 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForecast-PEFT: Parameter-Efficient Fine-Tuning for Pre-trained Motion Forecasting Models
Jul 28, 2024



Recent progress in motion forecasting has been substantially driven by self-supervised pre-training. However, adapting pre-trained models for specific downstream tasks, especially motion prediction, through extensive fine-tuning is often inefficient. This inefficiency arises because motion prediction closely aligns with the masked pre-training tasks, and traditional full fine-tuning methods fail to fully leverage this alignment. To address this, we introduce Forecast-PEFT, a fine-tuning strategy that freezes the majority of the model's parameters, focusing adjustments on newly introduced prompts and adapters. This approach not only preserves the pre-learned representations but also significantly reduces the number of parameters that need retraining, thereby enhancing efficiency. This tailored strategy, supplemented by our method's capability to efficiently adapt to different datasets, enhances model efficiency and ensures robust performance across datasets without the need for extensive retraining. Our experiments show that Forecast-PEFT outperforms traditional full fine-tuning methods in motion prediction tasks, achieving higher accuracy with only 17% of the trainable parameters typically required. Moreover, our comprehensive adaptation, Forecast-FT, further improves prediction performance, evidencing up to a 9.6% enhancement over conventional baseline methods. Code will be available at https://github.com/csjfwang/Forecast-PEFT.
GroupMamba: Parameter-Efficient and Accurate Group Visual State Space Model
Jul 18, 2024



Recent advancements in state-space models (SSMs) have showcased effective performance in modeling long-range dependencies with subquadratic complexity. However, pure SSM-based models still face challenges related to stability and achieving optimal performance on computer vision tasks. Our paper addresses the challenges of scaling SSM-based models for computer vision, particularly the instability and inefficiency of large model sizes. To address this, we introduce a Modulated Group Mamba layer which divides the input channels into four groups and applies our proposed SSM-based efficient Visual Single Selective Scanning (VSSS) block independently to each group, with each VSSS block scanning in one of the four spatial directions. The Modulated Group Mamba layer also wraps the four VSSS blocks into a channel modulation operator to improve cross-channel communication. Furthermore, we introduce a distillation-based training objective to stabilize the training of large models, leading to consistent performance gains. Our comprehensive experiments demonstrate the merits of the proposed contributions, leading to superior performance over existing methods for image classification on ImageNet-1K, object detection, instance segmentation on MS-COCO, and semantic segmentation on ADE20K. Our tiny variant with 23M parameters achieves state-of-the-art performance with a classification top-1 accuracy of 83.3% on ImageNet-1K, while being 26% efficient in terms of parameters, compared to the best existing Mamba design of same model size. Our code and models are available at: https://github.com/Amshaker/GroupMamba.
Gated Temporal Diffusion for Stochastic Long-Term Dense Anticipation
Jul 16, 2024



Long-term action anticipation has become an important task for many applications such as autonomous driving and human-robot interaction. Unlike short-term anticipation, predicting more actions into the future imposes a real challenge with the increasing uncertainty in longer horizons. While there has been a significant progress in predicting more actions into the future, most of the proposed methods address the task in a deterministic setup and ignore the underlying uncertainty. In this paper, we propose a novel Gated Temporal Diffusion (GTD) network that models the uncertainty of both the observation and the future predictions. As generator, we introduce a Gated Anticipation Network (GTAN) to model both observed and unobserved frames of a video in a mutual representation. On the one hand, using a mutual representation for past and future allows us to jointly model ambiguities in the observation and future, while on the other hand GTAN can by design treat the observed and unobserved parts differently and steer the information flow between them. Our model achieves state-of-the-art results on the Breakfast, Assembly101 and 50Salads datasets in both stochastic and deterministic settings. Code: https://github.com/olga-zats/GTDA .
Rethinking temporal self-similarity for repetitive action counting
Jul 12, 2024



Counting repetitive actions in long untrimmed videos is a challenging task that has many applications such as rehabilitation. State-of-the-art methods predict action counts by first generating a temporal self-similarity matrix (TSM) from the sampled frames and then feeding the matrix to a predictor network. The self-similarity matrix, however, is not an optimal input to a network since it discards too much information from the frame-wise embeddings. We thus rethink how a TSM can be utilized for counting repetitive actions and propose a framework that learns embeddings and predicts action start probabilities at full temporal resolution. The number of repeated actions is then inferred from the action start probabilities. In contrast to current approaches that have the TSM as an intermediate representation, we propose a novel loss based on a generated reference TSM, which enforces that the self-similarity of the learned frame-wise embeddings is consistent with the self-similarity of repeated actions. The proposed framework achieves state-of-the-art results on three datasets, i.e., RepCount, UCFRep, and Countix.
ADA-Track: End-to-End Multi-Camera 3D Multi-Object Tracking with Alternating Detection and Association
May 14, 2024Many query-based approaches for 3D Multi-Object Tracking (MOT) adopt the tracking-by-attention paradigm, utilizing track queries for identity-consistent detection and object queries for identity-agnostic track spawning. Tracking-by-attention, however, entangles detection and tracking queries in one embedding for both the detection and tracking task, which is sub-optimal. Other approaches resemble the tracking-by-detection paradigm, detecting objects using decoupled track and detection queries followed by a subsequent association. These methods, however, do not leverage synergies between the detection and association task. Combining the strengths of both paradigms, we introduce ADA-Track, a novel end-to-end framework for 3D MOT from multi-view cameras. We introduce a learnable data association module based on edge-augmented cross-attention, leveraging appearance and geometric features. Furthermore, we integrate this association module into the decoder layer of a DETR-based 3D detector, enabling simultaneous DETR-like query-to-image cross-attention for detection and query-to-query cross-attention for data association. By stacking these decoder layers, queries are refined for the detection and association task alternately, effectively harnessing the task dependencies. We evaluate our method on the nuScenes dataset and demonstrate the advantage of our approach compared to the two previous paradigms. Code is available at https://github.com/dsx0511/ADA-Track.
A Multimodal Handover Failure Detection Dataset and Baselines
Feb 28, 2024An object handover between a robot and a human is a coordinated action which is prone to failure for reasons such as miscommunication, incorrect actions and unexpected object properties. Existing works on handover failure detection and prevention focus on preventing failures due to object slip or external disturbances. However, there is a lack of datasets and evaluation methods that consider unpreventable failures caused by the human participant. To address this deficit, we present the multimodal Handover Failure Detection dataset, which consists of failures induced by the human participant, such as ignoring the robot or not releasing the object. We also present two baseline methods for handover failure detection: (i) a video classification method using 3D CNNs and (ii) a temporal action segmentation approach which jointly classifies the human action, robot action and overall outcome of the action. The results show that video is an important modality, but using force-torque data and gripper position help improve failure detection and action segmentation accuracy.
Wavelet Packet Power Spectrum Kullback-Leibler Divergence: A New Metric for Image Synthesis
Dec 23, 2023Current metrics for generative neural networks are biased towards low frequencies, specific generators, objects from the ImageNet dataset, and value texture more than shape. Many current quality metrics do not measure frequency information directly. In response, we propose a new frequency band-based quality metric, which opens a door into the frequency domain yet, at the same time, preserves spatial aspects of the data. Our metric works well even if the distributions we compare are far from ImageNet or have been produced by differing generator architectures. We verify the quality of our metric by sampling a broad selection of generative networks on a wide variety of data sets. A user study ensures our metric aligns with human perception. Furthermore, we show that frequency band guidance can improve the frequency domain fidelity of a current generative network.
VaLID: Variable-Length Input Diffusion for Novel View Synthesis
Dec 14, 2023


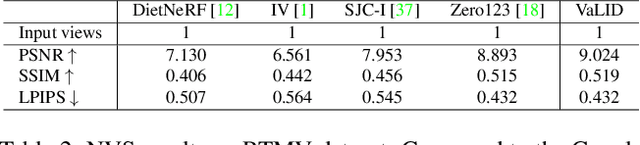
Novel View Synthesis (NVS), which tries to produce a realistic image at the target view given source view images and their corresponding poses, is a fundamental problem in 3D Vision. As this task is heavily under-constrained, some recent work, like Zero123, tries to solve this problem with generative modeling, specifically using pre-trained diffusion models. Although this strategy generalizes well to new scenes, compared to neural radiance field-based methods, it offers low levels of flexibility. For example, it can only accept a single-view image as input, despite realistic applications often offering multiple input images. This is because the source-view images and corresponding poses are processed separately and injected into the model at different stages. Thus it is not trivial to generalize the model into multi-view source images, once they are available. To solve this issue, we try to process each pose image pair separately and then fuse them as a unified visual representation which will be injected into the model to guide image synthesis at the target-views. However, inconsistency and computation costs increase as the number of input source-view images increases. To solve these issues, the Multi-view Cross Former module is proposed which maps variable-length input data to fix-size output data. A two-stage training strategy is introduced to further improve the efficiency during training time. Qualitative and quantitative evaluation over multiple datasets demonstrates the effectiveness of the proposed method against previous approaches. The code will be released according to the acceptance.
DiffAnt: Diffusion Models for Action Anticipation
Nov 27, 2023Anticipating future actions is inherently uncertain. Given an observed video segment containing ongoing actions, multiple subsequent actions can plausibly follow. This uncertainty becomes even larger when predicting far into the future. However, the majority of existing action anticipation models adhere to a deterministic approach, neglecting to account for future uncertainties. In this work, we rethink action anticipation from a generative view, employing diffusion models to capture different possible future actions. In this framework, future actions are iteratively generated from standard Gaussian noise in the latent space, conditioned on the observed video, and subsequently transitioned into the action space. Extensive experiments on four benchmark datasets, i.e., Breakfast, 50Salads, EpicKitchens, and EGTEA Gaze+, are performed and the proposed method achieves superior or comparable results to state-of-the-art methods, showing the effectiveness of a generative approach for action anticipation. Our code and trained models will be published on GitHub.
A Survey on Deep Learning Techniques for Action Anticipation
Sep 29, 2023



The ability to anticipate possible future human actions is essential for a wide range of applications, including autonomous driving and human-robot interaction. Consequently, numerous methods have been introduced for action anticipation in recent years, with deep learning-based approaches being particularly popular. In this work, we review the recent advances of action anticipation algorithms with a particular focus on daily-living scenarios. Additionally, we classify these methods according to their primary contributions and summarize them in tabular form, allowing readers to grasp the details at a glance. Furthermore, we delve into the common evaluation metrics and datasets used for action anticipation and provide future directions with systematical discussions.