 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Attack Vulnerability of Medical Image Analysis Systems: Unexplored Factors
Jun 12, 2020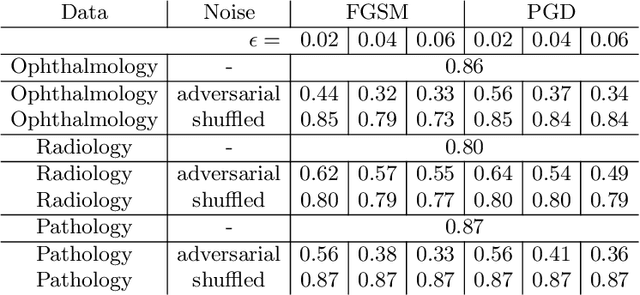
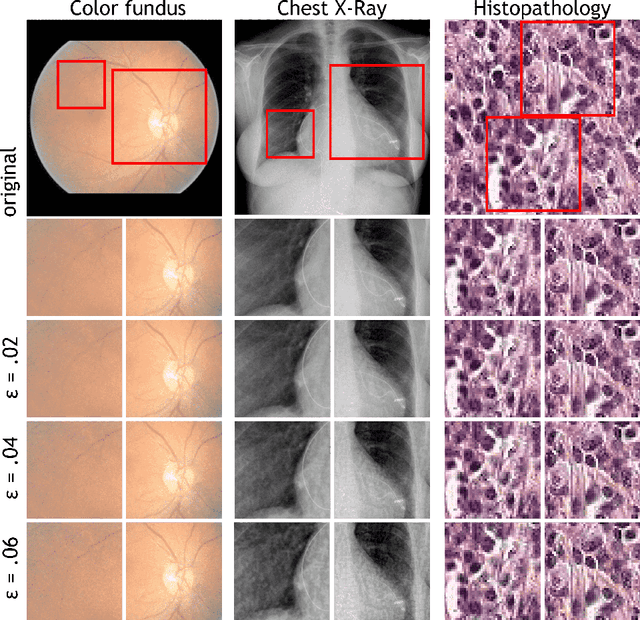
Adversarial attacks are considered a potentially serious security threat for machine learning systems. Medical image analysis (MedIA) systems have recently been argued to be particularly vulnerable to adversarial attacks due to strong financial incentives. In this paper, we study several previously unexplored factors affecting adversarial attack vulnerability of deep learning MedIA systems in three medical domains: ophthalmology, radiology and pathology. Firstly, we study the effect of varying the degree of adversarial perturbation on the attack performance and its visual perceptibility. Secondly, we study how pre-training on a public dataset (ImageNet) affects the models' vulnerability to attacks. Thirdly, we study the influence of data and model architecture disparity between target and attacker models. Our experiments show that the degree of perturbation significantly affects both performance and human perceptibility of attacks. Pre-training may dramatically increase the transfer of adversarial examples; the larger the performance gain achieved by pre-training, the larger the transfer. Finally, disparity in data and/or model architecture between target and attacker models substantially decreases the success of attacks. We believe that these factors should be considered when designing cybersecurity-critical MedIA systems, as well as kept in mind when evaluating their vulnerability to adversarial attacks.
Quantifying Graft Detachment after Descemet's Membrane Endothelial Keratoplasty with Deep Convolutional Neural Networks
Apr 24, 2020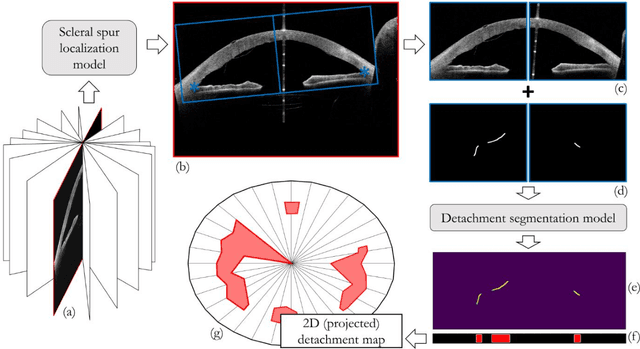
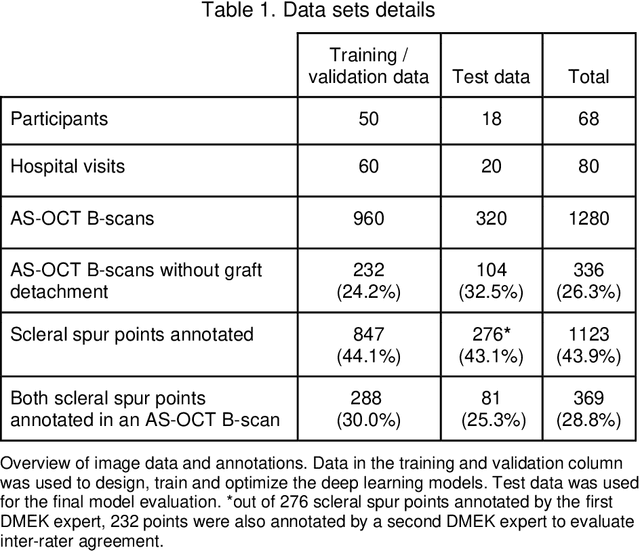
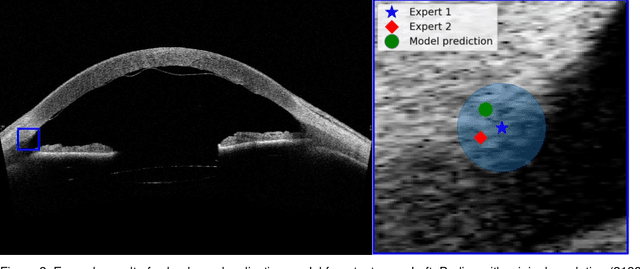
Purpose: We developed a method to automatically locate and quantify graft detachment after Descemet's Membrane Endothelial Keratoplasty (DMEK) in Anterior Segment Optical Coherence Tomography (AS-OCT) scans. Methods: 1280 AS-OCT B-scans were annotated by a DMEK expert. Using the annotations, a deep learning pipeline was developed to localize scleral spur, center the AS-OCT B-scans and segment the detached graft sections. Detachment segmentation model performance was evaluated per B-scan by comparing (1) length of detachment and (2) horizontal projection of the detached sections with the expert annotations. Horizontal projections were used to construct graft detachment maps. All final evaluations were done on a test set that was set apart during training of the models. A second DMEK expert annotated the test set to determine inter-rater performance. Results: Mean scleral spur localization error was 0.155 mm, whereas the inter-rater difference was 0.090 mm. The estimated graft detachment lengths were in 69% of the cases within a 10-pixel (~150{\mu}m) difference from the ground truth (77% for the second DMEK expert). Dice scores for the horizontal projections of all B-scans with detachments were 0.896 and 0.880 for our model and the second DMEK expert respectively. Conclusion: Our deep learning model can be used to automatically and instantly localize graft detachment in AS-OCT B-scans. Horizontal detachment projections can be determined with the same accuracy as a human DMEK expert, allowing for the construction of accurate graft detachment maps. Translational Relevance: Automated localization and quantification of graft detachment can support DMEK research and standardize clinical decision making.
clDice -- a Topology-Preserving Loss Function for Tubular Structure Segmentation
Mar 29, 2020

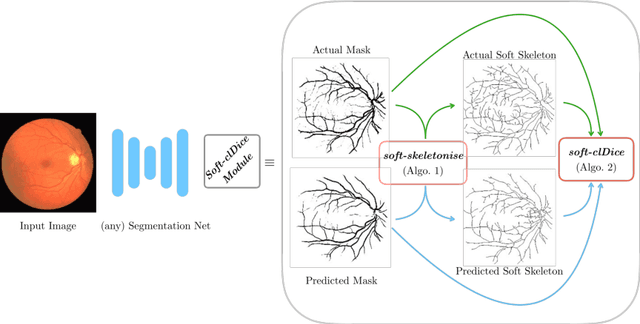
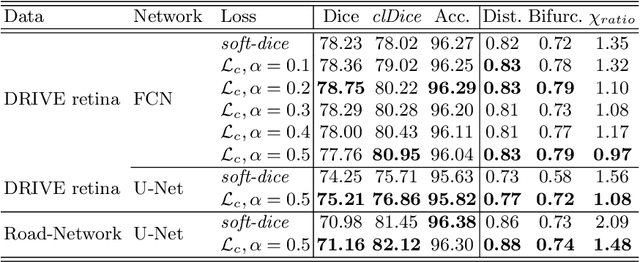
Accurate segmentation of tubular, network-like structures, such as vessels, neurons, or roads, is relevant to many fields of research. For such structures, the topology is their most important characteristic, e.g. preserving connectedness: in case of vascular networks, missing a connected vessel entirely alters the blood-flow dynamics. We introduce a novel similarity measure termed clDice, which is calculated on the intersection of the segmentation masks and their (morphological) skeletons. Crucially, we theoretically prove that clDice guarantees topological correctness for binary 2D and 3D segmentation. Extending this, we propose a computationally efficient, differentiable soft-clDice as a loss function for training arbitrary neural segmentation networks. We benchmark the soft-clDice loss for segmentation on four public datasets (2D and 3D). Training on soft-clDice leads to segmentation with more accurate connectivity information, higher graph similarity, and better volumetric scores.
Roto-Translation Equivariant Convolutional Networks: Application to Histopathology Image Analysis
Feb 20, 2020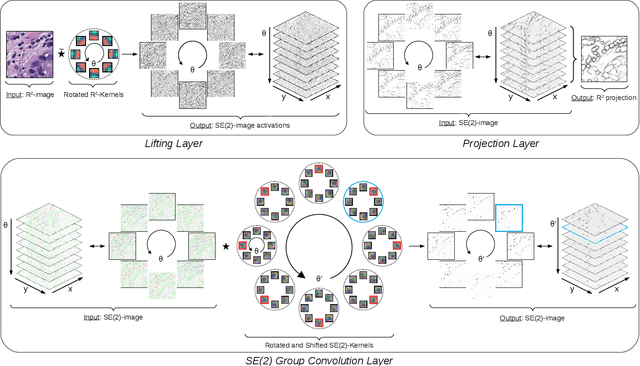
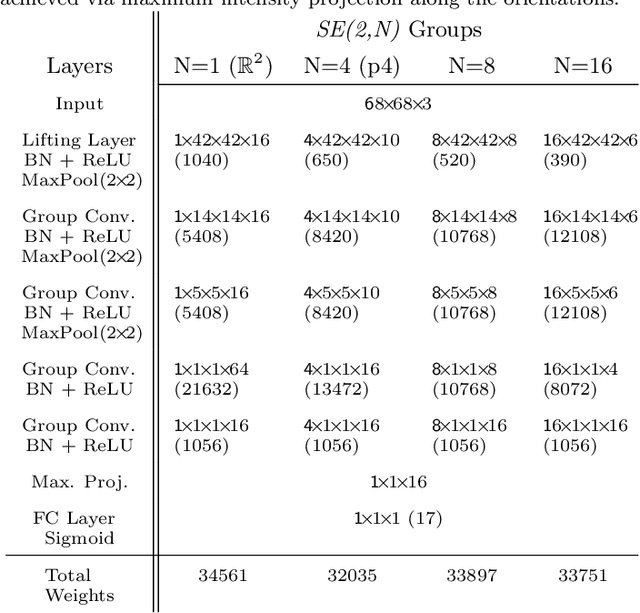
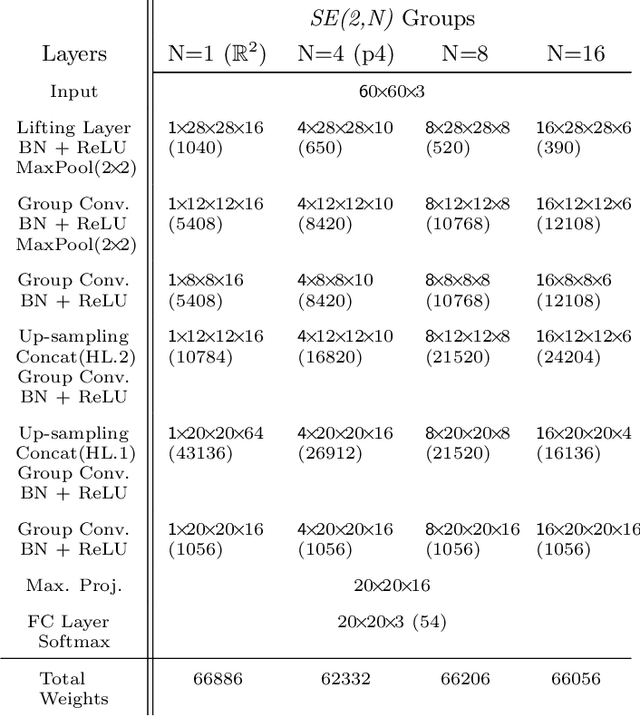

Rotation-invariance is a desired property of machine-learning models for medical image analysis and in particular for computational pathology applications. We propose a framework to encode the geometric structure of the special Euclidean motion group SE(2) in convolutional networks to yield translation and rotation equivariance via the introduction of SE(2)-group convolution layers. This structure enables models to learn feature representations with a discretized orientation dimension that guarantees that their outputs are invariant under a discrete set of rotations. Conventional approaches for rotation invariance rely mostly on data augmentation, but this does not guarantee the robustness of the output when the input is rotated. At that, trained conventional CNNs may require test-time rotation augmentation to reach their full capability. This study is focused on histopathology image analysis applications for which it is desirable that the arbitrary global orientation information of the imaged tissues is not captured by the machine learning models. The proposed framework is evaluated on three different histopathology image analysis tasks (mitosis detection, nuclei segmentation and tumor classification). We present a comparative analysis for each problem and show that consistent increase of performances can be achieved when using the proposed framework.
Direct Classification of Type 2 Diabetes From Retinal Fundus Images in a Population-based Sample From The Maastricht Study
Nov 22, 2019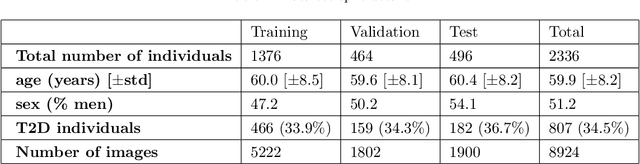
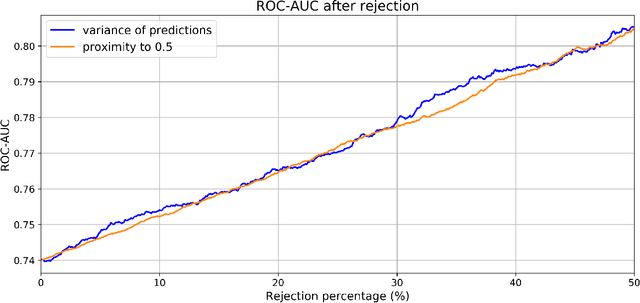
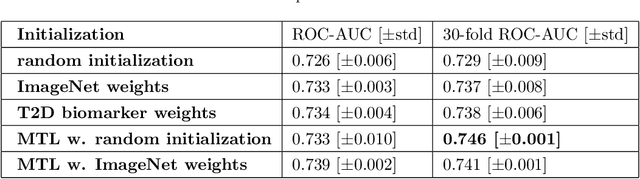

Type 2 Diabetes (T2D) is a chronic metabolic disorder that can lead to blindness and cardiovascular disease. Information about early stage T2D might be present in retinal fundus images, but to what extent these images can be used for a screening setting is still unknown. In this study, deep neural networks were employed to differentiate between fundus images from individuals with and without T2D. We investigated three methods to achieve high classification performance, measured by the area under the receiver operating curve (ROC-AUC). A multi-target learning approach to simultaneously output retinal biomarkers as well as T2D works best (AUC = 0.746 [$\pm$0.001]). Furthermore, the classification performance can be improved when images with high prediction uncertainty are referred to a specialist. We also show that the combination of images of the left and right eye per individual can further improve the classification performance (AUC = 0.758 [$\pm$0.003]), using a simple averaging approach. The results are promising, suggesting the feasibility of screening for T2D from retinal fundus images.
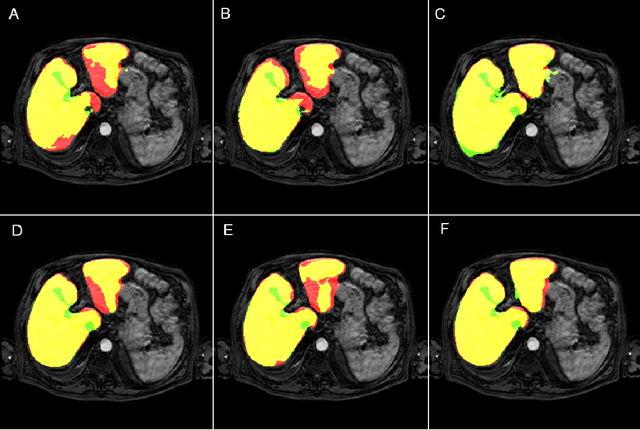
Liver segmentation and metastases detection in MR images using convolutional neural networks
Oct 15, 2019
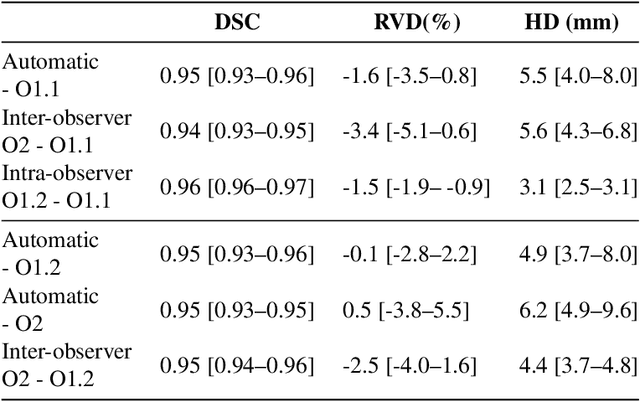
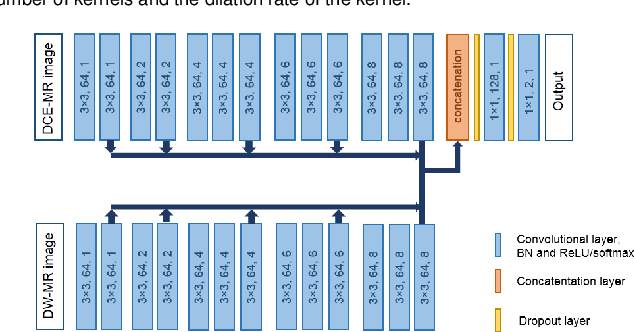
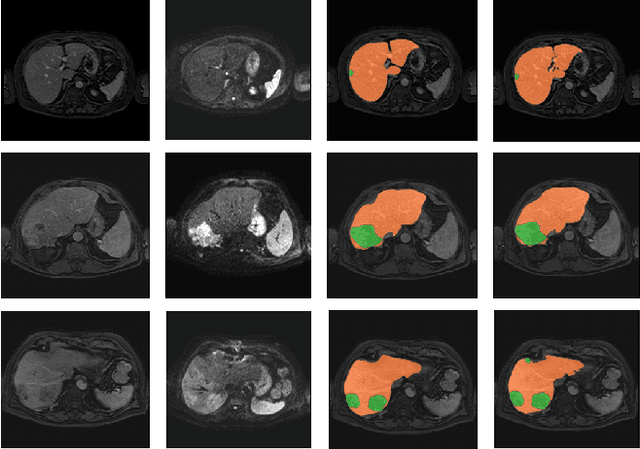
Primary tumors have a high likelihood of developing metastases in the liver and early detection of these metastases is crucial for patient outcome. We propose a method based on convolutional neural networks (CNN) to detect liver metastases. First, the liver was automatically segmented using the six phases of abdominal dynamic contrast enhanced (DCE) MR images. Next, DCE-MR and diffusion weighted (DW) MR images are used for metastases detection within the liver mask. The liver segmentations have a median Dice similarity coefficient of 0.95 compared with manual annotations. The metastases detection method has a sensitivity of 99.8% with a median of 2 false positives per image. The combination of the two MR sequences in a dual pathway network is proven valuable for the detection of liver metastases. In conclusion, a high quality liver segmentation can be obtained in which we can successfully detect liver metastases.
Motion correction of dynamic contrast enhanced MRI of the liver
Aug 22, 2019Motion correction of dynamic contrast enhanced magnetic resonance images (DCE-MRI) is a challenging task, due to changes in image appearance. In this study a groupwise registration, using a principle component analysis (PCA) based metric,1 is evaluated for clinical DCE MRI of the liver. The groupwise registration transforms the images to a common space, rather than to a reference volume as conventional pairwise methods do, and computes the similarity metric on all volumes simultaneously. This groupwise registration method is compared to a pairwise approach using a mutual information metric. Clinical DCE MRI of the abdomen of eight patients were included. Per patient one lesion in the liver was manually segmented in all temporal images (N=16). The registered images were compared for accuracy, spatial and temporal smoothness after transformation, and lesion volume change. Compared to a pairwise method or no registration, groupwise registration provided better alignment. In our recently started clinical study groupwise registered clinical DCE MRI of the abdomen of nine patients were scored by three radiologists. Groupwise registration increased the assessed quality of alignment. The gain in reading time for the radiologist was estimated to vary from no difference to almost a minute. A slight increase in reader confidence was also observed. Registration had no added value for images with little motion. In conclusion, the groupwise registration of DCE MR images results in better alignment than achieved by pairwise registration, which is beneficial for clinical assessment.
Optimal input configuration of dynamic contrast enhanced MRI in convolutional neural networks for liver segmentation
Aug 22, 2019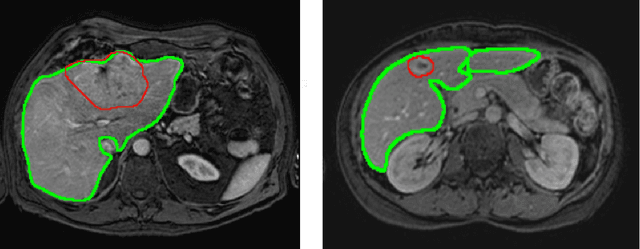
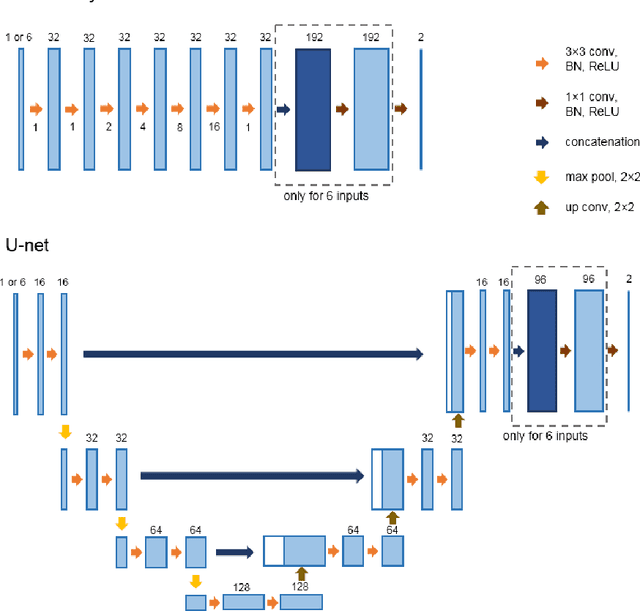
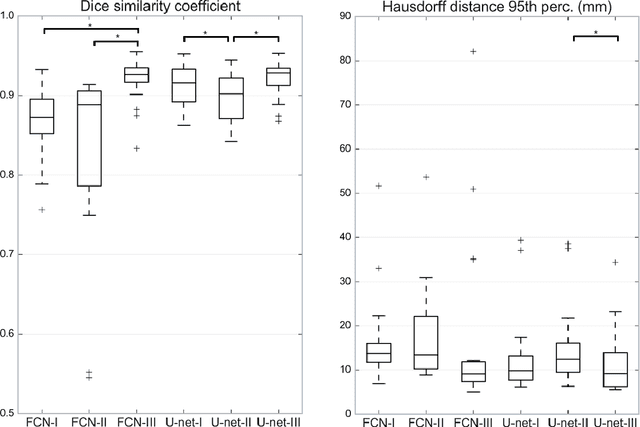
Most MRI liver segmentation methods use a structural 3D scan as input, such as a T1 or T2 weighted scan. Segmentation performance may be improved by utilizing both structural and functional information, as contained in dynamic contrast enhanced (DCE) MR series. Dynamic information can be incorporated in a segmentation method based on convolutional neural networks in a number of ways. In this study, the optimal input configuration of DCE MR images for convolutional neural networks (CNNs) is studied. The performance of three different input configurations for CNNs is studied for a liver segmentation task. The three configurations are I) one phase image of the DCE-MR series as input image; II) the separate phases of the DCE-MR as input images; and III) the separate phases of the DCE-MR as channels of one input image. The three input configurations are fed into a dilated fully convolutional network and into a small U-net. The CNNs were trained using 19 annotated DCE-MR series and tested on another 19 annotated DCE-MR series. The performance of the three input configurations for both networks is evaluated against manual annotations. The results show that both neural networks perform better when the separate phases of the DCE-MR series are used as channels of an input image in comparison to one phase as input image or the separate phases as input images. No significant difference between the performances of the two network architectures was found for the separate phases as channels of an input image.
Not-so-supervised: a survey of semi-supervised, multi-instance, and transfer learning in medical image analysis
Sep 14, 2018
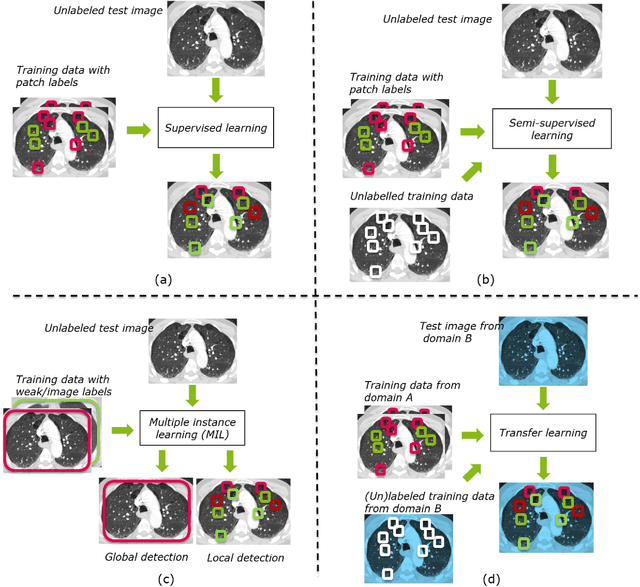

Machine learning (ML) algorithms have made a tremendous impact in the field of medical imaging. While medical imaging datasets have been growing in size, a challenge for supervised ML algorithms that is frequently mentioned is the lack of annotated data. As a result, various methods which can learn with less/other types of supervision, have been proposed. We review semi-supervised, multiple instance, and transfer learning in medical imaging, both in diagnosis/detection or segmentation tasks. We also discuss connections between these learning scenarios, and opportunities for future research.
Crowd disagreement about medical images is informative
Aug 17, 2018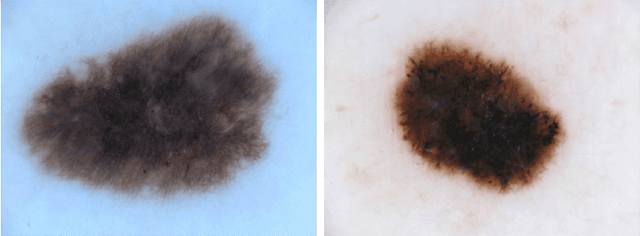
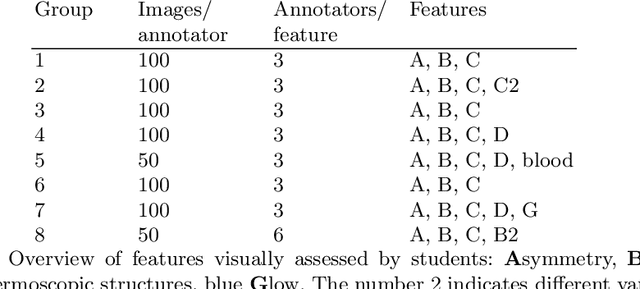
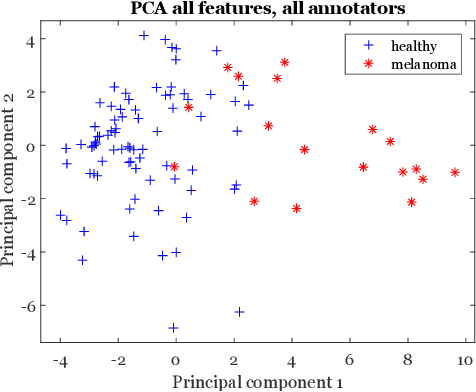
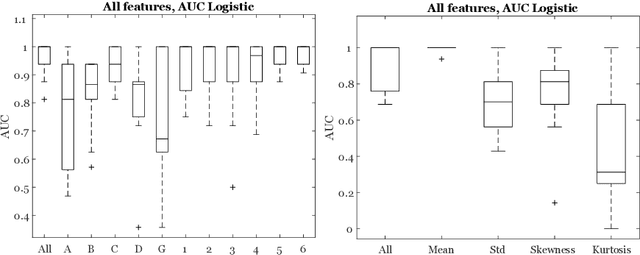
Classifiers for medical image analysis are often trained with a single consensus label, based on combining labels given by experts or crowds. However, disagreement between annotators may be informative, and thus removing it may not be the best strategy. As a proof of concept, we predict whether a skin lesion from the ISIC 2017 dataset is a melanoma or not, based on crowd annotations of visual characteristics of that lesion. We compare using the mean annotations, illustrating consensus, to standard deviations and other distribution moments, illustrating disagreement. We show that the mean annotations perform best, but that the disagreement measures are still informative. We also make the crowd annotations used in this paper available at \url{https://figshare.com/s/5cbbce14647b66286544}.