 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVolumetric Instance-Aware Semantic Mapping and 3D Object Discovery
Mar 01, 2019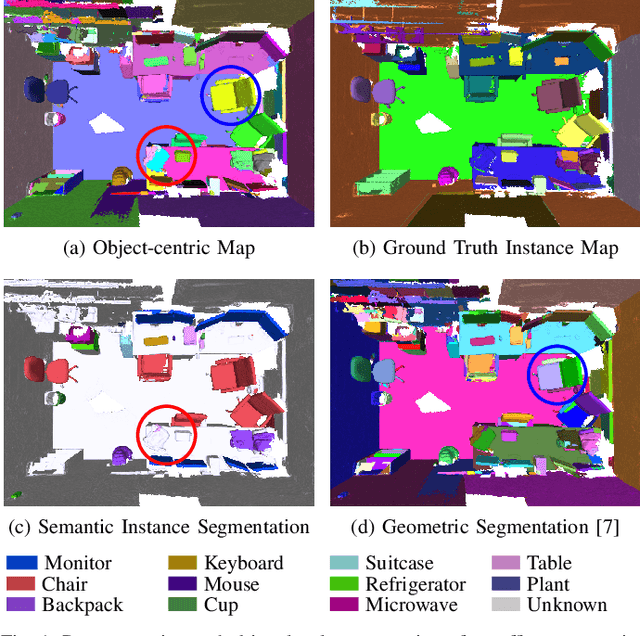
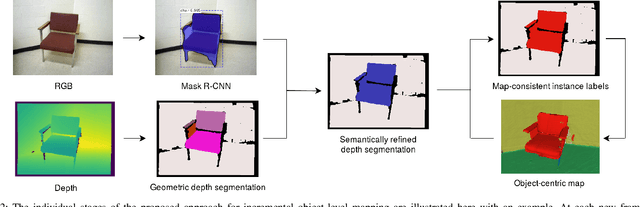


To autonomously navigate and plan interactions in real-world environments, robots require the ability to robustly perceive and map complex, unstructured surrounding scenes. Besides building an internal representation of the observed scene geometry, the key insight towards a truly functional understanding of the environment is the usage of higher-level entities during mapping, such as individual object instances. We propose an approach to incrementally build volumetric object-centric maps during online scanning with a localized RGB-D camera. First, a per-frame segmentation scheme combines an unsupervised geometric approach with instance-aware semantic object predictions. This allows us to detect and segment elements both from the set of known classes and from other, previously unseen categories. Next, a data association step tracks the predicted instances across the different frames. Finally, a map integration strategy fuses information about their 3D shape, location, and, if available, semantic class into a global volume. Evaluation on a publicly available dataset shows that the proposed approach for building instance-level semantic maps is competitive with state-of-the-art methods, while additionally able to discover objects of unseen categories. The system is further evaluated within a real-world robotic mapping setup, for which qualitative results highlight the online nature of the method.
Informative Path Planning and Mapping for Active Sensing Under Localization Uncertainty
Feb 25, 2019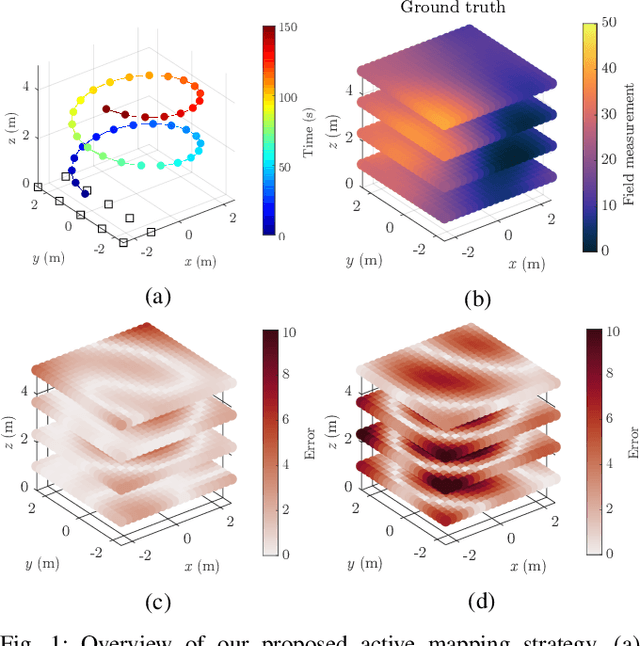
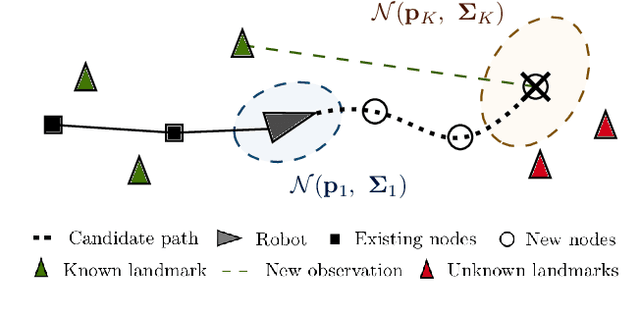
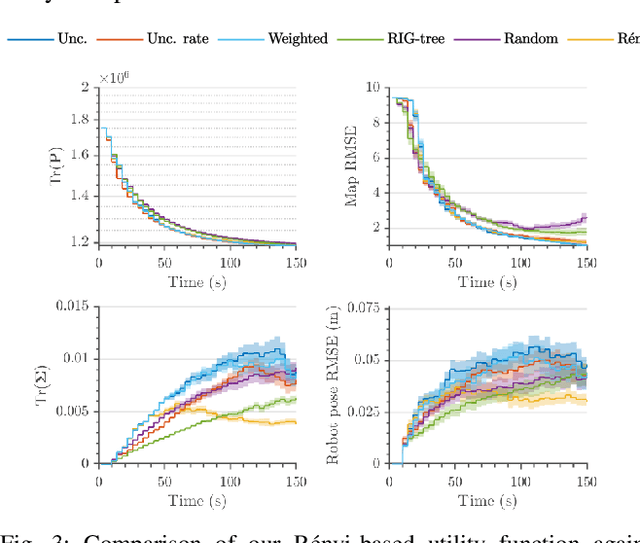
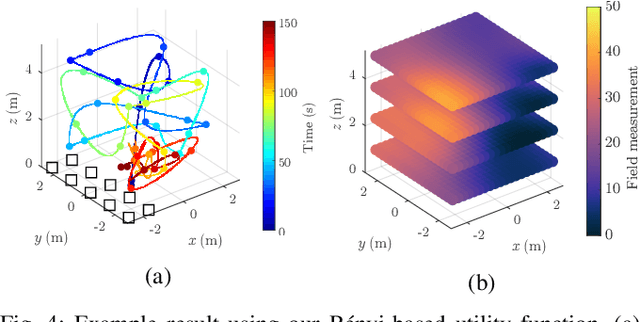
Robotic platforms are emerging as a timely and cost-efficient tool for exploration and monitoring. However, an open challenge is planning missions for robust, efficient data acquisition in complex environments. To address this issue, we introduce an informative planning framework for active sensing scenarios that accounts for the robot pose uncertainty. Our strategy exploits a Gaussian Process model to capture a target environmental field given the uncertainty on its inputs. This allows us to maintain robust maps, which are used for planning information-rich trajectories in continuous space. A key aspect of our method is a new utility function that couples the localization and field mapping objectives, enabling us to trade-off exploration against exploitation in a principled way. Extensive simulations show that our approach outperforms existing strategies, with reductions of up to 45.1% and 6.3% in mean pose uncertainty and map error. We demonstrate a proof of concept in an indoor temperature mapping scenario.
VIZARD: Reliable Visual Localization for Autonomous Vehicles in Urban Outdoor Environments
Feb 12, 2019
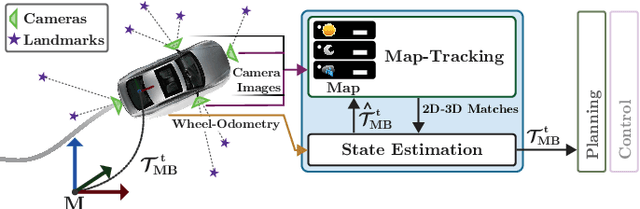
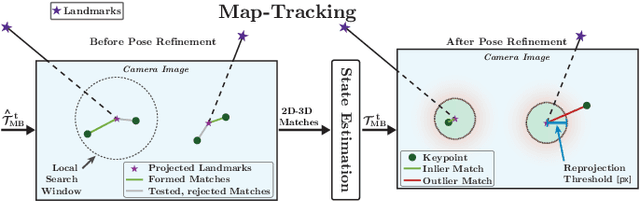
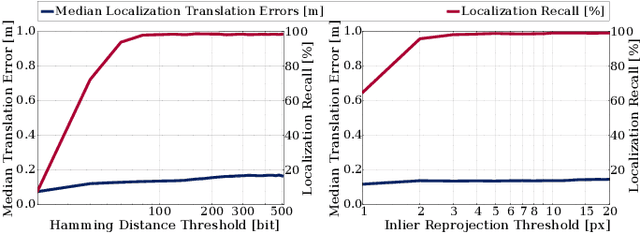
Changes in appearance is one of the main sources of failure in visual localization systems in outdoor environments. To address this challenge, we present VIZARD, a visual localization system for urban outdoor environments. By combining a local localization algorithm with the use of multi-session maps, a high localization recall can be achieved across vastly different appearance conditions. The fusion of the visual localization constraints with wheel-odometry in a state estimation framework further guarantees smooth and accurate pose estimates. In an extensive experimental evaluation on several hundreds of driving kilometers in challenging urban outdoor environments, we analyze the recall and accuracy of our localization system, investigate its key parameters and boundary conditions, and compare different types of feature descriptors. Our results show that VIZARD is able to achieve nearly 100% recall with a localization accuracy below 0.5m under varying outdoor appearance conditions, including at night-time.
Comparing Task Simplifications to Learn Closed-Loop Object Picking Using Deep Reinforcement Learning
Jan 31, 2019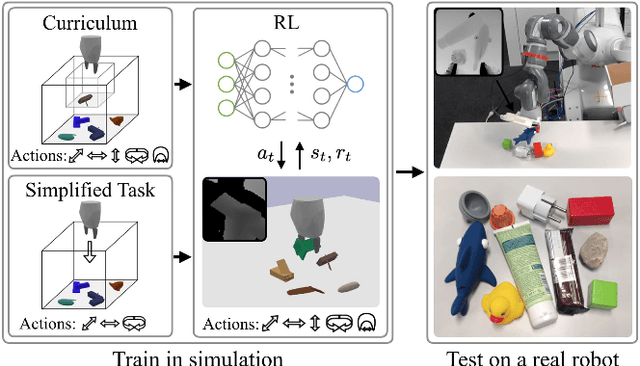
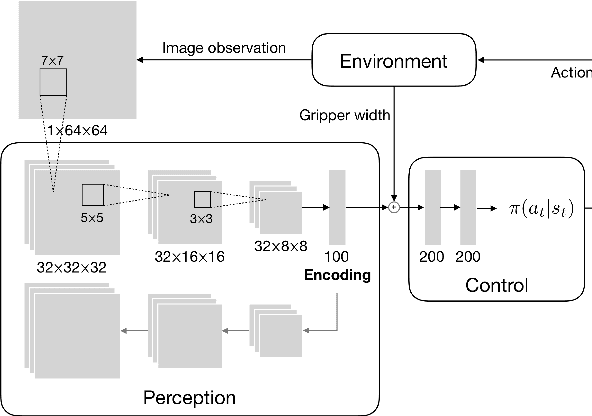

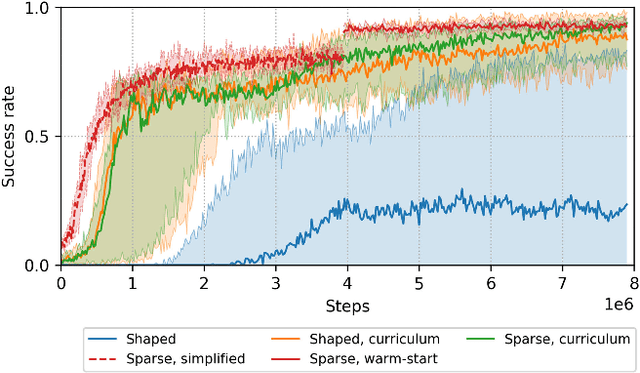
Enabling autonomous robots to interact in unstructured environments with dynamic objects requires manipulation capabilities that can deal with clutter, changes, and objects' variability. This paper presents a comparison of different reinforcement learning-based approaches for object picking with a robotic manipulator. We learn closed-loop policies mapping depth camera inputs to motion commands and compare different approaches to keep the problem tractable, including reward shaping, curriculum learning and using a policy pre-trained on a task with a reduced action set to warm-start the full problem. For efficient and more flexible data collection, we train in simulation and transfer the policies to a real robot. We show that using curriculum learning, policies learned with a sparse reward formulation can be trained at similar rates as with a shaped reward. These policies result in success rates comparable to the policy initialized on the simplified task. We could successfully transfer these policies to the real robot with only minor modifications of the depth image filtering. We found that using a heuristic to warm-start the training was useful to enforce desired behavior, while the policies trained from scratch using a curriculum learned better to cope with unseen scenarios where objects are removed.
Observability-aware Self-Calibration of Visual and Inertial Sensors for Ego-Motion Estimation
Jan 22, 2019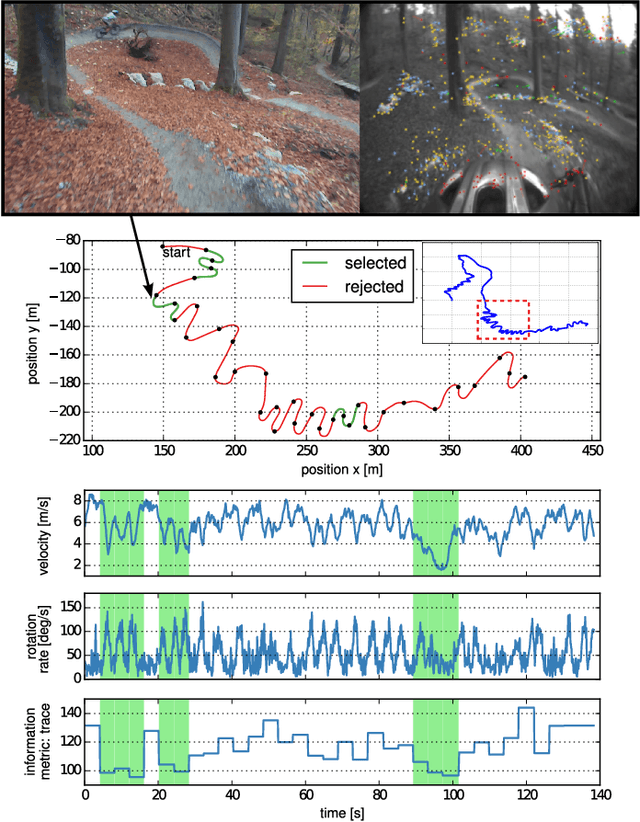
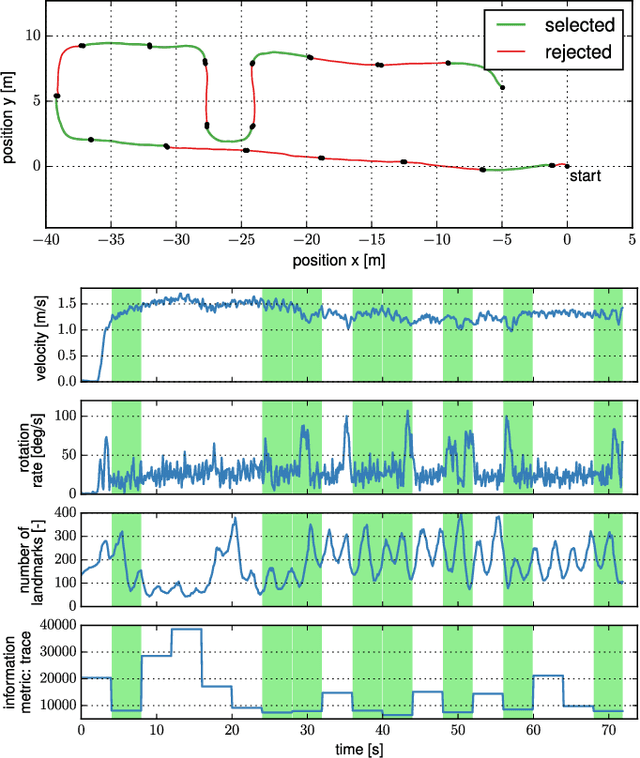
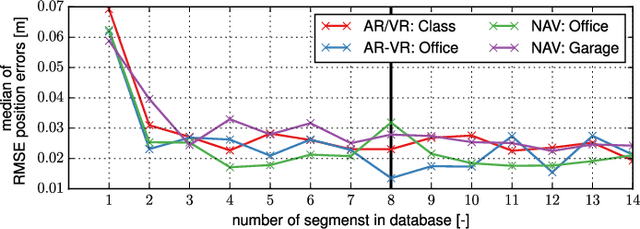
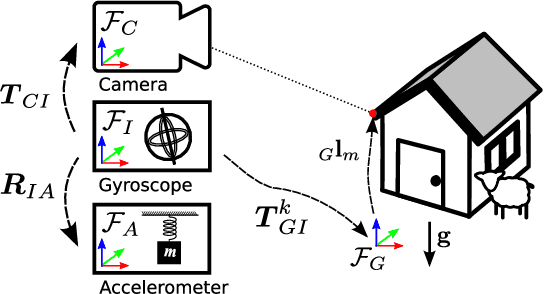
External effects such as shocks and temperature variations affect the calibration of visual-inertial sensor systems and thus they cannot fully rely on factory calibrations. Re-calibrations performed on short user-collected datasets might yield poor performance since the observability of certain parameters is highly dependent on the motion. Additionally, on resource-constrained systems (e.g mobile phones), full-batch approaches over longer sessions quickly become prohibitively expensive. In this paper, we approach the self-calibration problem by introducing information theoretic metrics to assess the information content of trajectory segments, thus allowing to select the most informative parts from a dataset for calibration purposes. With this approach, we are able to build compact calibration datasets either: (a) by selecting segments from a long session with limited exciting motion or (b) from multiple short sessions where a single sessions does not necessarily excite all modes sufficiently. Real-world experiments in four different environments show that the proposed method achieves comparable performance to a batch calibration approach, yet, at a constant computational complexity which is independent of the duration of the session.
SegMatch: Segment based loop-closure for 3D point clouds
Jan 15, 2019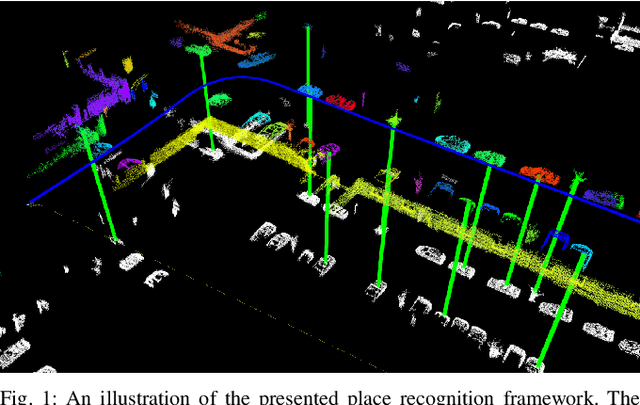
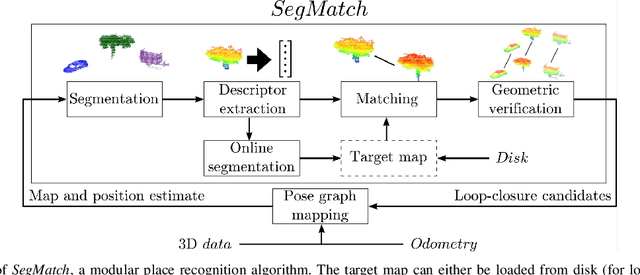
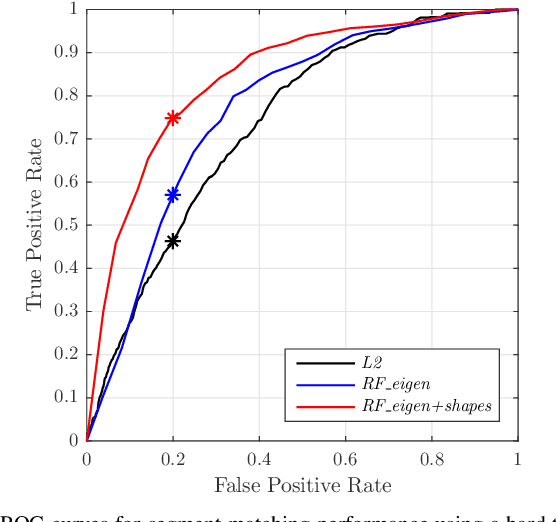
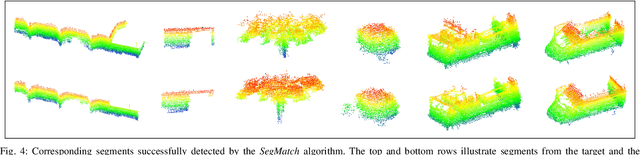
Loop-closure detection on 3D data is a challenging task that has been commonly approached by adapting image-based solutions. Methods based on local features suffer from ambiguity and from robustness to environment changes while methods based on global features are viewpoint dependent. We propose SegMatch, a reliable loop-closure detection algorithm based on the matching of 3D segments. Segments provide a good compromise between local and global descriptions, incorporating their strengths while reducing their individual drawbacks. SegMatch does not rely on assumptions of "perfect segmentation", or on the existence of "objects" in the environment, which allows for reliable execution on large scale, unstructured environments. We quantitatively demonstrate that SegMatch can achieve accurate localization at a frequency of 1Hz on the largest sequence of the KITTI odometry dataset. We furthermore show how this algorithm can reliably detect and close loops in real-time, during online operation. In addition, the source code for the SegMatch algorithm will be made available after publication.
SegMap: 3D Segment Mapping using Data-Driven Descriptors
Jan 15, 2019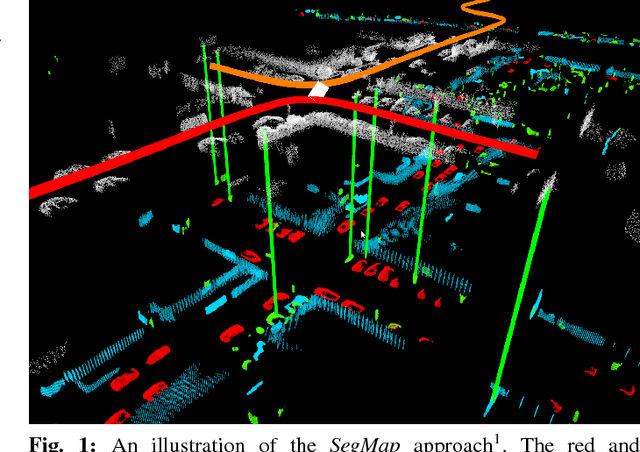
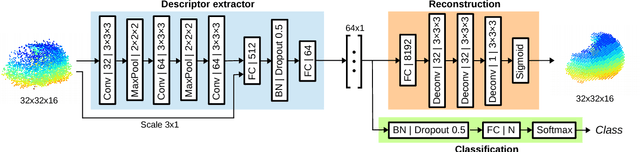
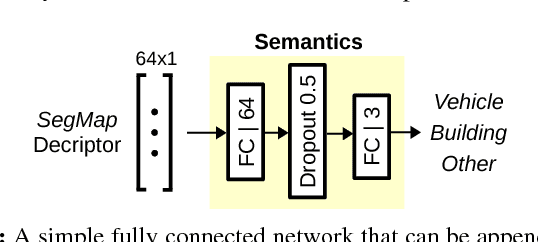

When performing localization and mapping, working at the level of structure can be advantageous in terms of robustness to environmental changes and differences in illumination. This paper presents SegMap: a map representation solution to the localization and mapping problem based on the extraction of segments in 3D point clouds. In addition to facilitating the computationally intensive task of processing 3D point clouds, working at the level of segments addresses the data compression requirements of real-time single- and multi-robot systems. While current methods extract descriptors for the single task of localization, SegMap leverages a data-driven descriptor in order to extract meaningful features that can also be used for reconstructing a dense 3D map of the environment and for extracting semantic information. This is particularly interesting for navigation tasks and for providing visual feedback to end-users such as robot operators, for example in search and rescue scenarios. These capabilities are demonstrated in multiple urban driving and search and rescue experiments. Our method leads to an increase of area under the ROC curve of 28.3% over current state of the art using eigenvalue based features. We also obtain very similar reconstruction capabilities to a model specifically trained for this task. The SegMap implementation will be made available open-source along with easy to run demonstrations at www.github.com/ethz-asl/segmap. A video demonstration is available at https://youtu.be/CMk4w4eRobg.
A Complete System for Vision-Based Micro-Aerial Vehicle Mapping, Planning, and Flight in Cluttered Environments
Dec 10, 2018

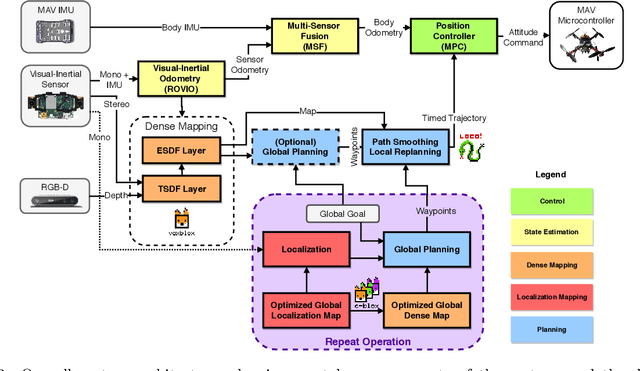

We present a complete system for micro-aerial vehicle autonomous navigation from vision-based sensing. We focus specifically on mapping using only on-board sensing and processing, and how this map information is best exploited for planning, especially when using narrow field of view sensors in very cluttered environments. In addition, details about other necessary parts of the system and special considerations are presented. We compare multiple global planning and path smoothing methods on real maps made in realistic search and rescue and industrial inspection scenarios.
From Perception to Decision: A Data-driven Approach to End-to-end Motion Planning for Autonomous Ground Robots
Nov 06, 2018
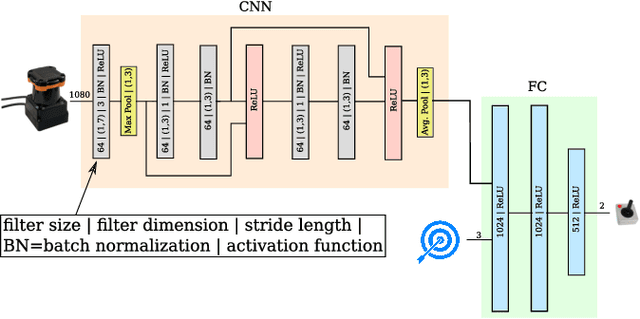

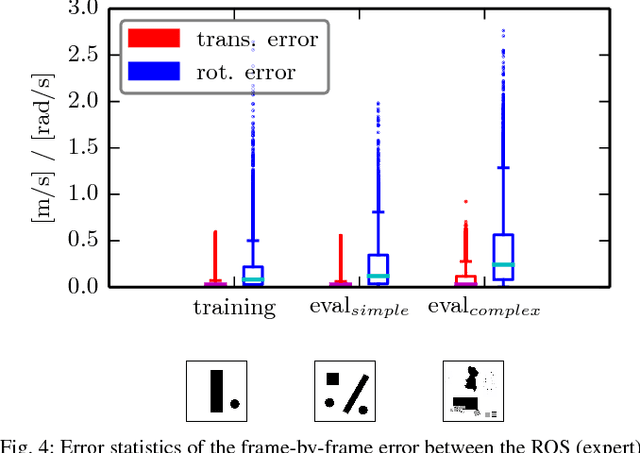
Learning from demonstration for motion planning is an ongoing research topic. In this paper we present a model that is able to learn the complex mapping from raw 2D-laser range findings and a target position to the required steering commands for the robot. To our best knowledge, this work presents the first approach that learns a target-oriented end-to-end navigation model for a robotic platform. The supervised model training is based on expert demonstrations generated in simulation with an existing motion planner. We demonstrate that the learned navigation model is directly transferable to previously unseen virtual and, more interestingly, real-world environments. It can safely navigate the robot through obstacle-cluttered environments to reach the provided targets. We present an extensive qualitative and quantitative evaluation of the neural network-based motion planner, and compare it to a grid-based global approach, both in simulation and in real-world experiments.
C-blox: A Scalable and Consistent TSDF-based Dense Mapping Approach
Sep 25, 2018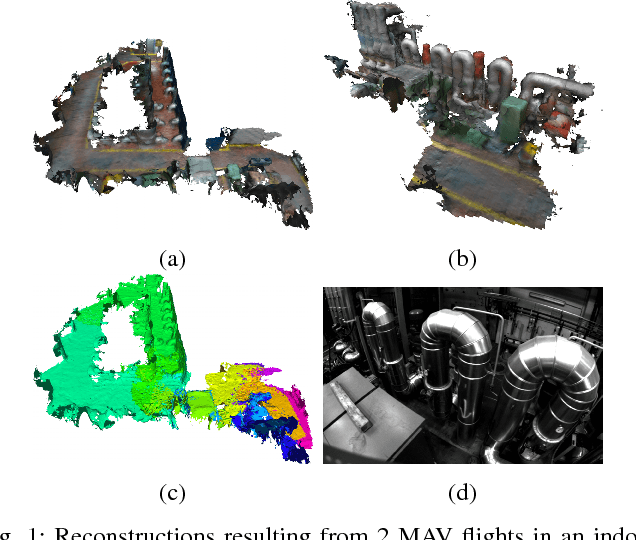
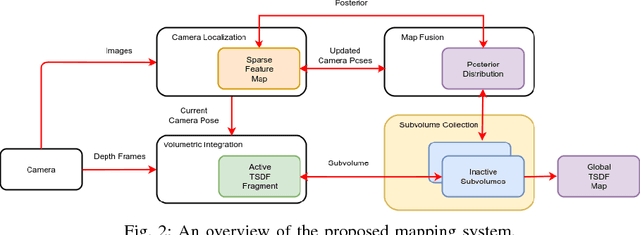


In many applications, maintaining a consistent dense map of the environment is key to enabling robotic platforms to perform higher level decision making. Several works have addressed the challenge of creating precise dense 3D maps from visual sensors providing depth information. However, during operation over longer missions, reconstructions can easily become inconsistent due to accumulated camera tracking error and delayed loop closure. Without explicitly addressing the problem of map consistency, recovery from such distortions tends to be difficult. We present a novel system for dense 3D mapping which addresses the challenge of building consistent maps while dealing with scalability. Central to our approach is the representation of the environment as a collection of overlapping TSDF subvolumes. These subvolumes are localized through feature-based camera tracking and bundle adjustment. Our main contribution is a pipeline for identifying stable regions in the map, and to fuse the contributing subvolumes. This approach allows us to reduce map growth while still maintaining consistency. We demonstrate the proposed system on a publicly available dataset and simulation engine, and demonstrate the efficacy of the proposed approach for building consistent and scalable maps. Finally we demonstrate our approach running in real-time on-board a lightweight MAV.