 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Mining for Cybersecurity: A Survey
Apr 02, 2023



The explosive growth of cyber attacks nowadays, such as malware, spam, and intrusions, caused severe consequences on society. Securing cyberspace has become an utmost concern for organizations and governments. Traditional Machine Learning (ML) based methods are extensively used in detecting cyber threats, but they hardly model the correlations between real-world cyber entities. In recent years, with the proliferation of graph mining techniques, many researchers investigated these techniques for capturing correlations between cyber entities and achieving high performance. It is imperative to summarize existing graph-based cybersecurity solutions to provide a guide for future studies. Therefore, as a key contribution of this paper, we provide a comprehensive review of graph mining for cybersecurity, including an overview of cybersecurity tasks, the typical graph mining techniques, and the general process of applying them to cybersecurity, as well as various solutions for different cybersecurity tasks. For each task, we probe into relevant methods and highlight the graph types, graph approaches, and task levels in their modeling. Furthermore, we collect open datasets and toolkits for graph-based cybersecurity. Finally, we outlook the potential directions of this field for future research.
Cross-modal Search Method of Technology Video based on Adversarial Learning and Feature Fusion
Oct 11, 2022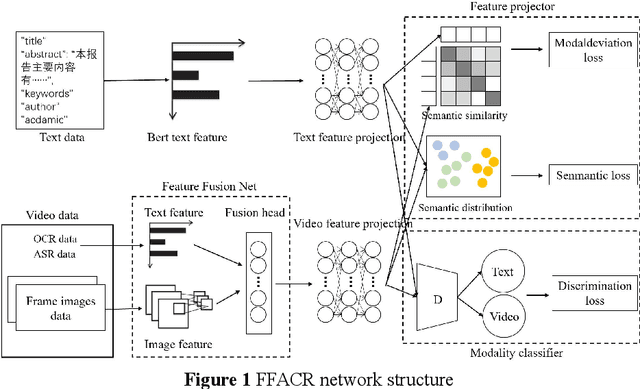
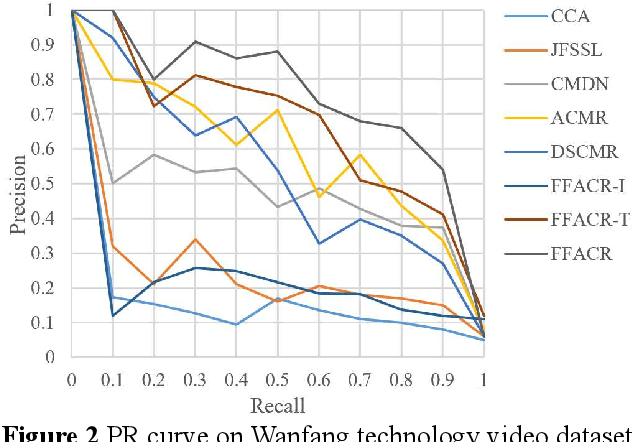
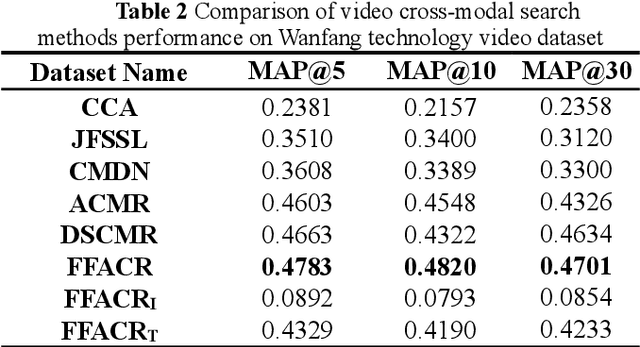
Technology videos contain rich multi-modal information. In cross-modal information search, the data features of different modalities cannot be compared directly, so the semantic gap between different modalities is a key problem that needs to be solved. To address the above problems, this paper proposes a novel Feature Fusion based Adversarial Cross-modal Retrieval method (FFACR) to achieve text-to-video matching, ranking and searching. The proposed method uses the framework of adversarial learning to construct a video multimodal feature fusion network and a feature mapping network as generator, a modality discrimination network as discriminator. Multi-modal features of videos are obtained by the feature fusion network. The feature mapping network projects multi-modal features into the same semantic space based on semantics and similarity. The modality discrimination network is responsible for determining the original modality of features. Generator and discriminator are trained alternately based on adversarial learning, so that the data obtained by the feature mapping network is semantically consistent with the original data and the modal features are eliminated, and finally the similarity is used to rank and obtain the search results in the semantic space. Experimental results demonstrate that the proposed method performs better in text-to-video search than other existing methods, and validate the effectiveness of the method on the self-built datasets of technology videos.
A Relational Triple Extraction Method Based on Feature Reasoning for Technological Patents
Oct 07, 2022



The relation triples extraction method based on table filling can address the issues of relation overlap and bias propagation. However, most of them only establish separate table features for each relationship, which ignores the implicit relationship between different entity pairs and different relationship features. Therefore, a feature reasoning relational triple extraction method based on table filling for technological patents is proposed to explore the integration of entity recognition and entity relationship, and to extract entity relationship triples from multi-source scientific and technological patents data. Compared with the previous methods, the method we proposed for relational triple extraction has the following advantages: 1) The table filling method that saves more running space enhances the speed and efficiency of the model. 2) Based on the features of existing token pairs and table relations, reasoning the implicit relationship features, and improve the accuracy of triple extraction. On five benchmark datasets, we evaluated the model we suggested. The result suggest that our model is advanced and effective, and it performed well on most of these datasets.
Scientific and Technological News Recommendation Based on Knowledge Graph with User Perception
Oct 07, 2022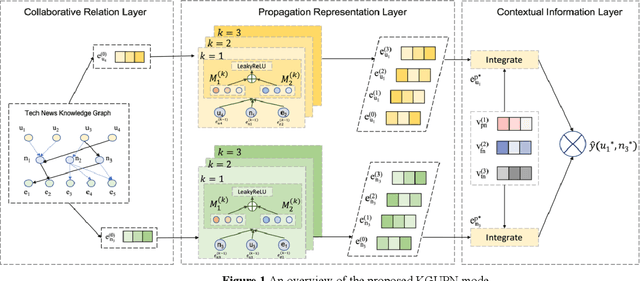
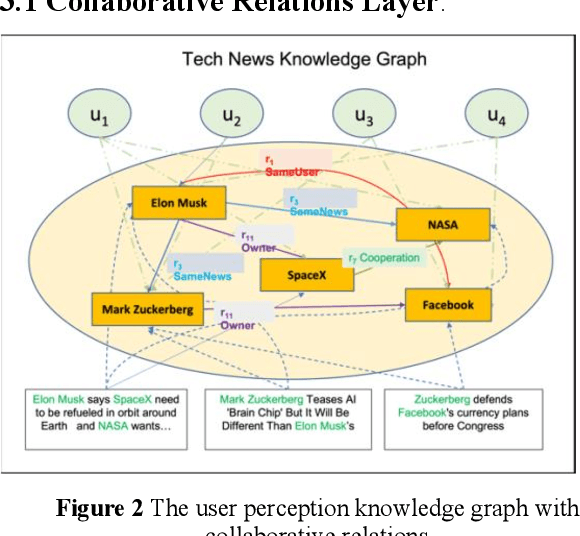
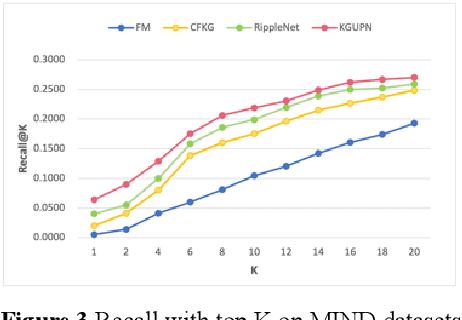
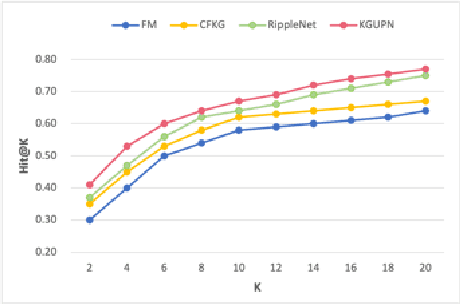
Existing research usually utilizes side information such as social network or item attributes to improve the performance of collaborative filtering-based recommender systems. In this paper, the knowledge graph with user perception is used to acquire the source of side information. We proposed KGUPN to address the limitations of existing embedding-based and path-based knowledge graph-aware recommendation methods, an end-to-end framework that integrates knowledge graph and user awareness into scientific and technological news recommendation systems. KGUPN contains three main layers, which are the propagation representation layer, the contextual information layer and collaborative relation layer. The propagation representation layer improves the representation of an entity by recursively propagating embeddings from its neighbors (which can be users, news, or relationships) in the knowledge graph. The contextual information layer improves the representation of entities by encoding the behavioral information of entities appearing in the news. The collaborative relation layer complements the relationship between entities in the news knowledge graph. Experimental results on real-world datasets show that KGUPN significantly outperforms state-of-the-art baselines in scientific and technological news recommendation.
CCPL: Contrastive Coherence Preserving Loss for Versatile Style Transfer
Jul 19, 2022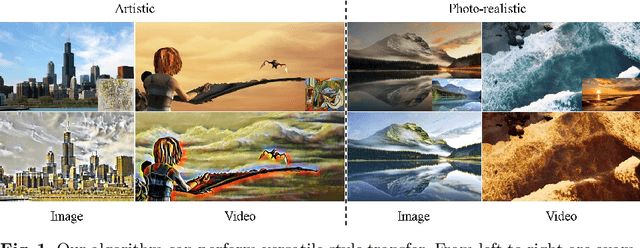
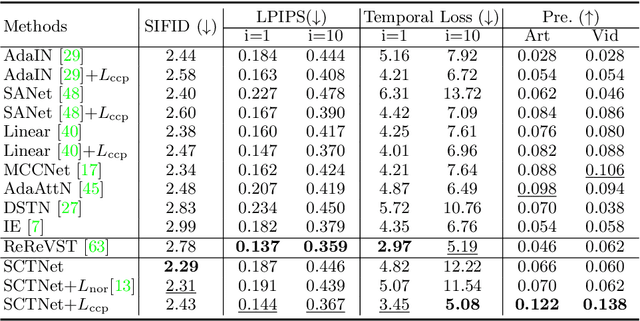
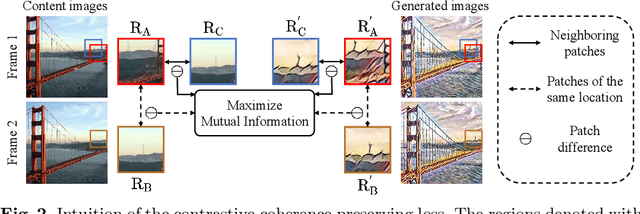

In this paper, we aim to devise a universally versatile style transfer method capable of performing artistic, photo-realistic, and video style transfer jointly, without seeing videos during training. Previous single-frame methods assume a strong constraint on the whole image to maintain temporal consistency, which could be violated in many cases. Instead, we make a mild and reasonable assumption that global inconsistency is dominated by local inconsistencies and devise a generic Contrastive Coherence Preserving Loss (CCPL) applied to local patches. CCPL can preserve the coherence of the content source during style transfer without degrading stylization. Moreover, it owns a neighbor-regulating mechanism, resulting in a vast reduction of local distortions and considerable visual quality improvement. Aside from its superior performance on versatile style transfer, it can be easily extended to other tasks, such as image-to-image translation. Besides, to better fuse content and style features, we propose Simple Covariance Transformation (SCT) to effectively align second-order statistics of the content feature with the style feature. Experiments demonstrate the effectiveness of the resulting model for versatile style transfer, when armed with CCPL.
Aspect-Based Sentiment Analysis using Local Context Focus Mechanism with DeBERTa
Jul 07, 2022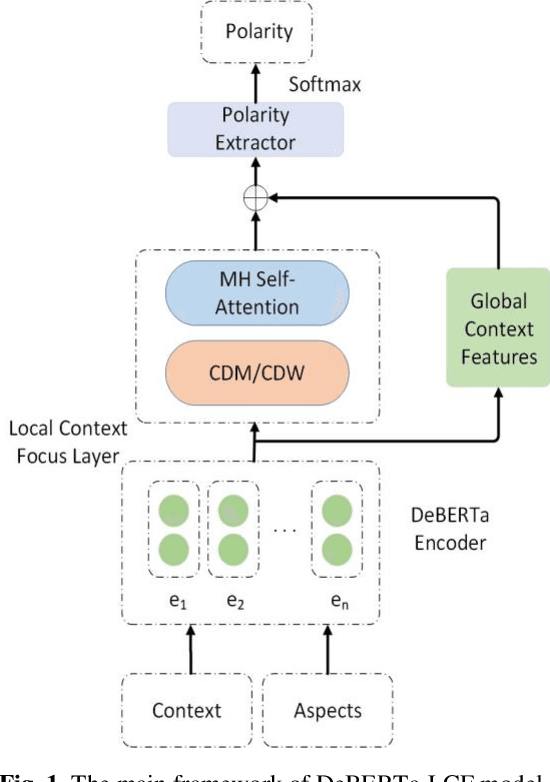

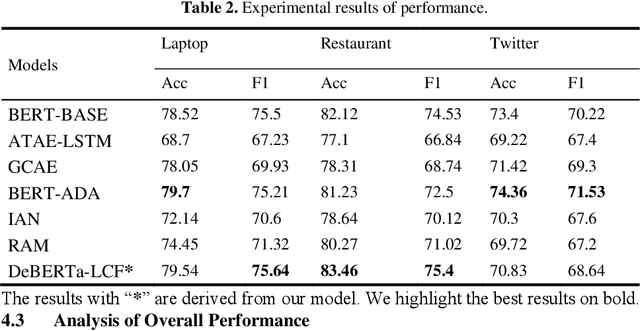
Text sentiment analysis, also known as opinion mining, is research on the calculation of people's views, evaluations, attitude and emotions expressed by entities. Text sentiment analysis can be divided into text-level sentiment analysis, sen-tence-level sentiment analysis and aspect-level sentiment analysis. Aspect-Based Sentiment Analysis (ABSA) is a fine-grained task in the field of sentiment analysis, which aims to predict the polarity of aspects. The research of pre-training neural model has significantly improved the performance of many natural language processing tasks. In recent years, pre training model (PTM) has been applied in ABSA. Therefore, there has been a question, which is whether PTMs contain sufficient syntactic information for ABSA. In this paper, we explored the recent DeBERTa model (Decoding-enhanced BERT with disentangled attention) to solve Aspect-Based Sentiment Analysis problem. DeBERTa is a kind of neural language model based on transformer, which uses self-supervised learning to pre-train on a large number of original text corpora. Based on the Local Context Focus (LCF) mechanism, by integrating DeBERTa model, we purpose a multi-task learning model for aspect-based sentiment analysis. The experiments result on the most commonly used the laptop and restaurant datasets of SemEval-2014 and the ACL twitter dataset show that LCF mechanism with DeBERTa has significant improvement.
A Rare Topic Discovery Model for Short Texts Based on Co-occurrence word Network
Jun 30, 2022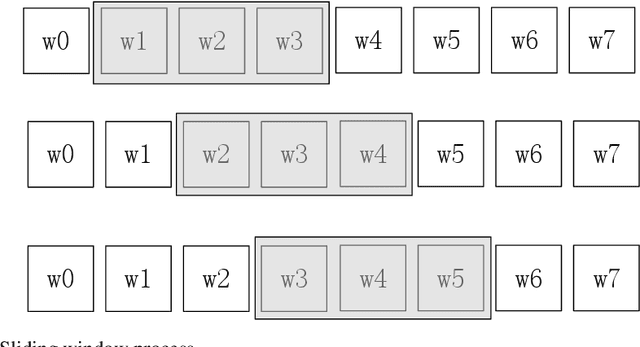


We provide a simple and general solution for the discovery of scarce topics in unbalanced short-text datasets, namely, a word co-occurrence network-based model CWIBTD, which can simultaneously address the sparsity and unbalance of short-text topics and attenuate the effect of occasional pairwise occurrences of words, allowing the model to focus more on the discovery of scarce topics. Unlike previous approaches, CWIBTD uses co-occurrence word networks to model the topic distribution of each word, which improves the semantic density of the data space and ensures its sensitivity in identify-ing rare topics by improving the way node activity is calculated and normal-izing scarce topics and large topics to some extent. In addition, using the same Gibbs sampling as LDA makes CWIBTD easy to be extended to vari-ous application scenarios. Extensive experimental validation in the unbal-anced short text dataset confirms the superiority of CWIBTD over the base-line approach in discovering rare topics. Our model can be used for early and accurate discovery of emerging topics or unexpected events on social platforms.
Chinese Word Sense Embedding with SememeWSD and Synonym Set
Jun 29, 2022
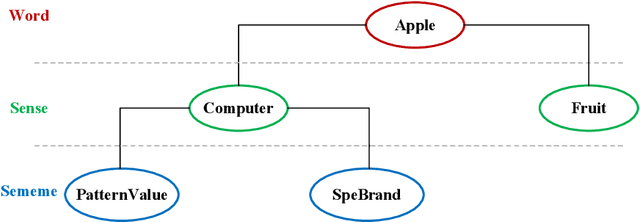

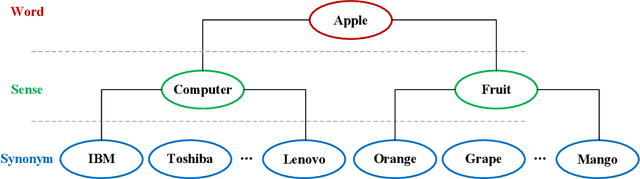
Word embedding is a fundamental natural language processing task which can learn feature of words. However, most word embedding methods assign only one vector to a word, even if polysemous words have multi-senses. To address this limitation, we propose SememeWSD Synonym (SWSDS) model to assign a different vector to every sense of polysemous words with the help of word sense disambiguation (WSD) and synonym set in OpenHowNet. We use the SememeWSD model, an unsupervised word sense disambiguation model based on OpenHowNet, to do word sense disambiguation and annotate the polysemous word with sense id. Then, we obtain top 10 synonyms of the word sense from OpenHowNet and calculate the average vector of synonyms as the vector of the word sense. In experiments, We evaluate the SWSDS model on semantic similarity calculation with Gensim's wmdistance method. It achieves improvement of accuracy. We also examine the SememeWSD model on different BERT models to find the more effective model.
Sentiment Analysis of Online Travel Reviews Based on Capsule Network and Sentiment Lexicon
Jun 05, 2022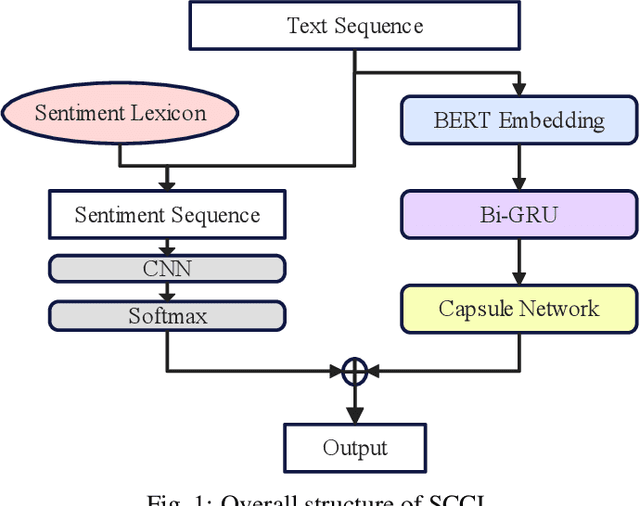
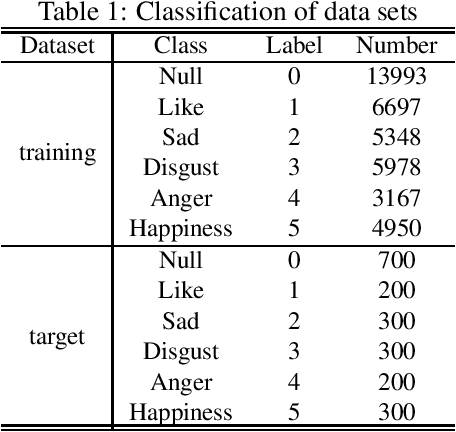
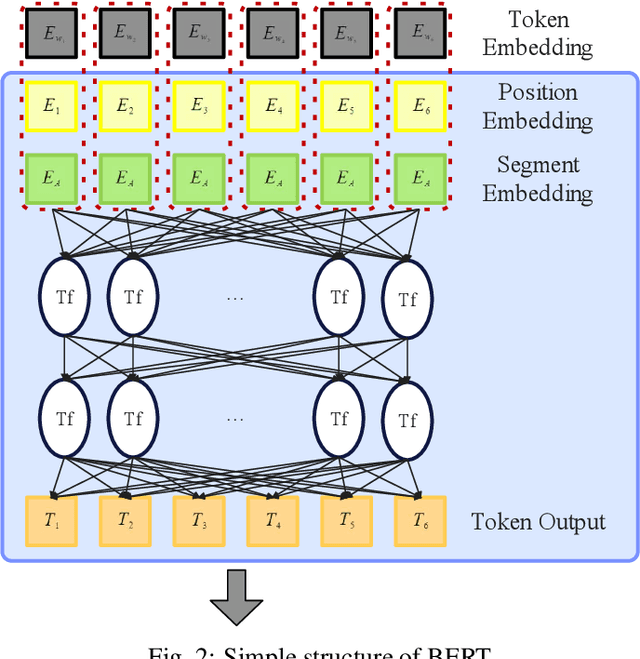
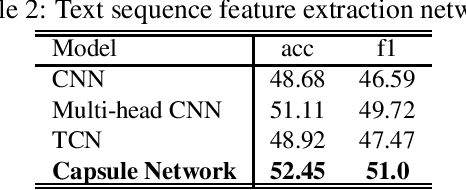
With the development of online travel services, it has great application prospects to timely mine users' evaluation emotions for travel services and use them as indicators to guide the improvement of online travel service quality. In this paper, we study the text sentiment classification of online travel reviews based on social media online comments and propose the SCCL model based on capsule network and sentiment lexicon. SCCL model aims at the lack of consideration of local features and emotional semantic features of the text in the language model that can efficiently extract text context features like BERT and GRU. Then make the following improvements to their shortcomings. On the one hand, based on BERT-BiGRU, the capsule network is introduced to extract local features while retaining good context features. On the other hand, the sentiment lexicon is introduced to extract the emotional sequence of the text to provide richer emotional semantic features for the model. To enhance the universality of the sentiment lexicon, the improved SO-PMI algorithm based on TF-IDF is used to expand the lexicon, so that the lexicon can also perform well in the field of online travel reviews.
Bi-convolution matrix factorization algorithm based on improved ConvMF
Jun 02, 2022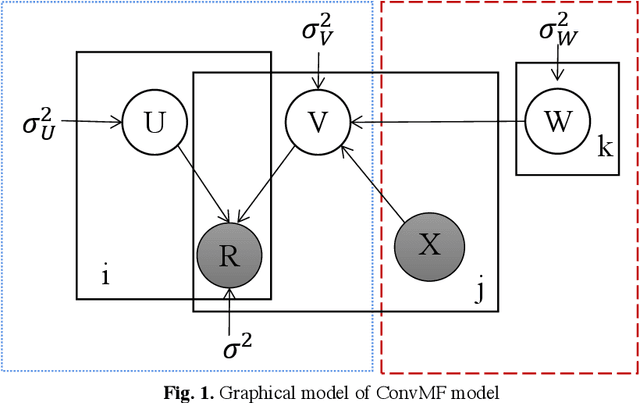



With the rapid development of information technology, "information overload" has become the main theme that plagues people's online life. As an effective tool to help users quickly search for useful information, a personalized recommendation is more and more popular among people. In order to solve the sparsity problem of the traditional matrix factorization algorithm and the problem of low utilization of review document information, this paper proposes a Bicon-vMF algorithm based on improved ConvMF. This algorithm uses two parallel convolutional neural networks to extract deep features from the user review set and item review set respectively and fuses these features into the decomposition of the rating matrix, so as to construct the user latent model and the item latent model more accurately. The experimental results show that compared with traditional recommendation algorithms like PMF, ConvMF, and DeepCoNN, the method proposed in this paper has lower prediction error and can achieve a better recommendation effect. Specifically, compared with the previous three algorithms, the prediction errors of the algorithm proposed in this paper are reduced by 45.8%, 16.6%, and 34.9%, respectively.