 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting breast tumor proliferation from whole-slide images: the TUPAC16 challenge
Jul 22, 2018
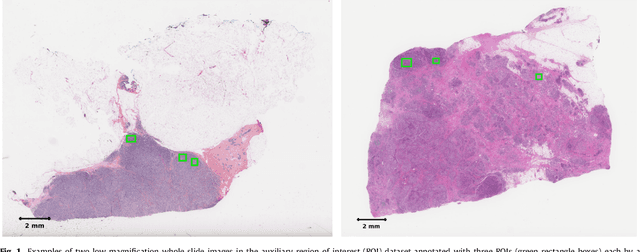
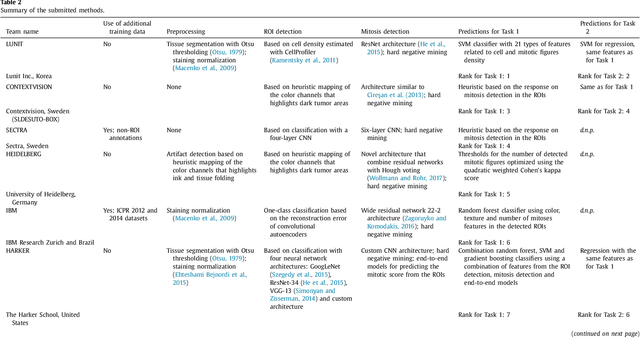
Tumor proliferation is an important biomarker indicative of the prognosis of breast cancer patients. Assessment of tumor proliferation in a clinical setting is highly subjective and labor-intensive task. Previous efforts to automate tumor proliferation assessment by image analysis only focused on mitosis detection in predefined tumor regions. However, in a real-world scenario, automatic mitosis detection should be performed in whole-slide images (WSIs) and an automatic method should be able to produce a tumor proliferation score given a WSI as input. To address this, we organized the TUmor Proliferation Assessment Challenge 2016 (TUPAC16) on prediction of tumor proliferation scores from WSIs. The challenge dataset consisted of 500 training and 321 testing breast cancer histopathology WSIs. In order to ensure fair and independent evaluation, only the ground truth for the training dataset was provided to the challenge participants. The first task of the challenge was to predict mitotic scores, i.e., to reproduce the manual method of assessing tumor proliferation by a pathologist. The second task was to predict the gene expression based PAM50 proliferation scores from the WSI. The best performing automatic method for the first task achieved a quadratic-weighted Cohen's kappa score of $\kappa$ = 0.567, 95% CI [0.464, 0.671] between the predicted scores and the ground truth. For the second task, the predictions of the top method had a Spearman's correlation coefficient of r = 0.617, 95% CI [0.581 0.651] with the ground truth. This was the first study that investigated tumor proliferation assessment from WSIs. The achieved results are promising given the difficulty of the tasks and weakly-labelled nature of the ground truth. However, further research is needed to improve the practical utility of image analysis methods for this task.
A Unified Framework for Tumor Proliferation Score Prediction in Breast Histopathology
Aug 11, 2017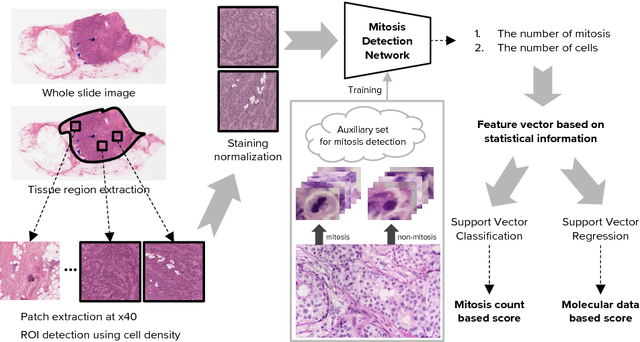
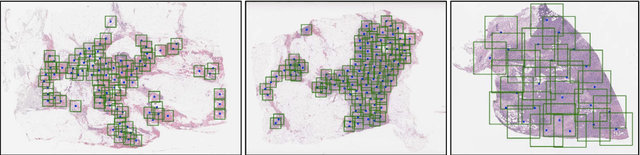

We present a unified framework to predict tumor proliferation scores from breast histopathology whole slide images. Our system offers a fully automated solution to predicting both a molecular data-based, and a mitosis counting-based tumor proliferation score. The framework integrates three modules, each fine-tuned to maximize the overall performance: An image processing component for handling whole slide images, a deep learning based mitosis detection network, and a proliferation scores prediction module. We have achieved 0.567 quadratic weighted Cohen's kappa in mitosis counting-based score prediction and 0.652 F1-score in mitosis detection. On Spearman's correlation coefficient, which evaluates predictive accuracy on the molecular data based score, the system obtained 0.6171. Our approach won first place in all of the three tasks in Tumor Proliferation Assessment Challenge 2016 which is MICCAI grand challenge.
Accurate Lung Segmentation via Network-Wise Training of Convolutional Networks
Aug 02, 2017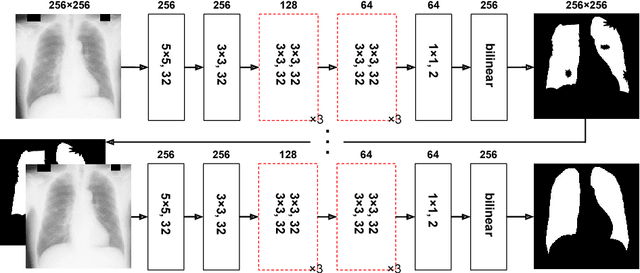
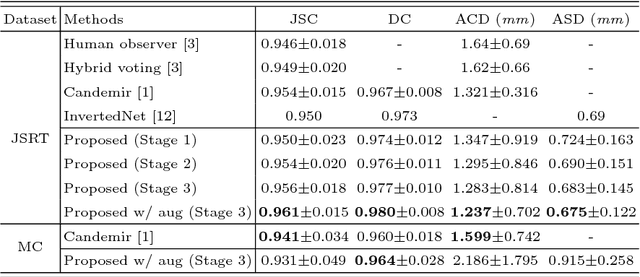
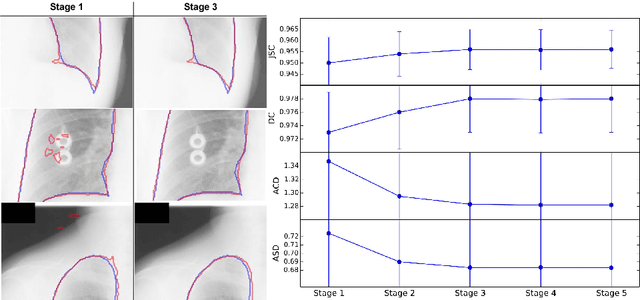
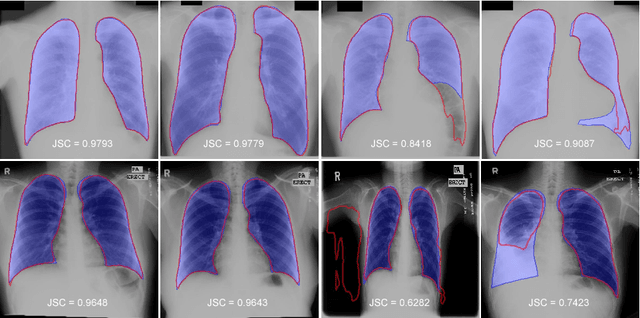
We introduce an accurate lung segmentation model for chest radiographs based on deep convolutional neural networks. Our model is based on atrous convolutional layers to increase the field-of-view of filters efficiently. To improve segmentation performances further, we also propose a multi-stage training strategy, network-wise training, which the current stage network is fed with both input images and the outputs from pre-stage network. It is shown that this strategy has an ability to reduce falsely predicted labels and produce smooth boundaries of lung fields. We evaluate the proposed model on a common benchmark dataset, JSRT, and achieve the state-of-the-art segmentation performances with much fewer model parameters.
Action-Driven Object Detection with Top-Down Visual Attentions
Dec 20, 2016

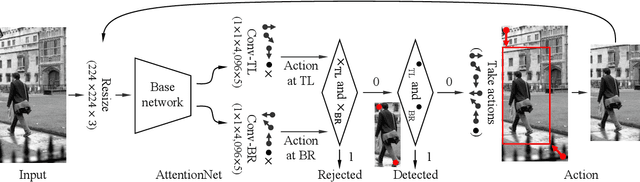
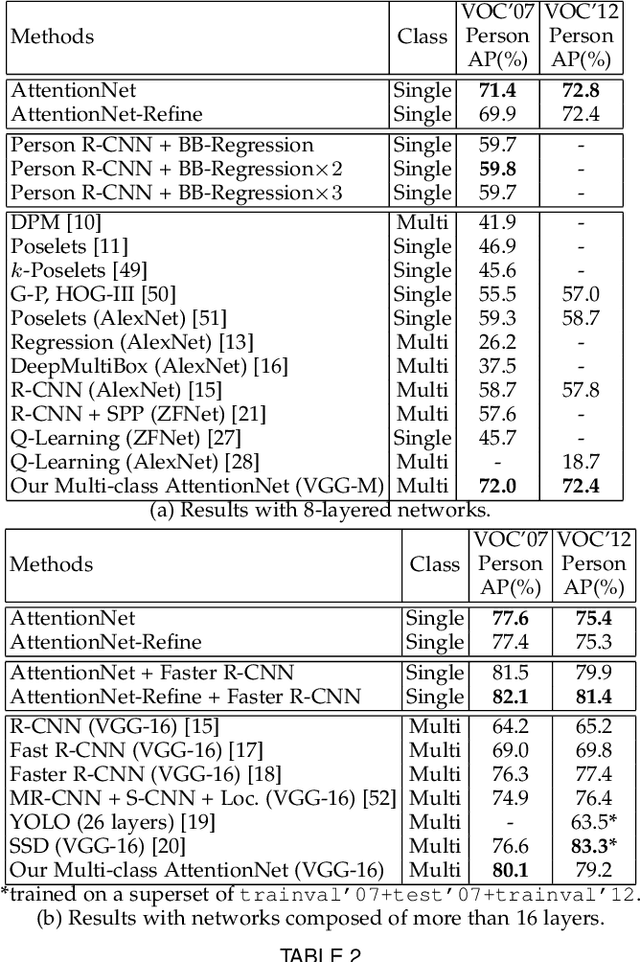
A dominant paradigm for deep learning based object detection relies on a "bottom-up" approach using "passive" scoring of class agnostic proposals. These approaches are efficient but lack of holistic analysis of scene-level context. In this paper, we present an "action-driven" detection mechanism using our "top-down" visual attention model. We localize an object by taking sequential actions that the attention model provides. The attention model conditioned with an image region provides required actions to get closer toward a target object. An action at each time step is weak itself but an ensemble of the sequential actions makes a bounding-box accurately converge to a target object boundary. This attention model we call AttentionNet is composed of a convolutional neural network. During our whole detection procedure, we only utilize the actions from a single AttentionNet without any modules for object proposals nor post bounding-box regression. We evaluate our top-down detection mechanism over the PASCAL VOC series and ILSVRC CLS-LOC dataset, and achieve state-of-the-art performances compared to the major bottom-up detection methods. In particular, our detection mechanism shows a strong advantage in elaborate localization by outperforming Faster R-CNN with a margin of +7.1% over PASCAL VOC 2007 when we increase the IoU threshold for positive detection to 0.7.
Pixel-Level Domain Transfer
Nov 28, 2016
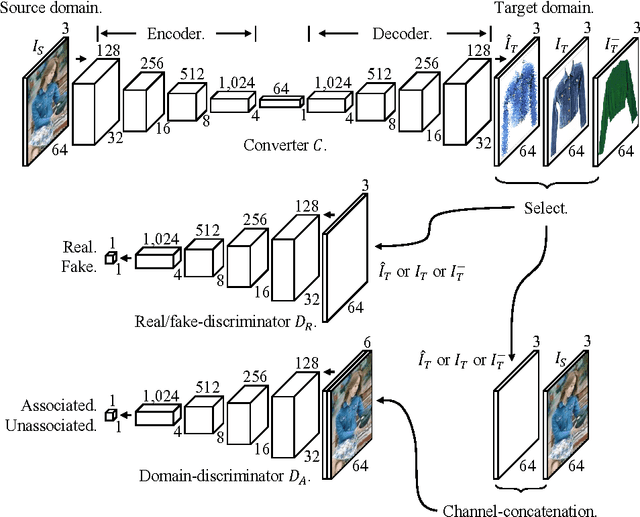

We present an image-conditional image generation model. The model transfers an input domain to a target domain in semantic level, and generates the target image in pixel level. To generate realistic target images, we employ the real/fake-discriminator as in Generative Adversarial Nets, but also introduce a novel domain-discriminator to make the generated image relevant to the input image. We verify our model through a challenging task of generating a piece of clothing from an input image of a dressed person. We present a high quality clothing dataset containing the two domains, and succeed in demonstrating decent results.
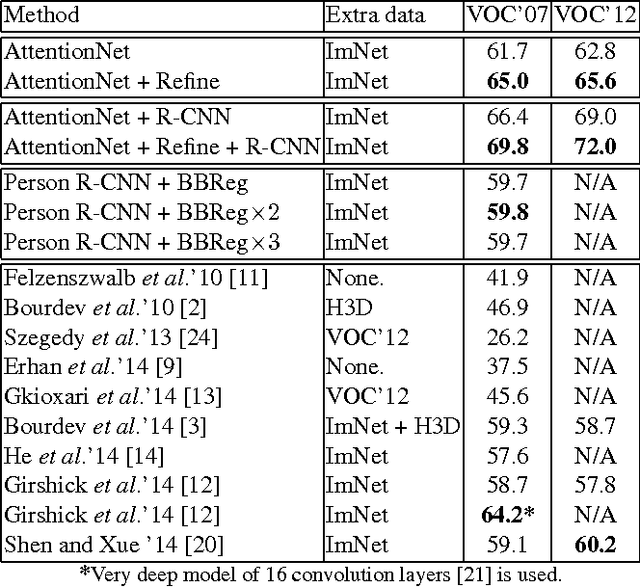
AttentionNet: Aggregating Weak Directions for Accurate Object Detection
Sep 26, 2015
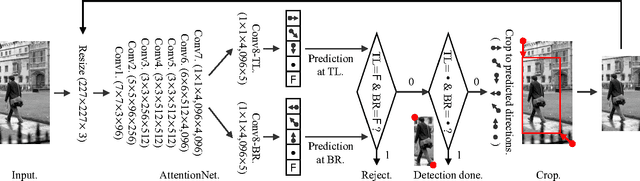
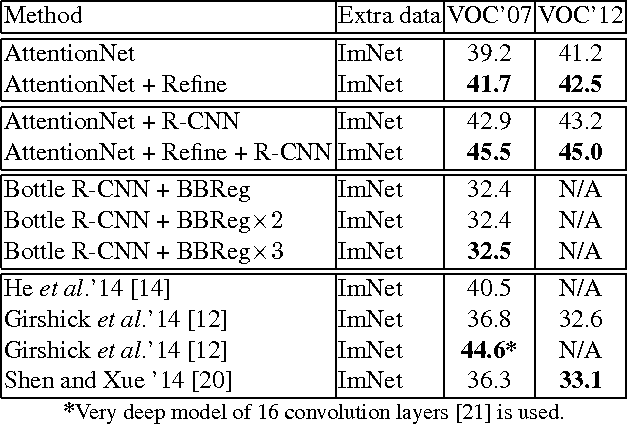
We present a novel detection method using a deep convolutional neural network (CNN), named AttentionNet. We cast an object detection problem as an iterative classification problem, which is the most suitable form of a CNN. AttentionNet provides quantized weak directions pointing a target object and the ensemble of iterative predictions from AttentionNet converges to an accurate object boundary box. Since AttentionNet is a unified network for object detection, it detects objects without any separated models from the object proposal to the post bounding-box regression. We evaluate AttentionNet by a human detection task and achieve the state-of-the-art performance of 65% (AP) on PASCAL VOC 2007/2012 with an 8-layered architecture only.
Fisher Kernel for Deep Neural Activations
Dec 19, 2014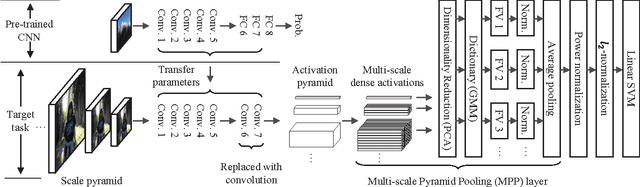
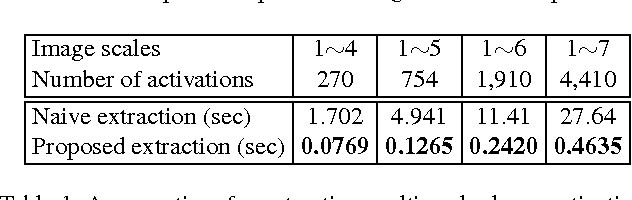
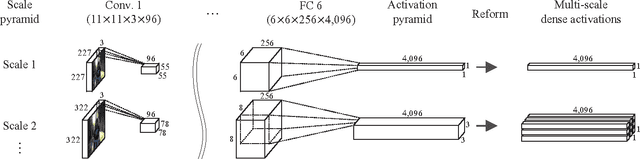

Compared to image representation based on low-level local descriptors, deep neural activations of Convolutional Neural Networks (CNNs) are richer in mid-level representation, but poorer in geometric invariance properties. In this paper, we present a straightforward framework for better image representation by combining the two approaches. To take advantages of both representations, we propose an efficient method to extract a fair amount of multi-scale dense local activations from a pre-trained CNN. We then aggregate the activations by Fisher kernel framework, which has been modified with a simple scale-wise normalization essential to make it suitable for CNN activations. Replacing the direct use of a single activation vector with our representation demonstrates significant performance improvements: +17.76 (Acc.) on MIT Indoor 67 and +7.18 (mAP) on PASCAL VOC 2007. The results suggest that our proposal can be used as a primary image representation for better performances in visual recognition tasks.