 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrossViewDiff: A Cross-View Diffusion Model for Satellite-to-Street View Synthesis
Aug 27, 2024



Satellite-to-street view synthesis aims at generating a realistic street-view image from its corresponding satellite-view image. Although stable diffusion models have exhibit remarkable performance in a variety of image generation applications, their reliance on similar-view inputs to control the generated structure or texture restricts their application to the challenging cross-view synthesis task. In this work, we propose CrossViewDiff, a cross-view diffusion model for satellite-to-street view synthesis. To address the challenges posed by the large discrepancy across views, we design the satellite scene structure estimation and cross-view texture mapping modules to construct the structural and textural controls for street-view image synthesis. We further design a cross-view control guided denoising process that incorporates the above controls via an enhanced cross-view attention module. To achieve a more comprehensive evaluation of the synthesis results, we additionally design a GPT-based scoring method as a supplement to standard evaluation metrics. We also explore the effect of different data sources (e.g., text, maps, building heights, and multi-temporal satellite imagery) on this task. Results on three public cross-view datasets show that CrossViewDiff outperforms current state-of-the-art on both standard and GPT-based evaluation metrics, generating high-quality street-view panoramas with more realistic structures and textures across rural, suburban, and urban scenes. The code and models of this work will be released at https://opendatalab.github.io/CrossViewDiff/.
Meta-Learning Empowered Meta-Face: Personalized Speaking Style Adaptation for Audio-Driven 3D Talking Face Animation
Aug 18, 2024



Audio-driven 3D face animation is increasingly vital in live streaming and augmented reality applications. While remarkable progress has been observed, most existing approaches are designed for specific individuals with predefined speaking styles, thus neglecting the adaptability to varied speaking styles. To address this limitation, this paper introduces MetaFace, a novel methodology meticulously crafted for speaking style adaptation. Grounded in the novel concept of meta-learning, MetaFace is composed of several key components: the Robust Meta Initialization Stage (RMIS) for fundamental speaking style adaptation, the Dynamic Relation Mining Neural Process (DRMN) for forging connections between observed and unobserved speaking styles, and the Low-rank Matrix Memory Reduction Approach to enhance the efficiency of model optimization as well as learning style details. Leveraging these novel designs, MetaFace not only significantly outperforms robust existing baselines but also establishes a new state-of-the-art, as substantiated by our experimental results.
SkyDiffusion: Street-to-Satellite Image Synthesis with Diffusion Models and BEV Paradigm
Aug 03, 2024
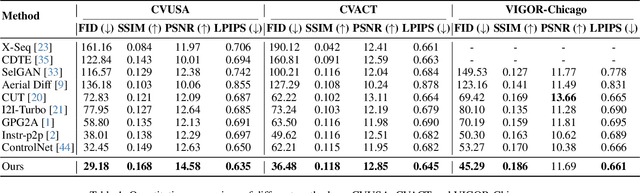

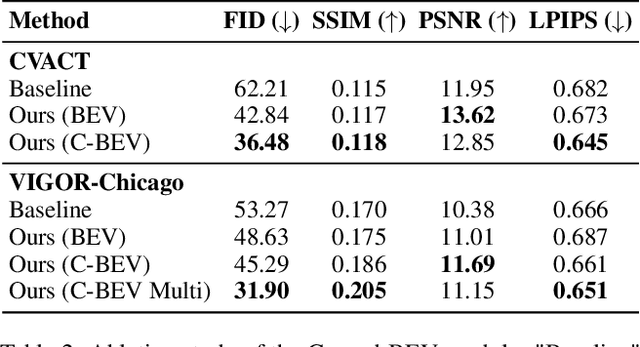
Street-to-satellite image synthesis focuses on generating realistic satellite images from corresponding ground street-view images while maintaining a consistent content layout, similar to looking down from the sky. The significant differences in perspectives create a substantial domain gap between the views, making this cross-view generation task particularly challenging. In this paper, we introduce SkyDiffusion, a novel cross-view generation method for synthesizing satellite images from street-view images, leveraging diffusion models and Bird's Eye View (BEV) paradigm. First, we design a Curved-BEV method to transform street-view images to the satellite view, reformulating the challenging cross-domain image synthesis task into a conditional generation problem. Curved-BEV also includes a "Multi-to-One" mapping strategy for combining multiple street-view images within the same satellite coverage area, effectively solving the occlusion issues in dense urban scenes. Next, we design a BEV-controlled diffusion model to generate satellite images consistent with the street-view content, which also incorporates a light manipulation module to optimize the lighting condition of the synthesized image using a reference satellite. Experimental results demonstrate that SkyDiffusion outperforms state-of-the-art methods on both suburban (CVUSA & CVACT) and urban (VIGOR-Chicago) cross-view datasets, with an average SSIM increase of 14.5% and a FID reduction of 29.6%, achieving realistic and content-consistent satellite image generation. The code and models of this work will be released at https://opendatalab.github.io/skydiffusion/.
SyncTalk: The Devil is in the Synchronization for Talking Head Synthesis
Nov 29, 2023Achieving high synchronization in the synthesis of realistic, speech-driven talking head videos presents a significant challenge. Traditional Generative Adversarial Networks (GAN) struggle to maintain consistent facial identity, while Neural Radiance Fields (NeRF) methods, although they can address this issue, often produce mismatched lip movements, inadequate facial expressions, and unstable head poses. A lifelike talking head requires synchronized coordination of subject identity, lip movements, facial expressions, and head poses. The absence of these synchronizations is a fundamental flaw, leading to unrealistic and artificial outcomes. To address the critical issue of synchronization, identified as the "devil" in creating realistic talking heads, we introduce SyncTalk. This NeRF-based method effectively maintains subject identity, enhancing synchronization and realism in talking head synthesis. SyncTalk employs a Face-Sync Controller to align lip movements with speech and innovatively uses a 3D facial blendshape model to capture accurate facial expressions. Our Head-Sync Stabilizer optimizes head poses, achieving more natural head movements. The Portrait-Sync Generator restores hair details and blends the generated head with the torso for a seamless visual experience. Extensive experiments and user studies demonstrate that SyncTalk outperforms state-of-the-art methods in synchronization and realism. We recommend watching the supplementary video: https://ziqiaopeng.github.io/synctalk
Fast Estimations of Hitting Time of Elitist Evolutionary Algorithms from Fitness Levels
Nov 17, 2023



The fitness level method is an easy-to-use tool for estimating the hitting time of elitist EAs. Recently, general linear lower and upper bounds from fitness levels have been constructed. However, the construction of these bounds requires recursive computation, which makes them difficult to use in practice. We address this shortcoming with a new directed graph (digraph) method that does not require recursive computation and significantly simplifies the calculation of coefficients in linear bounds. In this method, an EA is modeled as a Markov chain on a digraph. Lower and upper bounds are directly calculated using conditional transition probabilities on the digraph. This digraph method provides straightforward and explicit expressions of lower and upper time bound for elitist EAs. In particular, it can be used to derive tight lower bound on both fitness landscapes without and with shortcuts. This is demonstrated through four examples: the (1+1) EA on OneMax, FullyDeceptive, TwoMax1 and Deceptive. Our work extends the fitness level method from addressing simple fitness functions without shortcuts to more realistic functions with shortcuts.
BeatDance: A Beat-Based Model-Agnostic Contrastive Learning Framework for Music-Dance Retrieval
Oct 16, 2023



Dance and music are closely related forms of expression, with mutual retrieval between dance videos and music being a fundamental task in various fields like education, art, and sports. However, existing methods often suffer from unnatural generation effects or fail to fully explore the correlation between music and dance. To overcome these challenges, we propose BeatDance, a novel beat-based model-agnostic contrastive learning framework. BeatDance incorporates a Beat-Aware Music-Dance InfoExtractor, a Trans-Temporal Beat Blender, and a Beat-Enhanced Hubness Reducer to improve dance-music retrieval performance by utilizing the alignment between music beats and dance movements. We also introduce the Music-Dance (MD) dataset, a large-scale collection of over 10,000 music-dance video pairs for training and testing. Experimental results on the MD dataset demonstrate the superiority of our method over existing baselines, achieving state-of-the-art performance. The code and dataset will be made public available upon acceptance.
STDG: Semi-Teacher-Student Training Paradigram for Depth-guided One-stage Scene Graph Generation
Sep 15, 2023



Scene Graph Generation is a critical enabler of environmental comprehension for autonomous robotic systems. Most of existing methods, however, are often thwarted by the intricate dynamics of background complexity, which limits their ability to fully decode the inherent topological information of the environment. Additionally, the wealth of contextual information encapsulated within depth cues is often left untapped, rendering existing approaches less effective. To address these shortcomings, we present STDG, an avant-garde Depth-Guided One-Stage Scene Graph Generation methodology. The innovative architecture of STDG is a triad of custom-built modules: The Depth Guided HHA Representation Generation Module, the Depth Guided Semi-Teaching Network Learning Module, and the Depth Guided Scene Graph Generation Module. This trifecta of modules synergistically harnesses depth information, covering all aspects from depth signal generation and depth feature utilization, to the final scene graph prediction. Importantly, this is achieved without imposing additional computational burden during the inference phase. Experimental results confirm that our method significantly enhances the performance of one-stage scene graph generation baselines.
Drift Analysis with Fitness Levels for Elitist Evolutionary Algorithms
Sep 02, 2023



The fitness level method is a popular tool for analyzing the computation time of elitist evolutionary algorithms. Its idea is to divide the search space into multiple fitness levels and estimate lower and upper bounds on the computation time using transition probabilities between fitness levels. However, the lower bound generated from this method is often not tight. To improve the lower bound, this paper rigorously studies an open question about the fitness level method: what are the tightest lower and upper time bounds that can be constructed based on fitness levels? To answer this question, drift analysis with fitness levels is developed, and the tightest bound problem is formulated as a constrained multi-objective optimization problem subject to fitness level constraints. The tightest metric bounds from fitness levels are constructed and proven for the first time. Then the metric bounds are converted into linear bounds, where existing linear bounds are special cases. This paper establishes a general framework that can cover various linear bounds from trivial to best coefficients. It is generic and promising, as it can be used not only to draw the same bounds as existing ones, but also to draw tighter bounds, especially on fitness landscapes where shortcuts exist. This is demonstrated in the case study of the (1+1) EA maximizing the TwoPath function.
SelfTalk: A Self-Supervised Commutative Training Diagram to Comprehend 3D Talking Faces
Jun 19, 2023



Speech-driven 3D face animation technique, extending its applications to various multimedia fields. Previous research has generated promising realistic lip movements and facial expressions from audio signals. However, traditional regression models solely driven by data face several essential problems, such as difficulties in accessing precise labels and domain gaps between different modalities, leading to unsatisfactory results lacking precision and coherence. To enhance the visual accuracy of generated lip movement while reducing the dependence on labeled data, we propose a novel framework SelfTalk, by involving self-supervision in a cross-modals network system to learn 3D talking faces. The framework constructs a network system consisting of three modules: facial animator, speech recognizer, and lip-reading interpreter. The core of SelfTalk is a commutative training diagram that facilitates compatible features exchange among audio, text, and lip shape, enabling our models to learn the intricate connection between these factors. The proposed framework leverages the knowledge learned from the lip-reading interpreter to generate more plausible lip shapes. Extensive experiments and user studies demonstrate that our proposed approach achieves state-of-the-art performance both qualitatively and quantitatively. We recommend watching the supplementary video.
Backdoor Attacks with Input-unique Triggers in NLP
Mar 25, 2023Backdoor attack aims at inducing neural models to make incorrect predictions for poison data while keeping predictions on the clean dataset unchanged, which creates a considerable threat to current natural language processing (NLP) systems. Existing backdoor attacking systems face two severe issues:firstly, most backdoor triggers follow a uniform and usually input-independent pattern, e.g., insertion of specific trigger words, synonym replacement. This significantly hinders the stealthiness of the attacking model, leading the trained backdoor model being easily identified as malicious by model probes. Secondly, trigger-inserted poisoned sentences are usually disfluent, ungrammatical, or even change the semantic meaning from the original sentence, making them being easily filtered in the pre-processing stage. To resolve these two issues, in this paper, we propose an input-unique backdoor attack(NURA), where we generate backdoor triggers unique to inputs. IDBA generates context-related triggers by continuing writing the input with a language model like GPT2. The generated sentence is used as the backdoor trigger. This strategy not only creates input-unique backdoor triggers, but also preserves the semantics of the original input, simultaneously resolving the two issues above. Experimental results show that the IDBA attack is effective for attack and difficult to defend: it achieves high attack success rate across all the widely applied benchmarks, while is immune to existing defending methods. In addition, it is able to generate fluent, grammatical, and diverse backdoor inputs, which can hardly be recognized through human inspection.