 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Pseudo-Labeling for Image-based 3D Object Detection
Aug 15, 2022

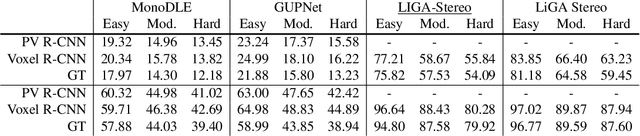
Image-based 3D detection is an indispensable component of the perception system for autonomous driving. However, it still suffers from the unsatisfying performance, one of the main reasons for which is the limited training data. Unfortunately, annotating the objects in the 3D space is extremely time/resource-consuming, which makes it hard to extend the training set arbitrarily. In this work, we focus on the semi-supervised manner and explore the feasibility of a cheaper alternative, i.e. pseudo-labeling, to leverage the unlabeled data. For this purpose, we conduct extensive experiments to investigate whether the pseudo-labels can provide effective supervision for the baseline models under varying settings. The experimental results not only demonstrate the effectiveness of the pseudo-labeling mechanism for image-based 3D detection (e.g. under monocular setting, we achieve 20.23 AP for moderate level on the KITTI-3D testing set without bells and whistles, improving the baseline model by 6.03 AP), but also show several interesting and noteworthy findings (e.g. the models trained with pseudo-labels perform better than that trained with ground-truth annotations based on the same training data). We hope this work can provide insights for the image-based 3D detection community under a semi-supervised setting. The codes, pseudo-labels, and pre-trained models will be publicly available.
StyleFlow For Content-Fixed Image to Image Translation
Jul 05, 2022

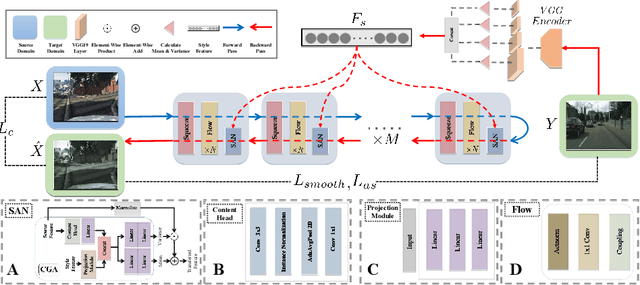

Image-to-image (I2I) translation is a challenging topic in computer vision. We divide this problem into three tasks: strongly constrained translation, normally constrained translation, and weakly constrained translation. The constraint here indicates the extent to which the content or semantic information in the original image is preserved. Although previous approaches have achieved good performance in weakly constrained tasks, they failed to fully preserve the content in both strongly and normally constrained tasks, including photo-realism synthesis, style transfer, and colorization, etc. To achieve content-preserving transfer in strongly constrained and normally constrained tasks, we propose StyleFlow, a new I2I translation model that consists of normalizing flows and a novel Style-Aware Normalization (SAN) module. With the invertible network structure, StyleFlow first projects input images into deep feature space in the forward pass, while the backward pass utilizes the SAN module to perform content-fixed feature transformation and then projects back to image space. Our model supports both image-guided translation and multi-modal synthesis. We evaluate our model in several I2I translation benchmarks, and the results show that the proposed model has advantages over previous methods in both strongly constrained and normally constrained tasks.
Probing Visual-Audio Representation for Video Highlight Detection via Hard-Pairs Guided Contrastive Learning
Jun 21, 2022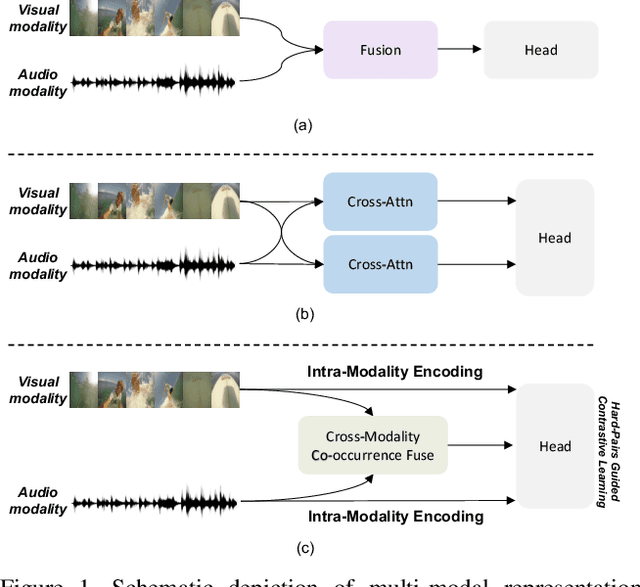

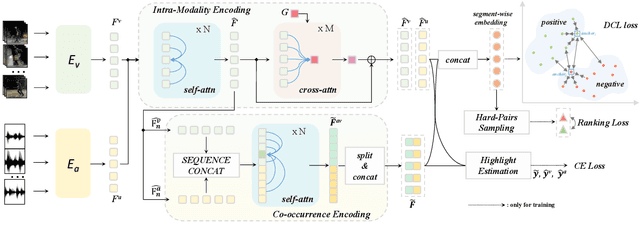
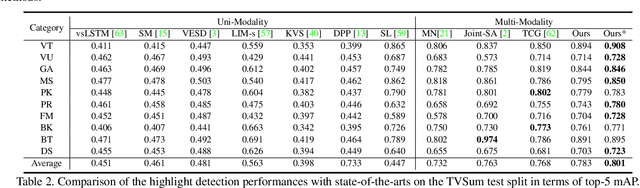
Video highlight detection is a crucial yet challenging problem that aims to identify the interesting moments in untrimmed videos. The key to this task lies in effective video representations that jointly pursue two goals, \textit{i.e.}, cross-modal representation learning and fine-grained feature discrimination. In this paper, these two challenges are tackled by not only enriching intra-modality and cross-modality relations for representation modeling but also shaping the features in a discriminative manner. Our proposed method mainly leverages the intra-modality encoding and cross-modality co-occurrence encoding for fully representation modeling. Specifically, intra-modality encoding augments the modality-wise features and dampens irrelevant modality via within-modality relation learning in both audio and visual signals. Meanwhile, cross-modality co-occurrence encoding focuses on the co-occurrence inter-modality relations and selectively captures effective information among multi-modality. The multi-modal representation is further enhanced by the global information abstracted from the local context. In addition, we enlarge the discriminative power of feature embedding with a hard-pairs guided contrastive learning (HPCL) scheme. A hard-pairs sampling strategy is further employed to mine the hard samples for improving feature discrimination in HPCL. Extensive experiments conducted on two benchmarks demonstrate the effectiveness and superiority of our proposed methods compared to other state-of-the-art methods.
Pyramid Region-based Slot Attention Network for Temporal Action Proposal Generation
Jun 21, 2022
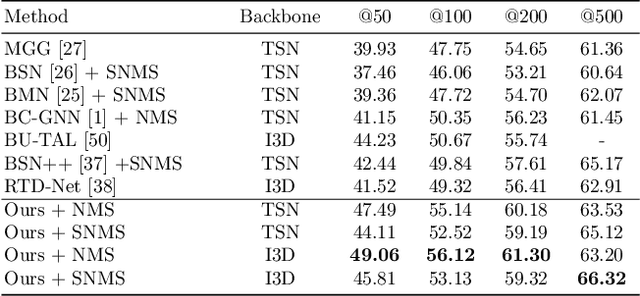
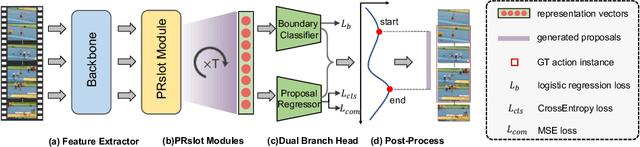

It has been found that temporal action proposal generation, which aims to discover the temporal action instances within the range of the start and end frames in the untrimmed videos, can largely benefit from proper temporal and semantic context exploitation. The latest efforts were dedicated to considering the temporal context and similarity-based semantic contexts through self-attention modules. However, they still suffer from cluttered background information and limited contextual feature learning. In this paper, we propose a novel Pyramid Region-based Slot Attention (PRSlot) module to address these issues. Instead of using the similarity computation, our PRSlot module directly learns the local relations in an encoder-decoder manner and generates the representation of a local region enhanced based on the attention over input features called \textit{slot}. Specifically, upon the input snippet-level features, PRSlot module takes the target snippet as \textit{query}, its surrounding region as \textit{key} and then generates slot representations for each \textit{query-key} slot by aggregating the local snippet context with a parallel pyramid strategy. Based on PRSlot modules, we present a novel Pyramid Region-based Slot Attention Network termed PRSA-Net to learn a unified visual representation with rich temporal and semantic context for better proposal generation. Extensive experiments are conducted on two widely adopted THUMOS14 and ActivityNet-1.3 benchmarks. Our PRSA-Net outperforms other state-of-the-art methods. In particular, we improve the AR@100 from the previous best 50.67% to 56.12% for proposal generation and raise the mAP under 0.5 tIoU from 51.9\% to 58.7\% for action detection on THUMOS14. \textit{Code is available at} \url{https://github.com/handhand123/PRSA-Net}
Better Teacher Better Student: Dynamic Prior Knowledge for Knowledge Distillation
Jun 14, 2022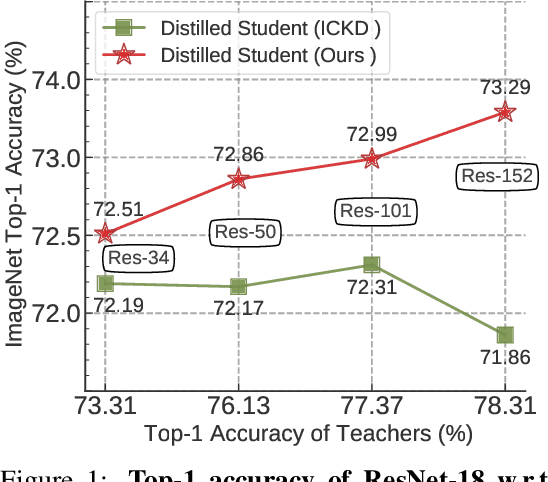
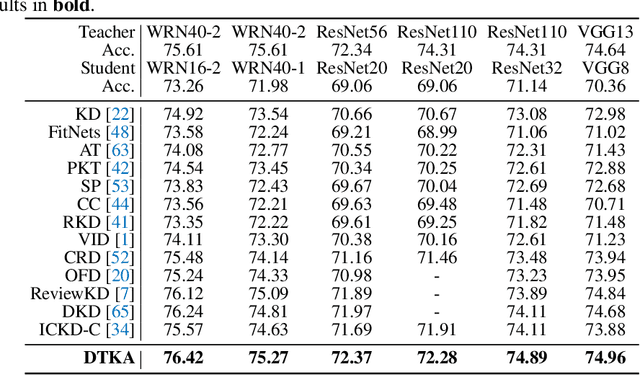
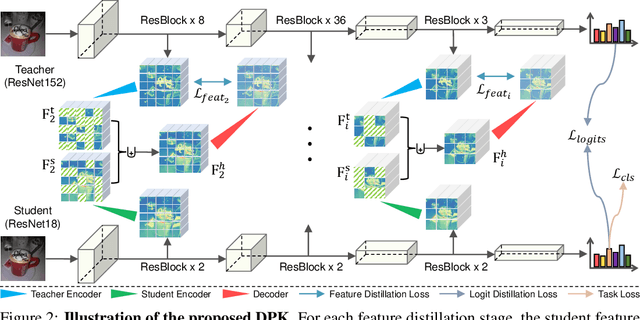

Knowledge distillation (KD) has shown very promising capabilities in transferring learning representations from large models (teachers) to small models (students). However, as the capacity gap between students and teachers becomes larger, existing KD methods fail to achieve better results. Our work shows that the 'prior knowledge' is vital to KD, especially when applying large teachers. Particularly, we propose the dynamic prior knowledge (DPK), which integrates part of the teacher's features as the prior knowledge before the feature distillation. This means that our method also takes the teacher's feature as `input', not just `target'. Besides, we dynamically adjust the ratio of the prior knowledge during the training phase according to the feature gap, thus guiding the student in an appropriate difficulty. To evaluate the proposed method, we conduct extensive experiments on two image classification benchmarks (i.e. CIFAR100 and ImageNet) and an object detection benchmark (i.e. MS COCO). The results demonstrate the superiority of our method in performance under varying settings. More importantly, our DPK makes the performance of the student model is positively correlated with that of the teacher model, which means that we can further boost the accuracy of students by applying larger teachers. Our codes will be publicly available for the reproducibility.
Inferring Prototypes for Multi-Label Few-Shot Image Classification with Word Vector Guided Attention
Dec 07, 2021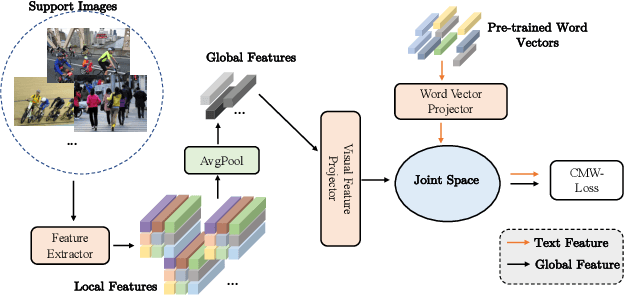
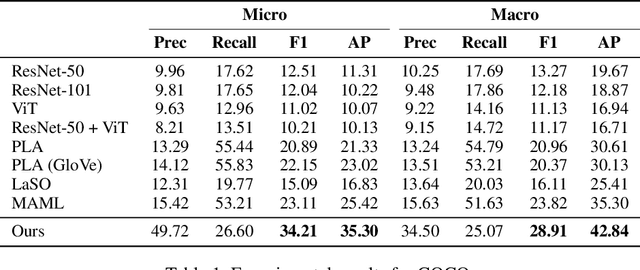
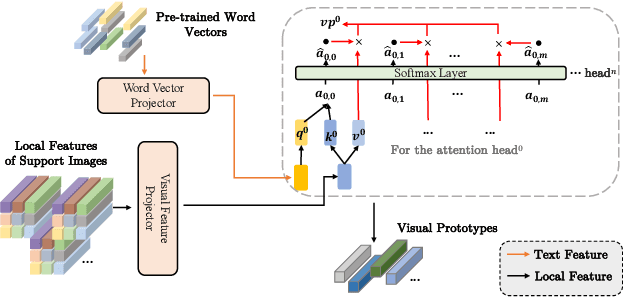
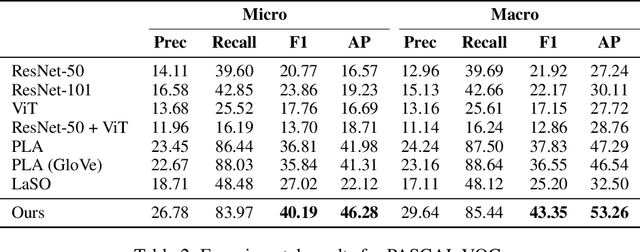
Multi-label few-shot image classification (ML-FSIC) is the task of assigning descriptive labels to previously unseen images, based on a small number of training examples. A key feature of the multi-label setting is that images often have multiple labels, which typically refer to different regions of the image. When estimating prototypes, in a metric-based setting, it is thus important to determine which regions are relevant for which labels, but the limited amount of training data makes this highly challenging. As a solution, in this paper we propose to use word embeddings as a form of prior knowledge about the meaning of the labels. In particular, visual prototypes are obtained by aggregating the local feature maps of the support images, using an attention mechanism that relies on the label embeddings. As an important advantage, our model can infer prototypes for unseen labels without the need for fine-tuning any model parameters, which demonstrates its strong generalization abilities. Experiments on COCO and PASCAL VOC furthermore show that our model substantially improves the current state-of-the-art.
GroupFormer: Group Activity Recognition with Clustered Spatial-Temporal Transformer
Aug 28, 2021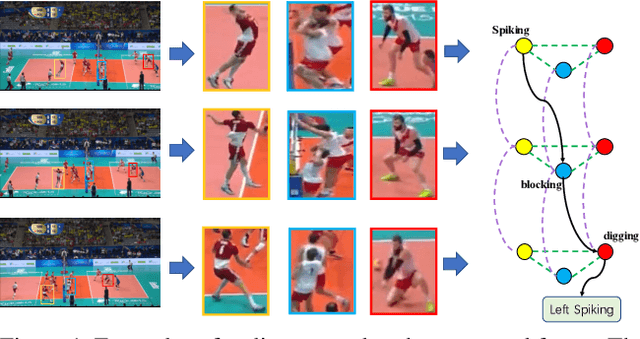
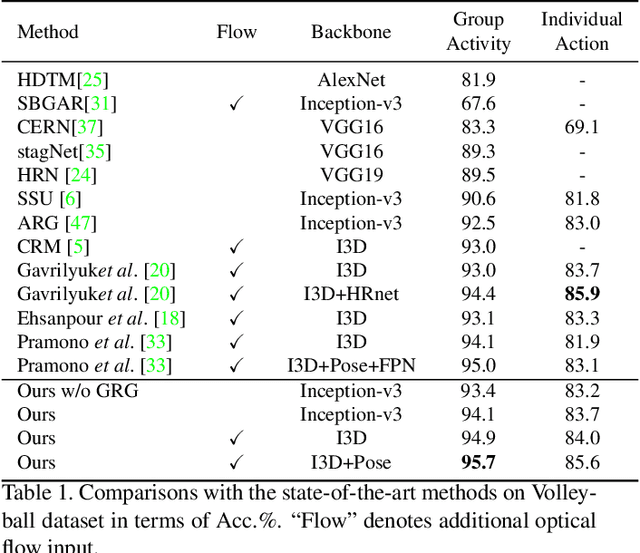
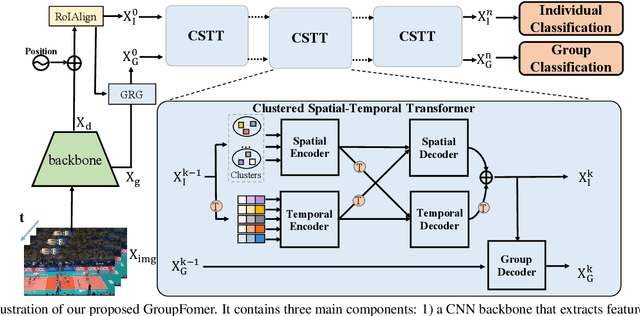
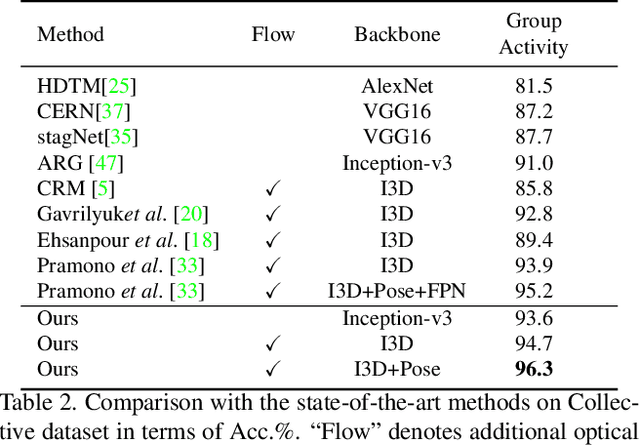
Group activity recognition is a crucial yet challenging problem, whose core lies in fully exploring spatial-temporal interactions among individuals and generating reasonable group representations. However, previous methods either model spatial and temporal information separately, or directly aggregate individual features to form group features. To address these issues, we propose a novel group activity recognition network termed GroupFormer. It captures spatial-temporal contextual information jointly to augment the individual and group representations effectively with a clustered spatial-temporal transformer. Specifically, our GroupFormer has three appealing advantages: (1) A tailor-modified Transformer, Clustered Spatial-Temporal Transformer, is proposed to enhance the individual representation and group representation. (2) It models the spatial and temporal dependencies integrally and utilizes decoders to build the bridge between the spatial and temporal information. (3) A clustered attention mechanism is utilized to dynamically divide individuals into multiple clusters for better learning activity-aware semantic representations. Moreover, experimental results show that the proposed framework outperforms state-of-the-art methods on the Volleyball dataset and Collective Activity dataset. Code is available at https://github.com/xueyee/GroupFormer.
Learning Geometry-Guided Depth via Projective Modeling for Monocular 3D Object Detection
Jul 29, 2021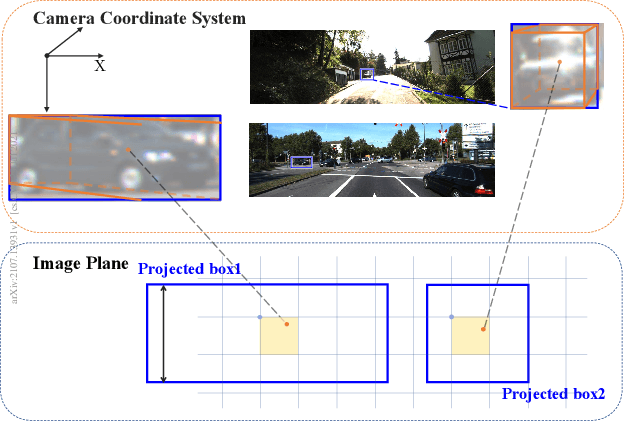
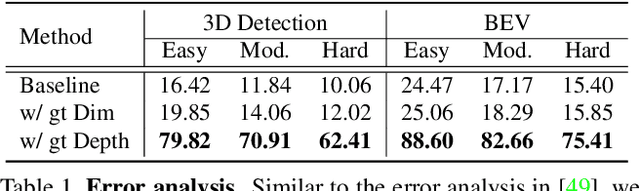

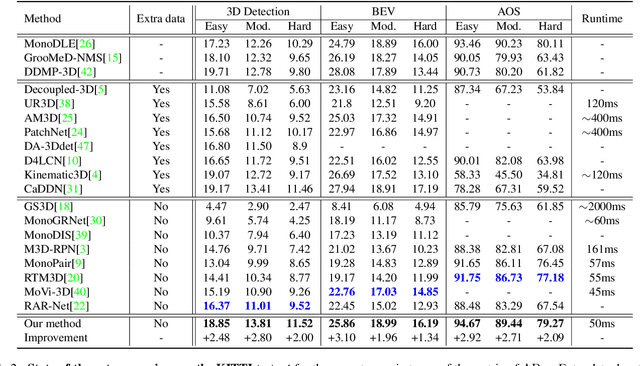
As a crucial task of autonomous driving, 3D object detection has made great progress in recent years. However, monocular 3D object detection remains a challenging problem due to the unsatisfactory performance in depth estimation. Most existing monocular methods typically directly regress the scene depth while ignoring important relationships between the depth and various geometric elements (e.g. bounding box sizes, 3D object dimensions, and object poses). In this paper, we propose to learn geometry-guided depth estimation with projective modeling to advance monocular 3D object detection. Specifically, a principled geometry formula with projective modeling of 2D and 3D depth predictions in the monocular 3D object detection network is devised. We further implement and embed the proposed formula to enable geometry-aware deep representation learning, allowing effective 2D and 3D interactions for boosting the depth estimation. Moreover, we provide a strong baseline through addressing substantial misalignment between 2D annotation and projected boxes to ensure robust learning with the proposed geometric formula. Experiments on the KITTI dataset show that our method remarkably improves the detection performance of the state-of-the-art monocular-based method without extra data by 2.80% on the moderate test setting. The model and code will be released at https://github.com/YinminZhang/MonoGeo.
Video Crowd Localization with Multi-focus Gaussian Neighbor Attention and a Large-Scale Benchmark
Jul 20, 2021
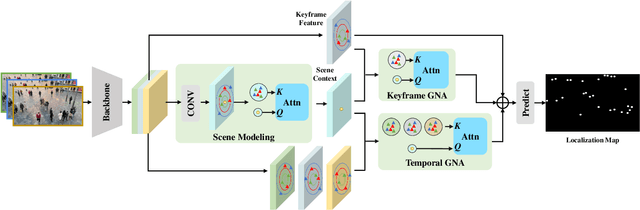

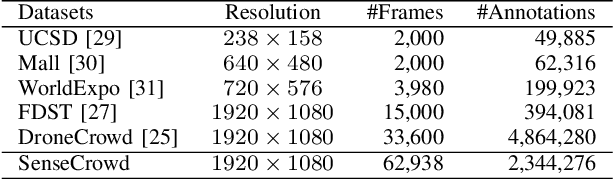
Video crowd localization is a crucial yet challenging task, which aims to estimate exact locations of human heads in the given crowded videos. To model spatial-temporal dependencies of human mobility, we propose a multi-focus Gaussian neighbor attention (GNA), which can effectively exploit long-range correspondences while maintaining the spatial topological structure of the input videos. In particular, our GNA can also capture the scale variation of human heads well using the equipped multi-focus mechanism. Based on the multi-focus GNA, we develop a unified neural network called GNANet to accurately locate head centers in video clips by fully aggregating spatial-temporal information via a scene modeling module and a context cross-attention module. Moreover, to facilitate future researches in this field, we introduce a large-scale crowded video benchmark named SenseCrowd, which consists of 60K+ frames captured in various surveillance scenarios and 2M+ head annotations. Finally, we conduct extensive experiments on three datasets including our SenseCrowd, and the experiment results show that the proposed method is capable to achieve state-of-the-art performance for both video crowd localization and counting. The code and the dataset will be released.
Cloud-Based Dynamic Programming for an Electric City Bus Energy Management Considering Real-Time Passenger Load Prediction
Oct 28, 2020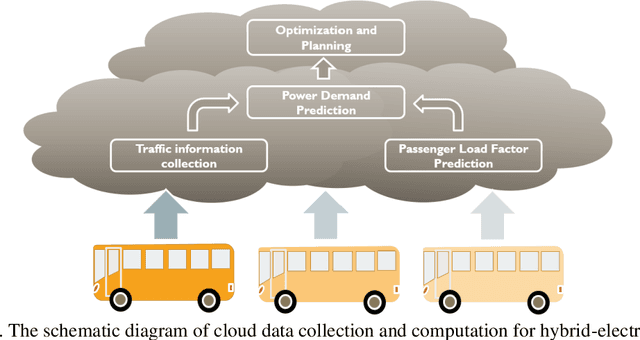
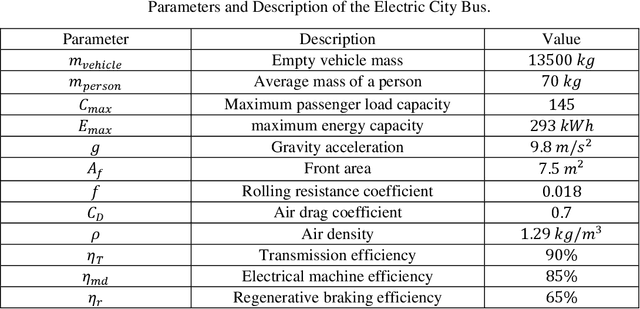
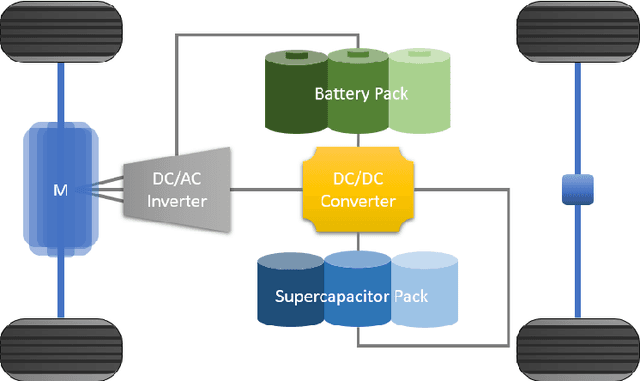

Electric city bus gains popularity in recent years for its low greenhouse gas emission, low noise level, etc. Different from a passenger car, the weight of a city bus varies significantly with different amounts of onboard passengers, which is not well studied in existing literature. This study proposes a passenger load prediction model using day-of-week, time-of-day, weather, temperatures, wind levels, and holiday information as inputs. The average model, Regression Tree, Gradient Boost Decision Tree, and Neural Networks models are compared in the passenger load prediction. The Gradient Boost Decision Tree model is selected due to its best accuracy and high stability. Given the predicted passenger load, dynamic programming algorithm determines the optimal power demand for supercapacitor and battery by optimizing the battery aging and energy usage in the cloud. Then rule extraction is conducted on dynamic programming results, and the rule is real-time loaded to onboard controllers of vehicles. The proposed cloud-based dynamic programming and rule extraction framework with the passenger load prediction shows 4% and 11% fewer bus operating costs in off-peak and peak hours, respectively. The operating cost by the proposed framework is less than 1% shy of the dynamic programming with the true passenger load information.