 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJun Guo
BALSON: Bayesian Least Squares Optimization with Nonnegative L1-Norm Constraint
Jul 08, 2018
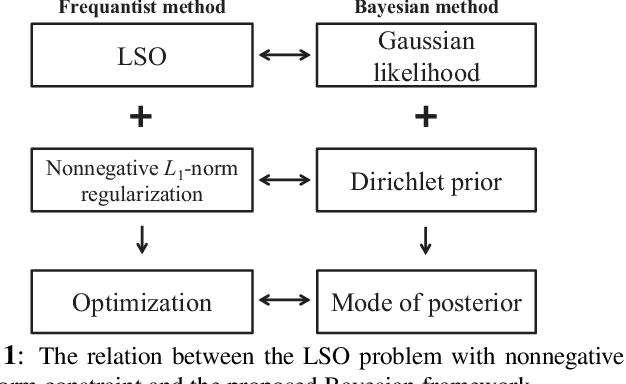
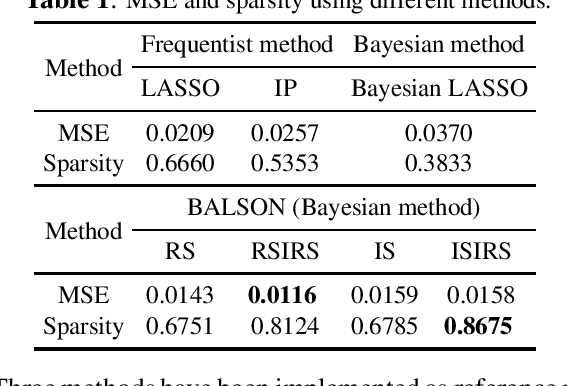
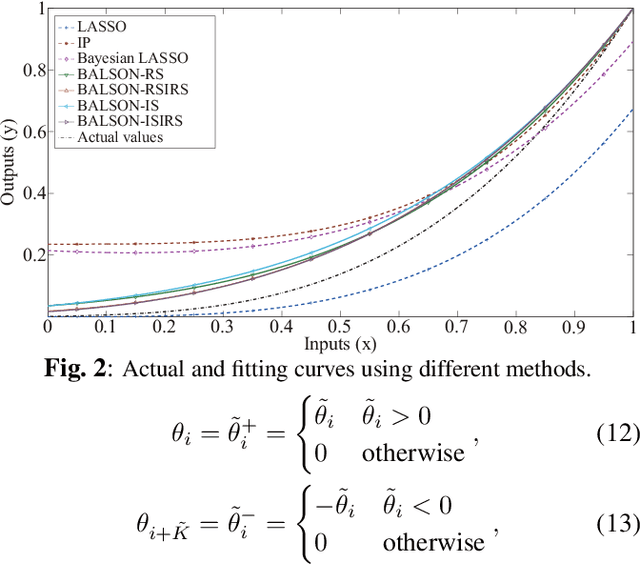
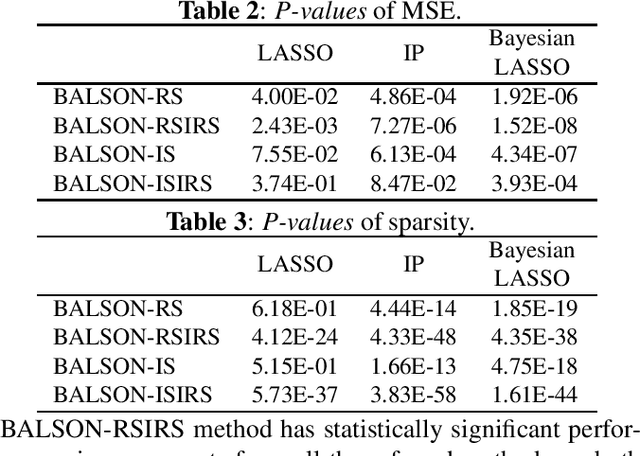
A Bayesian approach termed BAyesian Least Squares Optimization with Nonnegative L1-norm constraint (BALSON) is proposed. The error distribution of data fitting is described by Gaussian likelihood. The parameter distribution is assumed to be a Dirichlet distribution. With the Bayes rule, searching for the optimal parameters is equivalent to finding the mode of the posterior distribution. In order to explicitly characterize the nonnegative L1-norm constraint of the parameters, we further approximate the true posterior distribution by a Dirichlet distribution. We estimate the statistics of the approximating Dirichlet posterior distribution by sampling methods. Four sampling methods have been introduced. With the estimated posterior distributions, the original parameters can be effectively reconstructed in polynomial fitting problems, and the BALSON framework is found to perform better than conventional methods.
Constrained Sparse Subspace Clustering with Side-Information
May 22, 2018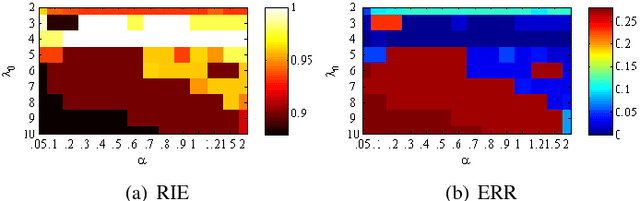
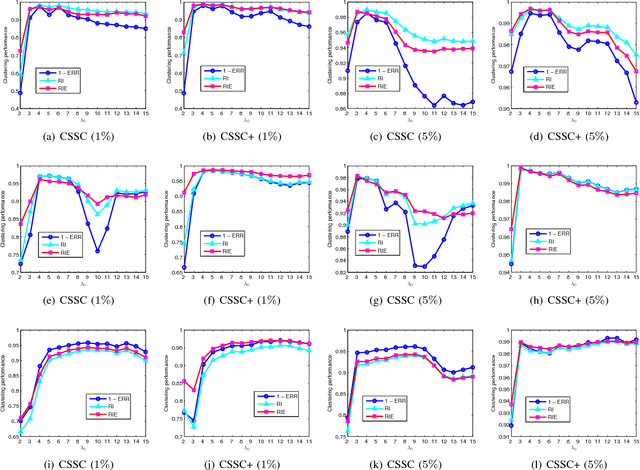

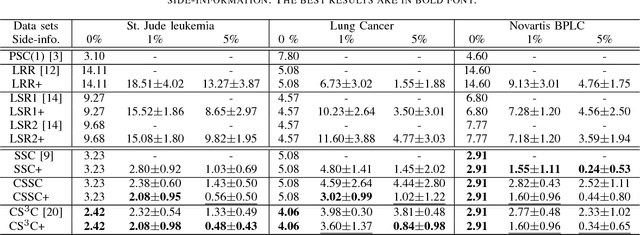
Subspace clustering refers to the problem of segmenting high dimensional data drawn from a union of subspaces into the respective subspaces. In some applications, partial side-information to indicate "must-link" or "cannot-link" in clustering is available. This leads to the task of subspace clustering with side-information. However, in prior work the supervision value of the side-information for subspace clustering has not been fully exploited. To this end, in this paper, we present an enhanced approach for constrained subspace clustering with side-information, termed Constrained Sparse Subspace Clustering plus (CSSC+), in which the side-information is used not only in the stage of learning an affinity matrix but also in the stage of spectral clustering. Moreover, we propose to estimate clustering accuracy based on the partial side-information and theoretically justify the connection to the ground-truth clustering accuracy in terms of the Rand index. We conduct experiments on three cancer gene expression datasets to validate the effectiveness of our proposals.
SketchMate: Deep Hashing for Million-Scale Human Sketch Retrieval
Apr 04, 2018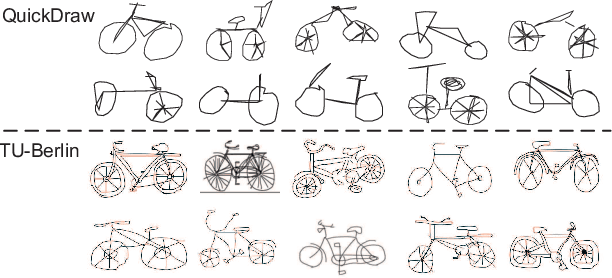
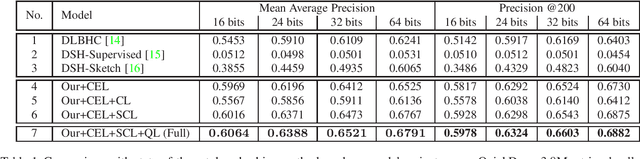
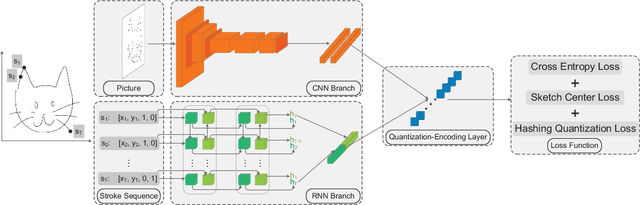
We propose a deep hashing framework for sketch retrieval that, for the first time, works on a multi-million scale human sketch dataset. Leveraging on this large dataset, we explore a few sketch-specific traits that were otherwise under-studied in prior literature. Instead of following the conventional sketch recognition task, we introduce the novel problem of sketch hashing retrieval which is not only more challenging, but also offers a better testbed for large-scale sketch analysis, since: (i) more fine-grained sketch feature learning is required to accommodate the large variations in style and abstraction, and (ii) a compact binary code needs to be learned at the same time to enable efficient retrieval. Key to our network design is the embedding of unique characteristics of human sketch, where (i) a two-branch CNN-RNN architecture is adapted to explore the temporal ordering of strokes, and (ii) a novel hashing loss is specifically designed to accommodate both the temporal and abstract traits of sketches. By working with a 3.8M sketch dataset, we show that state-of-the-art hashing models specifically engineered for static images fail to perform well on temporal sketch data. Our network on the other hand not only offers the best retrieval performance on various code sizes, but also yields the best generalization performance under a zero-shot setting and when re-purposed for sketch recognition. Such superior performances effectively demonstrate the benefit of our sketch-specific design.
Robust Actor-Critic Contextual Bandit for Mobile Health (mHealth) Interventions
Feb 27, 2018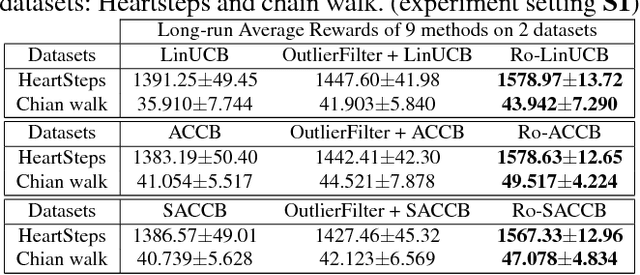
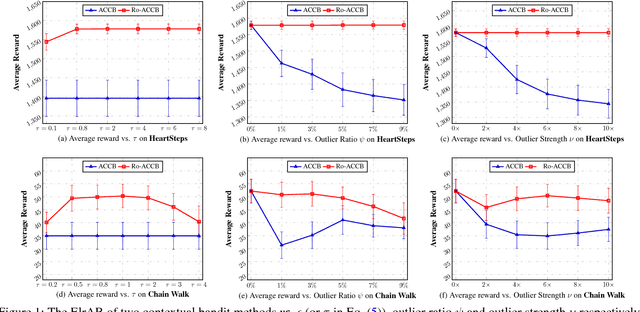
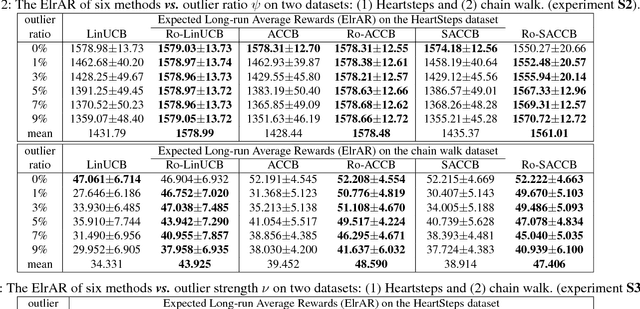
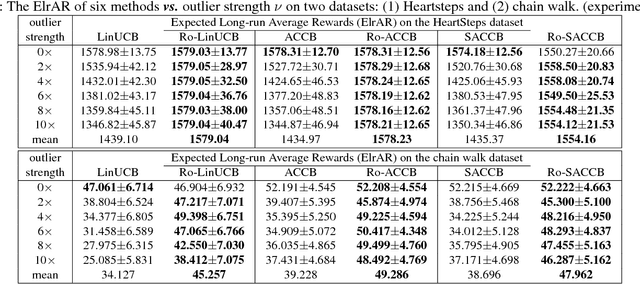
We consider the actor-critic contextual bandit for the mobile health (mHealth) intervention. State-of-the-art decision-making algorithms generally ignore the outliers in the dataset. In this paper, we propose a novel robust contextual bandit method for the mHealth. It can achieve the conflicting goal of reducing the influence of outliers while seeking for a similar solution compared with the state-of-the-art contextual bandit methods on the datasets without outliers. Such performance relies on two technologies: (1) the capped-$\ell_{2}$ norm; (2) a reliable method to set the thresholding hyper-parameter, which is inspired by one of the most fundamental techniques in the statistics. Although the model is non-convex and non-differentiable, we propose an effective reweighted algorithm and provide solid theoretical analyses. We prove that the proposed algorithm can find sufficiently decreasing points after each iteration and finally converges after a finite number of iterations. Extensive experiment results on two datasets demonstrate that our method can achieve almost identical results compared with state-of-the-art contextual bandit methods on the dataset without outliers, and significantly outperform those state-of-the-art methods on the badly noised dataset with outliers in a variety of parameter settings.
Group-driven Reinforcement Learning for Personalized mHealth Intervention
Aug 14, 2017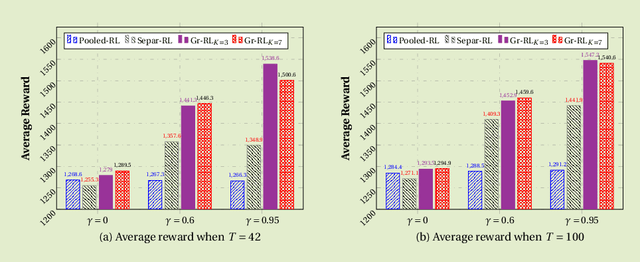
Due to the popularity of smartphones and wearable devices nowadays, mobile health (mHealth) technologies are promising to bring positive and wide impacts on people's health. State-of-the-art decision-making methods for mHealth rely on some ideal assumptions. Those methods either assume that the users are completely homogenous or completely heterogeneous. However, in reality, a user might be similar with some, but not all, users. In this paper, we propose a novel group-driven reinforcement learning method for the mHealth. We aim to understand how to share information among similar users to better convert the limited user information into sharper learned RL policies. Specifically, we employ the K-means clustering method to group users based on their trajectory information similarity and learn a shared RL policy for each group. Extensive experiment results have shown that our method can achieve clear gains over the state-of-the-art RL methods for mHealth.
Decorrelation of Neutral Vector Variables: Theory and Applications
May 30, 2017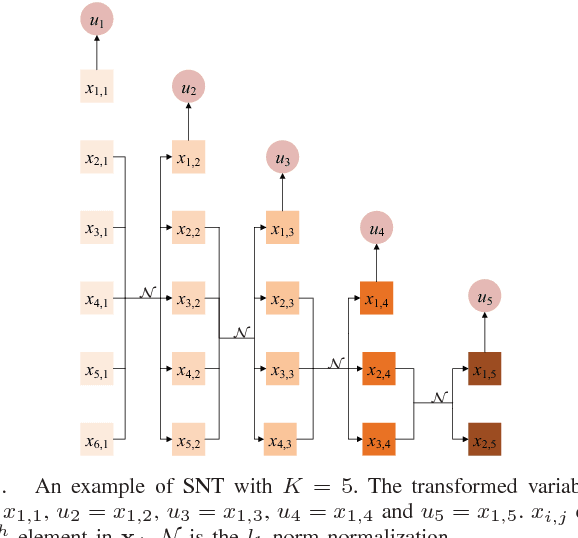
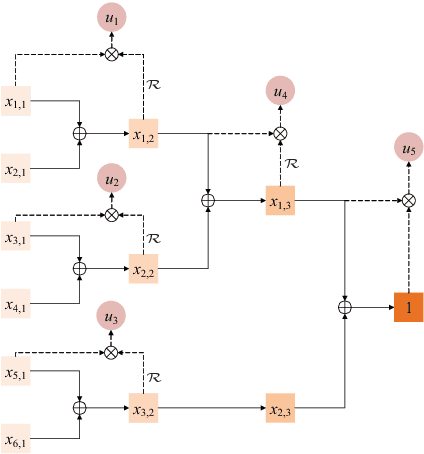
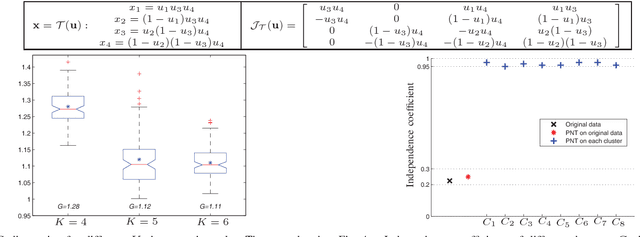
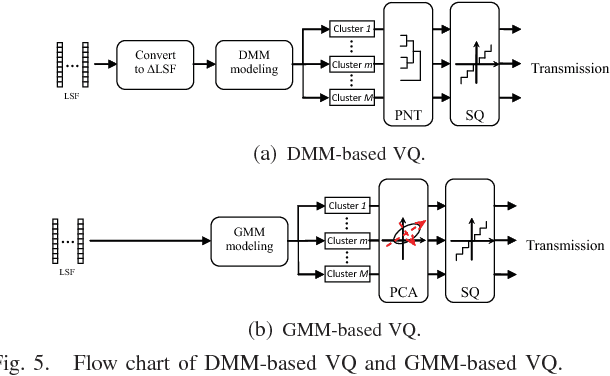
In this paper, we propose novel strategies for neutral vector variable decorrelation. Two fundamental invertible transformations, namely serial nonlinear transformation and parallel nonlinear transformation, are proposed to carry out the decorrelation. For a neutral vector variable, which is not multivariate Gaussian distributed, the conventional principal component analysis (PCA) cannot yield mutually independent scalar variables. With the two proposed transformations, a highly negatively correlated neutral vector can be transformed to a set of mutually independent scalar variables with the same degrees of freedom. We also evaluate the decorrelation performances for the vectors generated from a single Dirichlet distribution and a mixture of Dirichlet distributions. The mutual independence is verified with the distance correlation measurement. The advantages of the proposed decorrelation strategies are intensively studied and demonstrated with synthesized data and practical application evaluations.
Cross-modal Subspace Learning for Fine-grained Sketch-based Image Retrieval
May 28, 2017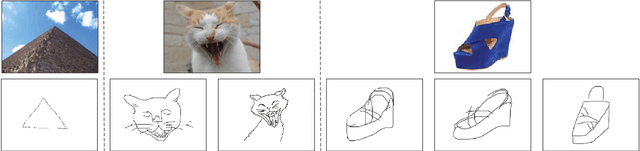
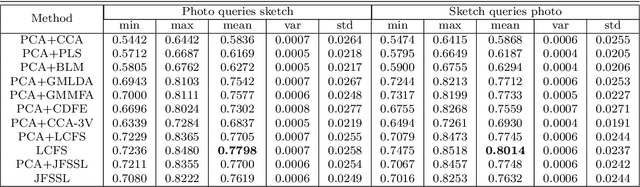
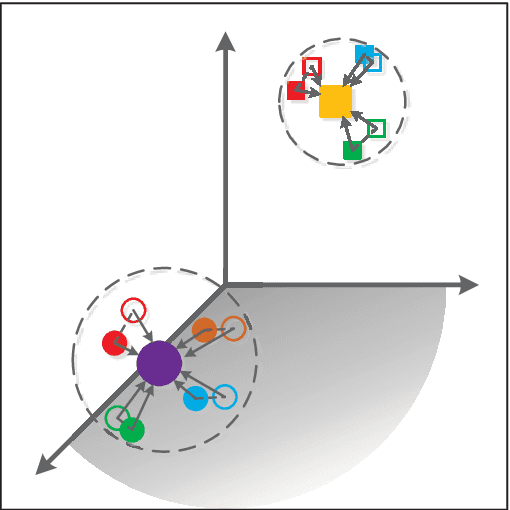
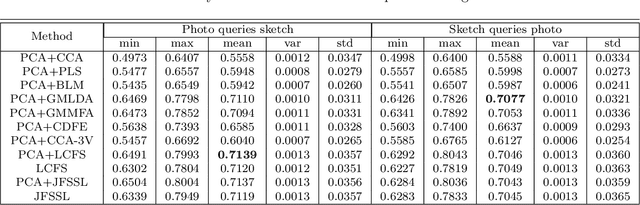
Sketch-based image retrieval (SBIR) is challenging due to the inherent domain-gap between sketch and photo. Compared with pixel-perfect depictions of photos, sketches are iconic renderings of the real world with highly abstract. Therefore, matching sketch and photo directly using low-level visual clues are unsufficient, since a common low-level subspace that traverses semantically across the two modalities is non-trivial to establish. Most existing SBIR studies do not directly tackle this cross-modal problem. This naturally motivates us to explore the effectiveness of cross-modal retrieval methods in SBIR, which have been applied in the image-text matching successfully. In this paper, we introduce and compare a series of state-of-the-art cross-modal subspace learning methods and benchmark them on two recently released fine-grained SBIR datasets. Through thorough examination of the experimental results, we have demonstrated that the subspace learning can effectively model the sketch-photo domain-gap. In addition we draw a few key insights to drive future research.
One-to-Many Network for Visually Pleasing Compression Artifacts Reduction
Apr 11, 2017

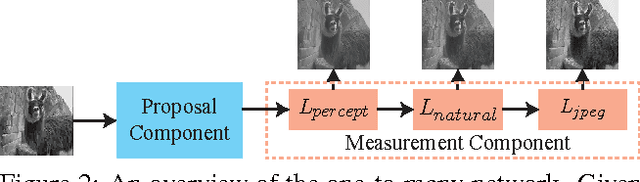
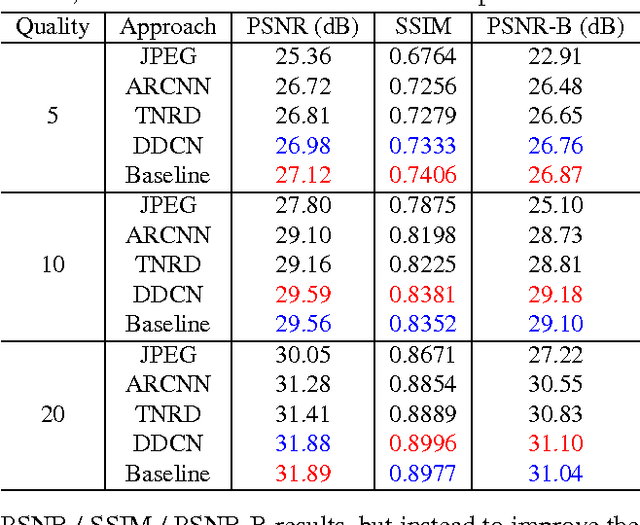
We consider the compression artifacts reduction problem, where a compressed image is transformed into an artifact-free image. Recent approaches for this problem typically train a one-to-one mapping using a per-pixel $L_2$ loss between the outputs and the ground-truths. We point out that these approaches used to produce overly smooth results, and PSNR doesn't reflect their real performance. In this paper, we propose a one-to-many network, which measures output quality using a perceptual loss, a naturalness loss, and a JPEG loss. We also avoid grid-like artifacts during deconvolution using a "shift-and-average" strategy. Extensive experimental results demonstrate the dramatic visual improvement of our approach over the state of the arts.
DNN Filter Bank Cepstral Coefficients for Spoofing Detection
Feb 13, 2017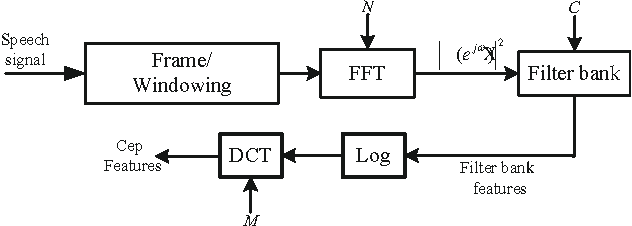
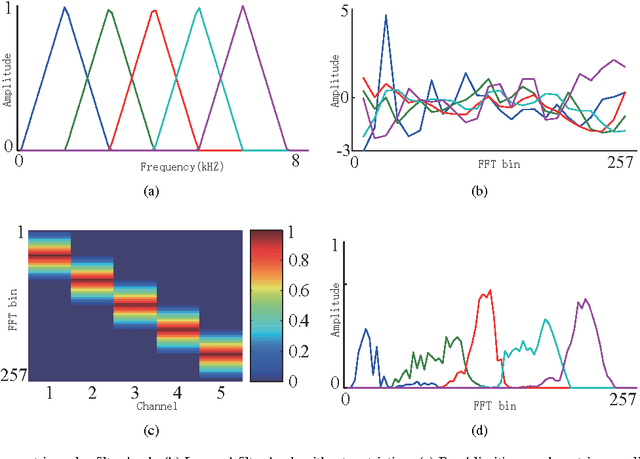
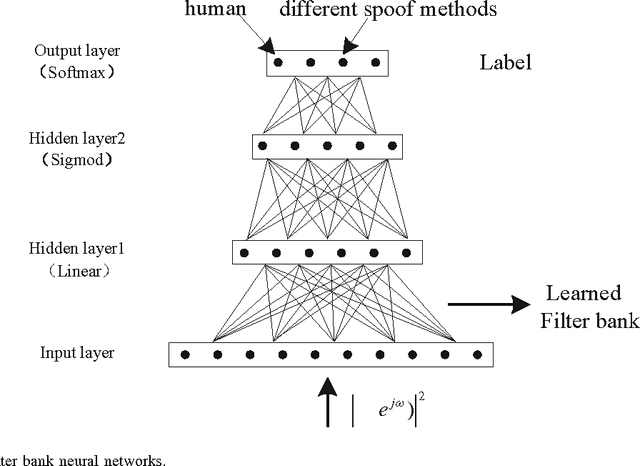
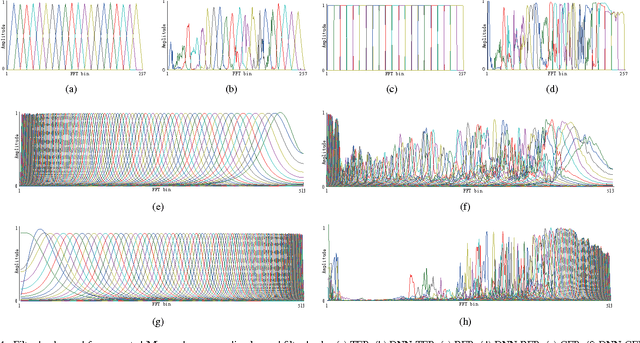
With the development of speech synthesis techniques, automatic speaker verification systems face the serious challenge of spoofing attack. In order to improve the reliability of speaker verification systems, we develop a new filter bank based cepstral feature, deep neural network filter bank cepstral coefficients (DNN-FBCC), to distinguish between natural and spoofed speech. The deep neural network filter bank is automatically generated by training a filter bank neural network (FBNN) using natural and synthetic speech. By adding restrictions on the training rules, the learned weight matrix of FBNN is band-limited and sorted by frequency, similar to the normal filter bank. Unlike the manually designed filter bank, the learned filter bank has different filter shapes in different channels, which can capture the differences between natural and synthetic speech more effectively. The experimental results on the ASVspoof {2015} database show that the Gaussian mixture model maximum-likelihood (GMM-ML) classifier trained by the new feature performs better than the state-of-the-art linear frequency cepstral coefficients (LFCC) based classifier, especially on detecting unknown attacks.
HEp-2 Cell Classification via Fusing Texture and Shape Information
Feb 16, 2015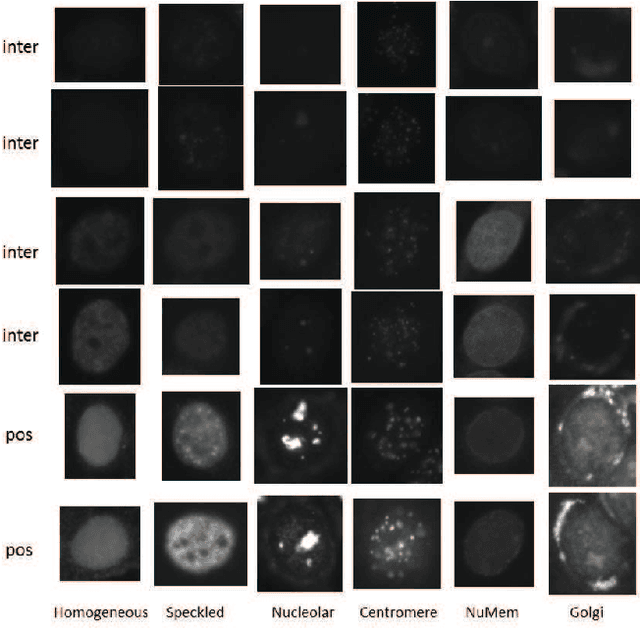
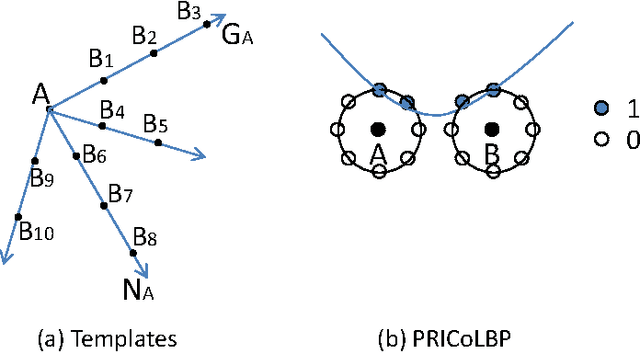
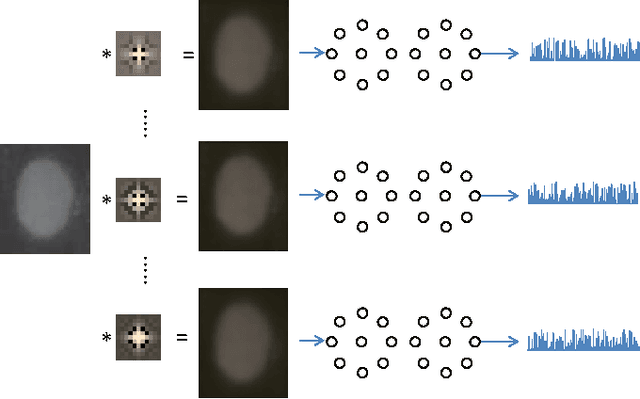
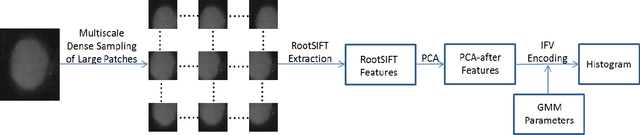
Indirect Immunofluorescence (IIF) HEp-2 cell image is an effective evidence for diagnosis of autoimmune diseases. Recently computer-aided diagnosis of autoimmune diseases by IIF HEp-2 cell classification has attracted great attention. However the HEp-2 cell classification task is quite challenging due to large intra-class variation and small between-class variation. In this paper we propose an effective and efficient approach for the automatic classification of IIF HEp-2 cell image by fusing multi-resolution texture information and richer shape information. To be specific, we propose to: a) capture the multi-resolution texture information by a novel Pairwise Rotation Invariant Co-occurrence of Local Gabor Binary Pattern (PRICoLGBP) descriptor, b) depict the richer shape information by using an Improved Fisher Vector (IFV) model with RootSIFT features which are sampled from large image patches in multiple scales, and c) combine them properly. We evaluate systematically the proposed approach on the IEEE International Conference on Pattern Recognition (ICPR) 2012, IEEE International Conference on Image Processing (ICIP) 2013 and ICPR 2014 contest data sets. The experimental results for the proposed methods significantly outperform the winners of ICPR 2012 and ICIP 2013 contest, and achieve comparable performance with the winner of the newly released ICPR 2014 contest.