 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybridGNN: Learning Hybrid Representation in Multiplex Heterogeneous Networks
Aug 03, 2022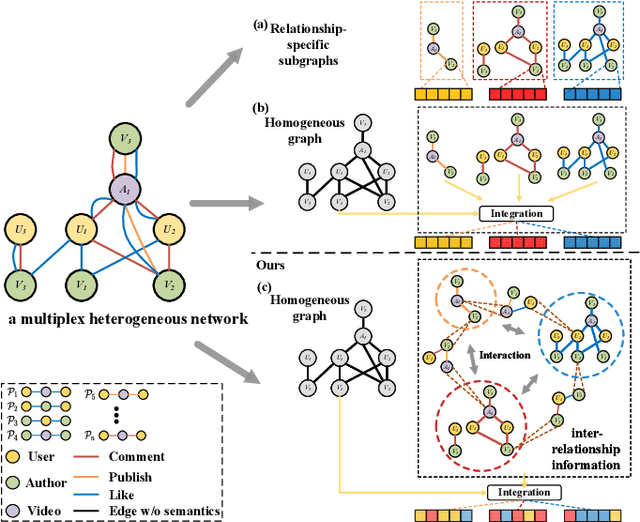
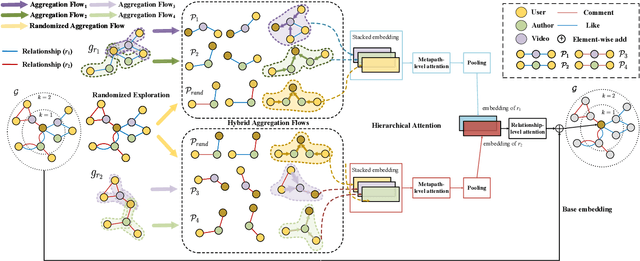
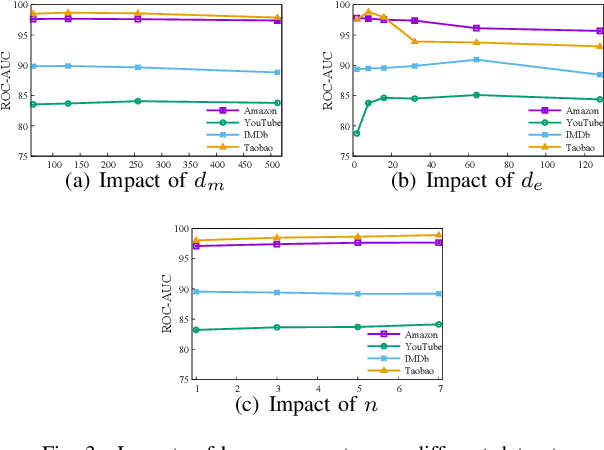
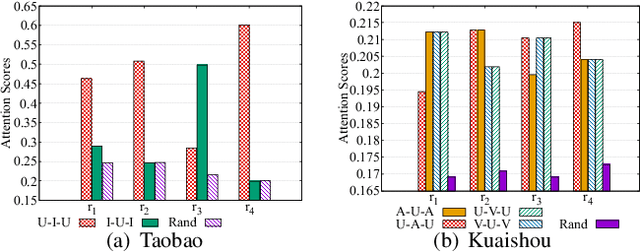
Recently, graph neural networks have shown the superiority of modeling the complex topological structures in heterogeneous network-based recommender systems. Due to the diverse interactions among nodes and abundant semantics emerging from diverse types of nodes and edges, there is a bursting research interest in learning expressive node representations in multiplex heterogeneous networks. One of the most important tasks in recommender systems is to predict the potential connection between two nodes under a specific edge type (i.e., relationship). Although existing studies utilize explicit metapaths to aggregate neighbors, practically they only consider intra-relationship metapaths and thus fail to leverage the potential uplift by inter-relationship information. Moreover, it is not always straightforward to exploit inter-relationship metapaths comprehensively under diverse relationships, especially with the increasing number of node and edge types. In addition, contributions of different relationships between two nodes are difficult to measure. To address the challenges, we propose HybridGNN, an end-to-end GNN model with hybrid aggregation flows and hierarchical attentions to fully utilize the heterogeneity in the multiplex scenarios. Specifically, HybridGNN applies a randomized inter-relationship exploration module to exploit the multiplexity property among different relationships. Then, our model leverages hybrid aggregation flows under intra-relationship metapaths and randomized exploration to learn the rich semantics. To explore the importance of different aggregation flow and take advantage of the multiplexity property, we bring forward a novel hierarchical attention module which leverages both metapath-level attention and relationship-level attention. Extensive experimental results suggest that HybridGNN achieves the best performance compared to several state-of-the-art baselines.
AutoTransition: Learning to Recommend Video Transition Effects
Jul 27, 2022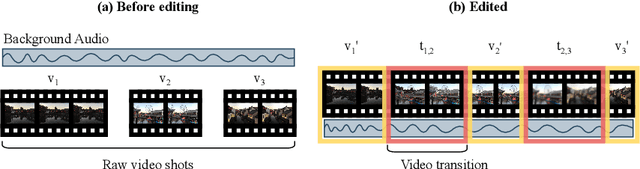
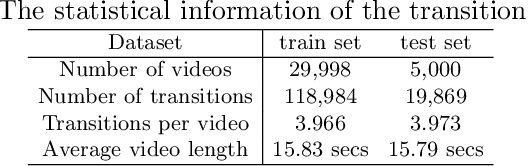
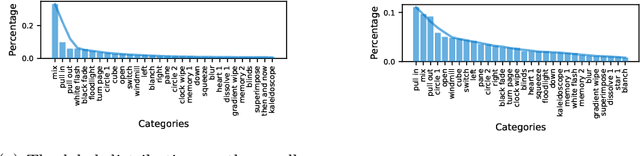
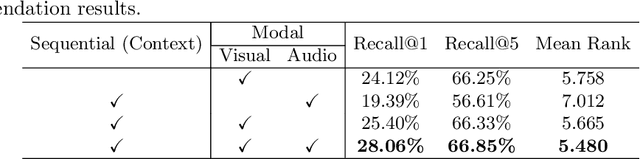
Video transition effects are widely used in video editing to connect shots for creating cohesive and visually appealing videos. However, it is challenging for non-professionals to choose best transitions due to the lack of cinematographic knowledge and design skills. In this paper, we present the premier work on performing automatic video transitions recommendation (VTR): given a sequence of raw video shots and companion audio, recommend video transitions for each pair of neighboring shots. To solve this task, we collect a large-scale video transition dataset using publicly available video templates on editing softwares. Then we formulate VTR as a multi-modal retrieval problem from vision/audio to video transitions and propose a novel multi-modal matching framework which consists of two parts. First we learn the embedding of video transitions through a video transition classification task. Then we propose a model to learn the matching correspondence from vision/audio inputs to video transitions. Specifically, the proposed model employs a multi-modal transformer to fuse vision and audio information, as well as capture the context cues in sequential transition outputs. Through both quantitative and qualitative experiments, we clearly demonstrate the effectiveness of our method. Notably, in the comprehensive user study, our method receives comparable scores compared with professional editors while improving the video editing efficiency by \textbf{300\scalebox{1.25}{$\times$}}. We hope our work serves to inspire other researchers to work on this new task. The dataset and codes are public at \url{https://github.com/acherstyx/AutoTransition}.
Repairing Systematic Outliers by Learning Clean Subspaces in VAEs
Jul 17, 2022
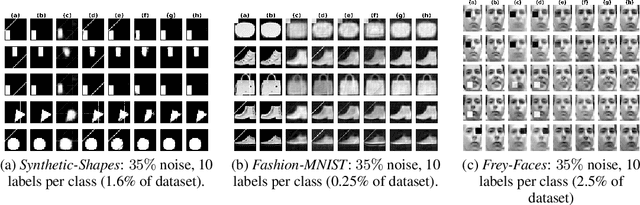
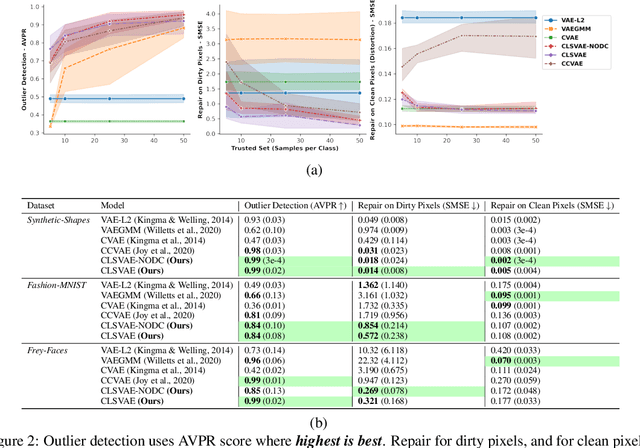

Data cleaning often comprises outlier detection and data repair. Systematic errors result from nearly deterministic transformations that occur repeatedly in the data, e.g. specific image pixels being set to default values or watermarks. Consequently, models with enough capacity easily overfit to these errors, making detection and repair difficult. Seeing as a systematic outlier is a combination of patterns of a clean instance and systematic error patterns, our main insight is that inliers can be modelled by a smaller representation (subspace) in a model than outliers. By exploiting this, we propose Clean Subspace Variational Autoencoder (CLSVAE), a novel semi-supervised model for detection and automated repair of systematic errors. The main idea is to partition the latent space and model inlier and outlier patterns separately. CLSVAE is effective with much less labelled data compared to previous related models, often with less than 2% of the data. We provide experiments using three image datasets in scenarios with different levels of corruption and labelled set sizes, comparing to relevant baselines. CLSVAE provides superior repairs without human intervention, e.g. with just 0.25% of labelled data we see a relative error decrease of 58% compared to the closest baseline.
dpart: Differentially Private Autoregressive Tabular, a General Framework for Synthetic Data Generation
Jul 12, 2022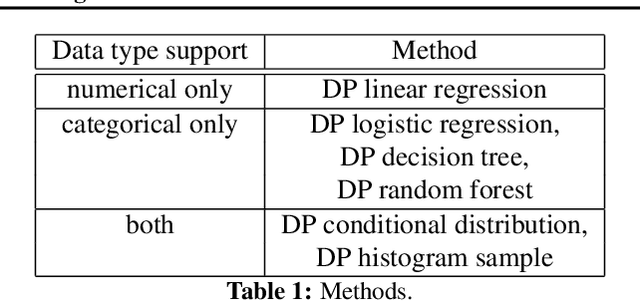
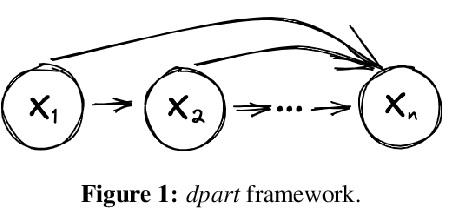
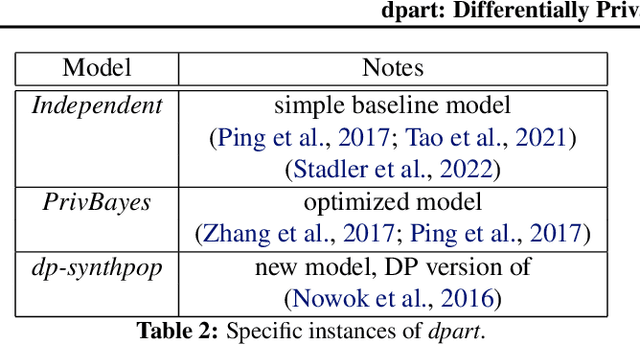

We propose a general, flexible, and scalable framework dpart, an open source Python library for differentially private synthetic data generation. Central to the approach is autoregressive modelling -- breaking the joint data distribution to a sequence of lower-dimensional conditional distributions, captured by various methods such as machine learning models (logistic/linear regression, decision trees, etc.), simple histogram counts, or custom techniques. The library has been created with a view to serve as a quick and accessible baseline as well as to accommodate a wide audience of users, from those making their first steps in synthetic data generation, to more experienced ones with domain expertise who can configure different aspects of the modelling and contribute new methods/mechanisms. Specific instances of dpart include Independent, an optimized version of PrivBayes, and a newly proposed model, dp-synthpop. Code: https://github.com/hazy/dpart
RayMVSNet: Learning Ray-based 1D Implicit Fields for Accurate Multi-View Stereo
Apr 04, 2022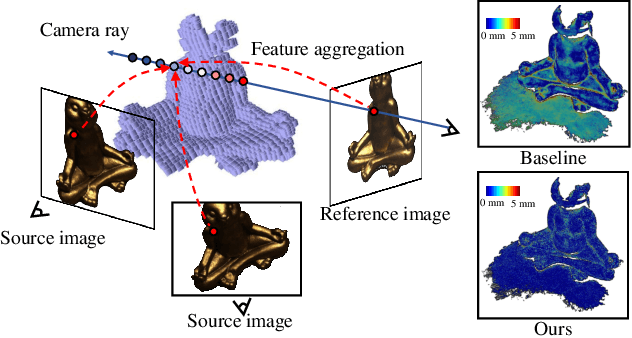
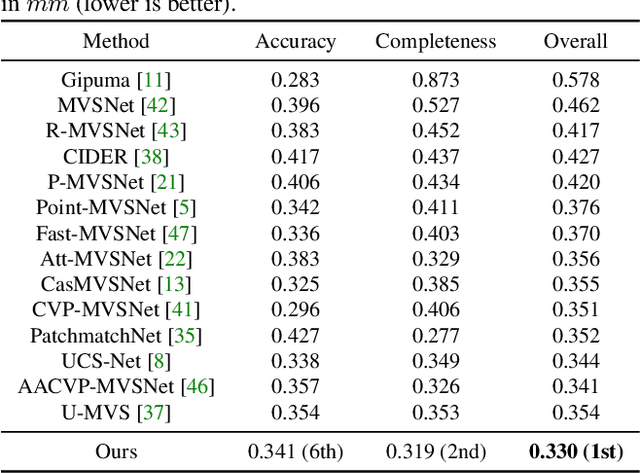
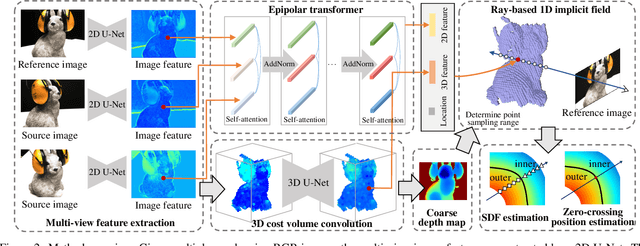
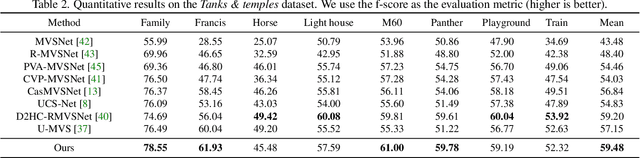
Learning-based multi-view stereo (MVS) has by far centered around 3D convolution on cost volumes. Due to the high computation and memory consumption of 3D CNN, the resolution of output depth is often considerably limited. Different from most existing works dedicated to adaptive refinement of cost volumes, we opt to directly optimize the depth value along each camera ray, mimicking the range (depth) finding of a laser scanner. This reduces the MVS problem to ray-based depth optimization which is much more light-weight than full cost volume optimization. In particular, we propose RayMVSNet which learns sequential prediction of a 1D implicit field along each camera ray with the zero-crossing point indicating scene depth. This sequential modeling, conducted based on transformer features, essentially learns the epipolar line search in traditional multi-view stereo. We also devise a multi-task learning for better optimization convergence and depth accuracy. Our method ranks top on both the DTU and the Tanks \& Temples datasets over all previous learning-based methods, achieving overall reconstruction score of 0.33mm on DTU and f-score of 59.48% on Tanks & Temples.
Geometric Transformer for Fast and Robust Point Cloud Registration
Mar 12, 2022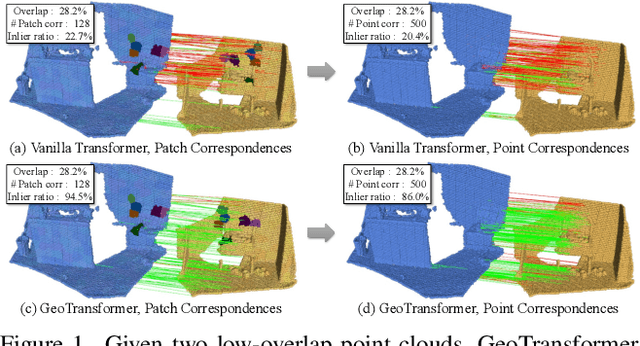
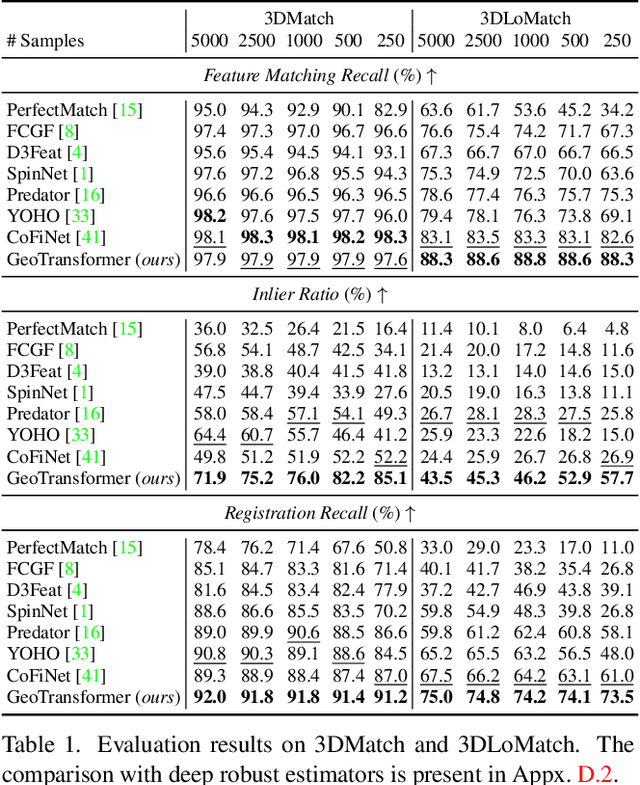
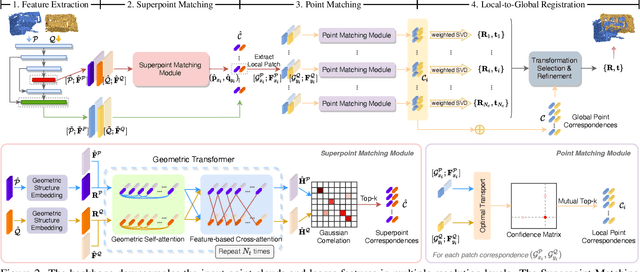
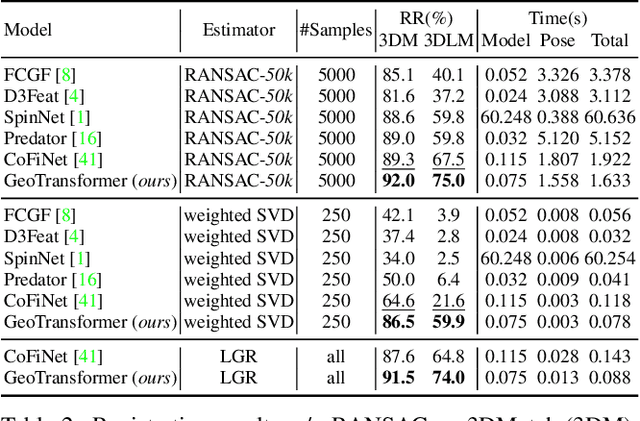
We study the problem of extracting accurate correspondences for point cloud registration. Recent keypoint-free methods bypass the detection of repeatable keypoints which is difficult in low-overlap scenarios, showing great potential in registration. They seek correspondences over downsampled superpoints, which are then propagated to dense points. Superpoints are matched based on whether their neighboring patches overlap. Such sparse and loose matching requires contextual features capturing the geometric structure of the point clouds. We propose Geometric Transformer to learn geometric feature for robust superpoint matching. It encodes pair-wise distances and triplet-wise angles, making it robust in low-overlap cases and invariant to rigid transformation. The simplistic design attains surprisingly high matching accuracy such that no RANSAC is required in the estimation of alignment transformation, leading to $100$ times acceleration. Our method improves the inlier ratio by $17{\sim}30$ percentage points and the registration recall by over $7$ points on the challenging 3DLoMatch benchmark. Our code and models are available at \url{https://github.com/qinzheng93/GeoTransformer}.
DisARM: Displacement Aware Relation Module for 3D Detection
Mar 02, 2022
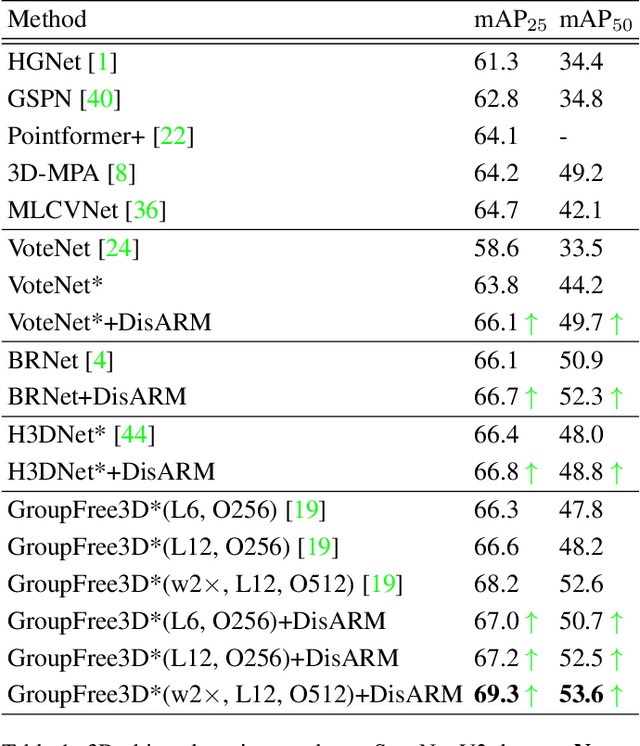
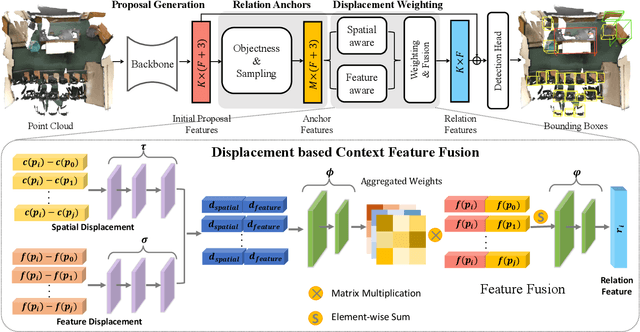
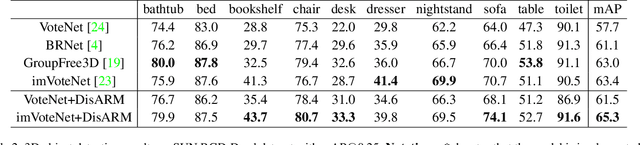
We introduce Displacement Aware Relation Module (DisARM), a novel neural network module for enhancing the performance of 3D object detection in point cloud scenes. The core idea of our method is that contextual information is critical to tell the difference when the instance geometry is incomplete or featureless. We find that relations between proposals provide a good representation to describe the context. However, adopting relations between all the object or patch proposals for detection is inefficient, and an imbalanced combination of local and global relations brings extra noise that could mislead the training. Rather than working with all relations, we found that training with relations only between the most representative ones, or anchors, can significantly boost the detection performance. A good anchor should be semantic-aware with no ambiguity and independent with other anchors as well. To find the anchors, we first perform a preliminary relation anchor module with an objectness-aware sampling approach and then devise a displacement-based module for weighing the relation importance for better utilization of contextual information. This lightweight relation module leads to significantly higher accuracy of object instance detection when being plugged into the state-of-the-art detectors. Evaluations on the public benchmarks of real-world scenes show that our method achieves state-of-the-art performance on both SUN RGB-D and ScanNet V2.
DropIT: Dropping Intermediate Tensors for Memory-Efficient DNN Training
Feb 28, 2022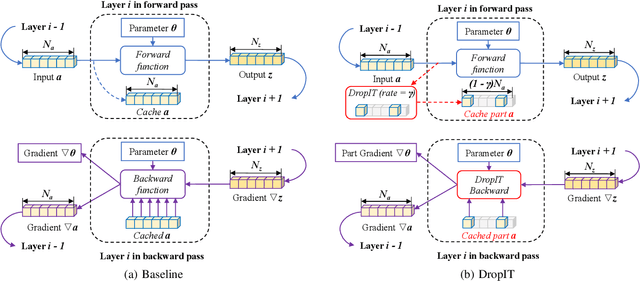
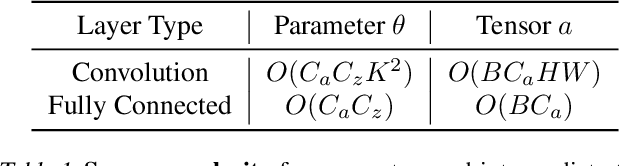
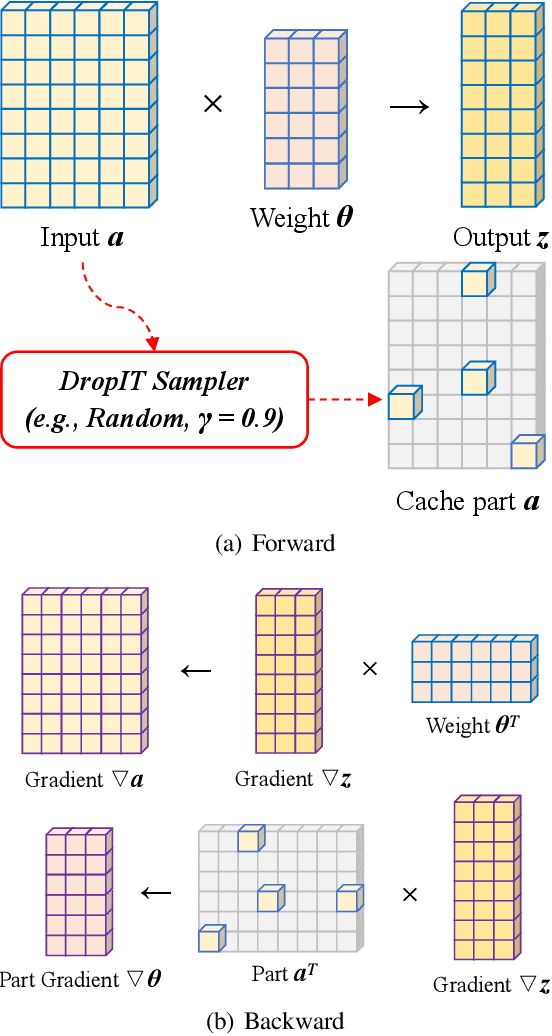
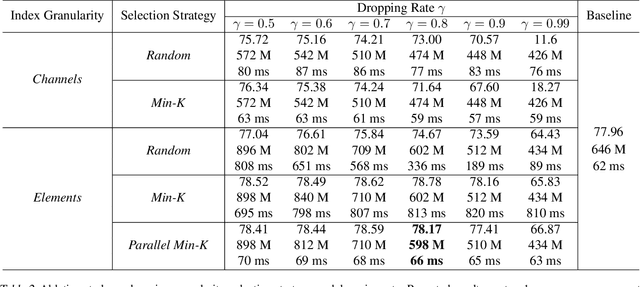
A standard hardware bottleneck when training deep neural networks is GPU memory. The bulk of memory is occupied by caching intermediate tensors for gradient computation in the backward pass. We propose a novel method to reduce this footprint by selecting and caching part of intermediate tensors for gradient computation. Our Intermediate Tensor Drop method (DropIT) adaptively drops components of the intermediate tensors and recovers sparsified tensors from the remaining elements in the backward pass to compute the gradient. Experiments show that we can drop up to 90% of the elements of the intermediate tensors in convolutional and fully-connected layers, saving 20% GPU memory during training while achieving higher test accuracy for standard backbones such as ResNet and Vision Transformer. Our code is available at https://github.com/ChenJoya/dropit.
3DRM:Pair-wise relation module for 3D object detection
Feb 20, 2022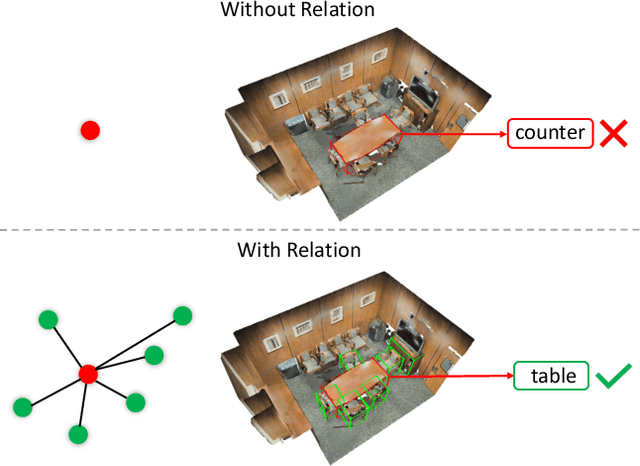
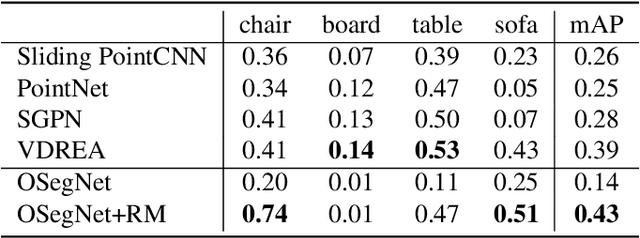
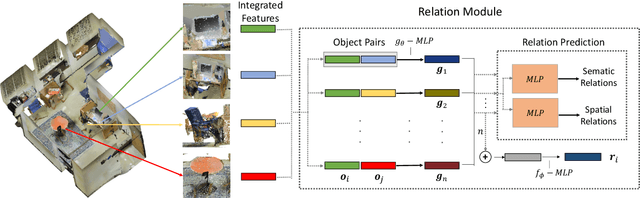
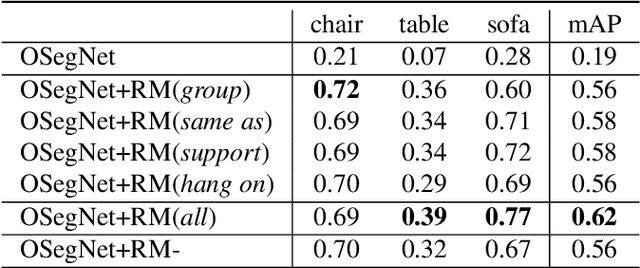
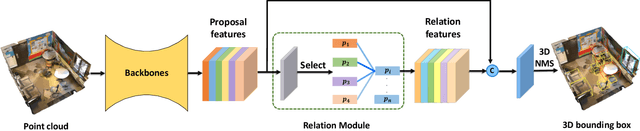
Context has proven to be one of the most important factors in object layout reasoning for 3D scene understanding. Existing deep contextual models either learn holistic features for context encoding or rely on pre-defined scene templates for context modeling. We argue that scene understanding benefits from object relation reasoning, which is capable of mitigating the ambiguity of 3D object detections and thus helps locate and classify the 3D objects more accurately and robustly. To achieve this, we propose a novel 3D relation module (3DRM) which reasons about object relations at pair-wise levels. The 3DRM predicts the semantic and spatial relationships between objects and extracts the object-wise relation features. We demonstrate the effects of 3DRM by plugging it into proposal-based and voting-based 3D object detection pipelines, respectively. Extensive evaluations show the effectiveness and generalization of 3DRM on 3D object detection. Our source code is available at https://github.com/lanlan96/3DRM.
* 13 pages, 8 figures
ARM3D: Attention-based relation module for indoor 3D object detection
Feb 20, 2022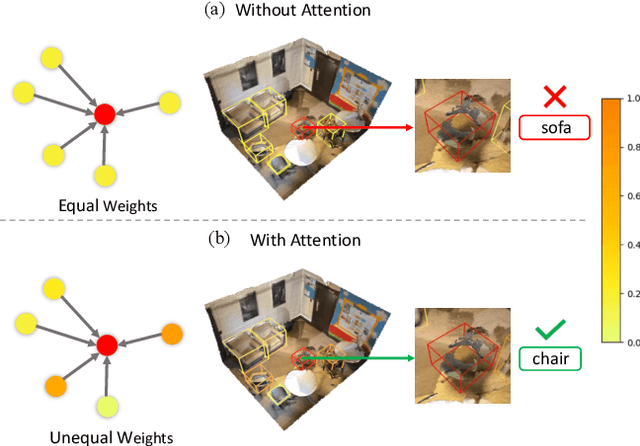
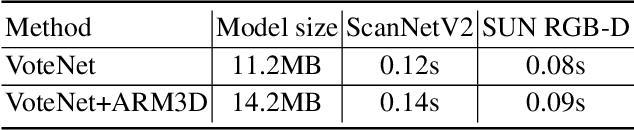
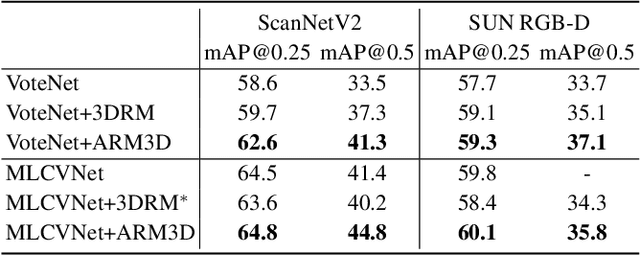
Relation context has been proved to be useful for many challenging vision tasks. In the field of 3D object detection, previous methods have been taking the advantage of context encoding, graph embedding, or explicit relation reasoning to extract relation context. However, there exists inevitably redundant relation context due to noisy or low-quality proposals. In fact, invalid relation context usually indicates underlying scene misunderstanding and ambiguity, which may, on the contrary, reduce the performance in complex scenes. Inspired by recent attention mechanism like Transformer, we propose a novel 3D attention-based relation module (ARM3D). It encompasses object-aware relation reasoning to extract pair-wise relation contexts among qualified proposals and an attention module to distribute attention weights towards different relation contexts. In this way, ARM3D can take full advantage of the useful relation context and filter those less relevant or even confusing contexts, which mitigates the ambiguity in detection. We have evaluated the effectiveness of ARM3D by plugging it into several state-of-the-art 3D object detectors and showing more accurate and robust detection results. Extensive experiments show the capability and generalization of ARM3D on 3D object detection. Our source code is available at https://github.com/lanlan96/ARM3D.