 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgestable-worldmodel: A Platform for Reproducible World Modeling Research and Evaluation
May 20, 2026World models are central to building agents that can reason, plan, and generalize beyond their training data. However, research on world models is currently fragmented, with disparate codebases, data pipelines, and evaluation protocols hindering reproducibility and fair comparison. Current practice is further limited by three key bottlenecks: fragile one-off codebases, slow video data loading, and the lack of standardized generalization benchmarks. We present stable-worldmodel (swm), an open-source platform for standardized and reproducible world modeling research and evaluation. It delivers (1) a high-performance Lance-based data layer with native support and conversion tools for MP4, HDF5, and LeRobot datasets, (2) clean, well-tested implementations of modern world model baselines and planning solvers, and (3) a broad suite of environments and tasks extended with controllable visual, geometric, and physical factors of variation for systematic in-silico evaluation of dynamics understanding, control performance, representation quality, and out-of-distribution generalization. By unifying the full pipeline under a single, scalable framework, \texttt{swm} dramatically reduces research overhead and accelerates trustworthy progress toward reliable world models.
Accelerating trajectory optimization with Sobolev-trained diffusion policies
Apr 21, 2026Trajectory Optimization (TO) solvers exploit known system dynamics to compute locally optimal trajectories through iterative improvements. A downside is that each new problem instance is solved independently; therefore, convergence speed and quality of the solution found depend on the initial trajectory proposed. To improve efficiency, a natural approach is to warm-start TO with initial guesses produced by a learned policy trained on trajectories previously generated by the solver. Diffusion-based policies have recently emerged as expressive imitation learning models, making them promising candidates for this role. Yet, a counterintuitive challenge comes from the local optimality of TO demonstrations: when a policy is rolled out, small non-optimal deviations may push it into situations not represented in the training data, triggering compounding errors over long horizons. In this work, we focus on learning-based warm-starting for gradient-based TO solvers that also provide feedback gains. Exploiting this specificity, we derive a first-order loss for Sobolev learning of diffusion-based policies using both trajectories and feedback gains. Through comprehensive experiments, we demonstrate that the resulting policy avoids compounding errors, and so can learn from very few trajectories to provide initial guesses reducing solving time by $2\times$ to $20 \times$. Incorporating first-order information enables predictions with fewer diffusion steps, reducing inference latency.
Causal-JEPA: Learning World Models through Object-Level Latent Interventions
Feb 11, 2026World models require robust relational understanding to support prediction, reasoning, and control. While object-centric representations provide a useful abstraction, they are not sufficient to capture interaction-dependent dynamics. We therefore propose C-JEPA, a simple and flexible object-centric world model that extends masked joint embedding prediction from image patches to object-centric representations. By applying object-level masking that requires an object's state to be inferred from other objects, C-JEPA induces latent interventions with counterfactual-like effects and prevents shortcut solutions, making interaction reasoning essential. Empirically, C-JEPA leads to consistent gains in visual question answering, with an absolute improvement of about 20\% in counterfactual reasoning compared to the same architecture without object-level masking. On agent control tasks, C-JEPA enables substantially more efficient planning by using only 1\% of the total latent input features required by patch-based world models, while achieving comparable performance. Finally, we provide a formal analysis demonstrating that object-level masking induces a causal inductive bias via latent interventions. Our code is available at https://github.com/galilai-group/cjepa.
stable-worldmodel-v1: Reproducible World Modeling Research and Evaluation
Feb 09, 2026World Models have emerged as a powerful paradigm for learning compact, predictive representations of environment dynamics, enabling agents to reason, plan, and generalize beyond direct experience. Despite recent interest in World Models, most available implementations remain publication-specific, severely limiting their reusability, increasing the risk of bugs, and reducing evaluation standardization. To mitigate these issues, we introduce stable-worldmodel (SWM), a modular, tested, and documented world-model research ecosystem that provides efficient data-collection tools, standardized environments, planning algorithms, and baseline implementations. In addition, each environment in SWM enables controllable factors of variation, including visual and physical properties, to support robustness and continual learning research. Finally, we demonstrate the utility of SWM by using it to study zero-shot robustness in DINO-WM.
Value-guided action planning with JEPA world models
Dec 28, 2025Building deep learning models that can reason about their environment requires capturing its underlying dynamics. Joint-Embedded Predictive Architectures (JEPA) provide a promising framework to model such dynamics by learning representations and predictors through a self-supervised prediction objective. However, their ability to support effective action planning remains limited. We propose an approach to enhance planning with JEPA world models by shaping their representation space so that the negative goal-conditioned value function for a reaching cost in a given environment is approximated by a distance (or quasi-distance) between state embeddings. We introduce a practical method to enforce this constraint during training and show that it leads to significantly improved planning performance compared to standard JEPA models on simple control tasks.
Differentiable Simulation of Soft Robots with Frictional Contacts
Jan 31, 2025



In recent years, soft robotics simulators have evolved to offer various functionalities, including the simulation of different material types (e.g., elastic, hyper-elastic) and actuation methods (e.g., pneumatic, cable-driven, servomotor). These simulators also provide tools for various tasks, such as calibration, design, and control. However, efficiently and accurately computing derivatives within these simulators remains a challenge, particularly in the presence of physical contact interactions. Incorporating these derivatives can, for instance, significantly improve the convergence speed of control methods like reinforcement learning and trajectory optimization, enable gradient-based techniques for design, or facilitate end-to-end machine-learning approaches for model reduction. This paper addresses these challenges by introducing a unified method for computing the derivatives of mechanical equations within the finite element method framework, including contact interactions modeled as a nonlinear complementarity problem. The proposed approach handles both collision and friction phases, accounts for their nonsmooth dynamics, and leverages the sparsity introduced by mesh-based models. Its effectiveness is demonstrated through several examples of controlling and calibrating soft systems.
End-to-End and Highly-Efficient Differentiable Simulation for Robotics
Sep 11, 2024



Over the past few years, robotics simulators have largely improved in efficiency and scalability, enabling them to generate years of simulated data in a few hours. Yet, efficiently and accurately computing the simulation derivatives remains an open challenge, with potentially high gains on the convergence speed of reinforcement learning and trajectory optimization algorithms, especially for problems involving physical contact interactions. This paper contributes to this objective by introducing a unified and efficient algorithmic solution for computing the analytical derivatives of robotic simulators. The approach considers both the collision and frictional stages, accounting for their intrinsic nonsmoothness and also exploiting the sparsity induced by the underlying multibody systems. These derivatives have been implemented in C++, and the code will be open-sourced in the Simple simulator. They depict state-of-the-art timings ranging from 5 microseconds for a 7-dof manipulator up to 95 microseconds for 36-dof humanoid, outperforming alternative solutions by a factor of at least 100.
From Compliant to Rigid Contact Simulation: a Unified and Efficient Approach
May 27, 2024



Whether rigid or compliant, contact interactions are inherent to robot motions, enabling them to move or manipulate things. Contact interactions result from complex physical phenomena, that can be mathematically cast as Nonlinear Complementarity Problems (NCPs) in the context of rigid or compliant point contact interactions. Such a class of complementarity problems is, in general, difficult to solve both from an optimization and numerical perspective. Over the past decades, dedicated and specialized contact solvers, implemented in modern robotics simulators (e.g., Bullet, Drake, MuJoCo, DART, Raisim) have emerged. Yet, most of these solvers tend either to solve a relaxed formulation of the original contact problems (at the price of physical inconsistencies) or to scale poorly with the problem dimension or its numerical conditioning (e.g., a robotic hand manipulating a paper sheet). In this paper, we introduce a unified and efficient approach to solving NCPs in the context of contact simulation. It relies on a sound combination of the Alternating Direction Method of Multipliers (ADMM) and proximal algorithms to account for both compliant and rigid contact interfaces in a unified way. To handle ill-conditioned problems and accelerate the convergence rate, we also propose an efficient update strategy to adapt the ADMM hyperparameters automatically. By leveraging proximal methods, we also propose new algorithmic solutions to efficiently evaluate the inverse dynamics involving rigid and compliant contact interactions, extending the approach developed in MuJoCo. We validate the efficiency and robustness of our contact solver against several alternative contact methods of the literature and benchmark them on various robotics and granular mechanics scenarios. Our code is made open-source at https://github.com/Simple-Robotics/Simple.
Contact Models in Robotics: a Comparative Analysis
Apr 13, 2023



Physics simulation is ubiquitous in robotics. Whether in model-based approaches (e.g., trajectory optimization), or model-free algorithms (e.g., reinforcement learning), physics simulators are a central component of modern control pipelines in robotics. Over the past decades, several robotic simulators have been developed, each with dedicated contact modeling assumptions and algorithmic solutions. In this article, we survey the main contact models and the associated numerical methods commonly used in robotics for simulating advanced robot motions involving contact interactions. In particular, we recall the physical laws underlying contacts and friction (i.e., Signorini condition, Coulomb's law, and the maximum dissipation principle), and how they are transcribed in current simulators. For each physics engine, we expose their inherent physical relaxations along with their limitations due to the numerical techniques employed. Based on our study, we propose theoretically grounded quantitative criteria on which we build benchmarks assessing both the physical and computational aspects of simulation. We support our work with an open-source and efficient C++ implementation of the existing algorithmic variations. Our results demonstrate that some approximations or algorithms commonly used in robotics can severely widen the reality gap and impact target applications. We hope this work will help motivate the development of new contact models, contact solvers, and robotic simulators in general, at the root of recent progress in motion generation in robotics.
Differentiable Collision Detection: a Randomized Smoothing Approach
Sep 19, 2022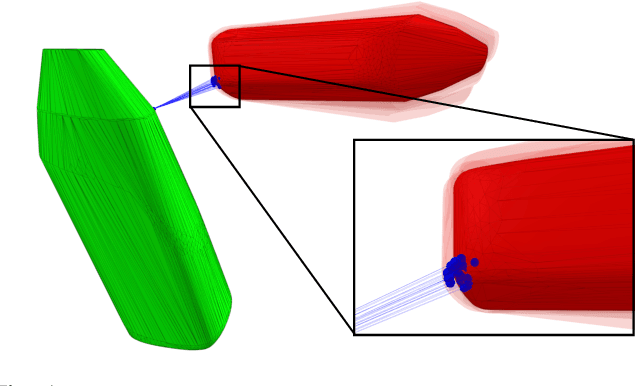
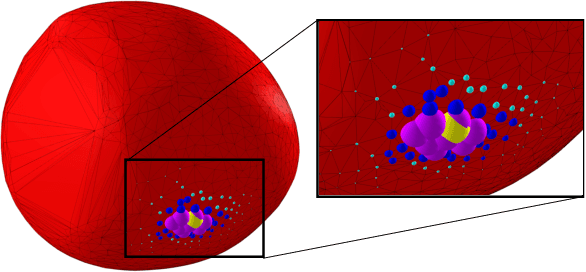

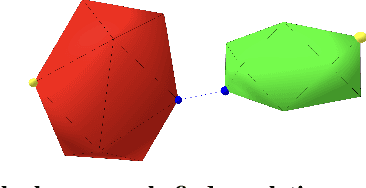
Collision detection appears as a canonical operation in a large range of robotics applications from robot control to simulation, including motion planning and estimation. While the seminal works on the topic date back to the 80s, it is only recently that the question of properly differentiating collision detection has emerged as a central issue, thanks notably to the ongoing and various efforts made by the scientific community around the topic of differentiable physics. Yet, very few solutions have been suggested so far, and only with a strong assumption on the nature of the shapes involved. In this work, we introduce a generic and efficient approach to compute the derivatives of collision detection for any pair of convex shapes, by notably leveraging randomized smoothing techniques which have shown to be particularly adapted to capture the derivatives of non-smooth problems. This approach is implemented in the HPP-FCL and Pinocchio ecosystems, and evaluated on classic datasets and problems of the robotics literature, demonstrating few micro-second timings to compute informative derivatives directly exploitable by many real robotic applications including differentiable simulation.