 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReliable Robotic Task Execution in the Face of Anomalies
Oct 27, 2025Learned robot policies have consistently been shown to be versatile, but they typically have no built-in mechanism for handling the complexity of open environments, making them prone to execution failures; this implies that deploying policies without the ability to recognise and react to failures may lead to unreliable and unsafe robot behaviour. In this paper, we present a framework that couples a learned policy with a method to detect visual anomalies during policy deployment and to perform recovery behaviours when necessary, thereby aiming to prevent failures. Specifically, we train an anomaly detection model using data collected during nominal executions of a trained policy. This model is then integrated into the online policy execution process, so that deviations from the nominal execution can trigger a three-level sequential recovery process that consists of (i) pausing the execution temporarily, (ii) performing a local perturbation of the robot's state, and (iii) resetting the robot to a safe state by sampling from a learned execution success model. We verify our proposed method in two different scenarios: (i) a door handle reaching task with a Kinova Gen3 arm using a policy trained in simulation and transferred to the real robot, and (ii) an object placing task with a UFactory xArm 6 using a general-purpose policy model. Our results show that integrating policy execution with anomaly detection and recovery increases the execution success rate in environments with various anomalies, such as trajectory deviations and adversarial human interventions.
Enhancing Video-Based Robot Failure Detection Using Task Knowledge
Aug 26, 2025Robust robotic task execution hinges on the reliable detection of execution failures in order to trigger safe operation modes, recovery strategies, or task replanning. However, many failure detection methods struggle to provide meaningful performance when applied to a variety of real-world scenarios. In this paper, we propose a video-based failure detection approach that uses spatio-temporal knowledge in the form of the actions the robot performs and task-relevant objects within the field of view. Both pieces of information are available in most robotic scenarios and can thus be readily obtained. We demonstrate the effectiveness of our approach on three datasets that we amend, in part, with additional annotations of the aforementioned task-relevant knowledge. In light of the results, we also propose a data augmentation method that improves performance by applying variable frame rates to different parts of the video. We observe an improvement from 77.9 to 80.0 in F1 score on the ARMBench dataset without additional computational expense and an additional increase to 81.4 with test-time augmentation. The results emphasize the importance of spatio-temporal information during failure detection and suggest further investigation of suitable heuristics in future implementations. Code and annotations are available.
A Multimodal Handover Failure Detection Dataset and Baselines
Feb 28, 2024An object handover between a robot and a human is a coordinated action which is prone to failure for reasons such as miscommunication, incorrect actions and unexpected object properties. Existing works on handover failure detection and prevention focus on preventing failures due to object slip or external disturbances. However, there is a lack of datasets and evaluation methods that consider unpreventable failures caused by the human participant. To address this deficit, we present the multimodal Handover Failure Detection dataset, which consists of failures induced by the human participant, such as ignoring the robot or not releasing the object. We also present two baseline methods for handover failure detection: (i) a video classification method using 3D CNNs and (ii) a temporal action segmentation approach which jointly classifies the human action, robot action and overall outcome of the action. The results show that video is an important modality, but using force-torque data and gripper position help improve failure detection and action segmentation accuracy.
b-it-bots RoboCup@Work Team Description Paper 2023
Dec 29, 2023This paper presents the b-it-bots RoboCup@Work team and its current hardware and functional architecture for the KUKA youBot robot. We describe the underlying software framework and the developed capabilities required for operating in industrial environments including features such as reliable and precise navigation, flexible manipulation, robust object recognition and task planning. New developments include an approach to grasp vertical objects, placement of objects by considering the empty space on a workstation, and the process of porting our code to ROS2.
Deploying Robots in Everyday Environments: Towards Dependable and Practical Robotic Systems
Jun 25, 2022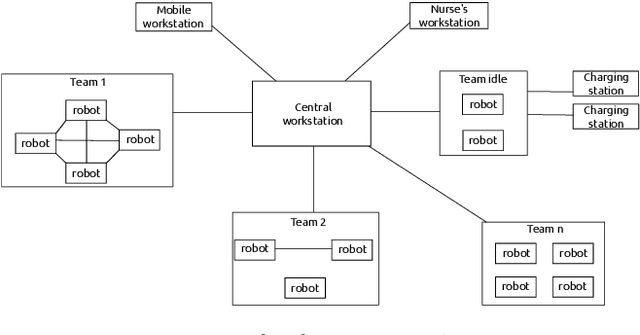
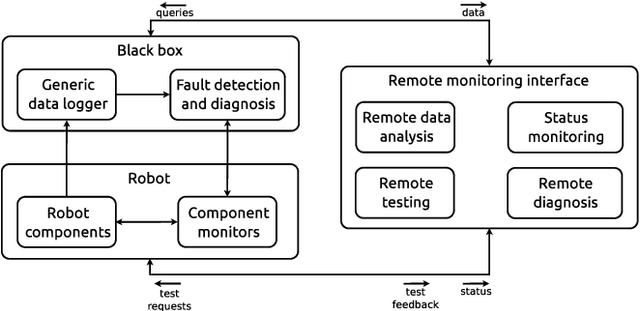
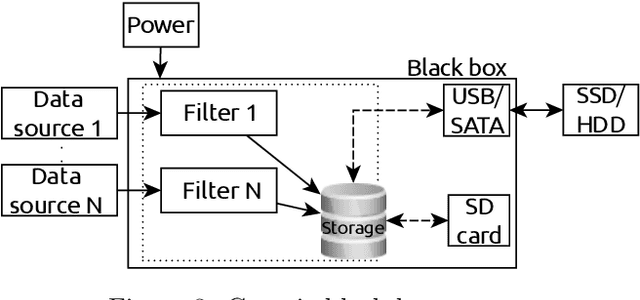
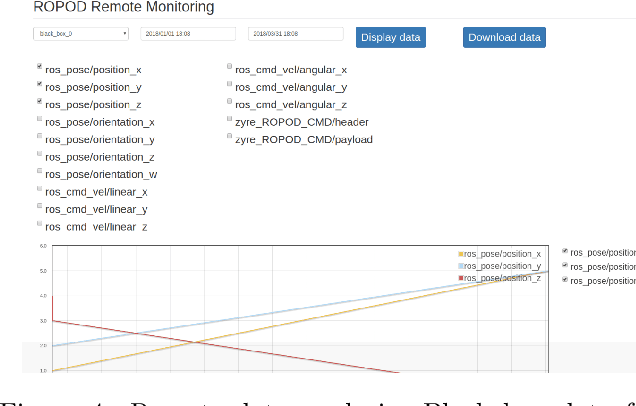
Robot deployment in realistic dynamic environments is a challenging problem despite the fact that robots can be quite skilled at a large number of isolated tasks. One reason for this is that robots are rarely equipped with powerful introspection capabilities, which means that they cannot always deal with failures in a reasonable manner; in addition, manual diagnosis is often a tedious task that requires technicians to have a considerable set of robotics skills. In this paper, we discuss our ongoing efforts - in the context of the ROPOD project - to address some of these problems. In particular, we (i) present our early efforts at developing a robotic black box and consider some factors that complicate its design, (ii) explain our component and system monitoring concept, and (iii) describe the necessity for remote monitoring and experimentation as well as our initial attempts at performing those. Our preliminary work opens a range of promising directions for making robots more usable and reliable in practice - not only in the context of ROPOD, but in a more general sense as well.
Using Visual Anomaly Detection for Task Execution Monitoring
Jul 29, 2021
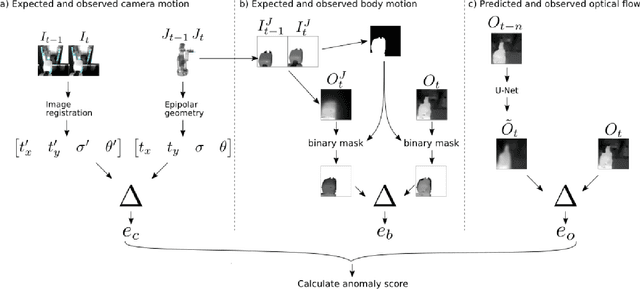

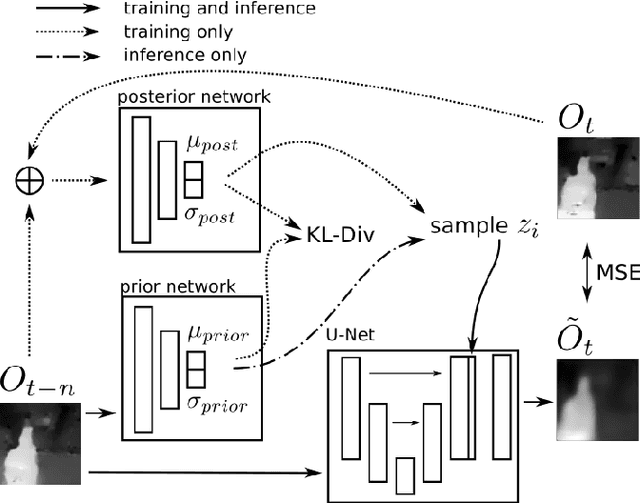
Execution monitoring is essential for robots to detect and respond to failures. Since it is impossible to enumerate all failures for a given task, we learn from successful executions of the task to detect visual anomalies during runtime. Our method learns to predict the motions that occur during the nominal execution of a task, including camera and robot body motion. A probabilistic U-Net architecture is used to learn to predict optical flow, and the robot's kinematics and 3D model are used to model camera and body motion. The errors between the observed and predicted motion are used to calculate an anomaly score. We evaluate our method on a dataset of a robot placing a book on a shelf, which includes anomalies such as falling books, camera occlusions, and robot disturbances. We find that modeling camera and body motion, in addition to the learning-based optical flow prediction, results in an improvement of the area under the receiver operating characteristic curve from 0.752 to 0.804, and the area under the precision-recall curve from 0.467 to 0.549.