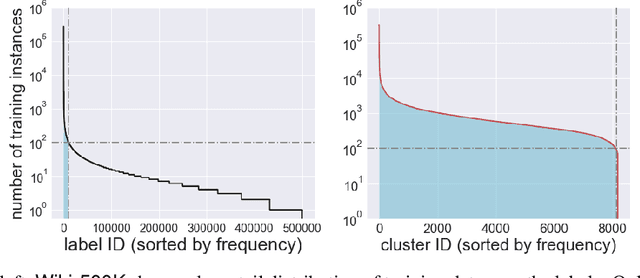
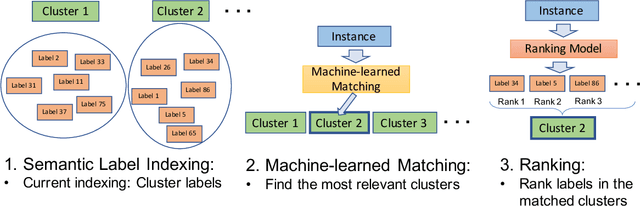

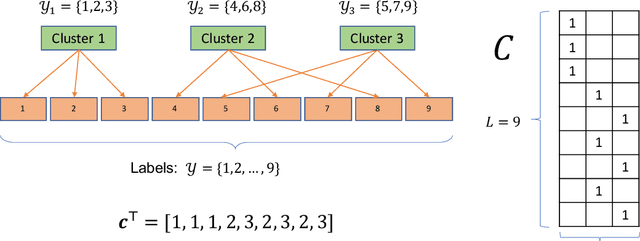
Many challenging problems in modern applications amount to finding relevant results from an enormous output space of potential candidates. The size of the output space for these problems can range from millions to billions. Moreover, training data is often limited for many of the so-called ``long-tail'' of items in the output space. Given the inherent paucity of training data for most of the items in the output space, developing machine learned models that perform well for spaces of this size is challenging. Fortunately, items in the output space are often correlated thereby presenting an opportunity to alleviate the data sparsity issue. In this paper, we propose the Prediction for Enormous and Correlated Output Spaces (PECOS) framework, a versatile and modular machine learning framework for solving prediction problems for very large output spaces, and apply it to the eXtreme Multilabel Ranking (XMR) problem: given an input instance, find and rank the most relevant items from an enormous but fixed and finite output space. PECOS is a three-phase framework: (i) in the first phase, PECOS organizes the output space using a semantic indexing scheme, (ii) in the second phase, PECOS uses the indexing to narrow down the output space by orders of magnitude using a machine learned matching scheme, and (iii) in the third phase, PECOS ranks the matched items using a final ranking scheme. The versatility and modularity of PECOS allows for easy plug-and-play of various choices for the indexing, matching, and ranking phases. On a dataset where the output space is of size 2.8 million, PECOS with a neural matcher results in a 10% increase in precision@1 (from 46% to 51.2%) over PECOS with a recursive linear matcher but takes 265x more time to train. We also develop fast real time inference procedures; for example, inference takes less than 10 milliseconds on the data set with 2.8 million labels.
Towards Lower Bit Multiplication for Convolutional Neural Network Training
Jun 04, 2020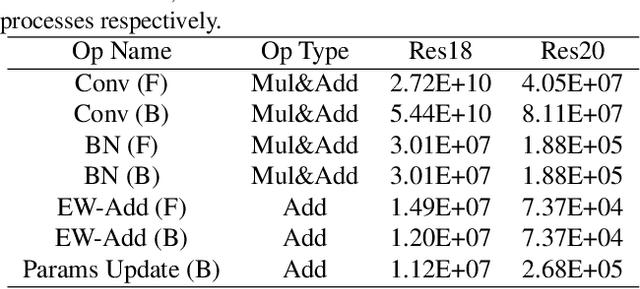
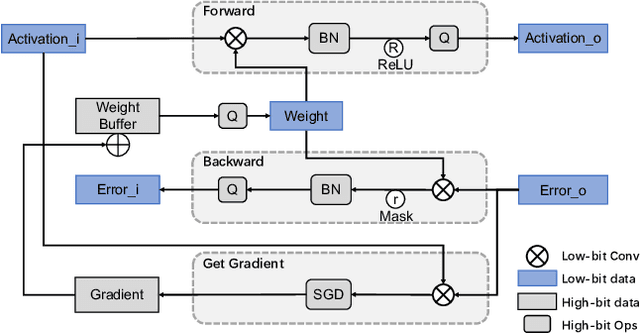
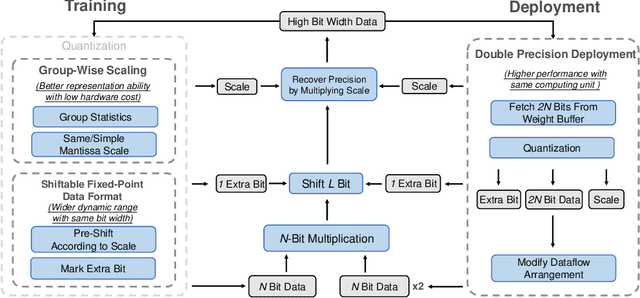
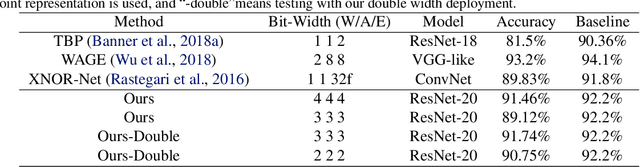
Convolutional Neural Networks (CNNs) have been widely used in many fields. However, the training process costs much energy and time, in which the convolution operations consume the major part. In this paper, we propose a fixed-point training framework, in order to reduce the data bit-width for the convolution multiplications. Firstly, we propose two constrained group-wise scaling methods that can be implemented with low hardware cost. Secondly, to overcome the challenge of trading off overflow and rounding error, a shiftable fixed-point data format is used in this framework. Finally, we propose a double-width deployment technique to boost inference performance with the same bit-width hardware multiplier. The experimental results show that the input data of convolution in the training process can be quantized to 2-bit for CIFAR-10 dataset, 6-bit for ImageNet dataset, with negligible accuracy degradation. Furthermore, our fixed-point train-ing framework has the potential to save at least 75% energy of the computation in the training process.
Enabling Efficient and Flexible FPGA Virtualization for Deep Learning in the Cloud
Mar 26, 2020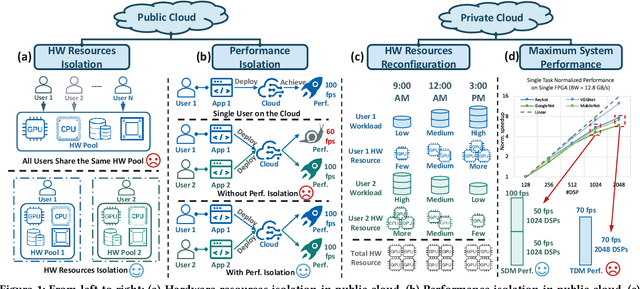
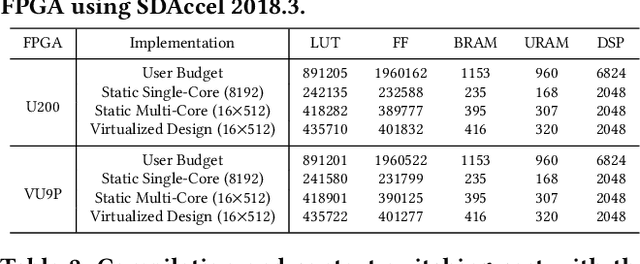
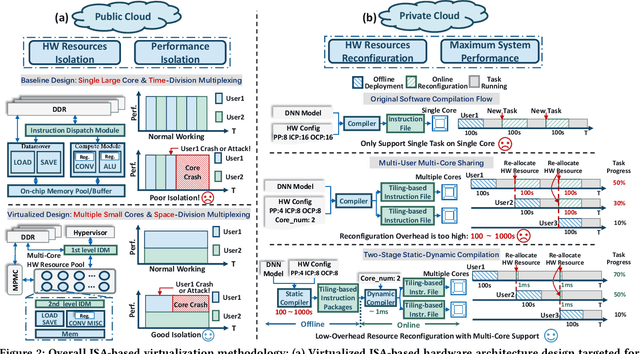
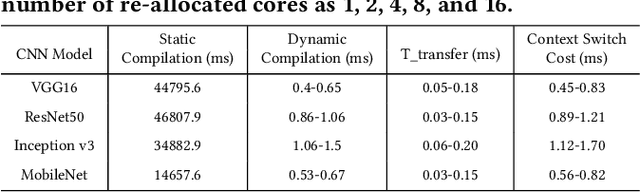
FPGAs have shown great potential in providing low-latency and energy-efficient solutions for deep neural network (DNN) inference applications. Currently, the majority of FPGA-based DNN accelerators in the cloud run in a time-division multiplexing way for multiple users sharing a single FPGA, and require re-compilation with $\sim$100 s overhead. Such designs lead to poor isolation and heavy performance loss for multiple users, which are far away from providing efficient and flexible FPGA virtualization for neither public nor private cloud scenarios. To solve these problems, we introduce a novel virtualization framework for instruction architecture set (ISA) based on DNN accelerators by sharing a single FPGA. We enable the isolation by introducing a two-level instruction dispatch module and a multi-core based hardware resources pool. Such designs provide isolated and runtime-programmable hardware resources, further leading to performance isolation for multiple users. On the other hand, to overcome the heavy re-compilation overheads, we propose a tiling-based instruction frame package design and two-stage static-dynamic compilation. Only the light-weight runtime information is re-compiled with $\sim$1 ms overhead, thus the performance is guaranteed for the private cloud. Our extensive experimental results show that the proposed virtualization design achieves 1.07-1.69x and 1.88-3.12x throughput improvement over previous static designs using the single-core and the multi-core architectures, respectively.
A Modular Deep Learning Approach for Extreme Multi-label Text Classification
May 07, 2019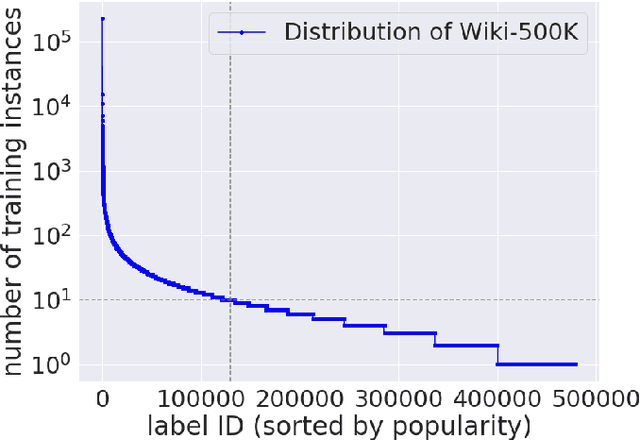

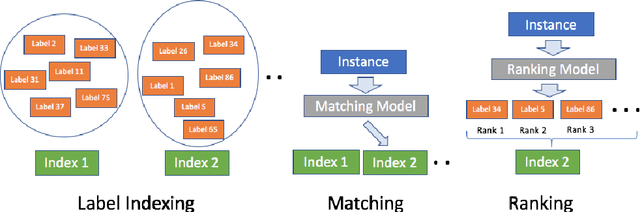
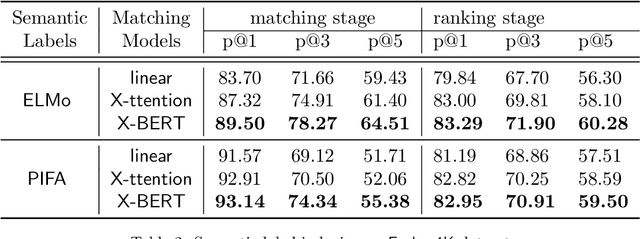
Extreme multi-label classification (XMC) aims to assign to an instance the most relevant subset of labels from a colossal label set. Due to modern applications that lead to massive label sets, the scalability of XMC has attracted much recent attention from both academia and industry. In this paper, we establish a three-stage framework to solve XMC efficiently, which includes 1) indexing the labels, 2) matching the instance to the relevant indices, and 3) ranking the labels from the relevant indices. This framework unifies many existing XMC approaches. Based on this framework, we propose a modular deep learning approach SLINMER: Semantic Label Indexing, Neural Matching, and Efficient Ranking. The label indexing stage of SLINMER can adopt different semantic label representations leading to different configurations of SLINMER. Empirically, we demonstrate that several individual configurations of SLINMER achieve superior performance than the state-of-the-art XMC approaches on several benchmark datasets. Moreover, by ensembling those configurations, SLINMER can achieve even better results. In particular, on a Wiki dataset with around 0.5 millions of labels, the precision@1 is increased from 61% to 67%.
Binary Classification with Karmic, Threshold-Quasi-Concave Metrics
Jun 02, 2018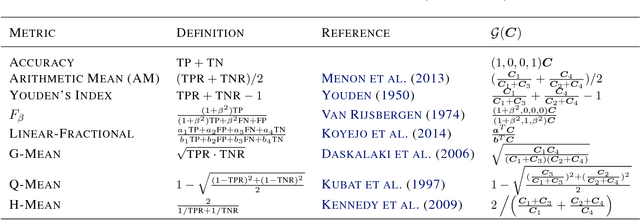
Complex performance measures, beyond the popular measure of accuracy, are increasingly being used in the context of binary classification. These complex performance measures are typically not even decomposable, that is, the loss evaluated on a batch of samples cannot typically be expressed as a sum or average of losses evaluated at individual samples, which in turn requires new theoretical and methodological developments beyond standard treatments of supervised learning. In this paper, we advance this understanding of binary classification for complex performance measures by identifying two key properties: a so-called Karmic property, and a more technical threshold-quasi-concavity property, which we show is milder than existing structural assumptions imposed on performance measures. Under these properties, we show that the Bayes optimal classifier is a threshold function of the conditional probability of positive class. We then leverage this result to come up with a computationally practical plug-in classifier, via a novel threshold estimator, and further, provide a novel statistical analysis of classification error with respect to complex performance measures.
Nonlinear Inductive Matrix Completion based on One-layer Neural Networks
May 26, 2018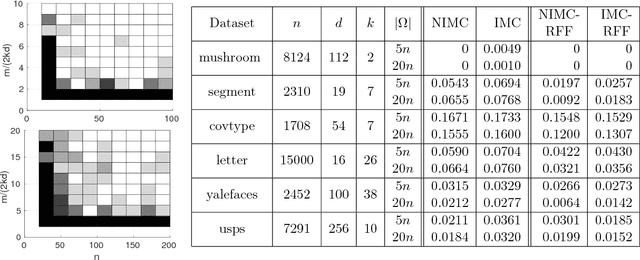

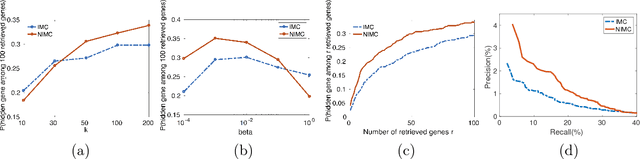
The goal of a recommendation system is to predict the interest of a user in a given item by exploiting the existing set of ratings as well as certain user/item features. A standard approach to modeling this problem is Inductive Matrix Completion where the predicted rating is modeled as an inner product of the user and the item features projected onto a latent space. In order to learn the parameters effectively from a small number of observed ratings, the latent space is constrained to be low-dimensional which implies that the parameter matrix is constrained to be low-rank. However, such bilinear modeling of the ratings can be limiting in practice and non-linear prediction functions can lead to significant improvements. A natural approach to introducing non-linearity in the prediction function is to apply a non-linear activation function on top of the projected user/item features. Imposition of non-linearities further complicates an already challenging problem that has two sources of non-convexity: a) low-rank structure of the parameter matrix, and b) non-linear activation function. We show that one can still solve the non-linear Inductive Matrix Completion problem using gradient descent type methods as long as the solution is initialized well. That is, close to the optima, the optimization function is strongly convex and hence admits standard optimization techniques, at least for certain activation functions, such as Sigmoid and tanh. We also highlight the importance of the activation function and show how ReLU can behave significantly differently than say a sigmoid function. Finally, we apply our proposed technique to recommendation systems and semi-supervised clustering, and show that our method can lead to much better performance than standard linear Inductive Matrix Completion methods.
Online Classification with Complex Metrics
Feb 10, 2018We present a framework and analysis of consistent binary classification for complex and non-decomposable performance metrics such as the F-measure and the Jaccard measure. The proposed framework is general, as it applies to both batch and online learning, and to both linear and non-linear models. Our work follows recent results showing that the Bayes optimal classifier for many complex metrics is given by a thresholding of the conditional probability of the positive class. This manuscript extends this thresholding characterization -- showing that the utility is strictly locally quasi-concave with respect to the threshold for a wide range of models and performance metrics. This, in turn, motivates simple normalized gradient ascent updates for threshold estimation. We present a finite-sample regret analysis for the resulting procedure. In particular, the risk for the batch case converges to the Bayes risk at the same rate as that of the underlying conditional probability estimation, and the risk of proposed online algorithm converges at a rate that depends on the conditional probability estimation risk. For instance, in the special case where the conditional probability model is logistic regression, our procedure achieves $O(\frac{1}{\sqrt{n}})$ sample complexity, both for batch and online training. Empirical evaluation shows that the proposed algorithms out-perform alternatives in practice, with comparable or better prediction performance and reduced run time for various metrics and datasets.