 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Investigation Between Schema Linking and Text-to-SQL Performance
Feb 03, 2021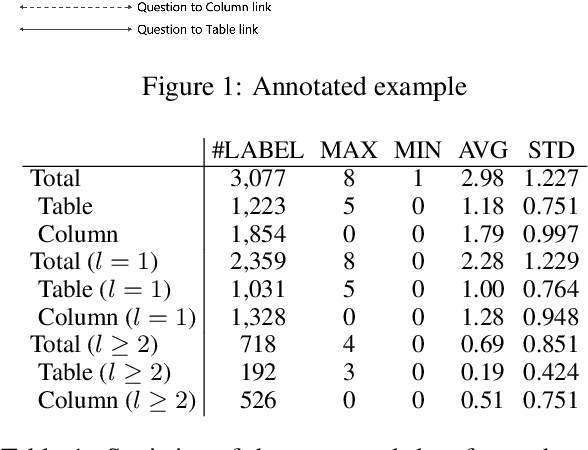


Text-to-SQL is a crucial task toward developing methods for understanding natural language by computers. Recent neural approaches deliver excellent performance; however, models that are difficult to interpret inhibit future developments. Hence, this study aims to provide a better approach toward the interpretation of neural models. We hypothesize that the internal behavior of models at hand becomes much easier to analyze if we identify the detailed performance of schema linking simultaneously as the additional information of the text-to-SQL performance. We provide the ground-truth annotation of schema linking information onto the Spider dataset. We demonstrate the usefulness of the annotated data and how to analyze the current state-of-the-art neural models.
NeurIPS 2020 EfficientQA Competition: Systems, Analyses and Lessons Learned
Jan 01, 2021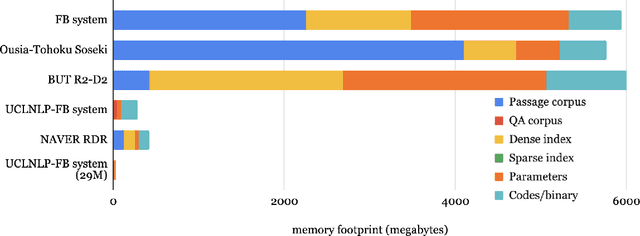
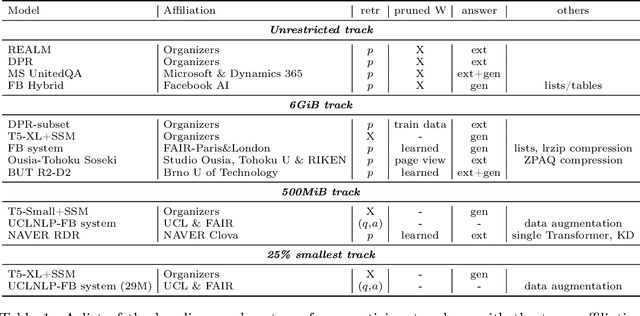
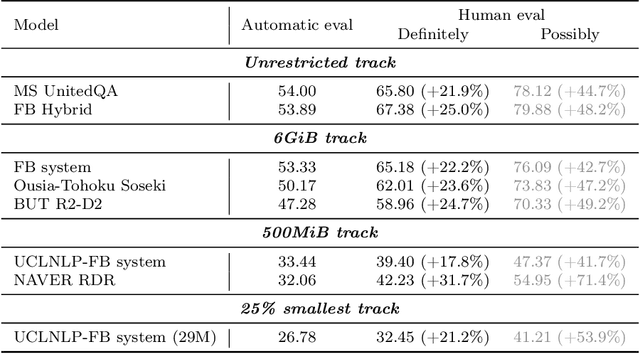
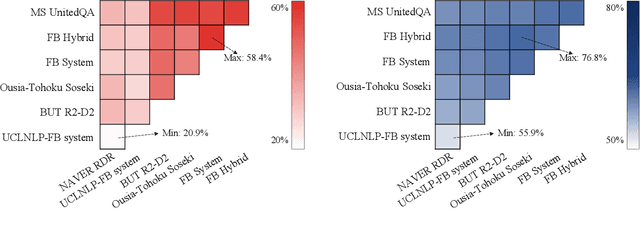
We review the EfficientQA competition from NeurIPS 2020. The competition focused on open-domain question answering (QA), where systems take natural language questions as input and return natural language answers. The aim of the competition was to build systems that can predict correct answers while also satisfying strict on-disk memory budgets. These memory budgets were designed to encourage contestants to explore the trade-off between storing large, redundant, retrieval corpora or the parameters of large learned models. In this report, we describe the motivation and organization of the competition, review the best submissions, and analyze system predictions to inform a discussion of evaluation for open-domain QA.
Efficient Estimation of Influence of a Training Instance
Dec 08, 2020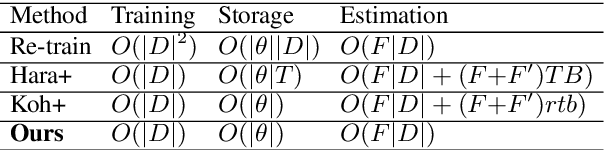
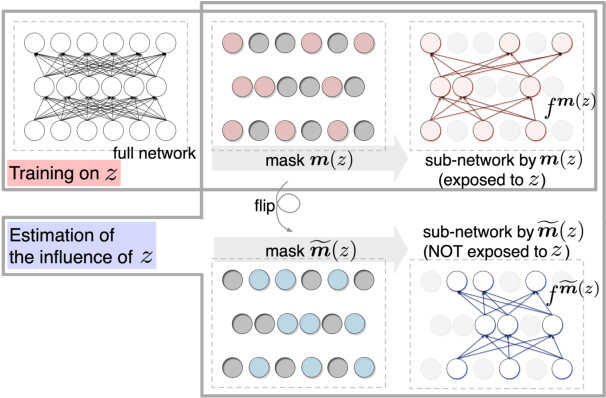
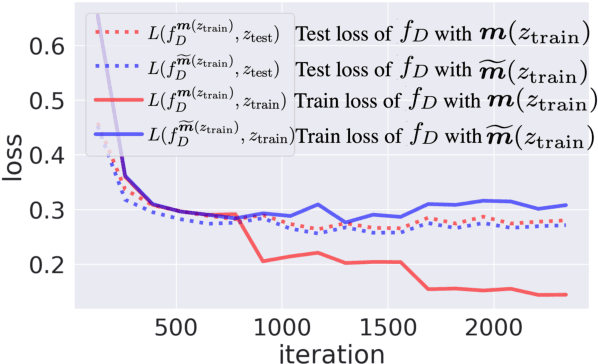

Understanding the influence of a training instance on a neural network model leads to improving interpretability. However, it is difficult and inefficient to evaluate the influence, which shows how a model's prediction would be changed if a training instance were not used. In this paper, we propose an efficient method for estimating the influence. Our method is inspired by dropout, which zero-masks a sub-network and prevents the sub-network from learning each training instance. By switching between dropout masks, we can use sub-networks that learned or did not learn each training instance and estimate its influence. Through experiments with BERT and VGGNet on classification datasets, we demonstrate that the proposed method can capture training influences, enhance the interpretability of error predictions, and cleanse the training dataset for improving generalization.
PheMT: A Phenomenon-wise Dataset for Machine Translation Robustness on User-Generated Contents
Nov 04, 2020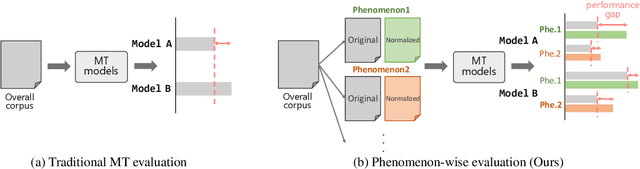

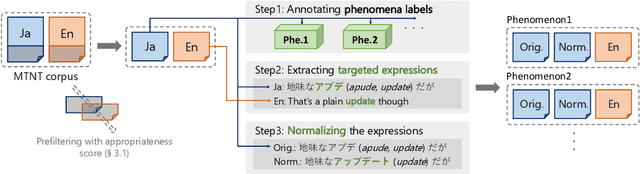

Neural Machine Translation (NMT) has shown drastic improvement in its quality when translating clean input, such as text from the news domain. However, existing studies suggest that NMT still struggles with certain kinds of input with considerable noise, such as User-Generated Contents (UGC) on the Internet. To make better use of NMT for cross-cultural communication, one of the most promising directions is to develop a model that correctly handles these expressions. Though its importance has been recognized, it is still not clear as to what creates the great gap in performance between the translation of clean input and that of UGC. To answer the question, we present a new dataset, PheMT, for evaluating the robustness of MT systems against specific linguistic phenomena in Japanese-English translation. Our experiments with the created dataset revealed that not only our in-house models but even widely used off-the-shelf systems are greatly disturbed by the presence of certain phenomena.
Langsmith: An Interactive Academic Text Revision System
Oct 09, 2020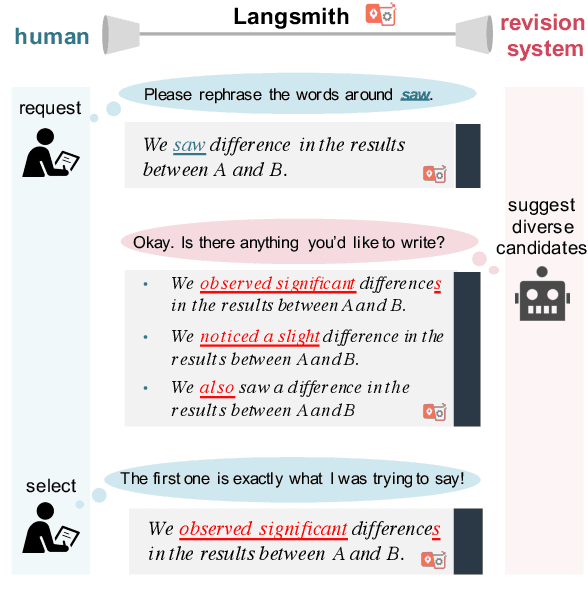
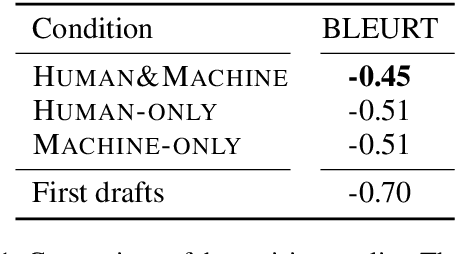
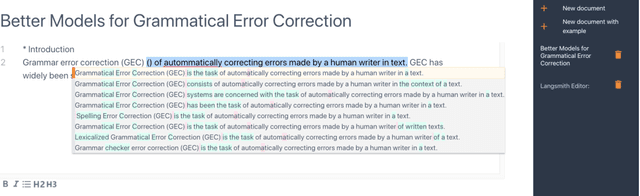
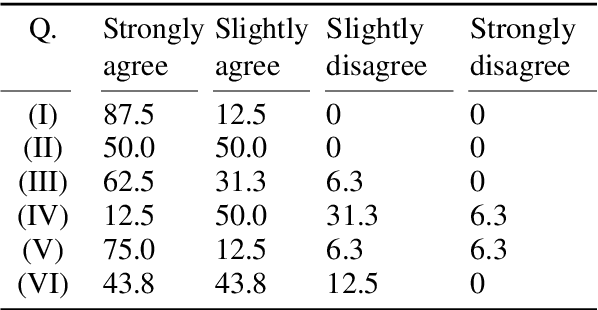
Despite the current diversity and inclusion initiatives in the academic community, researchers with a non-native command of English still face significant obstacles when writing papers in English. This paper presents the Langsmith editor, which assists inexperienced, non-native researchers to write English papers, especially in the natural language processing (NLP) field. Our system can suggest fluent, academic-style sentences to writers based on their rough, incomplete phrases or sentences. The system also encourages interaction between human writers and the computerized revision system. The experimental results demonstrated that Langsmith helps non-native English-speaker students write papers in English. The system is available at https://emnlp-demo.editor. langsmith.co.jp/.
A Self-Refinement Strategy for Noise Reduction in Grammatical Error Correction
Oct 07, 2020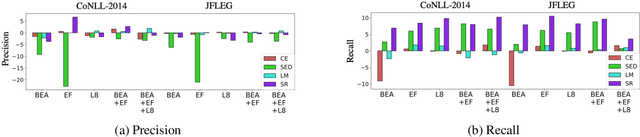

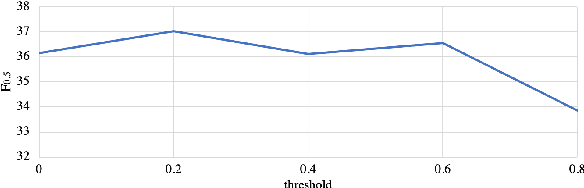
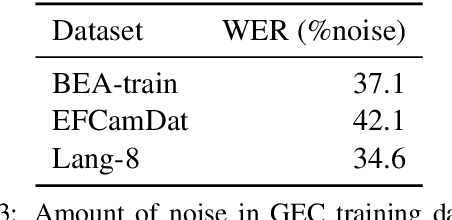
Existing approaches for grammatical error correction (GEC) largely rely on supervised learning with manually created GEC datasets. However, there has been little focus on verifying and ensuring the quality of the datasets, and on how lower-quality data might affect GEC performance. We indeed found that there is a non-negligible amount of "noise" where errors were inappropriately edited or left uncorrected. To address this, we designed a self-refinement method where the key idea is to denoise these datasets by leveraging the prediction consistency of existing models, and outperformed strong denoising baseline methods. We further applied task-specific techniques and achieved state-of-the-art performance on the CoNLL-2014, JFLEG, and BEA-2019 benchmarks. We then analyzed the effect of the proposed denoising method, and found that our approach leads to improved coverage of corrections and facilitated fluency edits which are reflected in higher recall and overall performance.
Embeddings of Label Components for Sequence Labeling: A Case Study of Fine-grained Named Entity Recognition
Jun 04, 2020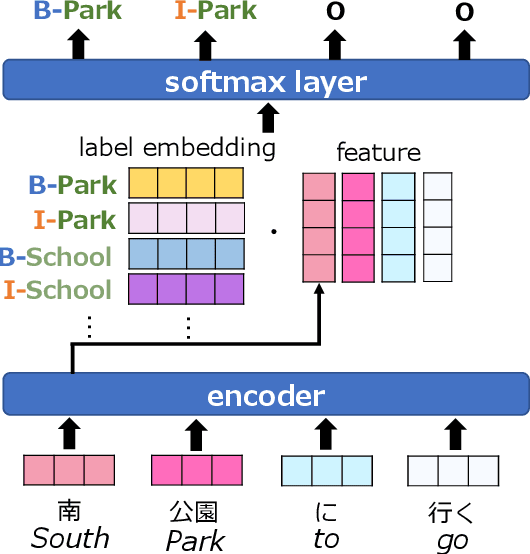
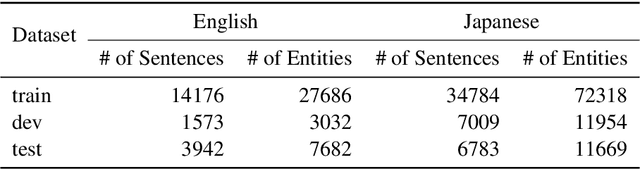
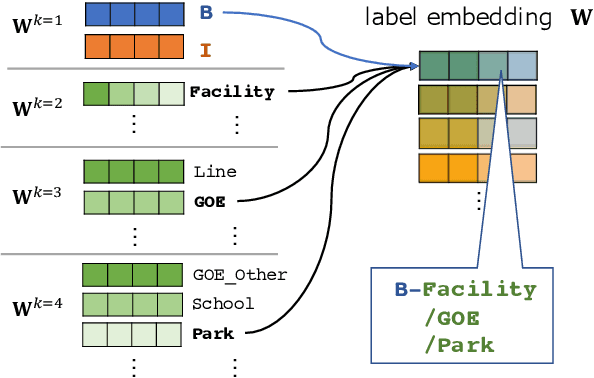
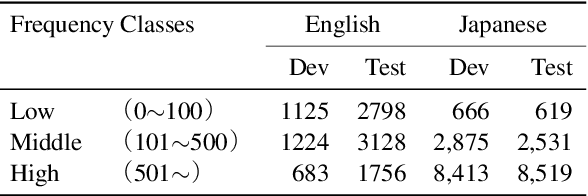
In general, the labels used in sequence labeling consist of different types of elements. For example, IOB-format entity labels, such as B-Person and I-Person, can be decomposed into span (B and I) and type information (Person). However, while most sequence labeling models do not consider such label components, the shared components across labels, such as Person, can be beneficial for label prediction. In this work, we propose to integrate label component information as embeddings into models. Through experiments on English and Japanese fine-grained named entity recognition, we demonstrate that the proposed method improves performance, especially for instances with low-frequency labels.
Encoder-Decoder Models Can Benefit from Pre-trained Masked Language Models in Grammatical Error Correction
May 31, 2020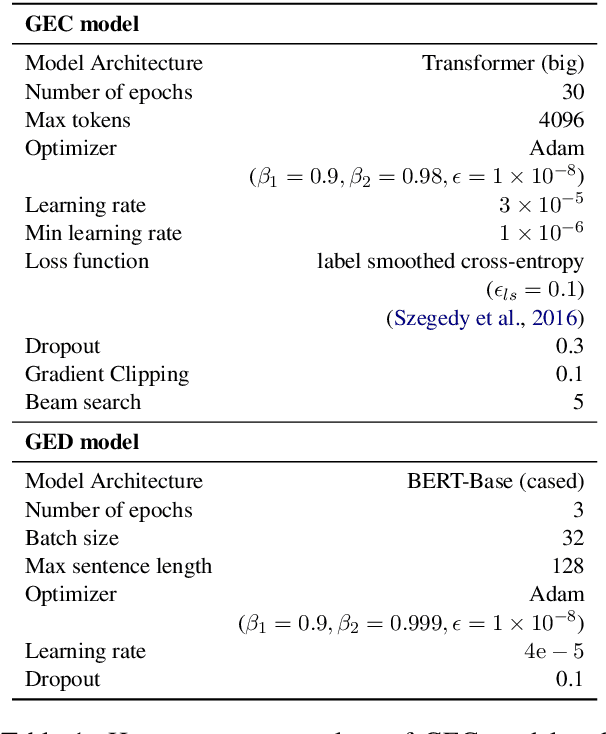
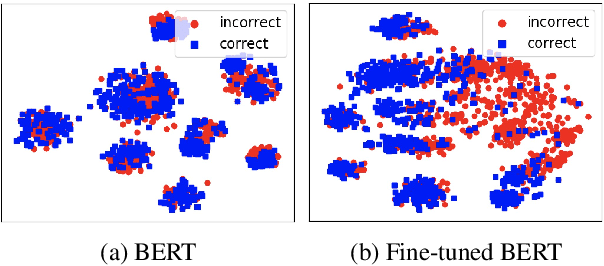
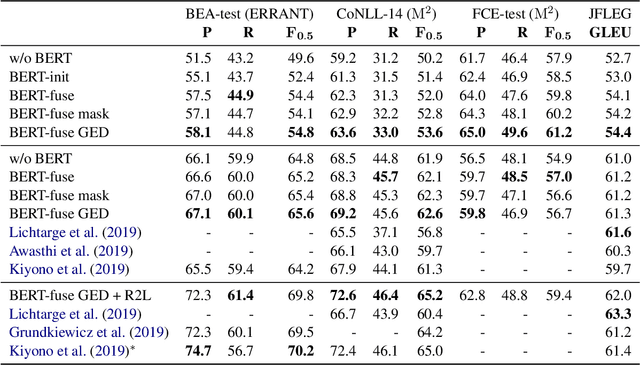
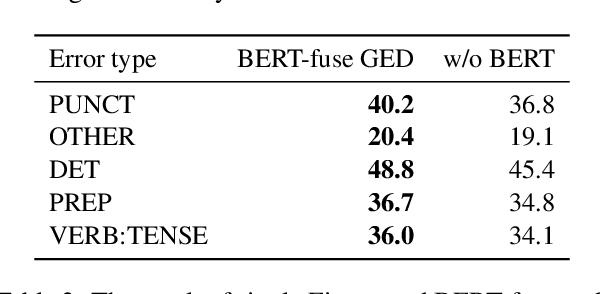
This paper investigates how to effectively incorporate a pre-trained masked language model (MLM), such as BERT, into an encoder-decoder (EncDec) model for grammatical error correction (GEC). The answer to this question is not as straightforward as one might expect because the previous common methods for incorporating a MLM into an EncDec model have potential drawbacks when applied to GEC. For example, the distribution of the inputs to a GEC model can be considerably different (erroneous, clumsy, etc.) from that of the corpora used for pre-training MLMs; however, this issue is not addressed in the previous methods. Our experiments show that our proposed method, where we first fine-tune a MLM with a given GEC corpus and then use the output of the fine-tuned MLM as additional features in the GEC model, maximizes the benefit of the MLM. The best-performing model achieves state-of-the-art performances on the BEA-2019 and CoNLL-2014 benchmarks. Our code is publicly available at: https://github.com/kanekomasahiro/bert-gec.
* Accepted as a short paper to the 58th Annual Conference of the Association for Computational Linguistics (ACL-2020)
Single Model Ensemble using Pseudo-Tags and Distinct Vectors
May 02, 2020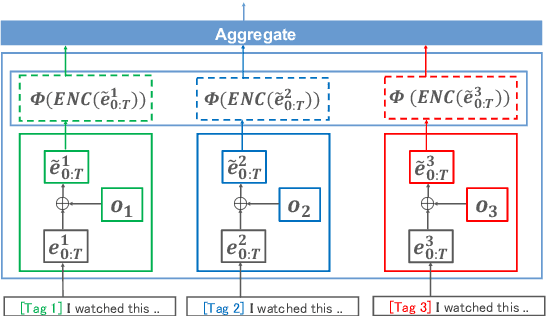
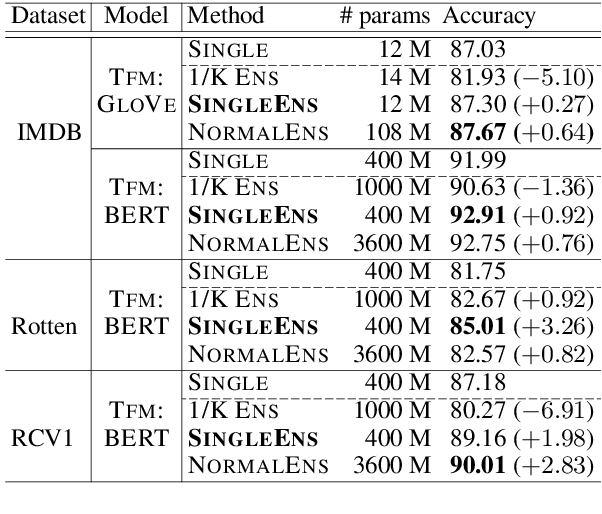
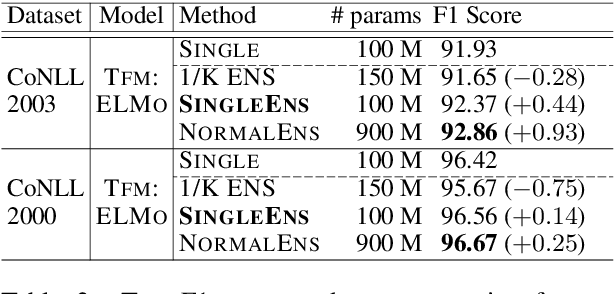
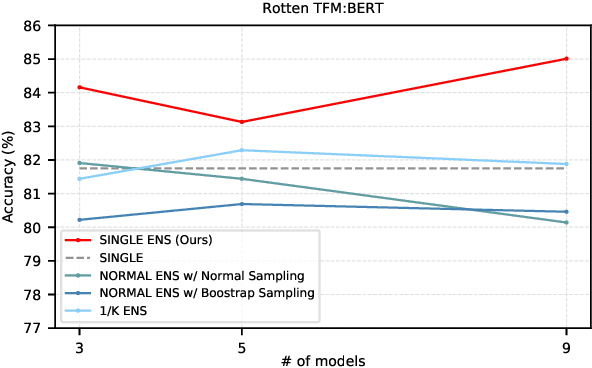
Model ensemble techniques often increase task performance in neural networks; however, they require increased time, memory, and management effort. In this study, we propose a novel method that replicates the effects of a model ensemble with a single model. Our approach creates K-virtual models within a single parameter space using K-distinct pseudo-tags and K-distinct vectors. Experiments on text classification and sequence labeling tasks on several datasets demonstrate that our method emulates or outperforms a traditional model ensemble with 1/K-times fewer parameters.
Language Models as an Alternative Evaluator of Word Order Hypotheses: A Case Study in Japanese
May 02, 2020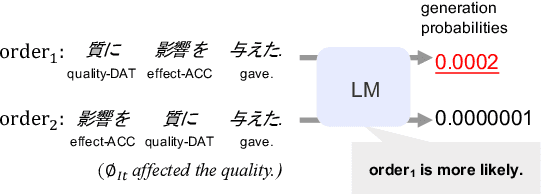

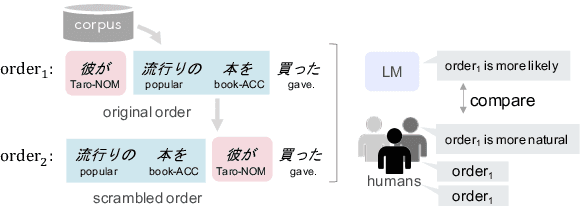

We examine a methodology using neural language models (LMs) for analyzing the word order of language. This LM-based method has the potential to overcome the difficulties existing methods face, such as the propagation of preprocessor errors in count-based methods. In this study, we explore whether the LM-based method is valid for analyzing the word order. As a case study, this study focuses on Japanese due to its complex and flexible word order. To validate the LM-based method, we test (i) parallels between LMs and human word order preference, and (ii) consistency of the results obtained using the LM-based method with previous linguistic studies. Through our experiments, we tentatively conclude that LMs display sufficient word order knowledge for usage as an analysis tool. Finally, using the LM-based method, we demonstrate the relationship between the canonical word order and topicalization, which had yet to be analyzed by large-scale experiments.