 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Oct 12, 2022



Recently, substantial progress has been made in text ranking based on pretrained language models such as BERT. However, there are limited studies on how to leverage more powerful sequence-to-sequence models such as T5. Existing attempts usually formulate text ranking as classification and rely on postprocessing to obtain a ranked list. In this paper, we propose RankT5 and study two T5-based ranking model structures, an encoder-decoder and an encoder-only one, so that they not only can directly output ranking scores for each query-document pair, but also can be fine-tuned with "pairwise" or "listwise" ranking losses to optimize ranking performances. Our experiments show that the proposed models with ranking losses can achieve substantial ranking performance gains on different public text ranking data sets. Moreover, when fine-tuned with listwise ranking losses, the ranking model appears to have better zero-shot ranking performance on out-of-domain data sets compared to the model fine-tuned with classification losses.
Retrieval Augmentation for T5 Re-ranker using External Sources
Oct 11, 2022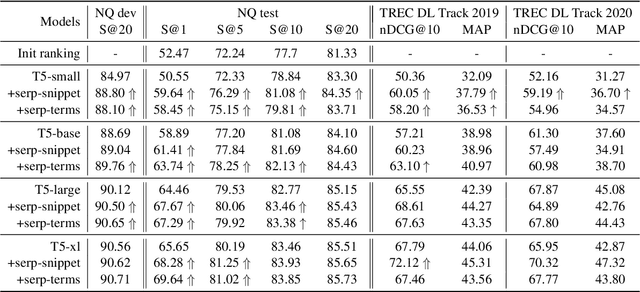
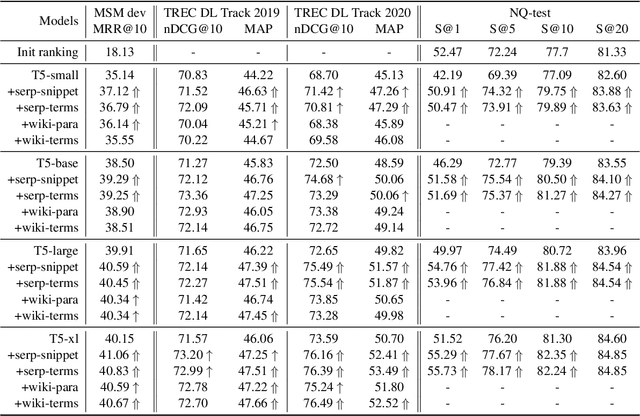
Retrieval augmentation has shown promising improvements in different tasks. However, whether such augmentation can assist a large language model based re-ranker remains unclear. We investigate how to augment T5-based re-rankers using high-quality information retrieved from two external corpora -- a commercial web search engine and Wikipedia. We empirically demonstrate how retrieval augmentation can substantially improve the effectiveness of T5-based re-rankers for both in-domain and zero-shot out-of-domain re-ranking tasks.
ED2LM: Encoder-Decoder to Language Model for Faster Document Re-ranking Inference
Apr 25, 2022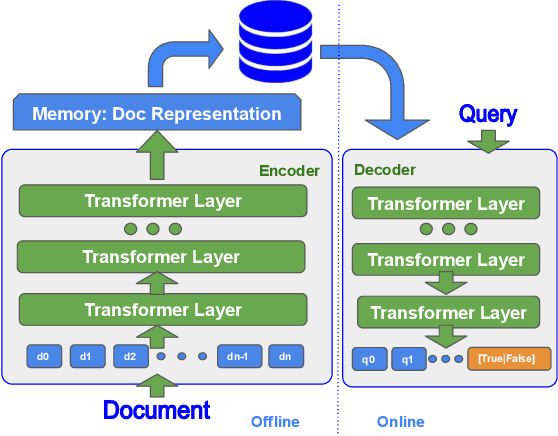
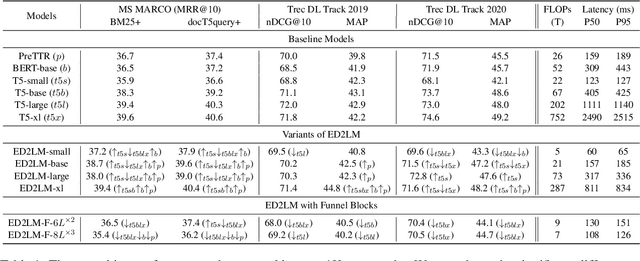
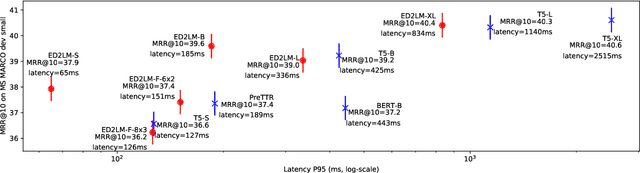
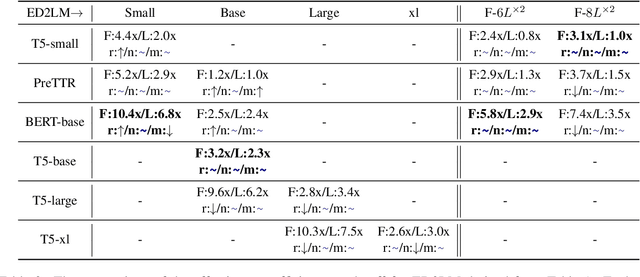
State-of-the-art neural models typically encode document-query pairs using cross-attention for re-ranking. To this end, models generally utilize an encoder-only (like BERT) paradigm or an encoder-decoder (like T5) approach. These paradigms, however, are not without flaws, i.e., running the model on all query-document pairs at inference-time incurs a significant computational cost. This paper proposes a new training and inference paradigm for re-ranking. We propose to finetune a pretrained encoder-decoder model using in the form of document to query generation. Subsequently, we show that this encoder-decoder architecture can be decomposed into a decoder-only language model during inference. This results in significant inference time speedups since the decoder-only architecture only needs to learn to interpret static encoder embeddings during inference. Our experiments show that this new paradigm achieves results that are comparable to the more expensive cross-attention ranking approaches while being up to 6.8X faster. We believe this work paves the way for more efficient neural rankers that leverage large pretrained models.
Transformer Memory as a Differentiable Search Index
Feb 16, 2022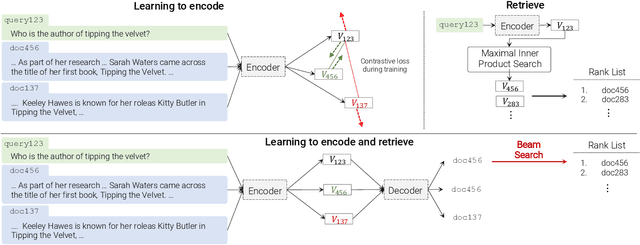
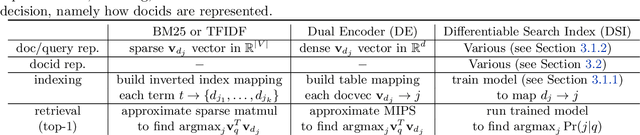
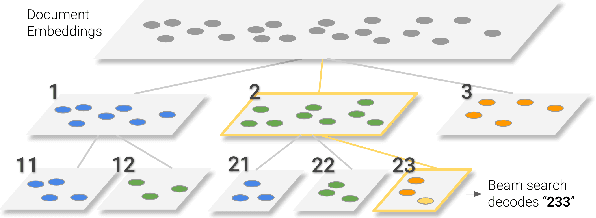
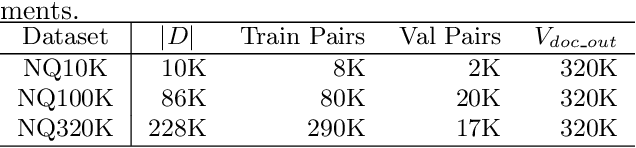
In this paper, we demonstrate that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. To this end, we introduce the Differentiable Search Index (DSI), a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
ExT5: Towards Extreme Multi-Task Scaling for Transfer Learning
Nov 22, 2021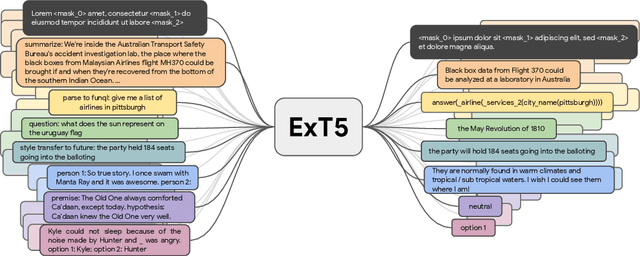
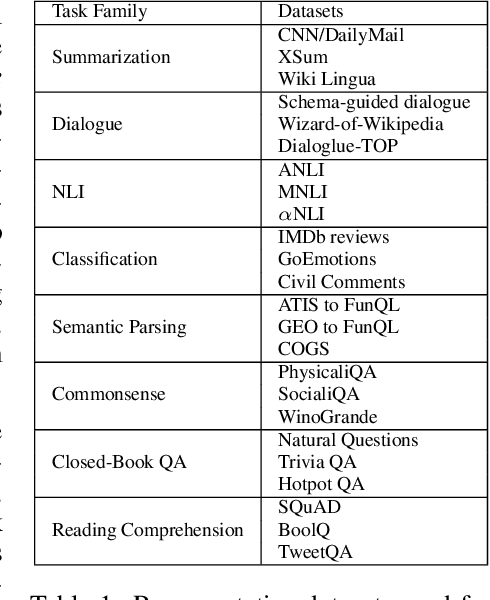
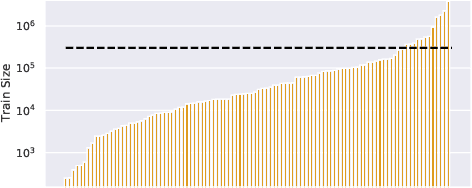
Despite the recent success of multi-task learning and transfer learning for natural language processing (NLP), few works have systematically studied the effect of scaling up the number of tasks during pre-training. Towards this goal, this paper introduces ExMix (Extreme Mixture): a massive collection of 107 supervised NLP tasks across diverse domains and task-families. Using ExMix, we study the effect of multi-task pre-training at the largest scale to date, and analyze co-training transfer amongst common families of tasks. Through this analysis, we show that manually curating an ideal set of tasks for multi-task pre-training is not straightforward, and that multi-task scaling can vastly improve models on its own. Finally, we propose ExT5: a model pre-trained using a multi-task objective of self-supervised span denoising and supervised ExMix. Via extensive experiments, we show that ExT5 outperforms strong T5 baselines on SuperGLUE, GEM, Rainbow, Closed-Book QA tasks, and several tasks outside of ExMix. ExT5 also significantly improves sample efficiency while pre-training.
Transitivity, Time Consumption, and Quality of Preference Judgments in Crowdsourcing
Apr 18, 2021
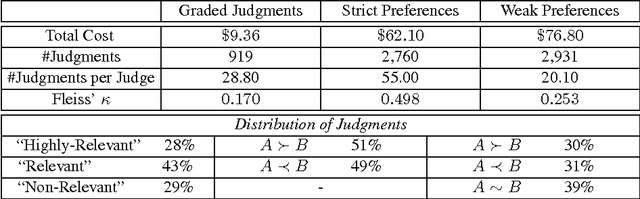
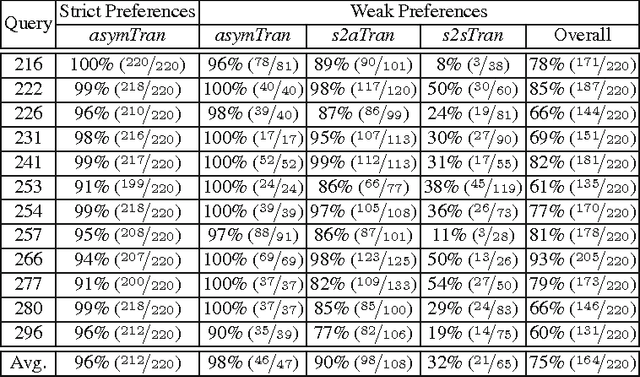
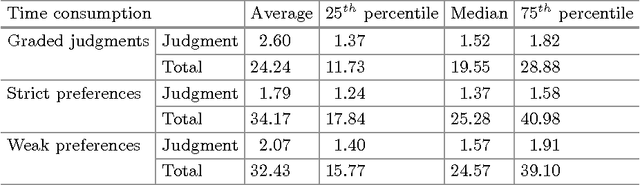
Preference judgments have been demonstrated as a better alternative to graded judgments to assess the relevance of documents relative to queries. Existing work has verified transitivity among preference judgments when collected from trained judges, which reduced the number of judgments dramatically. Moreover, strict preference judgments and weak preference judgments, where the latter additionally allow judges to state that two documents are equally relevant for a given query, are both widely used in literature. However, whether transitivity still holds when collected from crowdsourcing, i.e., whether the two kinds of preference judgments behave similarly remains unclear. In this work, we collect judgments from multiple judges using a crowdsourcing platform and aggregate them to compare the two kinds of preference judgments in terms of transitivity, time consumption, and quality. That is, we look into whether aggregated judgments are transitive, how long it takes judges to make them, and whether judges agree with each other and with judgments from TREC. Our key findings are that only strict preference judgments are transitive. Meanwhile, weak preference judgments behave differently in terms of transitivity, time consumption, as well as of quality of judgment.
Co-BERT: A Context-Aware BERT Retrieval Model Incorporating Local and Query-specific Context
Apr 17, 2021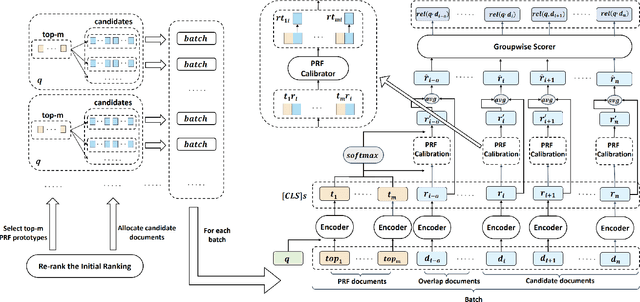
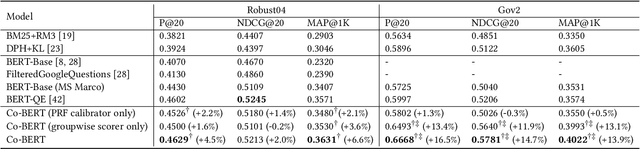
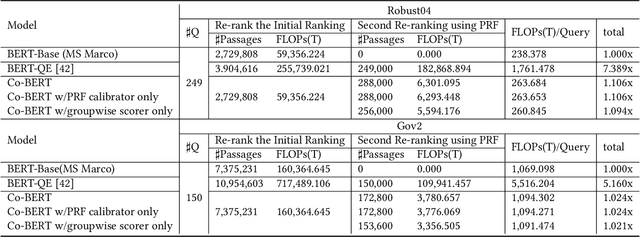

BERT-based text ranking models have dramatically advanced the state-of-the-art in ad-hoc retrieval, wherein most models tend to consider individual query-document pairs independently. In the mean time, the importance and usefulness to consider the cross-documents interactions and the query-specific characteristics in a ranking model have been repeatedly confirmed, mostly in the context of learning to rank. The BERT-based ranking model, however, has not been able to fully incorporate these two types of ranking context, thereby ignoring the inter-document relationships from the ranking and the differences among queries. To mitigate this gap, in this work, an end-to-end transformer-based ranking model, named Co-BERT, has been proposed to exploit several BERT architectures to calibrate the query-document representations using pseudo relevance feedback before modeling the relevance of a group of documents jointly. Extensive experiments on two standard test collections confirm the effectiveness of the proposed model in improving the performance of text re-ranking over strong fine-tuned BERT-Base baselines. We plan to make our implementation open source to enable further comparisons.
BERT-QE: Contextualized Query Expansion for Document Re-ranking
Sep 15, 2020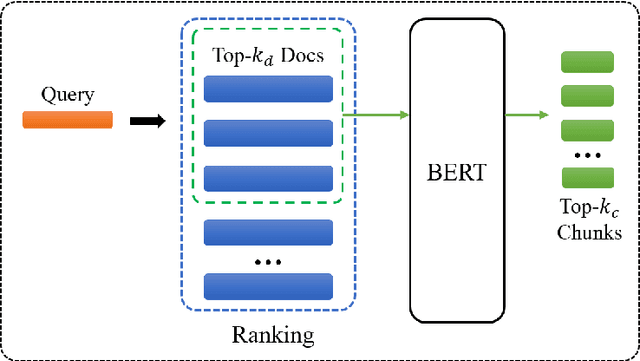
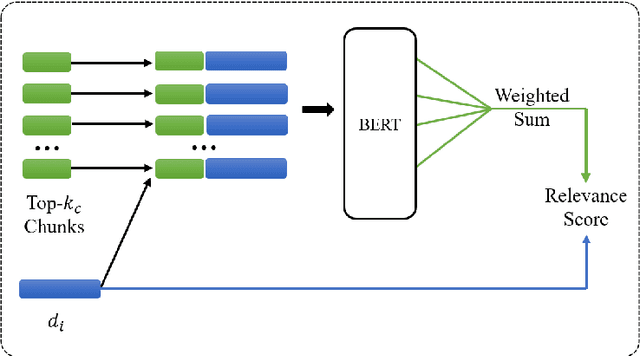
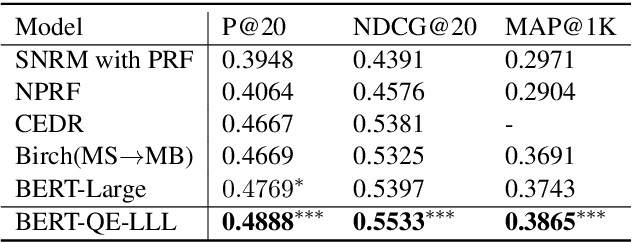
Query expansion aims to mitigate the mismatch between the language used in a query and in a document. Query expansion methods can suffer from introducing non-relevant information when expanding the query, however. To bridge this gap, inspired by recent advances in applying contextualized models like BERT to the document retrieval task, this paper proposes a novel query expansion model that leverages the strength of the BERT model to better select relevant information for expansion. In evaluations on the standard TREC Robust04 and GOV2 test collections, the proposed BERT-QE model significantly outperforms BERT-Large models commonly used for document retrieval.
NPRF: A Neural Pseudo Relevance Feedback Framework for Ad-hoc Information Retrieval
Oct 30, 2018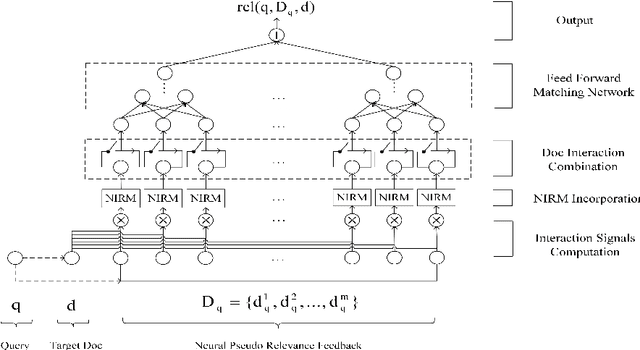
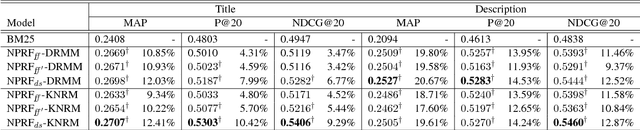
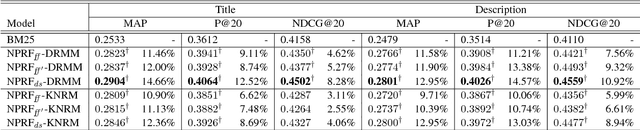
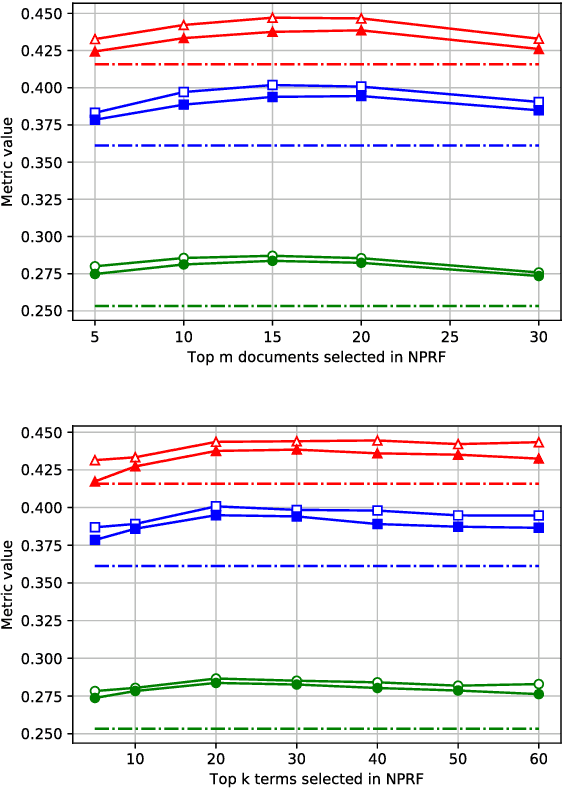
Pseudo-relevance feedback (PRF) is commonly used to boost the performance of traditional information retrieval (IR) models by using top-ranked documents to identify and weight new query terms, thereby reducing the effect of query-document vocabulary mismatches. While neural retrieval models have recently demonstrated strong results for ad-hoc retrieval, combining them with PRF is not straightforward due to incompatibilities between existing PRF approaches and neural architectures. To bridge this gap, we propose an end-to-end neural PRF framework that can be used with existing neural IR models by embedding different neural models as building blocks. Extensive experiments on two standard test collections confirm the effectiveness of the proposed NPRF framework in improving the performance of two state-of-the-art neural IR models.