 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Object Manipulation Skills from Video via Approximate Differentiable Physics
Aug 03, 2022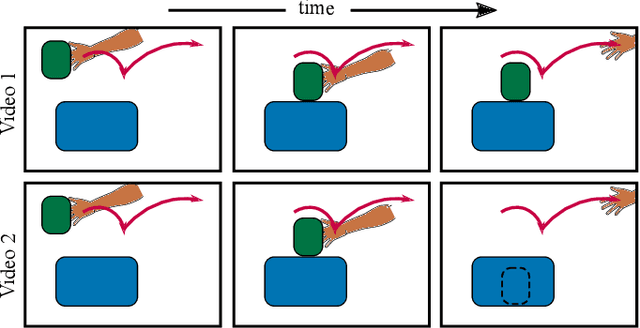
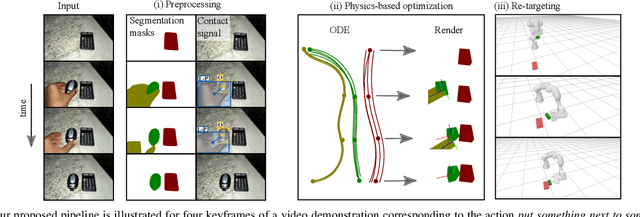


We aim to teach robots to perform simple object manipulation tasks by watching a single video demonstration. Towards this goal, we propose an optimization approach that outputs a coarse and temporally evolving 3D scene to mimic the action demonstrated in the input video. Similar to previous work, a differentiable renderer ensures perceptual fidelity between the 3D scene and the 2D video. Our key novelty lies in the inclusion of a differentiable approach to solve a set of Ordinary Differential Equations (ODEs) that allows us to approximately model laws of physics such as gravity, friction, and hand-object or object-object interactions. This not only enables us to dramatically improve the quality of estimated hand and object states, but also produces physically admissible trajectories that can be directly translated to a robot without the need for costly reinforcement learning. We evaluate our approach on a 3D reconstruction task that consists of 54 video demonstrations sourced from 9 actions such as pull something from right to left or put something in front of something. Our approach improves over previous state-of-the-art by almost 30%, demonstrating superior quality on especially challenging actions involving physical interactions of two objects such as put something onto something. Finally, we showcase the learned skills on a Franka Emika Panda robot.
Zero-Shot Video Question Answering via Frozen Bidirectional Language Models
Jun 16, 2022
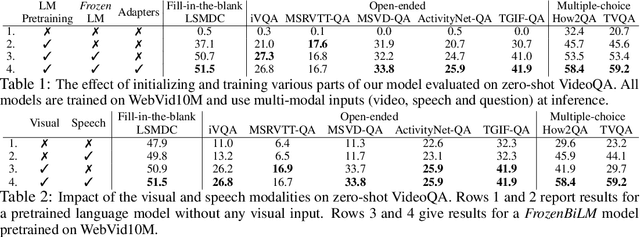
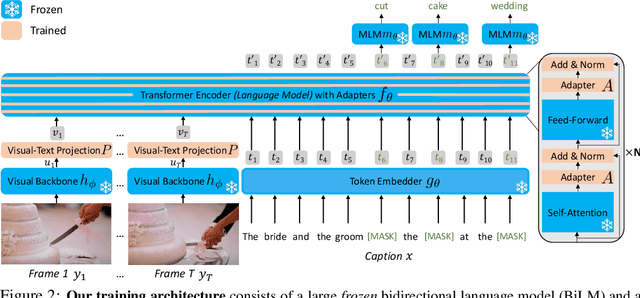

Video question answering (VideoQA) is a complex task that requires diverse multi-modal data for training. Manual annotation of question and answers for videos, however, is tedious and prohibits scalability. To tackle this problem, recent methods consider zero-shot settings with no manual annotation of visual question-answer. In particular, a promising approach adapts frozen autoregressive language models pretrained on Web-scale text-only data to multi-modal inputs. In contrast, we here build on frozen bidirectional language models (BiLM) and show that such an approach provides a stronger and cheaper alternative for zero-shot VideoQA. In particular, (i) we combine visual inputs with the frozen BiLM using light trainable modules, (ii) we train such modules using Web-scraped multi-modal data, and finally (iii) we perform zero-shot VideoQA inference through masked language modeling, where the masked text is the answer to a given question. Our proposed approach, FrozenBiLM, outperforms the state of the art in zero-shot VideoQA by a significant margin on a variety of datasets, including LSMDC-FiB, iVQA, MSRVTT-QA, MSVD-QA, ActivityNet-QA, TGIF-FrameQA, How2QA and TVQA. It also demonstrates competitive performance in the few-shot and fully-supervised setting. Our code and models will be made publicly available at https://antoyang.github.io/frozenbilm.html.
Collision Detection Accelerated: An Optimization Perspective
May 20, 2022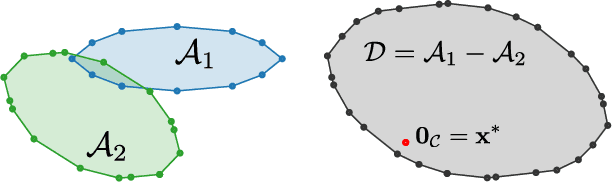
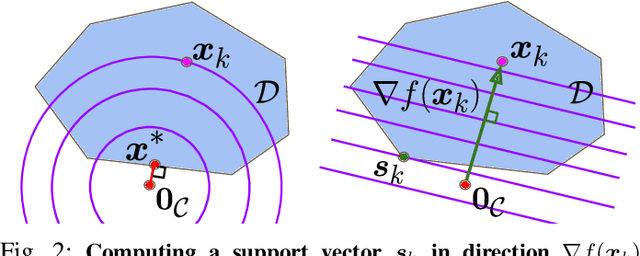
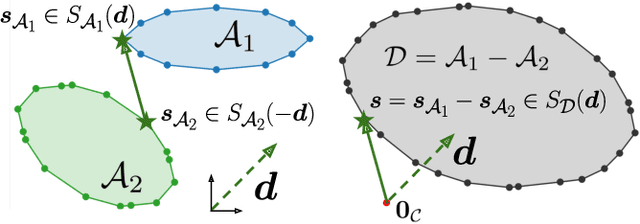
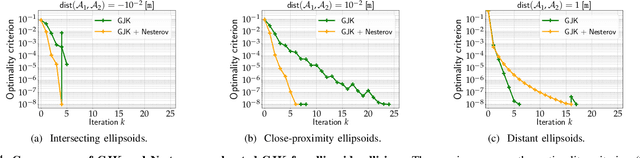
Collision detection between two convex shapes is an essential feature of any physics engine or robot motion planner. It has often been tackled as a computational geometry problem, with the Gilbert, Johnson and Keerthi (GJK) algorithm being the most common approach today. In this work we leverage the fact that collision detection is fundamentally a convex optimization problem. In particular, we establish that the GJK algorithm is a specific sub-case of the well-established Frank-Wolfe (FW) algorithm in convex optimization. We introduce a new collision detection algorithm by adapting recent works linking Nesterov acceleration and Frank-Wolfe methods. We benchmark the proposed accelerated collision detection method on two datasets composed of strictly convex and non-strictly convex shapes. Our results show that our approach significantly reduces the number of iterations to solve collision detection problems compared to the state-of-the-art GJK algorithm, leading to up to two times faster computation times.
* RSS 2022, 12 pages, 9 figures, 2 tables
Learning to Answer Visual Questions from Web Videos
May 11, 2022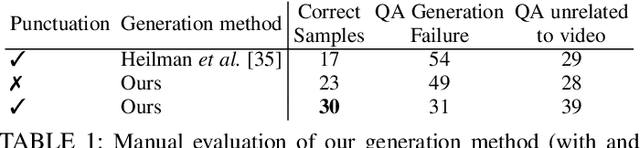
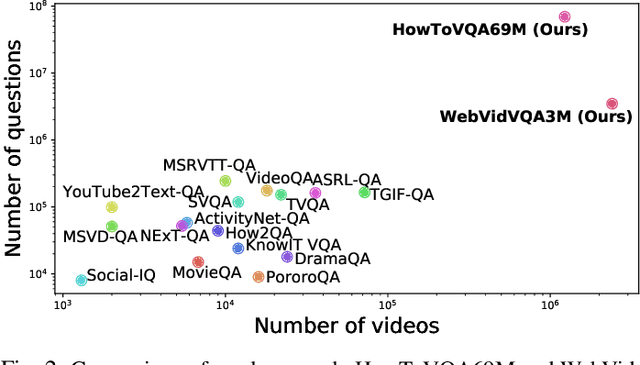
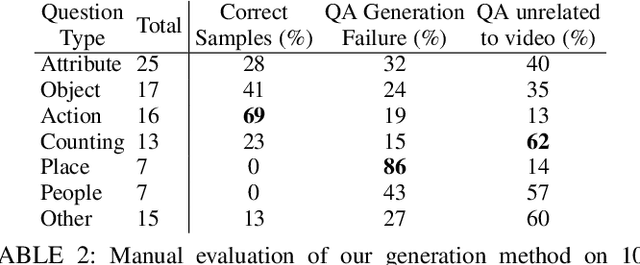
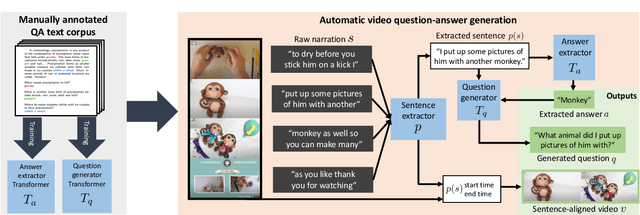
Recent methods for visual question answering rely on large-scale annotated datasets. Manual annotation of questions and answers for videos, however, is tedious, expensive and prevents scalability. In this work, we propose to avoid manual annotation and generate a large-scale training dataset for video question answering making use of automatic cross-modal supervision. We leverage a question generation transformer trained on text data and use it to generate question-answer pairs from transcribed video narrations. Given narrated videos, we then automatically generate the HowToVQA69M dataset with 69M video-question-answer triplets. To handle the open vocabulary of diverse answers in this dataset, we propose a training procedure based on a contrastive loss between a video-question multi-modal transformer and an answer transformer. We introduce the zero-shot VideoQA task and the VideoQA feature probe evaluation setting and show excellent results, in particular for rare answers. Furthermore, our method achieves competitive results on MSRVTT-QA, ActivityNet-QA, MSVD-QA and How2QA datasets. We also show that our VideoQA dataset generation approach generalizes to another source of web video and text data. We use our method to generate the WebVidVQA3M dataset from the WebVid dataset, i.e., videos with alt-text annotations, and show its benefits for training VideoQA models. Finally, for a detailed evaluation we introduce iVQA, a new VideoQA dataset with reduced language bias and high-quality manual annotations. Code, datasets and trained models are available at https://antoyang.github.io/just-ask.html
Focal Length and Object Pose Estimation via Render and Compare
Apr 11, 2022

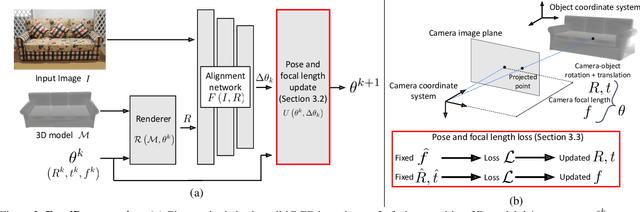
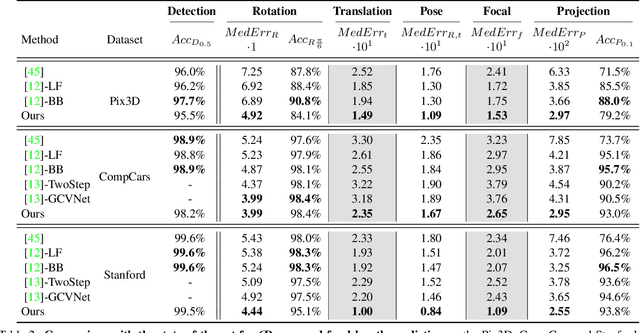
We introduce FocalPose, a neural render-and-compare method for jointly estimating the camera-object 6D pose and camera focal length given a single RGB input image depicting a known object. The contributions of this work are twofold. First, we derive a focal length update rule that extends an existing state-of-the-art render-and-compare 6D pose estimator to address the joint estimation task. Second, we investigate several different loss functions for jointly estimating the object pose and focal length. We find that a combination of direct focal length regression with a reprojection loss disentangling the contribution of translation, rotation, and focal length leads to improved results. We show results on three challenging benchmark datasets that depict known 3D models in uncontrolled settings. We demonstrate that our focal length and 6D pose estimates have lower error than the existing state-of-the-art methods.
TubeDETR: Spatio-Temporal Video Grounding with Transformers
Mar 30, 2022
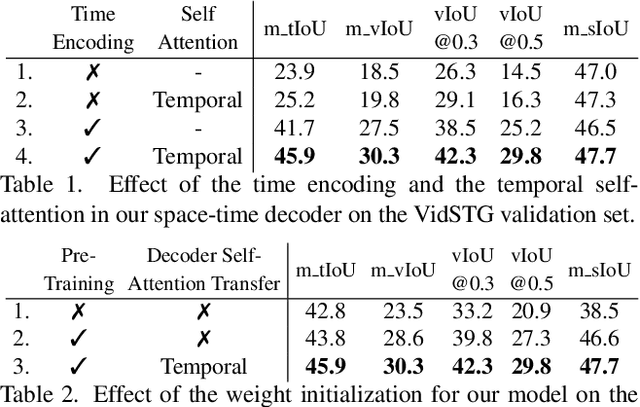
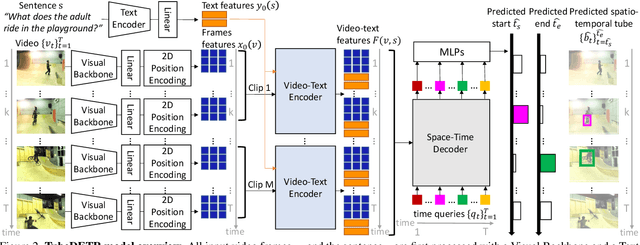
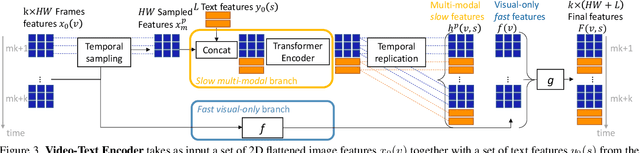
We consider the problem of localizing a spatio-temporal tube in a video corresponding to a given text query. This is a challenging task that requires the joint and efficient modeling of temporal, spatial and multi-modal interactions. To address this task, we propose TubeDETR, a transformer-based architecture inspired by the recent success of such models for text-conditioned object detection. Our model notably includes: (i) an efficient video and text encoder that models spatial multi-modal interactions over sparsely sampled frames and (ii) a space-time decoder that jointly performs spatio-temporal localization. We demonstrate the advantage of our proposed components through an extensive ablation study. We also evaluate our full approach on the spatio-temporal video grounding task and demonstrate improvements over the state of the art on the challenging VidSTG and HC-STVG benchmarks. Code and trained models are publicly available at https://antoyang.github.io/tubedetr.html.
Look for the Change: Learning Object States and State-Modifying Actions from Untrimmed Web Videos
Mar 22, 2022
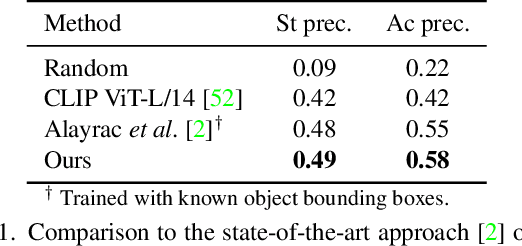
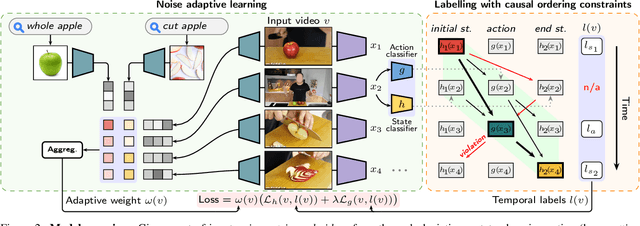

Human actions often induce changes of object states such as "cutting an apple", "cleaning shoes" or "pouring coffee". In this paper, we seek to temporally localize object states (e.g. "empty" and "full" cup) together with the corresponding state-modifying actions ("pouring coffee") in long uncurated videos with minimal supervision. The contributions of this work are threefold. First, we develop a self-supervised model for jointly learning state-modifying actions together with the corresponding object states from an uncurated set of videos from the Internet. The model is self-supervised by the causal ordering signal, i.e. initial object state $\rightarrow$ manipulating action $\rightarrow$ end state. Second, to cope with noisy uncurated training data, our model incorporates a noise adaptive weighting module supervised by a small number of annotated still images, that allows to efficiently filter out irrelevant videos during training. Third, we collect a new dataset with more than 2600 hours of video and 34 thousand changes of object states, and manually annotate a part of this data to validate our approach. Our results demonstrate substantial improvements over prior work in both action and object state-recognition in video.
Drive&Segment: Unsupervised Semantic Segmentation of Urban Scenes via Cross-modal Distillation
Mar 21, 2022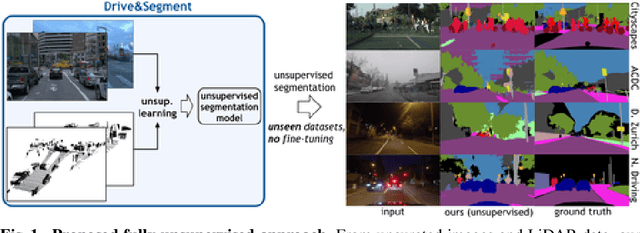
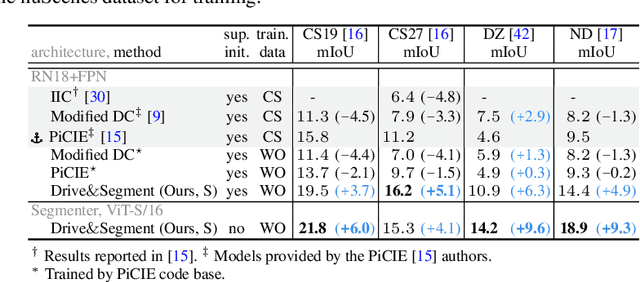
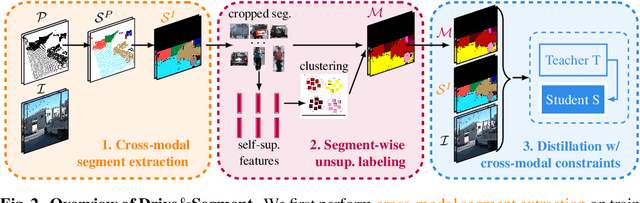
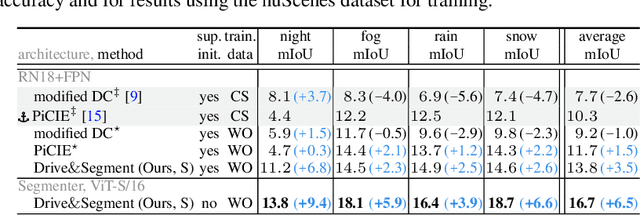
This work investigates learning pixel-wise semantic image segmentation in urban scenes without any manual annotation, just from the raw non-curated data collected by cars which, equipped with cameras and LiDAR sensors, drive around a city. Our contributions are threefold. First, we propose a novel method for cross-modal unsupervised learning of semantic image segmentation by leveraging synchronized LiDAR and image data. The key ingredient of our method is the use of an object proposal module that analyzes the LiDAR point cloud to obtain proposals for spatially consistent objects. Second, we show that these 3D object proposals can be aligned with the input images and reliably clustered into semantically meaningful pseudo-classes. Finally, we develop a cross-modal distillation approach that leverages image data partially annotated with the resulting pseudo-classes to train a transformer-based model for image semantic segmentation. We show the generalization capabilities of our method by testing on four different testing datasets (Cityscapes, Dark Zurich, Nighttime Driving and ACDC) without any finetuning, and demonstrate significant improvements compared to the current state of the art on this problem. See project webpage https://vobecant.github.io/DriveAndSegment/ for the code and more.
Learning to Manipulate Tools by Aligning Simulation to Video Demonstration
Nov 04, 2021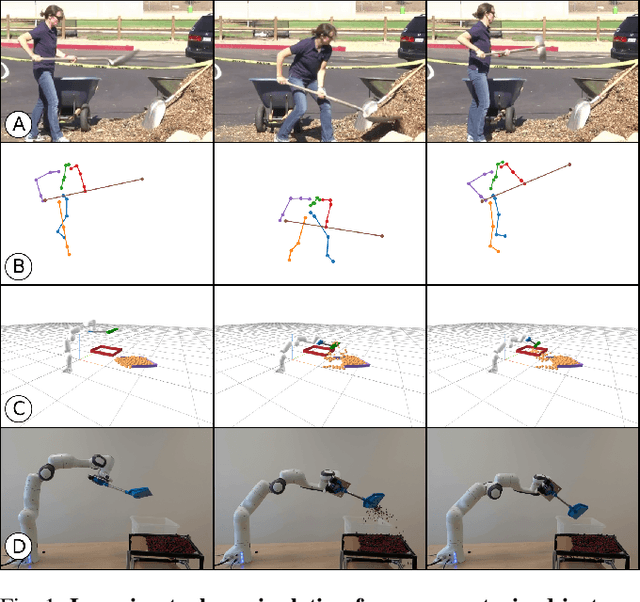


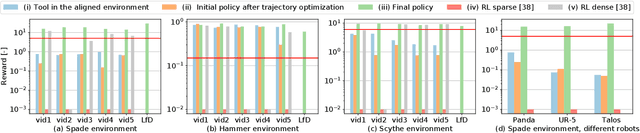
A seamless integration of robots into human environments requires robots to learn how to use existing human tools. Current approaches for learning tool manipulation skills mostly rely on expert demonstrations provided in the target robot environment, for example, by manually guiding the robot manipulator or by teleoperation. In this work, we introduce an automated approach that replaces an expert demonstration with a Youtube video for learning a tool manipulation strategy. The main contributions are twofold. First, we design an alignment procedure that aligns the simulated environment with the real-world scene observed in the video. This is formulated as an optimization problem that finds a spatial alignment of the tool trajectory to maximize the sparse goal reward given by the environment. Second, we describe an imitation learning approach that focuses on the trajectory of the tool rather than the motion of the human. For this we combine reinforcement learning with an optimization procedure to find a control policy and the placement of the robot based on the tool motion in the aligned environment. We demonstrate the proposed approach on spade, scythe and hammer tools in simulation, and show the effectiveness of the trained policy for the spade on a real Franka Emika Panda robot demonstration.
Estimating 3D Motion and Forces of Human-Object Interactions from Internet Videos
Nov 02, 2021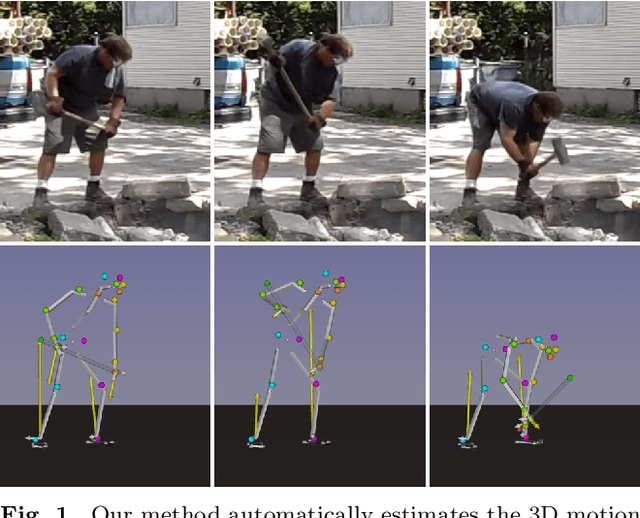

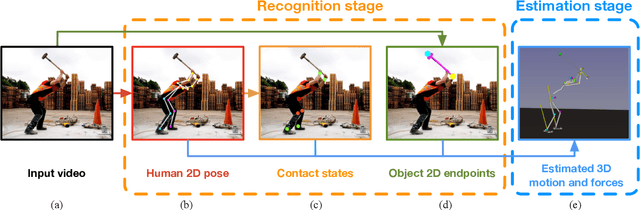

In this paper, we introduce a method to automatically reconstruct the 3D motion of a person interacting with an object from a single RGB video. Our method estimates the 3D poses of the person together with the object pose, the contact positions and the contact forces exerted on the human body. The main contributions of this work are three-fold. First, we introduce an approach to jointly estimate the motion and the actuation forces of the person on the manipulated object by modeling contacts and the dynamics of the interactions. This is cast as a large-scale trajectory optimization problem. Second, we develop a method to automatically recognize from the input video the 2D position and timing of contacts between the person and the object or the ground, thereby significantly simplifying the complexity of the optimization. Third, we validate our approach on a recent video+MoCap dataset capturing typical parkour actions, and demonstrate its performance on a new dataset of Internet videos showing people manipulating a variety of tools in unconstrained environments.