 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe VoiceMOS Challenge 2022
Mar 28, 2022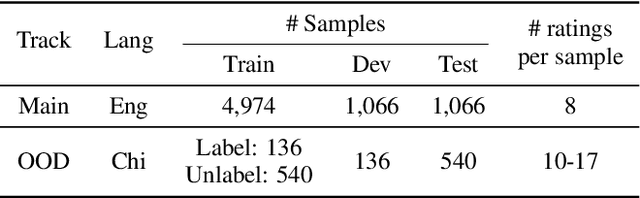
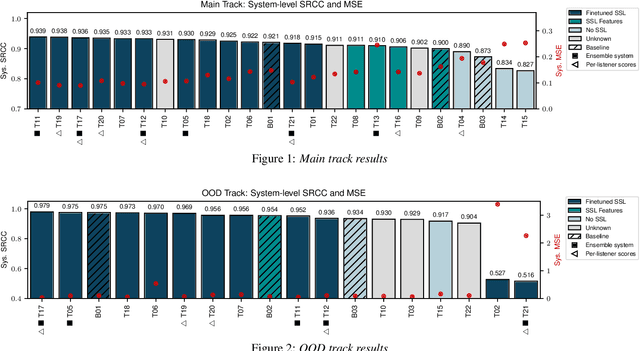
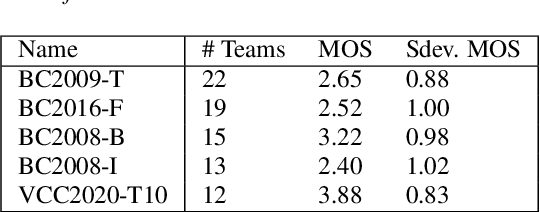
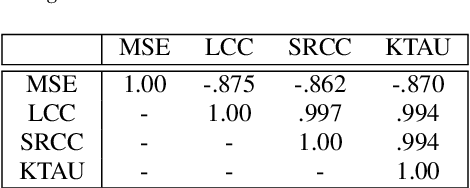
We present the first edition of the VoiceMOS Challenge, a scientific event that aims to promote the study of automatic prediction of the mean opinion score (MOS) of synthetic speech. This challenge drew 22 participating teams from academia and industry who tried a variety of approaches to tackle the problem of predicting human ratings of synthesized speech. The listening test data for the main track of the challenge consisted of samples from 187 different text-to-speech and voice conversion systems spanning over a decade of research, and the out-of-domain track consisted of data from more recent systems rated in a separate listening test. Results of the challenge show the effectiveness of fine-tuning self-supervised speech models for the MOS prediction task, as well as the difficulty of predicting MOS ratings for unseen speakers and listeners, and for unseen systems in the out-of-domain setting.
The VoicePrivacy 2022 Challenge Evaluation Plan
Mar 27, 2022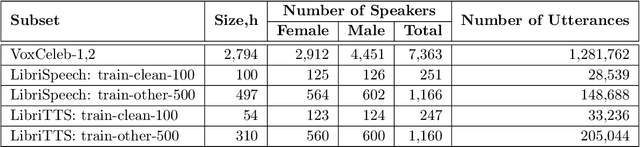
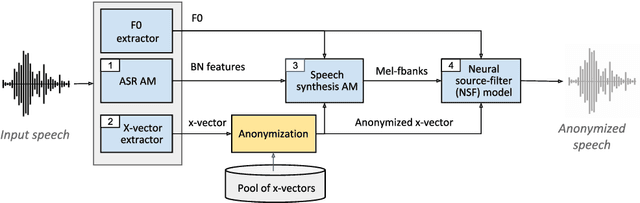
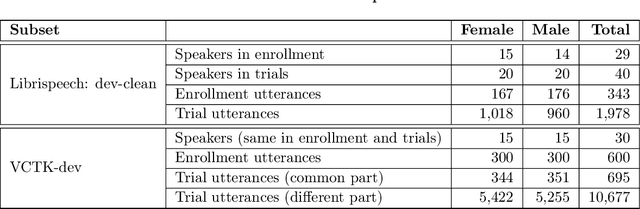
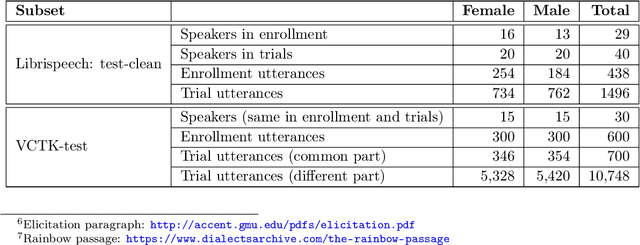
For new participants - Executive summary: (1) The task is to develop a voice anonymization system for speech data which conceals the speaker's voice identity while protecting linguistic content, paralinguistic attributes, intelligibility and naturalness. (2) Training, development and evaluation datasets are provided in addition to 3 different baseline anonymization systems, evaluation scripts, and metrics. Participants apply their developed anonymization systems, run evaluation scripts and submit objective evaluation results and anonymized speech data to the organizers. (3) Results will be presented at a workshop held in conjunction with INTERSPEECH 2022 to which all participants are invited to present their challenge systems and to submit additional workshop papers. For readers familiar with the VoicePrivacy Challenge - Changes w.r.t. 2020: (1) A stronger, semi-informed attack model in the form of an automatic speaker verification (ASV) system trained on anonymized (per-utterance) speech data. (2) Complementary metrics comprising the equal error rate (EER) as a privacy metric, the word error rate (WER) as a primary utility metric, and the pitch correlation and gain of voice distinctiveness as secondary utility metrics. (3) A new ranking policy based upon a set of minimum target privacy requirements.
Language-Independent Speaker Anonymization Approach using Self-Supervised Pre-Trained Models
Mar 26, 2022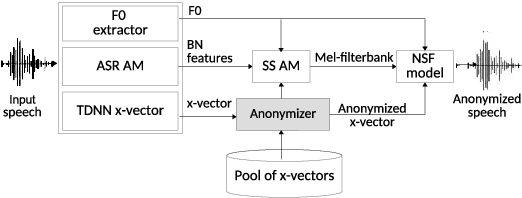
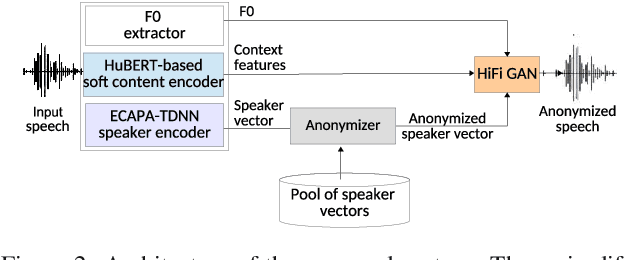

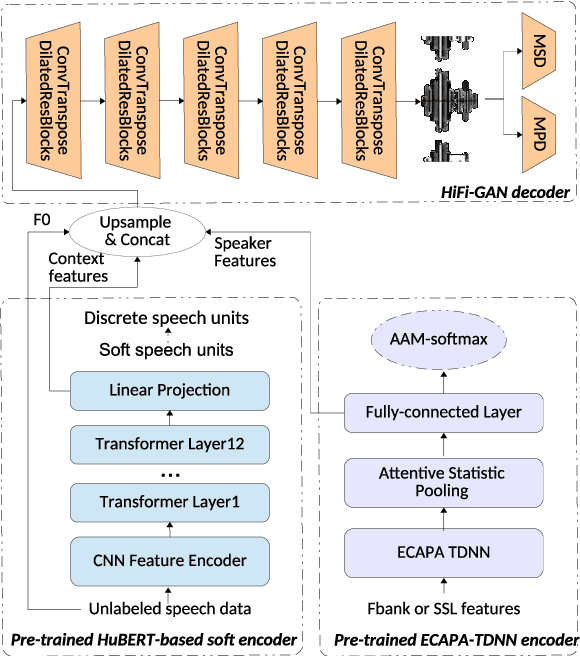
Speaker anonymization aims to protect the privacy of speakers while preserving spoken linguistic information from speech. Current mainstream neural network speaker anonymization systems are complicated, containing an F0 extractor, speaker encoder, automatic speech recognition acoustic model (ASR AM), speech synthesis acoustic model and speech waveform generation model. Moreover, as an ASR AM is language-dependent, trained on English data, it is hard to adapt it into another language. In this paper, we propose a simpler self-supervised learning (SSL)-based method for language-independent speaker anonymization without any explicit language-dependent model, which can be easily used for other languages. Extensive experiments were conducted on the VoicePrivacy Challenge 2020 datasets in English and AISHELL-3 datasets in Mandarin to demonstrate the effectiveness of our proposed SSL-based language-independent speaker anonymization method.
Joint Noise Reduction and Listening Enhancement for Full-End Speech Enhancement
Mar 22, 2022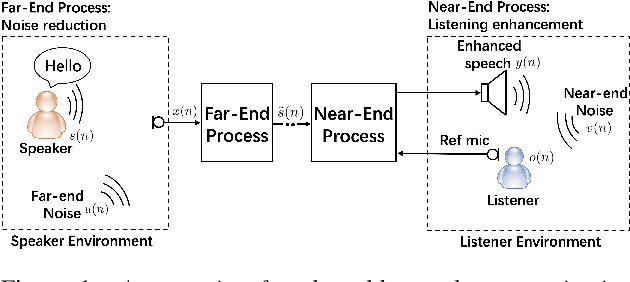
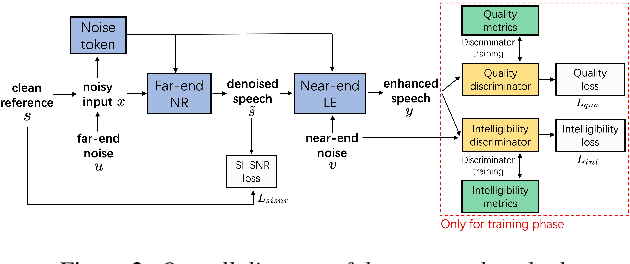
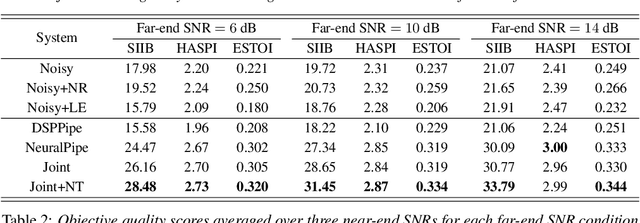

Speech enhancement (SE) methods mainly focus on recovering clean speech from noisy input. In real-world speech communication, however, noises often exist in not only speaker but also listener environments. Although SE methods can suppress the noise contained in the speaker's voice, they cannot deal with the noise that is physically present in the listener side. To address such a complicated but common scenario, we investigate a deep learning-based joint framework integrating noise reduction (NR) with listening enhancement (LE), in which the NR module first suppresses noise and the LE module then modifies the denoised speech, i.e., the output of the NR module, to further improve speech intelligibility. The enhanced speech can thus be less noisy and more intelligible for listeners. Experimental results show that our proposed method achieves promising results and significantly outperforms the disjoint processing methods in terms of various speech evaluation metrics.
Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation
Feb 28, 2022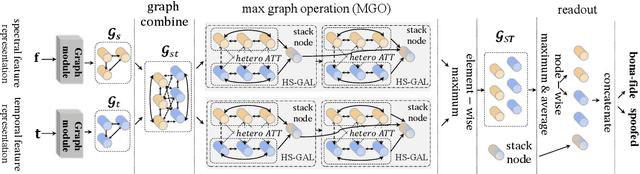
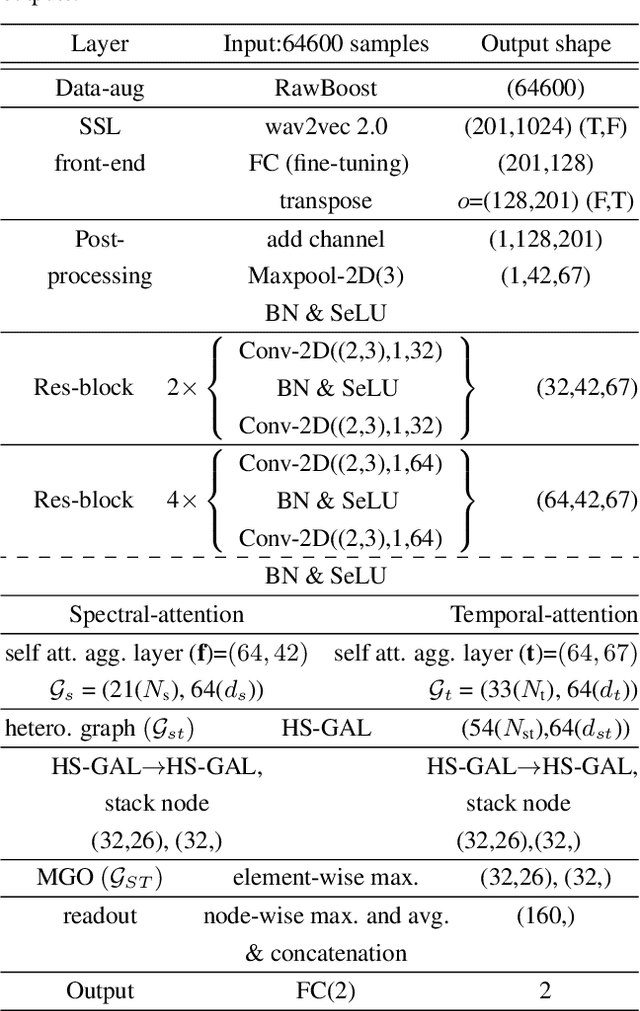
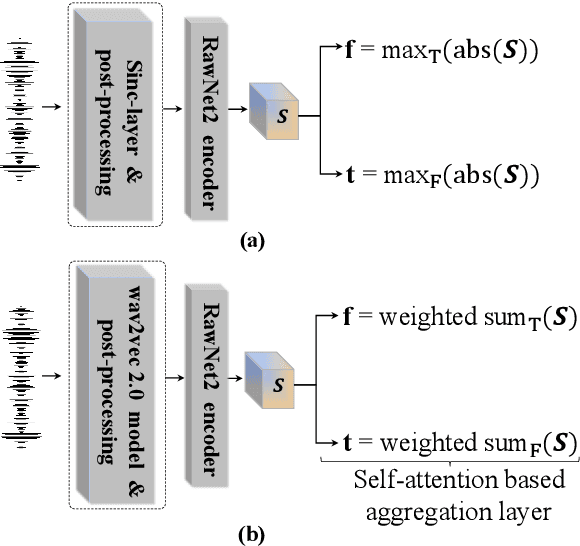
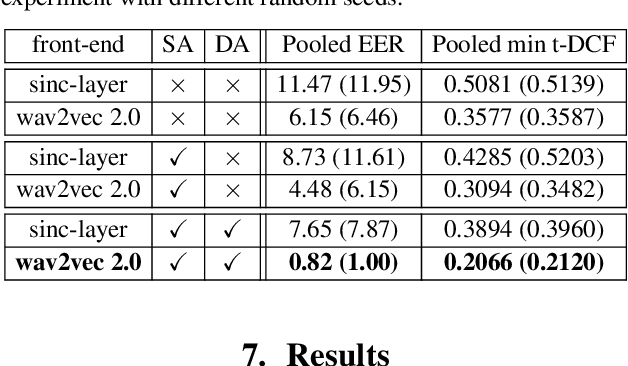
The performance of spoofing countermeasure systems depends fundamentally upon the use of sufficiently representative training data. With this usually being limited, current solutions typically lack generalisation to attacks encountered in the wild. Strategies to improve reliability in the face of uncontrolled, unpredictable attacks are hence needed. We report in this paper our efforts to use self-supervised learning in the form of a wav2vec 2.0 front-end with fine tuning. Despite initial base representations being learned using only bona fide data and no spoofed data, we obtain the lowest equal error rates reported in the literature for both the ASVspoof 2021 Logical Access and Deepfake databases. When combined with data augmentation,these results correspond to an improvement of almost 90% relative to our baseline system.
Robust Deepfake On Unrestricted Media: Generation And Detection
Feb 13, 2022Recent advances in deep learning have led to substantial improvements in deepfake generation, resulting in fake media with a more realistic appearance. Although deepfake media have potential application in a wide range of areas and are drawing much attention from both the academic and industrial communities, it also leads to serious social and criminal concerns. This chapter explores the evolution of and challenges in deepfake generation and detection. It also discusses possible ways to improve the robustness of deepfake detection for a wide variety of media (e.g., in-the-wild images and videos). Finally, it suggests a focus for future fake media research.
Optimizing Tandem Speaker Verification and Anti-Spoofing Systems
Jan 24, 2022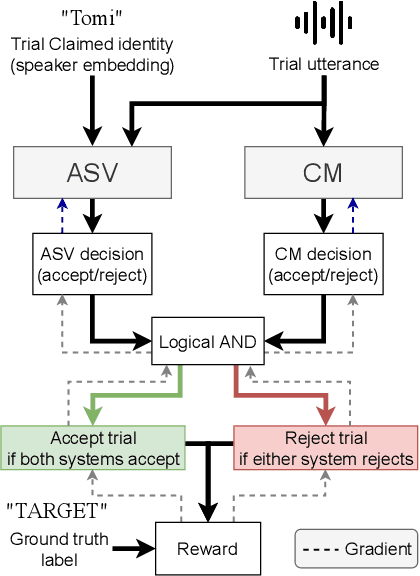
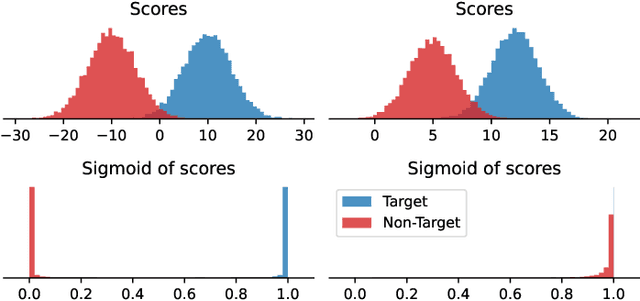
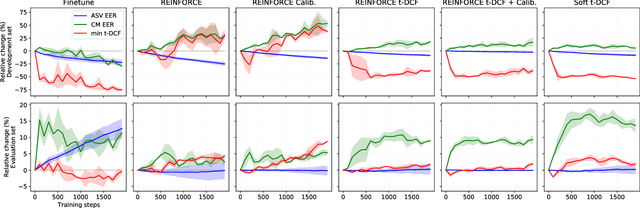

As automatic speaker verification (ASV) systems are vulnerable to spoofing attacks, they are typically used in conjunction with spoofing countermeasure (CM) systems to improve security. For example, the CM can first determine whether the input is human speech, then the ASV can determine whether this speech matches the speaker's identity. The performance of such a tandem system can be measured with a tandem detection cost function (t-DCF). However, ASV and CM systems are usually trained separately, using different metrics and data, which does not optimize their combined performance. In this work, we propose to optimize the tandem system directly by creating a differentiable version of t-DCF and employing techniques from reinforcement learning. The results indicate that these approaches offer better outcomes than finetuning, with our method providing a 20% relative improvement in the t-DCF in the ASVSpoof19 dataset in a constrained setting.
* Published in IEEE/ACM Transactions on Audio, Speech, and Language Processing. Published version available at: https://ieeexplore.ieee.org/document/9664367
A Practical Guide to Logical Access Voice Presentation Attack Detection
Jan 10, 2022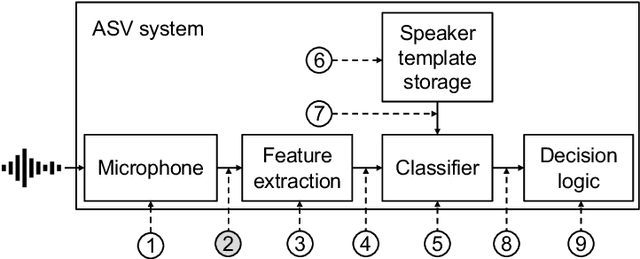

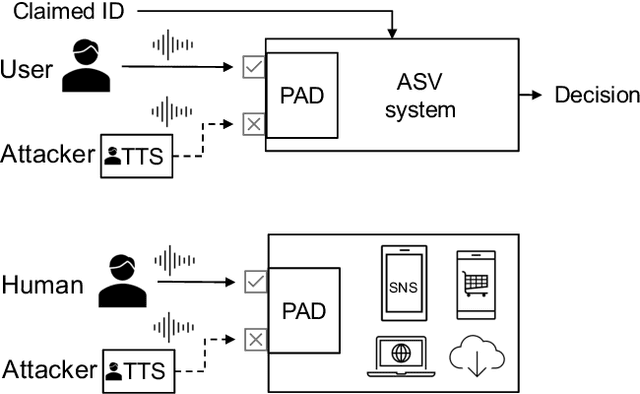
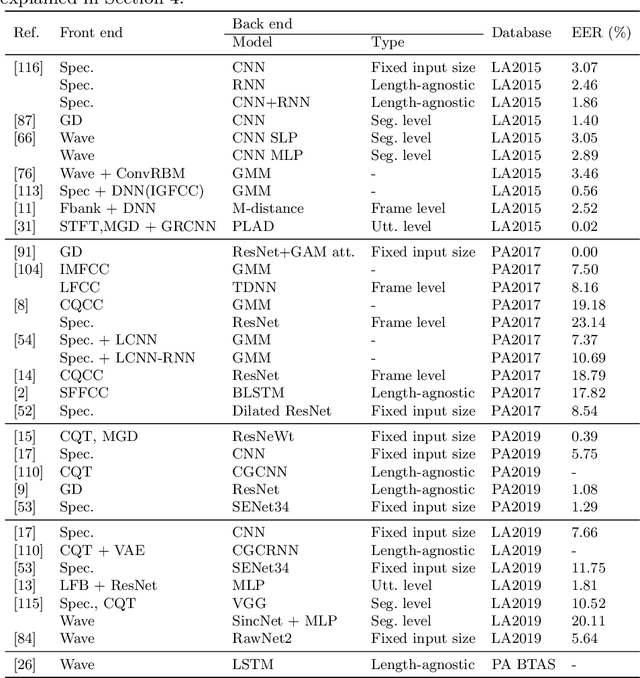
Voice-based human-machine interfaces with an automatic speaker verification (ASV) component are commonly used in the market. However, the threat from presentation attacks is also growing since attackers can use recent speech synthesis technology to produce a natural-sounding voice of a victim. Presentation attack detection (PAD) for ASV, or speech anti-spoofing, is therefore indispensable. Research on voice PAD has seen significant progress since the early 2010s, including the advancement in PAD models, benchmark datasets, and evaluation campaigns. This chapter presents a practical guide to the field of voice PAD, with a focus on logical access attacks using text-to-speech and voice conversion algorithms and spoofing countermeasures based on artifact detection. It introduces the basic concept of voice PAD, explains the common techniques, and provides an experimental study using recent methods on a benchmark dataset. Code for the experiments is open-sourced.
Effectiveness of Detection-based and Regression-based Approaches for Estimating Mask-Wearing Ratio
Dec 03, 2021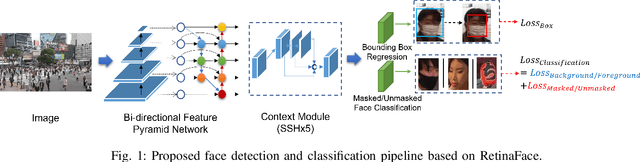
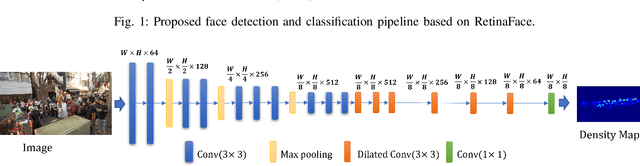

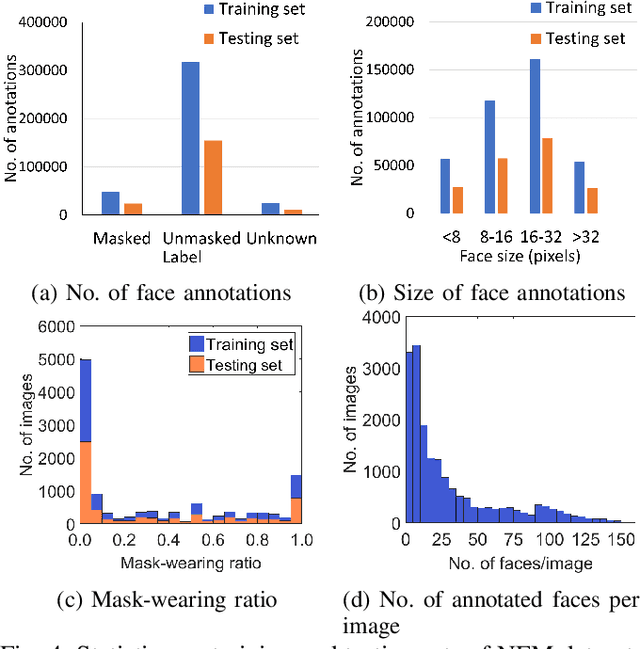
Estimating the mask-wearing ratio in public places is important as it enables health authorities to promptly analyze and implement policies. Methods for estimating the mask-wearing ratio on the basis of image analysis have been reported. However, there is still a lack of comprehensive research on both methodologies and datasets. Most recent reports straightforwardly propose estimating the ratio by applying conventional object detection and classification methods. It is feasible to use regression-based approaches to estimate the number of people wearing masks, especially for congested scenes with tiny and occluded faces, but this has not been well studied. A large-scale and well-annotated dataset is still in demand. In this paper, we present two methods for ratio estimation that leverage either a detection-based or regression-based approach. For the detection-based approach, we improved the state-of-the-art face detector, RetinaFace, used to estimate the ratio. For the regression-based approach, we fine-tuned the baseline network, CSRNet, used to estimate the density maps for masked and unmasked faces. We also present the first large-scale dataset, the ``NFM dataset,'' which contains 581,108 face annotations extracted from 18,088 video frames in 17 street-view videos. Experiments demonstrated that the RetinaFace-based method has higher accuracy under various situations and that the CSRNet-based method has a shorter operation time thanks to its compactness.
Investigating self-supervised front ends for speech spoofing countermeasures
Nov 20, 2021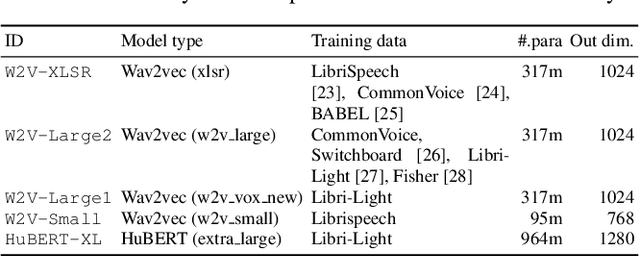
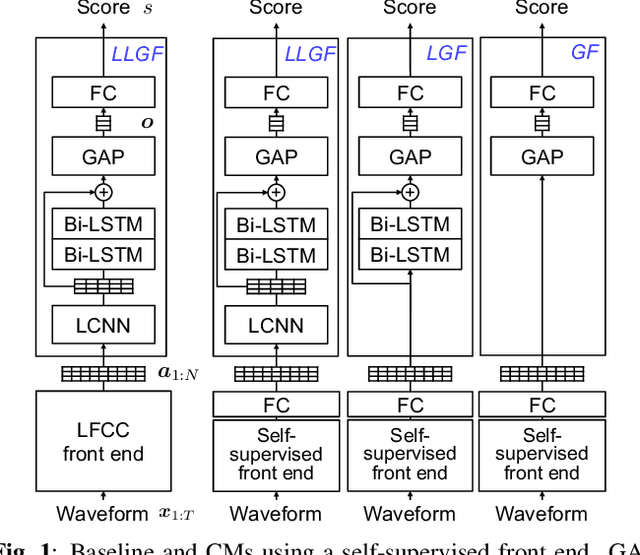
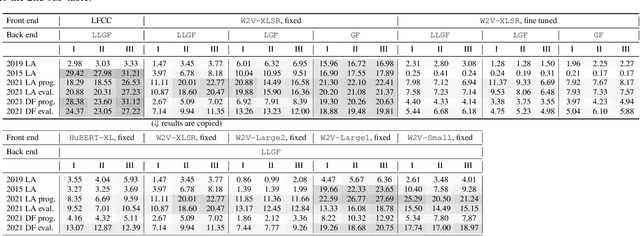
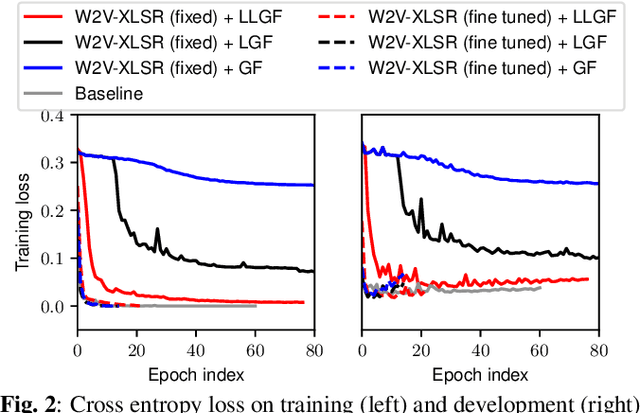
Self-supervised speech model is a rapid progressing research topic, and many pre-trained models have been released and used in various down stream tasks. For speech anti-spoofing, most countermeasures (CMs) use signal processing algorithms to extract acoustic features for classification. In this study, we use pre-trained self-supervised speech models as the front end of spoofing CMs. We investigated different back end architectures to be combined with the self-supervised front end, the effectiveness of fine-tuning the front end, and the performance of using different pre-trained self-supervised models. Our findings showed that, when a good pre-trained front end was fine-tuned with either a shallow or a deep neural network-based back end on the ASVspoof 2019 logical access (LA) training set, the resulting CM not only achieved a low EER score on the 2019 LA test set but also significantly outperformed the baseline on the ASVspoof 2015, 2021 LA, and 2021 deepfake test sets.