 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-modal Search Method of Technology Video based on Adversarial Learning and Feature Fusion
Oct 11, 2022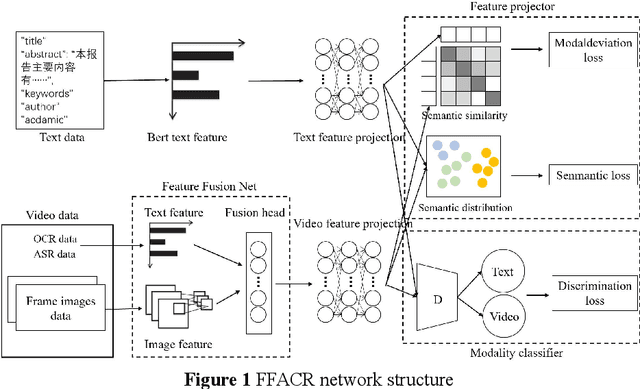
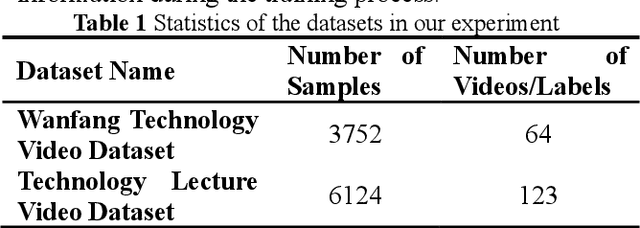
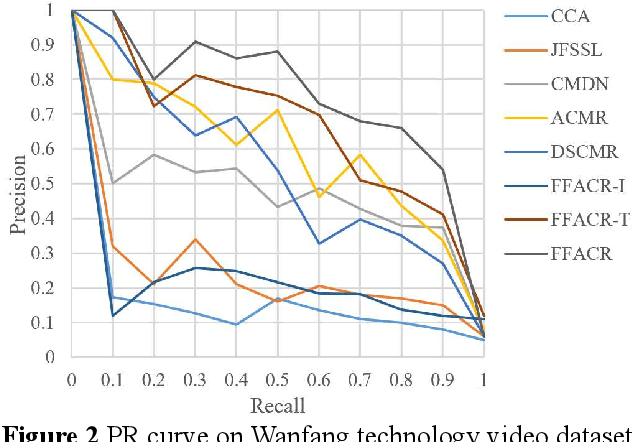
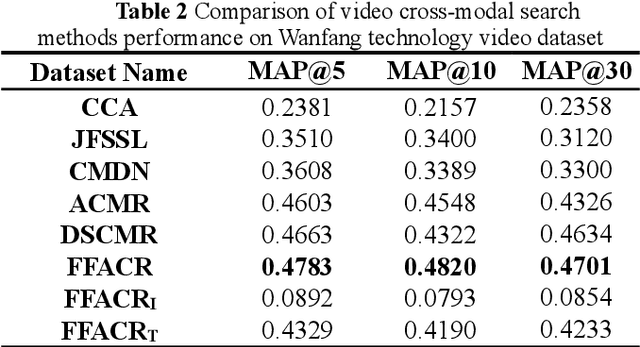
Technology videos contain rich multi-modal information. In cross-modal information search, the data features of different modalities cannot be compared directly, so the semantic gap between different modalities is a key problem that needs to be solved. To address the above problems, this paper proposes a novel Feature Fusion based Adversarial Cross-modal Retrieval method (FFACR) to achieve text-to-video matching, ranking and searching. The proposed method uses the framework of adversarial learning to construct a video multimodal feature fusion network and a feature mapping network as generator, a modality discrimination network as discriminator. Multi-modal features of videos are obtained by the feature fusion network. The feature mapping network projects multi-modal features into the same semantic space based on semantics and similarity. The modality discrimination network is responsible for determining the original modality of features. Generator and discriminator are trained alternately based on adversarial learning, so that the data obtained by the feature mapping network is semantically consistent with the original data and the modal features are eliminated, and finally the similarity is used to rank and obtain the search results in the semantic space. Experimental results demonstrate that the proposed method performs better in text-to-video search than other existing methods, and validate the effectiveness of the method on the self-built datasets of technology videos.